pyspark基础学习——环境配置
目录
- 一、配置版本
- 二、windows下安装pyspark
-
- 2.1 jdk安装
- 2.2 spark安装
- 2.3 Hadoop安装
- 2.4 检测代码
- 2.5 运行环境
- 总结
一、配置版本
Java JDK 1.8.0_111
Python 3.9.0
Spark 3.2.1
Hadoop 3.2.3
二、windows下安装pyspark
python在代码的编辑上具有简单易懂的效果,而spark在处理大数据的功能在行业内已经得到了广泛的应用,如今我们可以通过python语句来实现spark 的相关功能,但是要想在python中使用pyspark并不是单纯的导入pyspark包就可以实现的。我们需要根据不同的环境搭建spark、Hadoop环境,才可以在python中使用pyspark。
在安装之间,若对数据处理的速度或者是数据量不是非常大的情况下,建议下载到非系统盘的位置,同时在命名的时候,尽量选用英文,避免后续可能因为中文而出现的问题。
2.1 jdk安装
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载jdk8版本需要先进行注册
下载安装完后打开Windows中的环境变量
(1. 设置+系统+关于+高级系统设置+环境变量;2. win+r 输入cmd,在终端中输入sysdm.cpl,选择高级,再打开环境变量):
创建JAVA_HOME:D:\Java\jdk1.8.0_111(此处为安装时jdk的下载位置)
创建CLASSPATH:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
在Path添加:%JAVA_HOME%\bin;

测试是否安装成功:打开cmd命令行,输入java -version

2.2 spark安装
下载地址:https://spark.apache.org/downloads.html
环境变量:
创建SPARK_HOME:D:\spark\spark-3.2.1-bin-hadoop3.2(根据自己安装的位置)
Path添加:%SPARK_HOME%\bin

2.3 Hadoop安装
下载地址:链接:https://dlcdn.apache.org/hadoop/common/
环境变量:
创建HADOOP_HOME:D:\hadoop\hadoop-3.2.3(根据自己安装的位置)
Path添加:%HADOOP_HOME%\bin
在安装Hadoop的时候要注意跟spark版本相互对应
测试是否安装成功:打开cmd命令行,输入pyspark

表示安装成功。
在运行代码之前,需要导入pyspark的包
pip install pysaprk
2.4 检测代码
import findspark
findspark.init()
from datetime import datetime, date
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
rdd = spark.sparkContext.parallelize([
(1, 2.5, 'string1', date(2022, 1, 1), datetime(2022, 1, 1, 12, 0)),
(2, 3.5, 'string2', date(2022, 2, 1), datetime(2022, 1, 2, 12, 0)),
(3, 4.5, 'string3', date(2022, 3, 1), datetime(2022, 1, 3, 12, 0))])
df = spark.createDataFrame(rdd, schema=['A', 'B', 'C', 'D', 'E'])
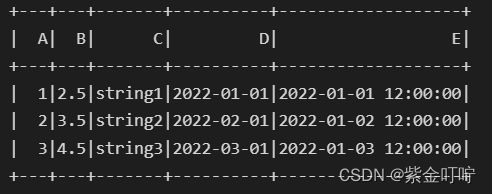
df.show()
运行结果如下所示:
2.5 运行环境
因为我使用vs code的频率相对较高,而且vs code下运行pyspark的代码没有众多环境进行配置。同时,为了方便模块化的处理,我在vs code下安装好Jupyter的插件,可以直接运行。若是想要在PyCharm或者Anaconda中运行pyspark,可以参考这篇文章Python安装spark,里面详细介绍了如何在PyCharm中添加相应的环境,以及在Anaconda中创建spark的虚拟环境。
总结
由于此次学习仅为了课堂大作业,因此有错误的地方还望指正。因本次处理的大数据为csv文件的类型,在下一篇文章中我简单介绍了几种简单的语句供大家使用pyspark基础学习—处理csv文件相关语法