mysql数据库sql语句的总结笔记
简述: 区分四个基本概念
- 数据(Data) 是数据库中存储的基本对象,包括文字,数字,图像,视频等,是描述事物的符号记录。
- 数据库(Database,简称DB) 是长期储存在计算机内、有组织的、可共享的大量数据的集合。
- 数据库管理系统(Database management system,DBMS ),位于用户与操作系统之间的一层数据管理软件,是基础软件,是一个大型复杂的软件系统 。
- 数据库系统:在计算机系统中引入数据库后的系统,由数据库,数据库管理系统(及其应用开发工具),应用程序,数据库管理员 (DataBase Administrator, DBA)构成。
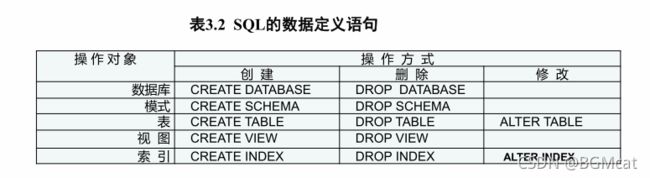
sql语句主要功能
功能包括数据定义、数据查询、数据操纵和数据控制。
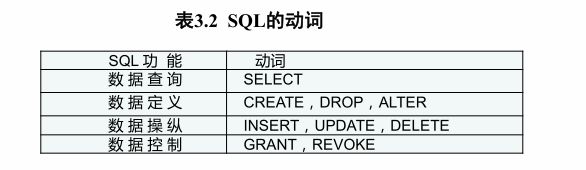
首先引入四张表:
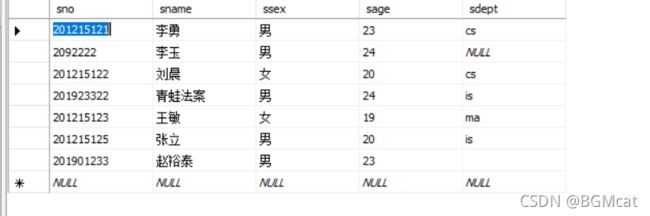
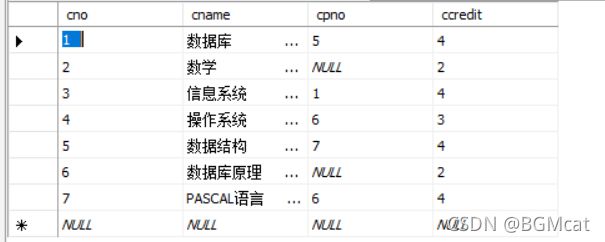
student 学生表
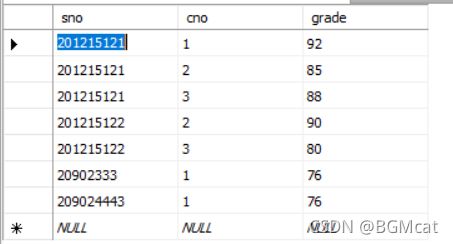
sc 学生成绩表
course 课程表
数据定义
数据库
创建数据库
#语法:CREATE DATABASE
CREATE DATABASE student
使用数据库
use student
删除数据库
drop database student
#不能删除当前数据库
模式
模式(架构): 模式是一个独立于数据库用户的非重复命名空间,在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等。您可以将模式视为数据库对象的容器。 一个数据库可以有多个模式,模式隶属于数据库。
定义模式
#语法:CREATE SCHEMA < 模式名> AUTHORIZATION < 用户名> [< 表定义> |< 视图定义>|< 授权定义>]
CREATE SCHEMA Test AUTHORIZATION ZHANG
CREATE TABLE student (Sno char(9) PRIMARY KEY,
Sname char(20),
Sage int )
#如果没有指定模式名,则模式名隐含为用户名
删除模式
#语法:DROP SCHEMA <模式名> 级联或限制
drop schema Test cascade
基本表
定义基本表
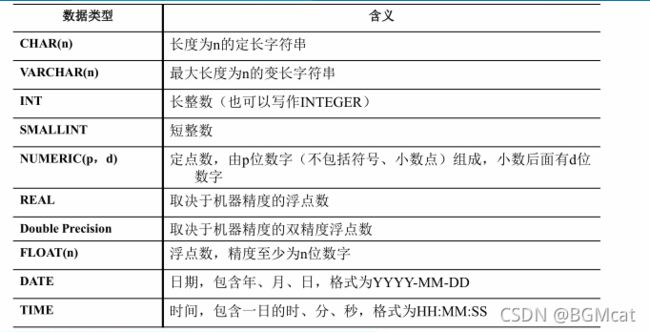
- 基本数据类型
- 常见完整性约束

#语法:CREATE TABLE <表名>
<列名> <数据类型> [ <列级完整性约束条件> ]
[,<列名> <数据类型> [ <列级完整性约束条件>] ] …
[,<表级完整性约束条件> ] );
CREATE TABLE SC
( Sno CHAR(9) NOT NULL,
Cno CHAR(4)
CONSTRAINT C1 NOT NULL, /*约束子句*/
Grade SMALLINT CHECK(Grade>=0 and Grade <=100),
PRIMARY KEY (Sno, Cno), /*在表级定义实体完整性*/
FOREIGN KEY (Sno) REFERENCES Student(Sno),
FOREIGN KEY (Cno) REFERENCES Course(Cno)
ON DELETE NO ACTION
/*当删除course 表中的元组造成了与SC表不一致时拒绝删除*/
ON UPDATE CASCADE
/*当更新course表中的cno时,级联更新SC表中相应的元组*/
);

修改基本表
