linux系统调用
一、系统编程概述
操作系统的职责:操作系统用来管理所有的资源,并将不同的设备和不同的程序关联起来。
Linux系统编程:在有操作系统的环境下编程,并使用操作系统提供的系统调用及各种库,对系统资源进行访问。系统编程主要就是为了让用户能够更好和更方便的操作硬件设备,并且对硬件设备也起到保护作用,我们所写的程序,本质就是对硬件设备的操作,所以操作系统提供接口可以对硬件进行操作,这就是系统编程。
二、系统调用概述

本质都是要对硬件设备进行操作,但是linux操作系统在硬件之上设置了内核,也就是只有内核才可以直接操作硬件设备,如果想操作内核,需要调用内核的系统调用,如果要操作内核中的系统调用,有三种方式:
第一种:shell,用户通过shell命令(ls、pwd等),被shell解释器解释后传给内核然后进行操作内核的系统调用。
第二种:库函数,用户通过应用层库函数的接口,比如fread、fwrite等函数对内核的系统调用进行操作。
第三种:应用层系统调用,它可以直接对内核的系统调用进行操作。比如read、write等函数。
系统调用是操作系统提供给用户程序的一组“特殊”函数接口,Linux的不同版本提供了两三百个系统调用。用户程序可以通过这组接口获得操作系统(内核)提供的服务。

系统调用按照功能逻辑大致可分为:
进程控制、进程间通信、文件系统控制、系统控制、内存管理、网络管理、socket控制、用户管理。
系统调用的返回值:
通常,用一个负的返回值来表明错误,返回一个0值表明成功。错误信息存放在全局变量errno中,用户可用perror函数打印出错信息。
三、系统调用I/O函数
3.1 文件描述符
文件描述符是非负整数。打开现存文件或新建文件时,系统(内核)会返回一个文件描述符。文件描述符用来指定已打开的文件。
在系统调用(文件IO)中,文件描文述符对件起到标识作用,如果要操作文件,就是对文件描述符的操作。
当一个程序运行或者一个进程开启时,系统会自动创建三个文件描述符:
0 标准输入
1 标准输出
2 标准输出出错
系统中也可以使用一些宏
#define STDIN_FILENO 0 //标准输入的文件描述符 #define STDOUT_FILENO 1 //标准输出的文件描述符 #define STDERR_FILENO 2 //标准错误的文件描述符
文件IO的文件描述符和标准IO的文件指针的对应关系:
文件IO 标准IO
0 stdin
1 stdout
2 stderr
如果自己打开文件,会返回文件描述符,而文件描述符一般按照从小到大依次创建的顺序。
3.2 open函数
打开一个文件:
#include
#include
#include
当文件存在时使用:
int open(const char *pathname, int flags);
当文件不存在时使用:
int open(const char *pathname, int flags, mode_t mode);
参数:
pathname:文件的路径及文件名。
flags:open 函数的行为标志。
mode:文件权限(可读、可写、可执行)的设置。
返回值:
成功返回打开的文件描述符。
失败返回-1,可以利用 perror 去查看原因。 3.2.1案例



flags的取值是取决于该文件已经存在的情况下,打开时的权限,如果不存在则作废,创建新的文件需要通过mode值进行新创建的文件权限的设置。
grep -nr “ 想要查找的宏定义”,可以查看宏定义的值
3.2.2文件IO和标准IO对比
 3.2.3函数调用出错后输出错误信息
3.2.3函数调用出错后输出错误信息
第一种:
通过全局变量 errno可显示错误码
要加上头文件#include
errno是一个全局变量,当函数调用失败后,可以通过errno获取错误码
第二种:
通过一个函数 perror
要加上头文件#include
void perror(const char *s);
功能:输出函数调用失败的错误信息
参数:
s:打印错误信息的提示消息
返回值:无
案例:
#include
#include
#include
#include
#include
int main(int argc, char const *argv[])
{
//使用open函数打开或者创建一个文件
int fd;
fd = open("file.txt", O_RDONLY);
if(fd == ‐1)
{
//通过全局变量errno打印错误码
//注意需要添加头文件errno.h
//printf("errno = %d\n", errno);
//通过perror函数输出函数调用失败的错误信息
perror("fail to open");
return ‐1;
}
printf("fd = %d\n", fd);
return 0;
} 执行结果:
perror对应的执行结果:

errno对应的执行结果:
![]()
部分错误码对照表(需要进入图中的文件目录):

