MySQL数据库总结(持续更新...)
文章目录
- 一、数据库简介
- 二、MySQL数据类型
-
- 1)常见的类型
- 2)主要包括的类别
- 3)MYSQL数据类型的长度和范围
- 三、MySQL语句
-
- (1)SQL语句简介
- (2)SQL分类
- (3)数据定义语言DDL【create,alter,drop】
- (4)数据操纵语言DML【update,insert,delete】
- (5)数据控制语言DCL【grant,revoke】
- (6)数据查询语言DQL【select】
- (7)分组查询与分页查询【group by,limit】
-
- - 分组查询
- - 分页查询
- 四、完整性约束(单表)
- 五、多表查询
- 六、视图
-
- 视图创建
- 视图修改
- 视图删除
一、数据库简介
- 数据库(Database,DB)是按照数据结构来组织,存储和管理数据的仓库。
- 典型特征:数据的结构化、数据间的共享、减少数据的冗余度,数据的独立性。
- 关系型数据库:使用关系模型把数据组织到数据表(table)中。现实世界可以用数据来描述。
- 主流的关系型数据库产品:Oracle(Oracle)、DB2(IBM)、SQL Server(MS)、MySQL(Oracle)。
- 数据表:数据表是关系数据库的基本存储结构,二维数据表有行(Row),和列(Column)组成,也叫作记录(行)和字段(列)。
二、MySQL数据类型
MySQL中除了字符串类型需要设置长度,其他类型都有默认长度.
1)常见的类型
| 数值类型 | Java中 | MySQL中 |
|---|---|---|
| 整型 | byte | tinyint |
| short | smallint | |
| int | int | |
| long | bigint | |
| 浮点型 | float | float |
| double | double | |
| 字符串类型 | String | 定长char() ;可变长varchar() |
| 时间日期 | date | date/time/datetime |
2)主要包括的类别
整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮点数类型:FLOAT、DOUBLE、DECIMAL
字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期类型:Date、DateTime、TimeStamp、Time、Year
其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
3)MYSQL数据类型的长度和范围
| 数据类型(DataType) | 字节长度(Byte) | 范围或用法(Range or Usage) |
|---|---|---|
| Bit | 1 | 无符号[0,255],有符号[-128,127],备注:BIT和BOOL布尔型都占用1字节 |
| TinyInt | 1 | 无符号[0,255],有符号[-128,127] |
| SmallInt | 2 | 无符号[0,65535],有符号[-32768,32767] |
| MediumInt | 3 | 无符号[0,224-1]==[0,16777215],有符号[-223,2^23-1]==[-8388608,8388607] |
| Int | 4 | 无符号[0,232-1]==[0,4294967295],有符号[-231,2^31-1]==[-2147483648,2147483647] |
| BigInt | 8 | 无符号[0,264-1]==[0,18446744073709551615],有符号[-263 ,2^63 -1]==[-9223372036854775808,9223372036854775807] |
| Float(M,D) | 4 | 单精度浮点数。注:这里的D是精度,如果D<=24则为默认的FLOAT,如果D>24则会自动被转换为DOUBLE型。 |
| Double(M,D) | 8 | 双精度浮点。 |
| Decimal(M,D) | M+1或M+2 | 未打包的浮点数,用法类似于FLOAT和DOUBLE,注:您如果在ASP中使用到Decimal数据类型,直接从数据库读出来的Decimal可能需要先转换成Float或Double类型后再进行运算。 |
| Date | 3 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Date Time | 8 | 以YYYY-MM-DD HH:MM:SS的格式显示,比如:2009-07-19 11:22:30 |
| TimeStamp | 4 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Time | 3 | 以HH:MM:SS的格式显示。比如:11:22:30 |
| Year | 1 | 以YYYY的格式显示。比如:2009 |
| Char(M) | M | 定长字符串。 |
| VarChar(M) | M | 变长字符串,要求M<=255 |
| Binary(M) | M | 类似Char的二进制存储,特点是插入定长不足补0 |
| VarBinary(M) | M | 类似VarChar的变长二进制存储,特点是定长不补0 |
| Tiny Text | Max:255 | 大小写不敏感 |
| Text | Max:64K | 大小写不敏感 |
