我们做出了一个分布式注册中心
开篇
这篇文章是基于SOFA Meetup合肥站的分享总结,主要针对于注册中心的定位以及功能介绍,通过对蚂蚁注册中心发展史的分析,带领大家了解,蚂蚁的注册中心是如何一步一步演变为现在的规模和特性的。
更多深入的技术细节,欢迎大家加入到SOFA和SOFARegistry的社区中,探寻结果。
注册中心是什么
服务发现 & 服务注册
注册中心简单来说,是为了解决分布式场景下,服务之间互相发现的问题。
如下图所示,服务A想要调用服务B的时候,需要知道B的地址在哪里,如何解决这个问题?

一般来说,分为两个点:
- 服务发现可以有一个中心化的组件或者说是存储,它承载了所有服务的地址,同时提供出来一个可供查询和订阅的能力,服务的消费方可以通过和这个中心化的存储交互,获取服务提供方的地址列表。
- 服务注册:同样是上文中中心化的组件,但是,这个时候的服务信息可以有两种措施
- 服务连接注册中心,同时上报自身的服务以及元数据(也是今天本文讲述的重点)
- 有一个集中的控制面(control plane)将用户定义的服务和IP的映射写入注册中心,例如AWS的CloudMap
调用流程

如上图所示,就是目前一种主流的注册中心模式,SOFARegistry和Nacos都是这种模式。
- 服务A,服务B通过SDK或者REST将自身的服务信息上报给注册中心
- 服务A需要调用服务B的时候,就对注册中心发起请求,拉取和服务B相关的服务IP列表以及信息
- 在获取到服务B的列表之后,就可以通过自身定义的负载均衡算法访问服务B
心跳
心跳是注册中心用于解决服务不可用时,及时拉出服务降低影响的默认方式,如下图所示
- 服务B的一个节点断网或是hang住,引发心跳超时;或是宕机、断链直接引发心跳失败
- 注册中心把问题节点从自身的存储中拉出(这里拉出根据具体实现:有的是直接删除,有的是标记为不健康)
- 服务A收到注册中心的通知,获取到服务B最新的列表
DUBBO 注册中心
下面通过DUBBO的例子,我们来看一下注册中心是如何使用的,以及流程
首先,DUBBO在2.7和3.0中的配置略有不同,但是都是简单易懂的,这里都放上来
DUBBO-2.7

DUBBO-3.0
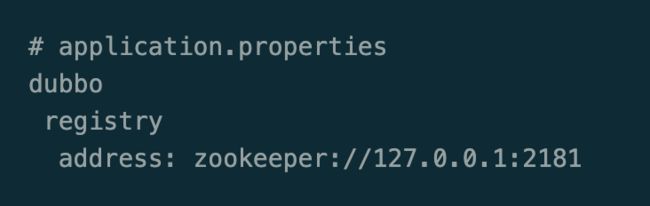
在RPC客户端只需要配置一个注册中心的地址即可,地址中包含了基础三元素
- protocol(协议类型)比如,zookeeper
- host
- port
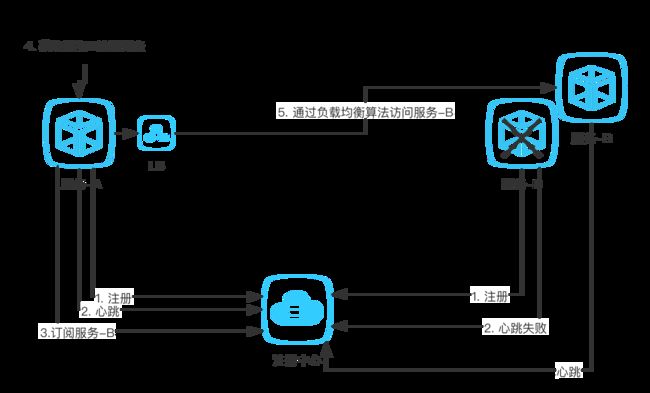
基于此,dubbo的注册流程如下图所示
- 服务的生产方通过DUBBO客户端向注册中心(Registry)发起注册行为(register)
- 服务的消费方通过DUBBO客户端订阅信息(subscribe)
- 注册中心通过通知的方式,下发服务列表给服务消费方