#语法:ALTER TABLE <表名>
[ ADD [COLUMN]<新列名> <数据类型> [ 完整性约束 ] ]
[ ADD <表级完整性约束>]
[ DROP [COLUMN]<列名>[CASCADE|RESTRICT] ]
[ DROP CONSTRAINT<完整性约束名[CASCADE|RESTRICT] ]
[ ALTER COLUMN <列名> <数据类型> ];
ALTER TABLE Student ADD S_entrance DATE;
ALTER TABLE Student ALTER COLUMN Sage INT;
ALTER TABLE Course ADD UNIQUE(Cname);
#修改表中完整性约束 ,先删后加
ALTER TABLE Student
DROP CONSTRAINT C1;
ALTER TABLE Student
ADD CONSTRAINT C1 CHECK (Sno BETWEEN 900000 AND 999999),
删除基本表
#语法:DROP TABLE <表名>[RESTRICT| CASCADE];
DROP TABLE Student CASCADE;
索引
建立索引是加快查询速度的有效手段,
建立索引
- 建立聚簇索引后,基表中数据也需要按指定的聚簇属性值的升序或降序存放。也即聚簇索引的索引项顺序与表中记录的物理顺序一致,在一个基本表上最多只能建立一个聚簇索引
- 对某个列建立UNIQUE索引后,插入新记录时DBMS会自动检查新记录在该列上是否取了重复值。这相当于增加了一UNIQUE约束,对于已含重复值的属性列不能建UNIQUE索引
#语法:CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON
<表名>(<列名>[<次序>][,<列名>[<次序>] ]…); UNIQUE唯一索引,CLUSTER聚簇索引,ASC升序,DESC降序
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
修改索引
#语法:ALTER INDEX <旧索引名> RENAME TO <新索引名>
ALTER INDEX SCno RENAME TO SCSno;
删除索引
#语法:DROP INDEX <索引名>
DROP INDEX Student.Stusname
视图
视图:由一个或几个基本表(或视图)导出的表,是虚表,只存放表的定义,不会出现数据冗余,当基表数据发生变化,由视图查询的数据也会发生变化。
定义视图
#语法:CREATE VIEW < 视图名> [(< 列名> [ ,< 列名>]…)]
AS < 子查询>
[WITH CHECK OPTION];
CREATE VIEW IS_Student
AS
SELECT Sno, Sname, Sage
FROM student
WHERE Sdept= 'IS'
WITH CHECK OPTION
WITH CHECK OPTION:透过视图进行增删改操作时,不得破坏视图定义中的谓词条件(即子查询中的条件表达式),防止用户通过视图对不属于视图范围内的基本表数据进行更新
删除视图
#语法:DROP VIEW <视图名> [CASCADE];
查询视图
SELECT *
FROM S_G
WHERE Gavg>=90;
更新视图
转化为对基表进行更新
UPDATE IS_Student
SET Sname= '刘辰'
WHERE Sno= ' 201215122 ';
转换后的语句:
UPDATE student
SET Sname= '刘辰'
WHERE Sno= ' 201215122 ' AND Sdept = ‘IS’;
数据查询
基本语法
SELECT [ALL|DISTINCT]〈目标列表达式〉[,〈目标列表达式>] …