| Medium Text | Max:16M | 大小写不敏感 |
| Long Text | Max:4G | 大小写不敏感 |
| TinyBlob | Max:255 | 大小写敏感 |
| Blob | Max:64K | 大小写敏感 |
| MediumBlob | Max:16M | 大小写敏感 |
| LongBlob | Max:4G | 大小写敏感 |
| Enum | 1或2 | 最大可达65535个不同的枚举值 |
| Set | 可达8 | 最大可达64个不同的值 |
| Geometry | ||
| Point | ||
| LineString | ||
| Polygon | ||
| MultiPoint | ||
| MultiLineString | ||
| MultiPolygon | ||
| GeometryCollection |
三、MySQL语句
(1)SQL语句简介
SQL(Structured Query Language):结构化查询语言,SQL是在关系数据库上执行数据操作、检索及维护所使用的标准语言,可以用来查询数据,操纵数据,定义数据,控制数据。
(2)SQL分类
- 数据定义语言(DDL):Data Definition Language
- 数据操纵语言(DML):Data Manipulation Language
- 事务控制语言(TCL):Transaction Control Language
- 数据查询语言(DQL):Data Query Language
- 数据控制语言(DCL):Data Control Language
(3)数据定义语言DDL【create,alter,drop】
--数据定义语言DDL(create,alter,drop)
-- 一、数据库相关的DDL
-- 1.创建数据库
CREATE DATABASE mybase;
-- 2.创建数据库并指定字符集
CREATE DATABASE mybase1 CHARACTER SET UTF8;
-- 3.查看所有数据库
SHOW DATABASES;
-- 4.查看当前使用的数据库
SELECT DATABASE();
-- 5.修改数据库
ALTER DATABASE mybase CHARACTER SET UTF8;
-- 6.删除数据库
DROP DATABASE mybase1;
-- 切换数据库
USE mybase;
--二、表相关DDL
-- 1.创建表
create table exam_2020(
ID INT(11) PRIMARY KEY AUTO_INCREMENT,
Name VARCHAR(20),
English INT,
Chinese INT,
Math int
);
-- 2.查看数据库中所有表
show TABLES;
-- 3.查看表结构
desc exam_2020;
-- 4.表的删除
drop table exam_2020;
-- 5.表的修改(基于exam表)
-- 5.1添加列
ALTER TABLE exam_2020 ADD History INT NOT NULL;
-- 5.2修改列的类型、长度、约束
ALTER TABLE exam_2020 MODIFY History DOUBLE(7,2);
-- 5.3修改表的列名
ALTER TABLE exam_2020 CHANGE History Physics INT NOT NULL;
-- 5.4修改表名
RENAME TABLE exam_2020 TO score;
-- 5.5修改表的字符集
ALTER TABLE score CHARACTER SET GBK;
-- 5.6删除列
ALTER TABLE score DROP Physics;
-- 5.7
ALTER TABLE
-- 三、练习:创建temp表
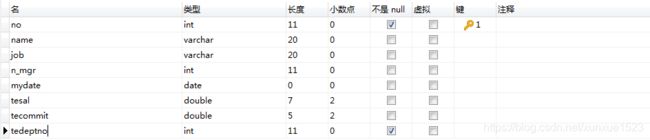
CREATE TABLE temp(
no INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
job VARCHAR(20),
n_mgr int,
mydate DATE,
tesal DOUBLE(7,2),
tecommit double(5,2),
tedeptno INT NOT NULL -- 非空约束
);
表temp:
表exam_2020:

(4)数据操纵语言DML【update,insert,delete】
-- 数据操纵语言DML(update,insert,delete)
-- 1.插入部分列
INSERT INTO score(id,NAME,English,Chinese,Math) VALUE(1,'张三',60,70,99);
INSERT INTO score(id,NAME,English,Chinese) VALUE(NULL,'李四',91,61);
-- 2.插入所有列
INSERT INTO score VALUES(3,'Wang',60,70,80);
-- 3.修改记录
UPDATE score set Chinese=96; --全表修改
UPDATE score SET Math=100 WHERE id='1';
-- 4.删除记录
DELETE FROM score WHERE id='2';
DELETE FROM score;
-- delete与truncate的区别 √
--TRUNCATE TABLE 删除表的记录:将整个表删除掉,重新创建一个新的表,属于DDL.