注册中心的本质
通过前文的讲解,以及DUBBO组件的具体例子,我们大概可以归纳注册中心的本质
“存储” + “可运维”
- 一方面,注册中心需要存储能力去记录服务的信息,比如应用列表
- 另一方面,注册中心在实践过程中,需要提供必需的运维手段,比如关闭某一服务流量

蚂蚁注册中心编年史
史前时代
史前时代的蚂蚁是相当久远的架构,当时所有的服务部署在同一台物理机上或者JVM上,服务之间不存在有跨机器调用的场景,这里略过不表

硬负载时代
后来,为了解决应用之间的耦合带来的部署难,运维难问题,我们对服务进行了拆分,拆分后的服务,遇到了一个问题,就是如何处理服务之间的调用关系,这个时候,蚂蚁用了两种硬负载 F5 或是 LVS。
通过简单的4层代理,我们可以把服务部署在代理的后面,服务与服务之间通过代理互相访问,达到了跨机调用的目的

第一代注册中心 – 硬负载到软负载的演变
通过硬负载访问的方式,一方面解决了服务之间互相调用的问题,部署架构也简单易懂;另一方面,在业务快速增长之后,却带来了一定的问题:
- 单点的问题(所有调用都走F5的话,F5一旦挂了,很多服务会不可用)
- 容量问题(F5承载的流量太高,本身会到一个性能瓶颈)
这个时候,蚂蚁引进了阿里集团的一款产品叫ConfigServer,作为注册中心进行使用,这个注册中心的架构就和开头提到的架构很像了,服务之间可以通过IP直接访问,而降低了对负载均衡产品的强依赖,减少了单点风险。
第二代注册中心 – ScaleUp?ScaleOut?It’s a problem
但是,问题还在持续,那就是注册中心,本身是一个单点,那么,他就会继续遇到上文中所说的两个问题
- 单点风险(注册中心本身是单机应用)
- 容量瓶颈(单台注册中心的连接数和存储数据的容量是有限的)
解决的方式有两种
- scale-up(淘宝):通过增加机器的配置,来增强容量以及扛链接能力;同时,通过主-备这样的架构,来保障可用性
- scale-out(蚂蚁):通过分片机制,将数据和链接均匀分布在多个节点上,做到水平拓展;通过分片之后的备份,做到高可用
蚂蚁和淘宝走了两条不同的路,也推进了蚂蚁后面演进出一套独立的生态系统
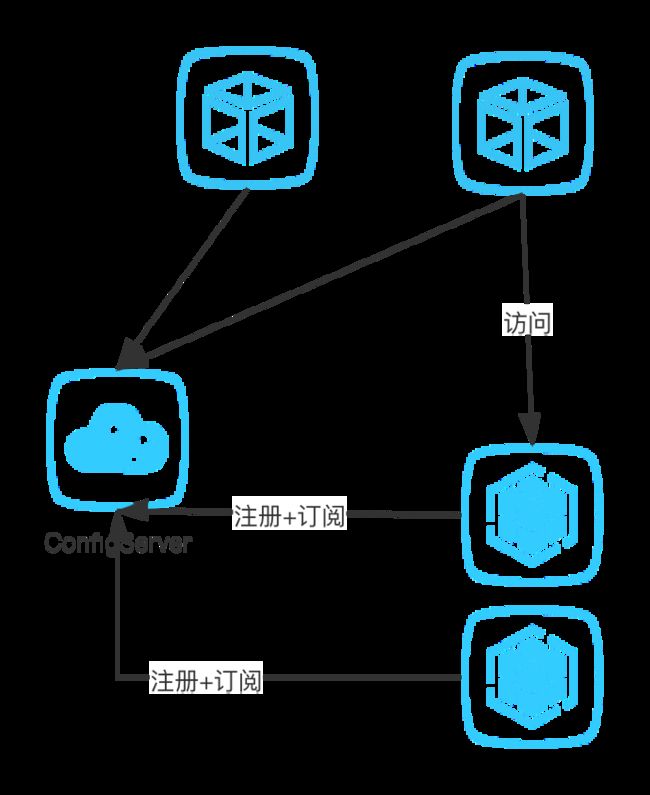
蚂蚁的演进架构如下,产生了两种不同的应用节点
- session节点,专门用来抗链接使用,本身无状态可以快速扩展,单机对资源的占用很小
- data节点,专门用来存储数据,通过分片的方式降低单个节点的存储量,控制资源占用