FROM 〈表名或视图名〉[,〈表名或视图名〉] …
[WHERE <条件表达式>]
[GROUP BY 〈列名〉[,〈列名〉]…
[HAVING <内部函数表达式>] ]
[ORDER BY 〈列名〉 [ASC│DESC] [,〈列名〉[ASC│DESC]]…]
WHERE子句作用于基表或视图,从中选择满足条件的元组
HAVING短语作用于组,从中选择满足条件的组。
单表查询
SELECT * FROM Student;
SELECT DISTINCT Sno FROM SC;
SELECT Sname, Ssex FROM Student WHERE Sdept NOT IN ('IS','MA’,'CS' );
SELECT Sname, Sno, Ssex
FROM Student
WHERE Sname NOT LIKE '刘%';
SELECT AVG(Grade)
FROM SC
WHERE Cno= ' 1 ';
SELECT Sno, AVG(Grade)
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90;
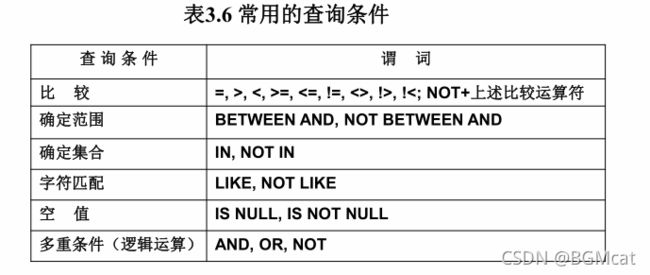
- 常用的查询条件
- 聚集函数

连接查询
等值与非等值连接查询
SELECT Student.*,SC.*
FROM Student,SC
WHERE Student.Sno = SC.Sno;
自身连接
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno = SECOND.Cno;
外连接复合条件查询
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC
ON Student.Sno = SC.Sno;
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST FULL OUTER JOIN Course SECOND
ON FIRST.Cpno = SECOND.Cno;
SELECT Student.Sno, student.Sname
FROM Student, SC
WHERE Student.Sno = SC.SnoAND /* 连接谓词*/
SC.Cno= ' 2 ' AND /* 其他限定条件 */
SC.Grade > 90; /* 其他限定条件 */
SELECT Student.Sno,Sname,Cname,Grade
FROM Student,SC,Course /* 多表连接*/
WHERE Student.Sno = SC.Sno
and SC.Cno = Course.Cno ;
嵌套查询

不相关子查询
SELECT Sname /*外层查询// 父查询*/
FROM Student
WHERE Sno IN
( (SELECT Sno /*内层查询// 子查询,不能使用order by 语句*/
FROM SC
WHERE Cno= ' 2 ' );
SELECT Sname,Sage
FROM Student
WHERE Sage < ANY
(SELECT Sage
FROM Student
WHERE Sdept= ' IS ')
AND Sdept <> ' IS ' ; /* 注 意这是父查询块中的条件 */
相关子查询
SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC /*相关子查询*/
WHERE Sno=Student.SnoAND Cno= '1')
集合查询

SELECT *
FROM Student
WHERE Sdept= 'CS'
UNION
SELECT *
FROM Student