--DELETE FROM 删除表的记录:一条一条进行删除,DELETE.
INSERT INTO score VALUES(3,'Wang',80,70,60);
DELETE FROM score;
INSERT INTO score VALUES(NULL,'张三',10,10,10); --不会清空AUTO_INCREMENT值
TRUNCATE TABLE score;
INSERT INTO score VALUES(NULL,'李四',10,10,10); --清空AUTO_INCREMENT的值
-- 事务管理:只能作用在DML语句上,如果在一个事务中使用delete删除所有记录,可以找回.
-- 使用delete删除后可以用COMMIT和ROLLBACK找回数据,使用truncate后就找不回来了.
-- delete、truncate、drop的区别
delete、truncate、只是删除表的记录,而drop会直接删除表.

(5)数据控制语言DCL【grant,revoke】
-- 数据控制语言DCL(grant,revoke)
-- 主要为用户授予和撤销权限
-- 1.创建用户:CREATE USER 用户名@ip IDENTIFIED BY 密码;
create user Wang@localhost identified by '123456';
-- 2.给用户授权:grank 权限1,权限2,...,权限n ON 数据库名.* TO 用户名@IP;
grant select,drop on mysql.* to Wang@localhost;
-- 3.撤销权限:REVOKE 权限1,权限2,...,权限n ON 数据库名.* FROM 用户名@IP;
revoke select on mysql.* from Wang@localhost;
-- 4.查看用户的权限:SHOW GRANTS FOR 用户名@IPl
show grants for Wang@localhost;
-- 5.删除用户: DROP USER 用户名@IP;
drop user Wang@localhost;
-- 6.登录:mysql -u 用户名-p 密码;
mysql -u root -p
-- 7.退出登录: exit;
exit;
(6)数据查询语言DQL【select】
score表:

INSERT INTO score VALUES(NULL,'王五',99,99,99);
INSERT INTO score VALUES(NULL,'四六',89,89,89);
-- 1.全表查询: SELECT * FROM 表;
SELECT * FROM score;
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 1 | 李四 | 10 | 10 | 10 |
| 2 | 张三 | 60 | 90 | 80 |
| 3 | 王五 | 99 | 99 | 99 |
| 4 | 四六 | 89 | 89 | 89 |
+----+------+---------+---------+------+
-- 2.查询部分字段: SELECT 字段,字段,字段... FROM 表;
SELECT NAME,English,Math FROM score;
+------+---------+------+
| NAME | English | Math |
+------+---------+------+
| 李四 | 10 | 10 |
| 张三 | 90 | 80 |
| 王五 | 99 | 99 |
| 四六 | 89 | 89 |
+------+---------+------+
-- 3.过滤重复字段行: SELECT [DISTINCT] *|列名 FROM 表;
SELECT DISTINCT Math FROM score;
+------+
| Math |
+------+
| 10 |
| 80 |
| 99 |
| 89 |
+------+
SELECT DISTINCT name,Math FROM score;
+------+------+
| name | Math |
+------+------+
| 李四 | 10 |
| 张三 | 80 |
| 王五 | 99 |
| 四六 | 89 |
+------+------+
-- 4.查询字段起别名: SELECT 字段 AS 新字段名,字段 新字段名 FROM 表;
SELECT NAME,English AS English_score FROM score;
+------+---------------+
| NAME | English_score |
+------+---------------+
| 李四 | 10 |
| 张三 | 90 |
| 王五 | 99 |
| 四六 | 89 |
+------+---------------+
-- 5.查询指定字段
SELECT NAME,English,Chinese FROM score WHERE NAME='李四';
+------+---------+---------+
| NAME | English | Chinese |
+------+---------+---------+
| 李四 | 10 | 10 |
+------+---------+---------+
-- 6.使用表达式+、-、*、/
SELECT id,NAME,English-10 AS _English FROM score;
