【Python从入门到进阶】40、requests的基本使用
接上篇《39、使用Selenium自动验证滑块登录》
上一篇我们介绍了使用selenium进行滑块自动验证操作。本篇我们结束selenium的章节,来学习requests库的基本使用。
一、requests与urllib的爱恨情仇
1、requests与urllib的区别
大家在前面的学习中,访问网络服务基本上一直使用的都是urllib库,而这个requests库和urllib库的作用十分相似,都是用于发送HTTP请求、读取和解析网页内容等场景,但是他们也有一些本质上的区别:
(1)易用性
requests库更加简洁和易于使用。它提供了简单而直观的API,使得发送HTTP请求变得非常简单。相比之下,urllib库的接口相对复杂,需要编写更多的代码来完成同样的任务。
(2)功能丰富
requests库提供了许多高级功能,如会话管理、身份验证、文件上传、Cookie处理等。它还支持自动解析JSON响应和处理常见的HTTP错误。相比之下,urllib库的功能较为基础,需要手动实现这些功能。
(3)性能
从性能角度看,urllib库在某些情况下可能更快,因为它是Python标准库的一部分,而requests库是一个第三方库。然而,在大多数情况下,这种差异不太明显,因为它们底层都使用了相似的机制。
总的来说,如果你想要一个简单易用、功能强大的HTTP库,推荐使用requests。如果你只需要处理一些基本的HTTP请求,并且不想依赖第三方库,那么urllib也是一个可以考虑的选择。
2、为什么推荐使用requests而不是urllib
除了上面提到的requests的“易用性”和“功能丰富”特点外,还拥有以下优点:
(1)更好的可读性
requests的代码可读性更强,因为它使用了基于对象的方式来构建请求和处理响应。与之相比,urllib使用了一些较低级别的函数和参数,可能会导致代码更加冗长和难以理解。
(2)活跃的社区支持
requests是一个非常流行的Python库,拥有庞大而活跃的社区。这意味着你可以很容易地找到关于requests的文档、教程和示例,并且可以获得及时的支持和更新。
(3)兼容性和稳定性
requests经过广泛的测试和使用,已被证明在各种环境和情况下都很稳定。相比之下,urllib在一些特殊情况下可能会存在一些问题。
尽管urllib是Python的标准库,但由于requests提供了更好的易用性、功能和可读性,因此大多数开发者更倾向于使用requests来发送HTTP请求。
二、requests安装和导入
1、相关文档
requests库官方文档:http://cn.python-requests.org/zh_CN/latest/
requests库快速上手:http://cn.python-requests.org/zh_CN/latest/user/quickstart.html
2、安装和导入requests库
在开始使用requests库之前,首先需要确保它已经安装在你的Python环境中。你可以通过以下步骤完成安装:
(1)打开命令行终端。
(2)运行以下命令来安装requests库:
pip install requests这将会从Python包管理器(pip)中下载并安装最新版本的requests库。
一旦requests库安装完成,我们就可以在Python脚本中导入它。使用import语句来导入requests模块:
import requests然后我们就可以在脚本中使用requests库的功能来发送HTTP请求了。
三、requests库常见语法
以下是 requests 库的一些常见语法:
1、发送GET请求语法
response = requests.get(url, params=params, headers=headers)其中,url是请求的目标URL,params是一个可选参数,用于指定查询字符串参数,headers是一个可选参数,用于设置请求头。
2、发送POST请求语法
response = requests.post(url, data=data, json=json_data, headers=headers)其中,url是请求的目标URL,data是一个字典或字符串,用于作为请求体发送数据,json是一个字典或JSON字符串,会被自动转换为JSON格式并作为请求体发送,headers是一个可选参数,用于设置请求头。
3、获取响应内容
content = response.text使用text属性可以获取响应的文本内容。
4、获取响应状态码
status_code = response.status_code使用status_code属性可以获取响应的状态码。
5、设置响应的编码格式
response = requests.get(url)
response.encoding='utf-8' # 设置响应内容的编码格式为utf-8一般我们的响应内容中包含中文的话,获取text之前就需要设置编码。
5、处理异常情况
try:
response = requests.get(url)
response.raise_for_status() # 检查是否有错误发生
except requests.exceptions.RequestException as e:
print("请求发生异常:", e)使用raise_for_status()方法可以检查是否有错误发生,并抛出适当的异常。
上面只是requests库的一小部分语法示例,还有更多功能和选项可用。大家可以通过阅读官方文档来了解更多详细信息:https://docs.python-requests.org/en/latest/
四、发送get及post请求示例
1、发送GET请求示例
使用requests.get()函数可以发送简单的GET请求。下面是一个发送GET请求并处理响应的基本示例:
import requests
# 发送GET请求
response = requests.get("http://www.baidu.com/s?wd=河南")
# 检查请求是否成功
if response.status_code == 200:
# 处理响应内容
response.encoding = 'utf-8' # 设置响应内容的编码格式为utf-8
data = response.text # 获取http响应信息
print(data)
else:
print("请求失败:", response.status_code)在上述示例中,我们使用URL"http://www.baidu.com/s?wd=河南"发送了一个GET请求。requests.get()函数返回一个响应对象,我们可以通过response来访问响应的各种属性和方法。在这个示例中,我们检查状态码是否为200(表示成功),然后解析响应的html内容并打印出来(如果结果有中文,则需要设置编码格式)。