WHERE Sage<=19;
#等价于:
SELECT DISTINCT *
FROM Student
WHERE Sdept= 'CS' OR Sage<=19;
ORDER BY子句只能用于对最终查询结果排序,不能对中间结果排序
任何情况下,ORDER BY子句只能出现在最后
数据操纵
数据插入
#语法:INSERT
INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>] … )
INSERT INTO Student (Sno, Sname, Ssex, Sdept, Sage)
VALUES ('201215128','陈冬','男','IS',18);
#语法:INSERT INTO <表名> [(<属性列1>[,<属性列2 >…)]
子查询
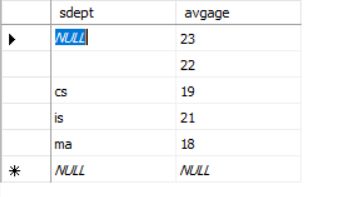
INSERT INTO Deptage(Sdept,Avgage)
SELECT Sdept,AVG(Sage) /**子查询*/
FROM Student
GROUP BY Sdept;
数据修改
#语法:UPDATE < 表名>
SET < 列名>=< 表达式>[ ,< 列名>=< 表达式>]…
[WHERE < 条件>];
UPDATE Student
SET Sage = 22
WHERE Sno=' 201215121 ';
UPDATE Student
SET Sage= Sage+1;
数据删除
#语法:DELETE
FROM < 表名>
[WHERE < 条件>];
DELETE
FROM Student
WHERE Sno=' 201215128 ';
数据控制
创建登录名
#语法:CREATE LOGIN <登录名>
[ {
WITH PASSWORD = ‘’ [HASHED][MUSTCHANGE]
,DEFAULT_DATABASE = <数据库>
} |
{
FROM
WINDOWS
[WITH DEFAULT_DATABASE = <数据库>]
|CERTIFICATE <证书名>
|ASYMMETRIC KEY <不对称密钥名>
}
]
#创建一个sql server验证模式的登录名
CREATE LOGIN Zhangsan
WITH PASSWORD = ‘abc123!’
# 创建一个windows验证模式的登录名
CREATE LOGIN [win2k3\Administrator]
FROM WINDOWS
创建用户
#语法:CREATE USER <用户名>
[ {{FOR | FROM}
LOGIN <登录名>
| CERTFICATE <证书名>
| ASYMMETERIC KEY <密钥名>
}
[WITHOUT LOGIN]
[WITH DEFAULT_SCHEMA = <架构名>]
] [WITH][DBA|RESOURCE|CONNECT];
CREATE USER dbUser1 FOR LOGIN zhangsan
WITH DEFAULT_SCHEMA = student;
存取控制对象

权限
授予权限
WITH GRANT OPTION子句,指定时可以在授权
不允许循环授权
#语法:GRANT语句的一般格式:
GRANT <权限>[,<权限>]...
ON <对象类型> <对象名>[,<对象类型> <对象名>]…
TO <用户>[,<用户>]...
[WITH GRANT OPTION];
GRANT SELECT
ON SC
TO PUBLIC;
GRANT UPDATE(Sno), SELECT
ON Student
TO U4
WITH GRANT OPTION;
#传播权限
GRANT SELECT
ON Student
TO U7;
回收权限
#语法:REVOKE <权限>[,<权限>]...