+----+------+----------+
| id | NAME | _English |
+----+------+----------+
| 1 | 李四 | 0 |
| 2 | 张三 | 80 |
| 3 | 王五 | 89 |
| 4 | 四六 | 79 |
+----+------+----------+
SELECT NAME,English+Math+Chinese FROM score;
+------+----------------------+
| NAME | English+Math+Chinese |
+------+----------------------+
| 李四 | 30 |
| 张三 | 230 |
| 王五 | 297 |
| 四六 | 267 |
+------+----------------------+
-- 7.模糊查询
SELECT * FROM score WHERE NAME LIKE '王_';
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 3 | 王五 | 99 | 99 | 99 |
+----+------+---------+---------+------+
SELECT * FROM score WHERE NAME LIKE '%%';
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 1 | 李四 | 10 | 10 | 10 |
| 2 | 张三 | 60 | 90 | 80 |
| 3 | 王五 | 99 | 99 | 99 |
| 4 | 四六 | 89 | 89 | 89 |
+----+------+---------+---------+------+
-- 8.使用and,or
SELECT * FROM score WHERE English > 90 AND Chinese >90;
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 3 | 王五 | 99 | 99 | 99 |
+----+------+---------+---------+------+
SELECT * FROM score WHERE English < 90 or Math >99;
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 1 | 李四 | 10 | 10 | 10 |
| 4 | 四六 | 89 | 89 | 89 |
+----+------+---------+---------+------+
-- 9.使用in,not in
SELECT * FROM score WHERE id=2 OR id=3 OR id=4;
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 2 | 张三 | 60 | 90 | 80 |
| 3 | 王五 | 99 | 99 | 99 |
| 4 | 四六 | 89 | 89 | 89 |
+----+------+---------+---------+------+
SELECT * FROM score where id IN(2,3,4);
SELECT * FROM score where id not IN(2,3,4);
-- 10.使用between...and []
SELECT * FROM score WHERE English BETWEEN 90 AND 100;
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 2 | 张三 | 60 | 90 | 80 |
| 3 | 王五 | 99 | 99 | 99 |
+----+------+---------+---------+------+
-- 11. is null,is not null
INSERT INTO score(id,NAME) VALUES(NULL,NULL);
SELECT * FROM score WHERE NAME IS NULL;
SELECT * FROM score WHERE NAME IS not NULL;
-- 11.排序查询
SELECT * FROM score ORDER BY Chinese ASC;
SELECT * FROM score ORDER BY Chinese DESC;
SELECT * FROM score ORDER BY English DESC,Chinese DESC;-- 如果英语成绩相同,按照汉语成绩降序排列
+----+------+---------+---------+------+
| ID | Name | Chinese | English | Math |
+----+------+---------+---------+------+
| 3 | 王五 | 99 | 99 | 99 |
| 2 | 张三 | 60 | 90 | 80 |
| 4 | 四六 | 89 | 89 | 89 |
| 1 | 李四 | 10 | 10 | 10 |
+----+------+---------+---------+------+
SELECT * FROM score WHERE NAME LIKE '王%' ORDER BY English ASC;
-- 12.聚合函数