3.3 close函数
#include (注意别忘记头文件)
int close(int fd);
功能:关闭一个文件描述符
参数:
fd:指定文件的文件描述符,open函数的返回值
返回值:
成功:0
失败:‐1 3.3.1案例
#include
#include
#include
#include
#include
int main(int argc, char const *argv[])
{
int fd;
fd = open("file.txt", O_RDONLY);
if(fd == ‐1)
{
perror("fail to open");
return ‐1;
}
printf("fd = %d\n", fd);
//当不对文件进行任何操作时,就会关闭文件描述符
//使用close函数关闭文件描述符
//一旦关闭了文件描述符,就不能再通过原有的文件描述符对文件进行操作
close(fd);
return 0;
} 3.3.2 文件描述符的相关问题
#include
#include
#include
#include
#include
int main(int argc, char const *argv[])
{
//测试1:一个进程(一个程序的运行)创建的文件描述符的个数
//一个程序运行的时候最多可以创建2014个文件描述符,0~1023
#if 0
int fd;
while (1)
{
fd = open("file.txt", O_RDONLY | O_CREAT, 0664);
if(fd == ‐1)
{
perror("fail to open");
return ‐1;
}
printf("fd = %d\n", fd);
}
#endif
//测试2:文件描述符值的规律
//文件描述符按照从小到大的顺序依次创建
//如果中途有文件描述符被关闭了,则再创建的文件描述符会先补齐之前的,然后依次递增创建
//注意:不要认为最后创建的文件描述符一定是最大的
#if 1
int fd1, fd2, fd3, fd4;
fd1 = open("test.txt", O_RDONLY | O_CREAT, 0664);
fd2 = open("test.txt", O_RDONLY | O_CREAT, 0664);
fd3 = open("test.txt", O_RDONLY | O_CREAT, 0664);
fd4 = open("test.txt", O_RDONLY | O_CREAT, 0664);
printf("fd1 = %d\n", fd1);
printf("fd2 = %d\n", fd2);
printf("fd3 = %d\n", fd3);
printf("fd4 = %d\n", fd4);
close(fd2);
int fd5, fd6;
fd5 = open("test.txt", O_RDONLY | O_CREAT, 0664);
fd6 = open("test.txt", O_RDONLY | O_CREAT, 0664);
printf("fd5 = %d\n", fd5);
printf("fd6 = %d\n", fd6);
#endif
return 0;
} 执行结果:
测试一:

测试二:

3.4 write函数
#include
ssize_t write(int fd, const void *buf, size_t count);
功能:向文件写入数据
参数:
fd:指定的文件描述符
buf:要写入的数据首地址
count:要写入的数据的长度
返回值:
成功:实际写入的字节数
失败:‐1 我们在write之后并没有直接read,那是因为read需要文件内的,光标在我们所要读取的内容之前(这里为文件的头部),而write后的光标总是在文件的尾部,所以直接在write之后读取的话,不会读取到内容,返回值为0。但是当打开一个文件时,光标位置在文件首部,此时写入write会覆盖掉文件本身的内容。但是先关闭文件(close)再打开文件(open)后,光标就在文件的头部,这样才能正确的读取。但是这个操作光标的方法不仅土得掉渣,还不灵活,这就需要光标操作函数 lseek()。
off_t lseek(int fd, off_t offset, int whence);光标的偏移量
fd : 文件描述符
Offffset :偏移量
Whence :
SEEK_SET: 参数offffset即为新的读写位置
SEEK_CUR: 以目前的读写位置往后增加offffset个偏移量
SEEK_END: 将读写位置指向文件尾后再增加offffset个位移量,当whence值为SEEK_CUR或SEEK_END时,
参数offffset允许负值的出现。
返回值: 文件读写距离文件开头的字节大小,出错返回 -13.4.1 向终端写入数据

执行结果:

3.4.2 向文件写入数据


执行结果:

3.5 read函数
#include
ssize_t read(int fd, void *buf, size_t count);
功能:从文件中读取数据
参数:
fd:指定的文件描述符
buf:保存读取到的数据(开辟内存的首地址)
count:最大一次读取多少个字节
返回值:
成功:实际读取的字节数
失败:‐1
注意:如果读取到文件末尾,返回0 3.5.1 从终端中读取数据


执行结果:


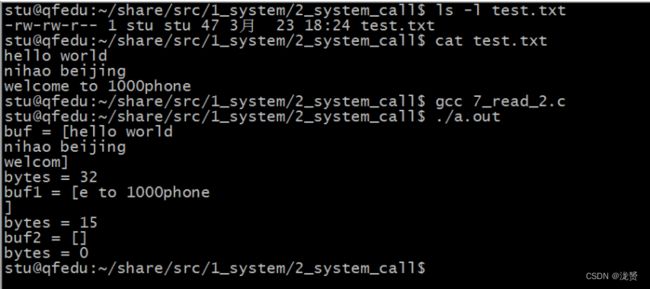
3.5.2 从文件中读取数据




执行结果:
3.6 remove函数
#include
int remove(const char *pathname);
功能:删除指定文件
参数:
pathname:包含路径的文件名
返回值:
成功返回0。
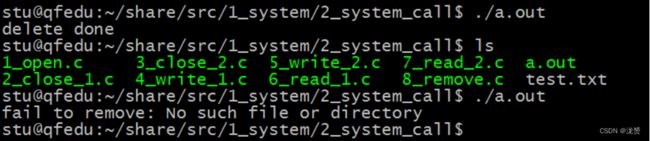
失败返回‐1 案例:


执行结果:
四、系统调用和库函数
库函数由两类函数组成:
(1)不需要调用系统调用:不需要切换到内核空间即可完成函数全部功能,并且将结果反馈给应用程序,如strcpy、bzero等字符串操作函数。
(2)需要调用系统调用需要切换到内核空间,这类函数通过封装系统调用去实现相应功能,如printf、fread等。
库函数与系统调用的关系:

系统提供的很多功能都必须通过系统调用才能实现。
系统调用是需要时间的,程序中频繁的使用系统调用会降低程序的运行效率
原因:当运行内核代码时,CPU工作在内核态,在系统调用发生前需要保存用户态的栈和内存环境,然后转入内核态工作。系统调用结束后,又要切换回用户态。这种环境的切换会消耗掉许多时间。
库函数访问文件的时候根据需要,设置不同类型的缓冲区(相当于先排好队,不是一次次的进入系统调用,而是全部排好队之后在统一进入系统调用),从而减少了直接调用IO系统调用的次数,提高了访问效率。
总结:大多数库函数的本质也是系统调用,只不过库函数有了缓冲区,用于减少系统调用的次数。