Java多线程(二)——Volatile关键字保证可见性,有序性,禁止指令重排实现
一、特性
1、保证线程可见性
2、保证线程有序性
3、禁止指令重排
在内存模型层面,如果给一个变量加上volatile,就说明这个变量是可见的,每次修改完读的时候都是从主内存中读的,也就是说每次修改完都存盘了,而不再是存缓存,供本线程自身可见。加上volatile也就避免了线程从自己的工作内存中查找变量的值,必须到主存中获取他的值,线程操作volatile变量都是直接操作内存。
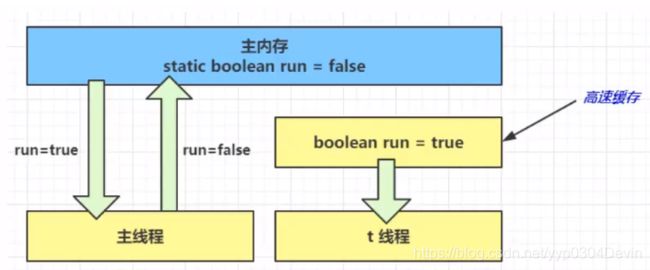
那么系统如何保证数据的可见性,有序性,指令重排呢
系统底层如何实现可见性
1.MESI如果不能解决,就使用MESI
2.如果不能,就锁总线
系统底层如何保证有序性
1.内存屏障:sfence mfence ifence 等原语
2.锁总线
volatile如何解决指令重排序
1: volatile i
2:ACC_VOLATILE
3:JVM的内存屏障
内存屏障两边的指令不可以重排,保证有序
4:hotspot实现
二、volatile原理
volatile的底层实现原理是内存屏障,Memory Barrier(Memory Dence)
对volatile 变量的写指令后会加入写屏障
对volatile变量的读指令前会加入读屏障
如何保证可见性
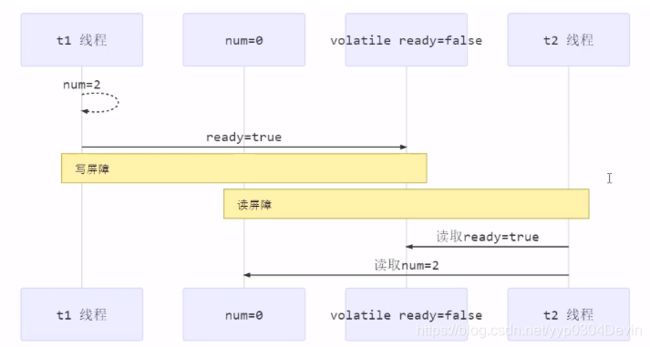
写屏障(sfence)保证在该写屏障之前的,对共享变量的改动,都同步到主存当中,
在没有加写屏障之前,我们对共享变量的操作会存到缓存中,不会同步到主存,然后对共享变量的修改,其他的线程都感觉不到,未知的,他们读到的都是之前在主存中的值。同步的时候不光是同步volatile修饰的变量,还会同步volatile修饰的变量之前的所有的值。
实例:
public void actor2(I_Result r){
num=2;
ready=true; //ready 是volatile赋值带写屏障
//写屏障
}在此实例中,ready是被volatile修饰过的,当代码运行到这里的时候,ready之前的数据也会同步的主存,比如num,所以工作内存中所有的操作都会同步到主存中。
而读屏障(Ifence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
public void actor1(I_Result r){
//读屏障
//ready 是volatile读取值读屏障
if(ready){
r.rl=num+num;
}else{
r.rl=1;
}
}读屏障和写屏障的实现是一样的,只不过在读数据的是,当代码运行到由volatile修饰的变量时,其后面的所有数据都是从主存中读的。
如图:用两个线程演示读写屏障。
如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
public void actor2(I_Result r){
num=2;
ready=true; //ready是volatile赋值带写屏障
//写屏障
}和之前的可见性相似,在共享变量上加了volatile关键字,除了保证可见性之外还能保证写屏障之前的代码不会在写屏障之后执行。
读屏障会确保指令重排时,不会将读屏障之后的代码排在读屏障之前
public void actor1(I_Result r){
//读屏障
//ready 是volatile读取带值读屏障
if(ready){
r.r1=num+num;
}else{
r.r1=1;
}
}
注意:
虽然保证顺序性,但不能保证指令交错:
写屏障仅仅是保证之后读能够读到最新的结果,但不能保证读跑到它前面去
而有序性的保证也只是保证了本线程内相关代码不被重排序
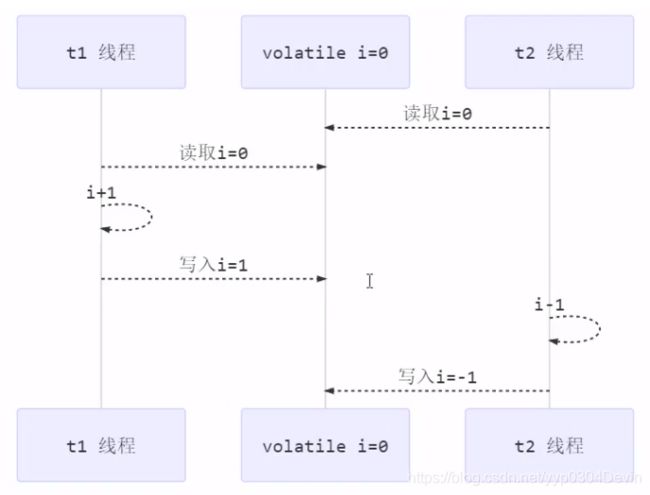
如何保证禁止指令重排
1. 字节码层面
添加 ACC_VOLATILE
2.JVM层面
JSR内存屏障
- LoadLoad屏障:
对于这样的语句Load1;LoadLoad;Load2;
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:
对于这样的语句Store1;StoreStore;Store2.
在Store及后续写入操作执行前,保证Store的写入操作对其他的处理器可见。
- LoadStroe屏障:
对于这样的语句:Load1;LoadStore;Store2;
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:
对于这样的语句Store1;StoreLoad;Load2;
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
内存屏障禁止了指令重排,也就是禁止JVM缓存优化和JVM指令重排优化。
3. 硬件层面
硬件内存屏障x86
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。
Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序。