SELECT SUM(English+Math+Chinese) FROM score;
SELECT COUNT(id) FROM score WHERE NAME IS NOT NULL;
SELECT MAX(English) FROM score;
SELECT MIN(English) FROM score;
SELECT AVG(English) FROM score ;
+--------------+
| AVG(English) |
+--------------+
| 72.0000 |
+--------------+
(7)分组查询与分页查询【group by,limit】
- 分组查询
CREATE TABLE temp(
no INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
job VARCHAR(20),
n_mgr int,
mydate DATE,
tesal DOUBLE(7,2),
tecommit double(5,2),
tedeptno INT NOT NULL
);
INSERT INTO temp VALUES
(2010,'白展堂','clerk',1001,'1983-05-09',7000.00,200.00,10),
(2011,'李大嘴','clerk',1002,'1980-07-08',8000.00,100.00,10),
(2012,'吕秀才','clerk',1002,'1985-11-12',4000.00,null,10),
(2015,'郭芙蓉','clerk',1002,'1985-03-04',4000.00,null,10),
(2021,'胡一菲','leader',null,'1994-03-04',15000.00,NULL,20),
(2022,'陈美嘉','manger',2001,'1993-05-24',10000.00,300.00,20),
(2023,'吕子乔','clerk',2002,'1995-05-19',7300.00,100.00,20),
(2024,'张伟','clerk',2002,'1994-10-12',8000.00,500.00,20),
(2025,'曾小贤','clerk',2002,'1993-05-10',9000.00,700.00,20),
(3031,'刘梅','leader',null,'1968-08-08',13000.00,NULL,30),
(3032,'夏冬梅','manger',3001,'1968-09-21',10000.00,600.00,30),
(3033,'夏雪','clerk',3002,'1989-09-21',8000.00,300.00,30),
(3034,'张一山','clerk',3002,'1991-06-16',88000.00,200.00,30);
-- 1.查询每个部门的平均工资
SELECT tedeptno ,AVG(tesal) FROM temp GROUP BY tedeptno;
-- 2.查询每个职位的最高工资和最低工资
SELECT job,MAX(tesal),MIN(tesal) FROM temp GROUP BY job;
-- 3.查询每个部门每种职位的最高工资
SELECT tedeptno,job,MAX(tesal) FROM temp GROUP BY tedeptno,job;
-- 4.查询每个部门的最高薪水,只有最高薪水大于15000的记录才被输出显示
SELECT tedeptno,MAX(tesal)AS max_sal FROM temp GROUP BY tedeptno HAVING max_sal>=15000;
-- 5.查询每个部门的平均工资
SELECT tedeptno,AVG(tesal) FROM temp GROUP BY tedeptno HAVING AVG(tesal)>9000;
-- 6.Havaing子句与where子句的区别
(1)where是用来过滤记录的,HAVING是用来过滤分组的
(2)过滤的时机不相同,先过滤Where后过滤Having.
(3)WHERE是在查询表时逐行过滤以选取满足条件的记录
(4)having是在数据查询后并且分完组后对分组进行过滤的
(5)HAVING必须跟在group BY
(6)查询语句执行顺序:5select 1from 2where 3group by 4having 6order by
详细查询结果如下:



- 分页查询
-- 1.从第几页开始多少页(下标从0开始)
SELECT * FROM temp LIMIT 0,3;
-- 2.每页几条第几页==需要查看第几页-1)乘以第二个参数
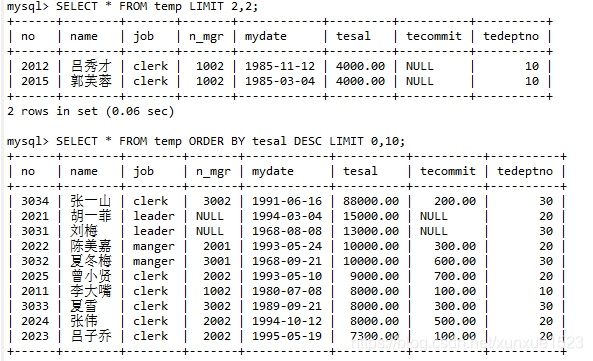
SELECT * FROM temp LIMIT 10,5;-- 每页五条第三页(3-1)*5
SELECT * FROM temp LIMIT 2,2; --每页2条第2页(2-1)*2
-- 3.查看工资最高的前十个职员信息
SELECT * FROM temp ORDER BY tesal DESC LIMIT 0,10;
详细查询结果如下:
四、完整性约束(单表)
主键约束: primary key(默认就是唯一非空的)
外键约束: 用于在两个表之间建立关系,需要指定引用主表的哪一列。
- 如果表A的主键是表B中的字段,则该字段称为表B的外键,表A(主表),表B(从表).