ON <对象类型> <对象名>[,<对象类型><对象名>]…
FROM <用户>[,<用户>]...[CASCADE | RESTRICT];
REVOKE UPDATE(Sno)
ON Student
FROM U4;
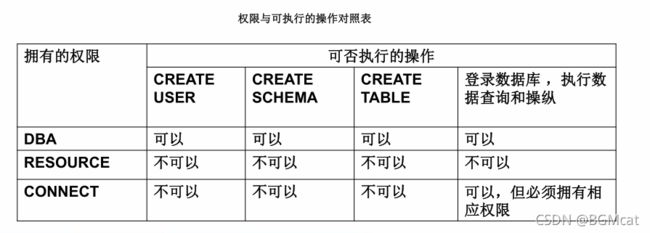
角色
角色是权限的集合,可以为一组具有相同权限的用户创建一个角色,简化授权过程
创建角色
#语法:CREATE ROLE <角色名>
CREATE ROLE R1
角色授权
#语法:
GRANT <权限>[,<权限>]…
ON <对象类型>对象名
TO <角色>[,<角色>]…
GRANT SELECT, UPDATE, INSERT
ON Student
TO R1;
#将一个角色授予其他的角色或用户
#语法:GRANT <角色1>[,<角色2>]…
TO <角色3>[,<用户1>]…
[WITH ADMIN OPTION]
GRANT R1
TO U1,U2,U3;
角色权限回收
#语法:REVOKE <权限>[,<权限>]…
ON <对象类型> <对象名>
FROM <角色>[,<角色>]…
REVOKE R1
FROM U1;
审计
审计:将用户对数据库的操作记录
设置审计
#语法:UDIT ALTER,UPDATE ON SC;
取消审计
#语法:NOAUDIT ALTER,UPDATE ON SC;
T-SQL编程
是SQL SERVER专用标准结构化查询语言增强版,提供了标准的SQL和DDL 和DML功能,加上延伸的函数,系统预存程序以及程序设计结构让程序设计更具有弹性。
- 标识符:字母或_、@、#开头的字母数字或_、@、$序列,不与保留字相同,长度小于128,不符合规则的标识符必须加以界定(双引号””或方括号[])
- 注释语句:单行注释 --,多行注释 /**/
局部变量:
局部变量是用户定义,必须以@开头,在程序内声明,并只能在该程序内使用
全局变量是SQL Server系统内部使用的变量,以@@开头,全局变量不是由用户的程序定义的,它们是在服务器级定义的.
#语法-声明:
DECLARE @<局部变量名> <数据类型>[,…n]
DECLARE @myvar char(20),@a int
#语法-赋值:
SET|SELECT @<局部变量名>=<表达式>
SELECT @a=1,@b=2
SET @var1 = getdate()
if-else选择结构
#语法:IF <布尔表达式>
|<语句块>
[ELSE
|<语句块>]
IF EXISTS( SELECT * FROM STUDENT WHERE SNO = ‘201215120’)
BEGIN
SELECT *
FROM STUDENT
WHERE SNO = ‘201215120’
END
ELSE
PRINT ‘没找到!’
case选择结构
#语法:CASE 表达式
WHEN 表达式的值1 THEN 返回表达式1
WHEN 表达式的值2 THEN 返回表达式2
…
ELSE 返回表达式n
END
SELECT SNO,SSEX=
CASE SSEX
WHEN ‘男’ THEN ‘M’
WHEN ‘女’ THEN ‘F’
END
FROM STUDENT
while循环结构
#语法:WHILE 逻辑表达式
Begin
T-SQL语句组
[break]/*终止整个语句的执行*/
[continue]/*结束一次循环体的执行*/
END
DECLARE @X int, @sum int
SET @X=0
SET @sum = 0
WHILE @x<10
BEGIN
SET @X=@X+1
SET @sum = @sum + @X
PRINT ‘sum='+convert(char(2),@sum) --类型转换函数convert
END
等待语句
#语法:WAITFOR DELAY '<时间间隔>‘ | TIME '<时间>'
BEGIN
WAITFOR DELAY '1:00:00’
SELECT * FROM s
END
BEGIN
WAITFOR TIME '10:00:00'
SELECT * FROM s
END
时间和日期函数
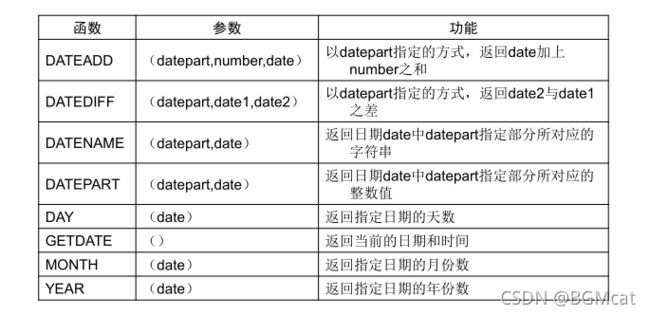
字符串函数



数据类型转换函数

游标
游标是一种能从包括多条数据记录的结果集中每次提取一条记录的机制,类似于视图执行后的结果
声明游标
#语法:
DECLARE < 游标名> [INSENSITIVE] [SCROLL]
CURSOR
FOR Insensitive 指定游标只对基本表的副本操作,游标的任何操作不对基本表产生影响
Scroll 指定游标推进方向( FIRST、LAST、PRIOR、NEXT、RELATIVE、ABSOLUTE)均可用,否则只有next可用
打开游标
#语法:OPEN < 游标名>
open num_cursor;
使用游标

#语法:FETCH
[[NEXT|PRIOR|FIRST|LAST|ABSOLUTE {n|@nvar}
|RELATIVE {n|@nvar}]
FROM ]
{{[GLOBAL] < 游标名>}|<@ 游标变量>}
[INTO @< 变量名>[,...n]]
declare num_cursor cursor --声明
for select sno from student