第五代注册中心 – Meta节点的诞生
上面的架构已经很符合目前主流的分布式架构了,但是在运维过程中,产生了一系列问题,比如
- 所有data都是分布式的,data之间的服务发现需要通过启动时给定一个配置文件,这样就和标准运维脱钩
- data节点的上下线需要去及时修改配置文件,否则集群重启会受到影响
- 分布式存储一致性问题,每次迭代发布,需要锁定paas平台,防止节点变动带来的不一致
所有这些问题的产生,我们发现可以引入一个元数据管理中心(Meta)节点来,解决对data和session管理的问题,data和session通过4层负载或是7层负载对meta访问即可.
对比业界的解决方案,都有类似的模型,比如HDFS的Name Node、Kafka依赖于ZK,Oceanbase依赖于RootServer 或者 配置中心Apollo依赖于Euraka。
Meta节点的出现,缓解了手工运维注册中心的瓶颈,但是,依然没有从根本上解决问题,那么问题在哪里?详见下文分析。

第六代注册中心 – 面向运维的注册中心
上文说道,Meta节点的出现,承接了Data以及Session之间服务发现的问题,但是,丛云未测来讲,还是有很多问题解决不了,比如
- Data节点的发布在数据量大的前提下,依然是个痛点
- Session节点的新加节点上,可能很久都没有流量
等等,对于这些问题,在SOFARegistry5.x的基础上,我们快速迭代了6.0版本,主要是面向运维的注册中心。
Data节点发布难的问题,说到底是一个影响范围的问题,如何控制单一data节点发布或者挂掉对数据的影响面,是解决问题的本源,这里我们采用了两个措施
- 改进数据存储算法(consistent-hash -> hash-slot)
- 应用级服务发现
存储算法的演进
之前我们使用了一致性hash的算法,如下图所示,每一个节点承载一部分数据,通过是存储进行hash运算,算出存储内容的hash值,再计算出hash值落在哪一个data所负责的存储区间,来存储数据。
当data节点宕机或者重启时,由下一个data节点接收宕机节点的数据以及数据的访问支持。

这样依赖,数据迁移的粒度只能以单个data节点所存储的数据为单位,在数据量较大(单节点8G)的情况下,对数据的重建有一定的影响,而且,在data连续宕机的情况下,可能存在数据丢失或是不一致的场景。
改进后的算法,我们参考了Redis Cluster的算法机制,使用hash slot进行数据分片
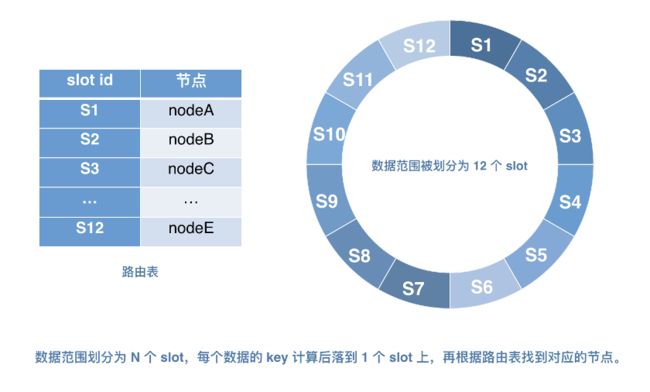
这样,在data发布过程中,可以控制数据的迁移以slot为单位(单个data节点多个slot,可配置)
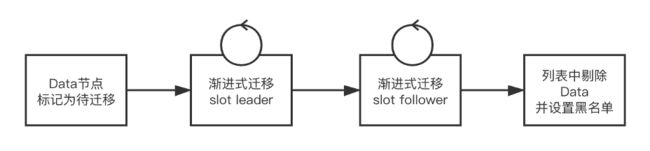