- 外键是用来实现参照完整性的,主表更新时从表也更新,主表删除时如果从表有匹配的项,删除失败
唯一约束:unique
非空约束:not null
CREATE TABLE temp(
no INT PRIMARY KEY AUTO_INCREMENT,--主键约束
name VARCHAR(20),
job VARCHAR(20),
n_mgr int,
mydate DATE,
tesal DOUBLE(7,2),
tecommit double(5,2),
tedeptno INT NOT NULL -- 非空约束
);
-- √ 添加 唯一约束和非空约束
ALTER TABLE temp MODIFY NAME VARCHAR(21) UNIQUE NOT NULL;
-- 创建主表
CREATE TABLE dept(
deptno INT PRIMARY KEY,
dname VARCHAR(20),
loc VARCHAR(20)
);
INSERT INTO dept VALUES
(10,'餐饮部','上海'),
(20,'销售部','浙江'),
(30,'财务部','北京'),
(40,'技术部','深圳');
为从表temp加外键
ALTER TABLE temp ADD FOREIGN KEY (tedeptno) REFERENCES dept(deptno);
五、多表查询
多张数据表或视图的查询叫做连接查询
-- 1.笛卡尔积:
SELECT *
FROM temp,dept;
-- 2.等值链接(SELECT * FROM A,B WHERE A.主键=B.外键;)
SELECT *
FROM temp,dept WHERE dept.deptno = temp.tedeptno;
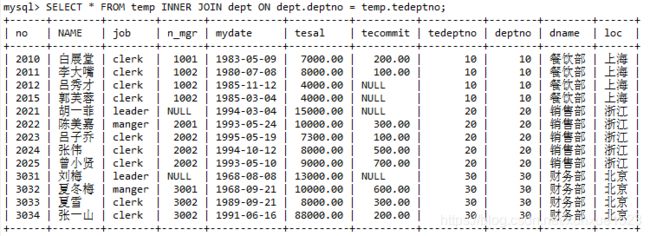
-- 3.内连接(SELECT * FROM A INNER JOIN B ON A.主键=B.外键;)
SELECT *
FROM temp INNER JOIN dept ON dept.deptno = temp.tedeptno;
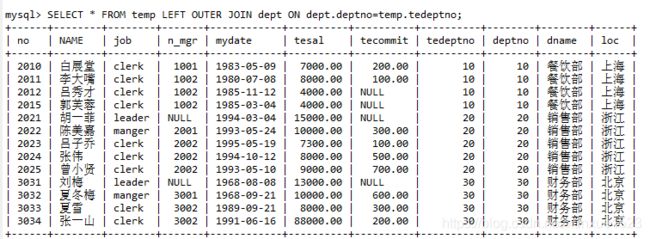
-- 4.外连接:
-- 4.1左外连接:(SELECT * FROM A LEFT OUTER JOIN B ON 条件;)
SELECT *
FROM temp LEFT OUTER JOIN dept ON dept.deptno=temp.tedeptno;