for READ ONLY
Open num_cursor; --打开
declare @sno varchar(10),@num int --声明变量
set @num = 0
fetch next from num_cursor --取信息
into @sno
while @@fetch_status = 0 --检测状态
begin
if not exists(select *
from sc
where sno = @sno)
set @num = @num + 1
fetch next from num_cursor
into @sno
end
select @num 未选课人数
CLOSE num_cursor
DEALLOCATE num_cursor
关闭游标
#语法: CLOSE [GLOBAL] < 游标名>|@< 游标变量>
释放游标
#语法:DEALLOCATE [GLOBAL] <游标名>|@<游标变量>
存储过程
存储过程(Stored Procedure)是一组完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行存储过程
创建存储过程
#语法:CREATE { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameter data_type } [ = default ] [ OUTPUT ] ] [ ,...n ]
AS
create proc myproc
as
select * from student
create proc proc_sum
@department char(9),
@p_num int out
as
begin
select @p_num=count(*)
from student
where department=@department
end
执行存储过程
#语法:EXEC|EXECUTE [ @return_status = ] [schema_name.]procedure_name
[[@parameter =] {value | @variable [OUTPUT] | [ DEFAULT ]}][ ,...n ]
exec myproc 16 @pare out
修改存储过程
#语法:ALTER { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameter data_type } [ = default ] [ OUTPUT ] ] [ ,...n ]
AS
alter proc myproc
@sage int,
@savg float out
as
select AVG(sage) from student where sdept = 'CS'
删除存储过程
#语法:drop procedure {procedure_name}[,…n]
自定义函数
标量函数
#语法:CREATE FUNCTION [ schema_name.] function_name
([{ @parameter_name [ AS ] data_type [ = default ] } [ ,...n ]])
RETURNS return_data_type
[ WITH | [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
自定义日期函数
#语法:CREATE FUNCTION dbo.DateOnly(@date datetime)
RETURNS VARCHAR(12)
AS
BEGIN
RETURN CONVERT(VARCHAR(12),@DATE,101)
END
CREATE FUNCTION whichgeneration(@birthday datetime)
RETURNS VARCHAR(12)
AS
BEGIN
if year(@birthday)<1980
return “too old”;
else if year(@birthday)<1990
return “80s”;
else
return “90s”;
END
内嵌表值函数
#语法:CREATE FUNCTION [ schema_name. ] function_name
([{ @parameter_name data_type [ = default ] } [ ,...n ]])
RETURNS TABLE
[ WITH [ ,...n ] ]
[ AS ]
RETURN ( select_stmt )
CREATE FUNCTION dbo.Fun1()
RETURNS table
AS
RETURN
SELECT SNO,SNAME
FROM STUDENT
多语句表值函数
#语法:
CREATE FUNCTION [ schema_name. ] function_name
([{@parameter_name data_type [ = default ] } [ ,...n ]])
RETURNS @return_variable TABLE < table_type_definition >
[ WITH [ ,...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