同时,为了解决迁移或是宕机期间,数据写入不一致的场景,我们引入了数据回放的补偿机制,data在promotion为slot的master之后,会主动地去和所有的session完成一次数据比对/校验,增量同步新增数据

应用级服务发现
应用级服务发现是为了解决数据存储量大的问题,因为篇幅原因,这里略过不表
开源
SOFARegistry从项目早期就开始了开源的进程,与目前主流的注册中心的对比如下
我们认为,注册中心首先需要解决的是可用性的问题,所以,在分布式一致性的问题上,我们选择了AP的模型,这点也和主流的注册中心,例如Euraka以及Nacos保持一致的观点。
其次,在性能方面,基于长连接的SOFARegistry拥有更短的推送延迟,相较于Nacos1.0的推送时延更短(Nacos1.0基于Long Polling的模型,Nacos2.0也使用了长连接的模型)
在协议方面,SOFARegistry使用了蚂蚁开源协议栈:BOLT协议(类似于HTTP2.0)的流式协议,更加轻量级,同时协议本身的全双工模式:无阻塞,大大提升了资源利用率。
| Feature | Consul | Zookeeper | Etcd | Eureka | Nacos | SOFARegistry |
|---|---|---|---|---|---|---|
| 服务健康检查 | 定期healthcheck (http/tcp/script/docker) | 定期心跳保持会话(session) + TTL | 定期refresh(http)+TTL | 定期心跳+TTL;支持自定义healthCheck | 定期链接心跳+断链 | 定期连接心跳 + 断链敏感 |
| 多数据中心 | 支持 | - | - | - | 支持 | 支持 |
| Kv存储服务 | 支持 | 支持 | 支持 | - | 支持 | 支持 |
| 一致性 | raft | ZAB | raft | 最终一致性 | 最终一致(注册中心) Raft(配置中心) | 最终一致性 |
| cap | cp | cp | cp | ap | ap+cp | ap |
| 使用接口(多语言能力) | 支持http和dns | 客户端 | http/grpc | 客户端/http | 客户端(多语言) http | 客户端(java) |
| watch支持 | 全量/支持long polling | 支持 | 支持long polling | 不支持(client定期fetch) | 支持 | 支持(服务端推送) |
| 安全 | acl/https | acl | https支持 | - | https | acl |
| spring cloud集成 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
和大家所熟知的Nacos对比,我们在金融级和分布式(存储量级)上具有很大优势,易用性和云原生方面,目前还在追赶
欢迎加入我们
一个人可以走得很快,但一群人可以走的更远
SOFARegistry是一个开源项目,也是开源社区SOFA重要的一环,我们希望用社区的力量推动SOFARegistry的前进,而不是只有蚂蚁的工程师去开发。我们在今年也启动了两个项目,用于支持更多的开发者参与进来:
- Trun-Key Project (开箱即用计划):https://github.com/sofastack/sofa-registry/projects/5
- Deep-Dive Project(深入浅出计划):https://github.com/sofastack/sofa-registry/projects/4
计划目前还处在初期阶段,欢迎大家加入进来,可以帮助我们解决一个issue,或是写一篇文档,都可以更好地帮助社区,帮助自己去成长。
本周推荐阅读
-
RFC8998+BabaSSL—让国密驶向更远的星辰大海
-
还在为多集群管理烦恼吗?OCM来啦!
-
MOSN 子项目 Layotto:开启服务网格+应用运行时新篇章
-
开启云原生 MOSN 新篇章 — 融合 Envoy 和 GoLang 生态
更多文章请扫码关注“金融级分布式架构”公众号