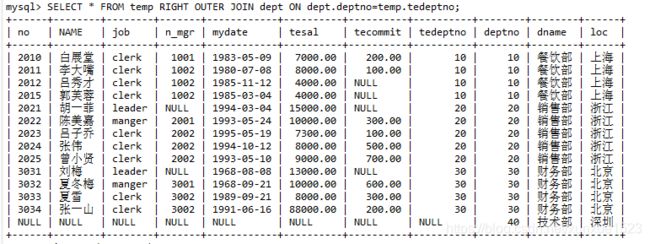
-- 4.2右外连接:(SELECT * FROM A right OUTER JOIN B ON 条件;)
SELECT *
FROM temp RIGHT OUTER JOIN dept ON dept.deptno=temp.tedeptno;
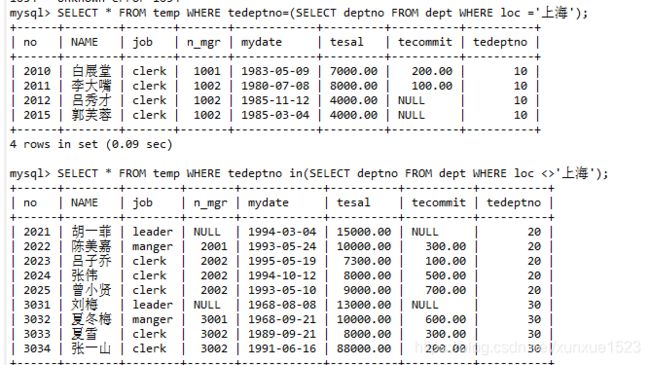
-- 5.子查询:
-- 5.1单行单列,工作地点在上海的员工
SELECT *
FROM temp WHERE tedeptno=(SELECT deptno FROM dept WHERE loc ='上海');
-- 5.2多行单列,工作地点不在上海的员工
SELECT *
FROM temp WHERE tedeptno in(SELECT deptno FROM dept WHERE loc <>'上海');
-- 6.自连接
SELECT e1.*,e2.* FROM temp e1 inner join temp e2 ON e1.n_mgr =e2.tedeptno
WHERE e1.name ='吕子乔';
多表查询练习
-- 1.查看每个员工的名字以及其所在部门的名字
SELECT temp.name,dept.dname,dept.loc
FROM temp,dept
WHERE temp.tedeptno = dept.deptno;
-- 2.查看工作地点在北京的员工有哪些
SELECT *
FROM temp INNER JOIN dept ON temp.tedeptno = dept.deptno
WHERE dept.loc ='北京';
-- 3.查看每个城市员工的平均工资
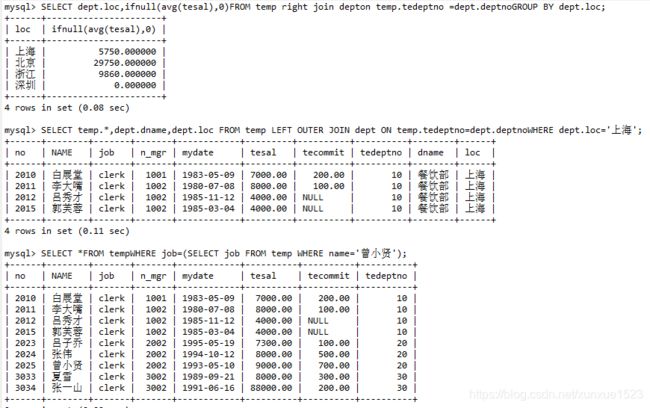
SELECT dept.loc,ifnull(avg(tesal),0)
FROM temp right join dept
on temp.tedeptno =dept.deptno
GROUP BY dept.loc;
-- 4.查看工作地点在上海的员工有哪些
SELECT temp.*,dept.dname,dept.loc
FROM temp LEFT OUTER JOIN dept ON temp.tedeptno=dept.deptno
WHERE dept.loc='上海';
-- 5.查找和曾小贤同职位的员工
SELECT *
FROM temp
WHERE job=(SELECT job FROM temp WHERE name='曾小贤');