效果: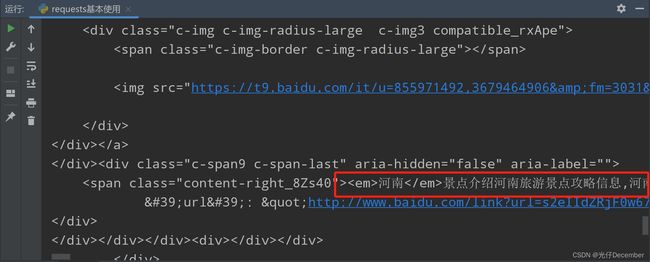
2、发送POST请求示例
有时候需要向服务器发送包含数据的POST请求。requests.post()函数可用于发送包含数据的POST请求。下面是一个发送POST请求的基本示例:
注:这是一个百度翻译的post请求,去翻译apple的中文含义。具体的headers中参数的设置方法,详见之前我们讲解urllib翻译中文的博文《【Python从入门到进阶】23.urllib使用post请求百度翻译》
import requests
import json
url = "https://fanyi.baidu.com/v2transapi?from=en&to=zh"
headers = {
'User-Agents': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=9ACAA09E33A14A90B3A1F09AF6429144; PSTM=1680336365; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; FANYI_WORD_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=DBuTGxTUkoxV0xlM0paSUlGRXZKSEl2U2FhQnI1c2YwdjdiZGJja04wOG9hTDVrRVFBQUFBJCQAAAAAAQAAAAEAAABzBe8oZ2xkenN3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACjblmQo25Zkb; BDUSS_BFESS=DBuTGxTUkoxV0xlM0paSUlGRXZKSEl2U2FhQnI1c2YwdjdiZGJja04wOG9hTDVrRVFBQUFBJCQAAAAAAQAAAAEAAABzBe8oZ2xkenN3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACjblmQo25Zkb; BAIDUID=C99AB112566ED56877EDCE374CBC55F5:FG=1; APPGUIDE_10_6_2=1; APPGUIDE_10_6_5=1; MCITY=-268%3A; BAIDUID_BFESS=C99AB112566ED56877EDCE374CBC55F5:FG=1; ZFY=bDrEaCX7:Ap0QdmZc6J3:Amu1ai6lctzuDpYDD2B3BlIY:C; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; RT="z=1&dm=baidu.com&si=eepethtdr6b&ss=lo5prtua&sl=4&tt=1io&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=3ge&cl=2zz&ul=c0a&hd=c0w"; BA_HECTOR=al2gah0k8g0g0g8l0l0181831ijnivp1q; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=1; H_PS_PSSID=39322_39396_39531_39419_39541_39498_39551_39461_39234_39467_26350_39563_39427; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1698461891; APPGUIDE_10_6_6=1; BDRCVFR[BASDVugcKF6]=IdAnGome-nsnWnYPi4WUvY; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1698462793; ab_sr=1.0.1_OWFjMjI3MmMwNzFhNmVmN2NiZTUyNGVmOGQwNzNlODYzOGE5OGQxNzQ2NzMwYTg2ZmI0NDkzYWE5MzViNzY5MWNlMzJjMzczMGMxOGRlMzY2MWVjYmJlOTI2NTExYjNkMDgxMGQyNDNjZmNiY2U4ZTc1MWVkNmRhYjNjZTM4NDVhMDFiN2YwNWJjYzE5ZDBlMmM2MTUyZTZhMjMyZjdhY2RkODA0MWViZTYxMWJhYmI3ZDc1MGNmZjU0MmUyODBl'
}
data = {
'from': 'en', # 要翻译的语言(英文)
'to': 'zh', # 翻译后的语言(中文)
'query': 'apple', # 要翻译的内容
'transtype': 'realtime', # 翻译类型
'simple_means_flag': 3, # 简单均值标志
'sign': 704513.926512, # 签名
'token':'507133edd1b6a9929fae99c7f9ca28f2', # 令牌
'domain': 'common', # 领域:公共部分
'ts': 1698462967794 # 时间戳
}
# 发送POST请求-百度翻译
response = requests.post(url=url, headers=headers, data=data)
# 检查请求是否成功
if response.status_code == 200:
# 处理响应内容
response.encoding = 'utf-8' # 设置响应内容的编码格式为utf-8
data = response.text # 获取响应信息
jsonObj = json.loads(data)
print(jsonObj)
else:
print("请求失败:", response.status_code)在上述示例中,我们使用requests.post()函数发送了一个包含数据的POST请求。我们将数据存储在一个字典中,并通过data参数传递给该函数。类似地,我们还可以使用json参数来发送JSON数据。
效果: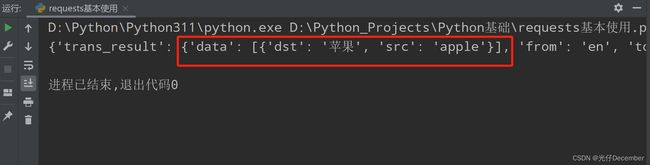
后续博文会讲解requests的其他功能,如代理和Cookie管理、文件上传和下载等。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/134089052