CREATE FUNCTION fn_salary ( @bm char(2) )
RETURNS @salary table
(姓名 varchar(10),部门名称 varchar(10),工资 numeric(8,2))
as
begin
insert @salary
select a.姓名,b.部门名称,a.工资
from test a left join bm b on a.部门=b.部门 and a.部门=@bm
return
end
视图,存储过程,自定义函数的区别

触发器
触发器(Trigger)是用户定义在关系表上的一类由事件驱动的特殊过程,是一种特殊的存储过程,它在执行事件时自动生效。SQL Server2008 包括两大类触发器:DML 触发器和 DDL 触发器。
DML触发器
DML 触发器在数据库中发生数据操作语言 (DML) 事件时将启用。DML 事件包括在指定表或视图中修改数据的 INSERT 语句、UPDATE 语句或 DELETE 语句。DML 触发器可以查询其他表,还可以包含复杂的 Transact-SQL 语句。将触发器和触发它的语句作为可在触发器内回滚的单个事务对待。如果检测到错误(例如,磁盘空间不足),则整个事务即自动回滚

执行过程

创建DML触发器
#语法:CREATE TRIGGER [ schema_name . ]trigger_name
ON { table | view }
[ WITH ENCRYPTION ]
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
[ NOT FOR REPLICATION ]
AS
begin sql_statement [ ; ] end
使用insert触发器
CREATE TRIGGER tr_sc_insert ON sc
FOR INSERT
AS
BEGIN
DECLARE @bh char(10)
Select @bh=Inserted.sno from Inserted
If not exists(select sno from student where student.sno=@bh)
Delete from sc where sno=@bh
END
CREATE TRIGGER tr_sc_grade
ON sc
AFTER INSERT,UPDATE
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
DECLARE @score int;
SELECT @score=inserted.grade from inserted
IF (@score<0 or @score > 100)
BEGIN
RAISERROR ('成绩的取值必须在0到100之间', 16, 1)
ROLLBACK TRANSACTION
END
END
使用UPDATE触发器
CREATE TRIGGER tr_student_sno ON student
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
if update(sno)
begin
raiserror('不能修改学号',16,10)
rollback transaction
end
END
使用DELETE触发器
CREATE TRIGGER tr_student_delete
ON sc
AFTER DELETE
AS
BEGIN
SET NOCOUNT ON;
insert into s1 select * from deleted
END
CREATE TRIGGER tr_student_sc_delete
ON student
AFTER DELETE
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sno char(10)
Select @sno=deleted.sno from deleted
Delete from sc where sno=@sno
END
instead of 触发器
CREATE TRIGGER tr_student_instead
ON student
instead of DELETE
AS
BEGIN
SET NOCOUNT ON;
delete from sc
where sno in ( select deleted.sno from deleted )
delete from student
where sno in ( select deleted.sno from deleted )
END
DLL触发器
DDL 触发器是 SQL Server 2008 的新增功能。当服务器或数据库中发生数据定义语言(DDL) 事件时将调用这些触发器
显式定义事务
事务是数据库操作序列,恢复和并发控制的基本单位,一个事务可以是一条或多条SQL语句,也可以是一个或多个程序。
#语法:BEGIN TRANSACTION
SQL 语句1
SQL 语句2
……
COMMIT
#语法:BEGIN TRANSACTION
SQL 语句1
SQL 语句2
……
ROLLBACK
begin transaction
update student
set sdept='CS’
where sno='201215125'
commit