-- 6.查找薪水比整个机构平均水平高的员工
SELECT *
FROM temp
WHERE tesal>(SELECT AVG(tesal) FROM temp);
-- 7.查询出部门中有clerk但职位不是clerk的员工的信息
SELECT *
FROM temp
WHERE tedeptno IN(SELECT DISTINCT tedeptno FROM temp WHERE job='clerk') AND job!='clerk';
-- 8.查看每个城市员工的平均工资'
SELECT dept.loc,AVG(tesal)
FROM temp INNER JOIN dept ON temp.tedeptno=dept.deptno GROUP BY dept.loc;
-- 9.查询出最低薪水高于部门20的最低薪水的部门信息
SELECT tedeptno,MIN(tesal) AS MIN_sal
FROM temp
GROUP BY tedeptno
HAVING min_sal>(SELECT MIN(tesal) FROM temp WHERE tedeptno=20);
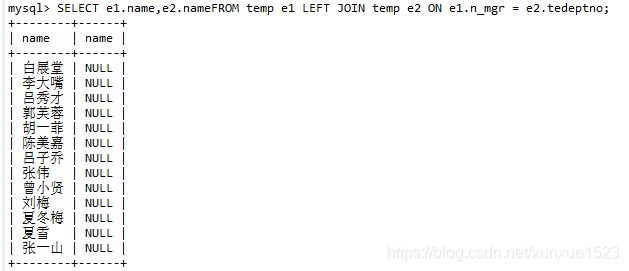
-- 10.列出所有员工的姓名及其直接上级的姓名
SELECT e1.name,e2.name
FROM temp e1
LEFT JOIN temp e2 ON e1.n_mgr = e2.tedeptno;
部分执行截图: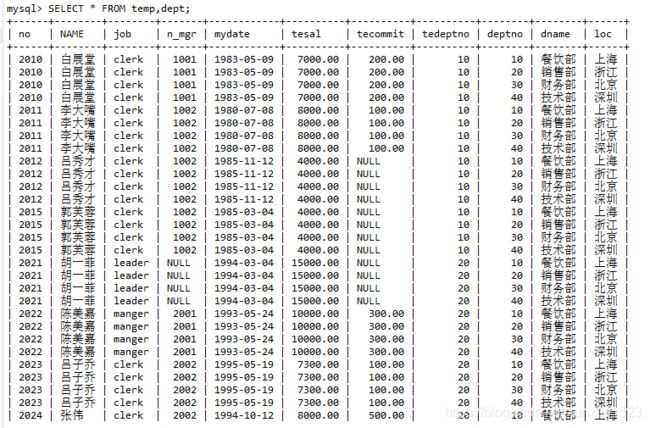
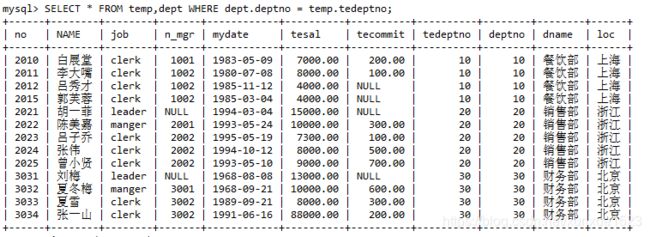




六、视图
视图是在MySQL5.1版本出现的新特性,它是一张虚拟表,和普通表一样的用法。但在几个特点的条件下,视图不支持更新,一般也不对视图进行更新。在物理空间中,只保存视图的SQL逻辑结构,而不保存具体的数据,在使用时,动态生成查询数据。应用场景:
- 多个地方用到同样的查询结果
- 查询语句较为复杂
视图创建
CREATE VIEW <视图名>
AS
<SELECT语句>
语法说明如下:
<视图名>:指定视图的名称。该名称在数据库中必须是唯一的,不能与其他表或视图同名。
视图修改
#方式一
CREATE OR REPLACE VIEW <视图名>
AS
<SELECT语句>
#方式二
ALTER VIEW <视图名>
AS
<SELECT语句>
视图删除
DROP VIEW <视图名>,<视图名>…;#支持同时删除多个视图