贪心算法总结(未完结)
贪心的定义(摘自百度百科)
贪心算法(greedy algorithm,又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解 。
贪心算法是以局部最优而达到全局最优,可以说贪心算法是短视的,每次只考虑当前状况下最好的选择。
贪心并没有通用的模板和算法思路,大多时候是靠刷题积累。
区间问题
AcWing 905. 区间选点

思路分析:
1. 按照右端点从小到大将区间排序
2. 依次从前往后枚举每个区间:
1 > 若当前区间能覆盖所选点,无需操作
2 > 若当前区间不能覆盖所选点,就选择当前区间的右端点作为新选的点,
同时答案要加一
代码展示:
#include
#include
using namespace std;
const int N = 100010;
struct Edge
{
int l, r;
bool operator < (const Edge &W)const
{
return r < W.r;
}
}edges[N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i ++)
{
int l, r;
cin >> l >> r;
edges[i] = {l, r};
}
sort(edges, edges + n);
int res = 0, ed = -2e9;
for (int i = 0; i < n; i ++)
{
if (edges[i].l > ed)
{
res ++;
ed = edges[i].r;
}
}
cout << res << endl;
return 0;
} AcWing 908. 最大不相交区间数量

代码展示:
#include
#include
using namespace std;
const int N = 100010;
struct Edge
{
int l, r;
bool operator <(const Edge &W)const
{
return r < W.r;
}
}edges[N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i ++)
{
int l, r;
cin >> l >> r;
edges[i] = {l, r};
}
sort(edges, edges + n);
int res = 0, ed = -2e9;
for (int i = 0; i < n; i ++)
{
if (edges[i].l > ed)
{
res ++;
ed = edges[i].r;
}
}
cout << res << endl;
return 0;
} AcWing 906. 区间分组

思路分析:
1. 区间按照左端点从小到大排序
2. 用小根堆去存储每组的右端点的最大值
3. 从前往后处理每一个区间:
1 > 若当前区间的左端点小于堆顶,说明当前区间与前面所有组都存在交集,
那么就开一个新的组去存储当前区间
2 > 若当前区间的左端点大于堆顶,说明当前区间和堆顶无交集,
则可以将当前区间添加到堆顶所在组中,
即要更新该组在小根堆中存储的右端点数值
代码展示:
#include
#include
#include
using namespace std;
const int N = 100010;
//按照区间左端点大小排序
struct Range
{
int l, r;
bool operator <(const Range &W)const
{
return l < W.l;
}
}edges[N];
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i ++)
{
int l, r;
cin >> l >> r;
edges[i] = {l, r};
}
sort(edges, edges + n);
priority_queue, greater> heap;
for (int i = 0; i < n; i ++)
{
//当前枚举的区间
auto t = edges[i];
//当堆中为空或者与堆顶元素有交集
if (heap.empty() || heap.top() >= t.l) heap.push(t.r);
else
{
heap.pop();
heap.push(t.r);
}
}
cout << heap.size() << endl;
return 0;
} AcWing 907. 区间覆盖

思路分析:
1. 区间按照左端点从小到大排序
2. 从前往后枚举每个区间(双指针算法)
每次选取能覆盖当前点st并且右端点最大的区间,然后更新st
代码展示:
#include
#include
using namespace std;
const int N = 100010;
struct Edge
{
int l, r;
bool operator <(const Edge &W)const
{
return l < W.l;
}
}edges[N];
int main()
{
int st, ed;
cin >> st >> ed;
int n;
cin >> n;
for (int i = 0; i < n; i ++)
{
int l, r;
cin >> l >> r;
edges[i] = {l, r};
}
sort(edges, edges + n);
int res = 0;
bool flag = false;
//找到能覆盖当前点的最靠右的区间,更新当前点
for (int i = 0; i < n; i ++)
{
int j = i, r = -2e9;
while (j < n && st >= edges[j].l)
{
r = max(r, edges[j].r);
j ++;
}
if (r < st)
{
res = -1;
break;
}
res ++;
if (r >= ed)
{
flag = true;
break;
}
st = r;
i = j - 1;
}
if (!flag) res = -1;
cout << res << endl;
return 0;
}
Huffman树
哈夫曼树定义(摘自百度百科)
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
哈夫曼树的构造
每次选取最小的两个数作为两个权值相加的节点的子节点,在将该节点与未选取的值再重复操作
以一个样例来模拟这个过程:

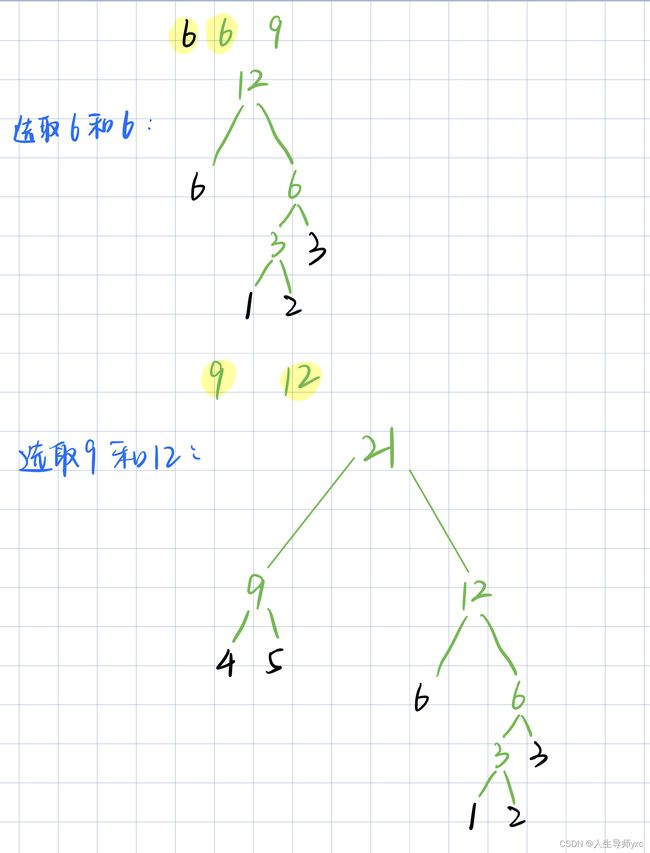
AcWing 148. 合并果子

思路分析:
用小根堆来存储权值,然后构造以哈夫曼树的思路得出最终结果
代码展示:
#include
#include
#include
using namespace std;
priority_queue, greater> heap;
int main()
{
int n;
cin >> n;
while (n --)
{
int x;
cin >> x;
heap.push(x);
}
int res = 0;
while (heap.size() > 1)
{
int a = heap.top();
heap.pop();
int b = heap.top();
heap.pop();
res += (a + b);
heap.push(a + b);
}
cout << res << endl;
return 0;
}