c++之构造函数,析构函数(六千字长文详解!)
c++之类和对象——构造函数,析构函数
文章目录
- c++之类和对象——构造函数,析构函数
-
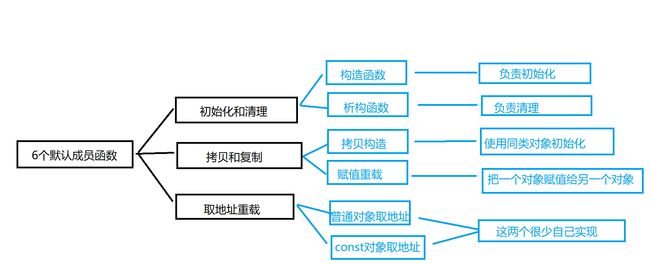
- 类的六个默认成员函数
- 构造函数
-
- 构造函数特征
- 在c++下栈的写法
- 默认构造函数
- 析构函数
-
- 析构函数的特征
类的六个默认成员函数
如果一个类中什么成员都没有,简称为空类。
空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。
默认成员函数:用户没有显式实现,编译器会生成的成员函数称为默认成员函数。
class date
{};
构造函数
用于类初始化的函数
构造函数,其实指的是对象创造构建的时候调用这个函数!所以才叫构造函数啊
构造函数特征
-
函数名与类名相同。
-
无返回值。//甚至连void类型都不是!
-
对象实例化时编译器自动调用对应的构造函数。
-
构造函数可以重载。//函数名相同参数不同
可以提供多个构造函数多种初始化方式!
为什么要有构造函数?
我们以前使用c的数据结构的时候往往要先定义,然后调用函数接口进行初始化,但是我们往往很容易忽略这一步
有了构造函数我们就可以省这一步,在类创建的时候自动调用
构造函数是一个特殊的成员函数,名字与类名相同,
创建类类型对象时由编译器自动调用,以保证每个数据成员都有 一个合适的初始值,并且在对象整个生命周期内只调用一次。

class date
{
public:
date(int year, int month, int day)//构造函数没有返回值!类型名就是函数名!
{
cout << "Iint success!" << endl;
_year = year;
_month = month;
_day = day;
}
date()//构造函数支持函数重载!
{
cout << "Iint success!" << endl;
_year = 1;
_month = 1;
_day = 1;
}
//既可以传参也可以不传参!
/*
date(int year = 1, int month = 1, int day = 1)//构造函数没有返回值!类型名就是函数名!
{
cout << "Iint success!" << endl;
_year = year;
_month = month;
_day = day;
}我们同时也要注意函数重载和缺省值使用的时候避免调用函数的二义性!
全缺省和无参函数同时存在会出现二义性
*/
private:
int _year;
int _month;
int _day;
};
int main()
{
date a(2000, 1, 1);
date b;//在定义对象后悔自动的去调用!
return 0;
}
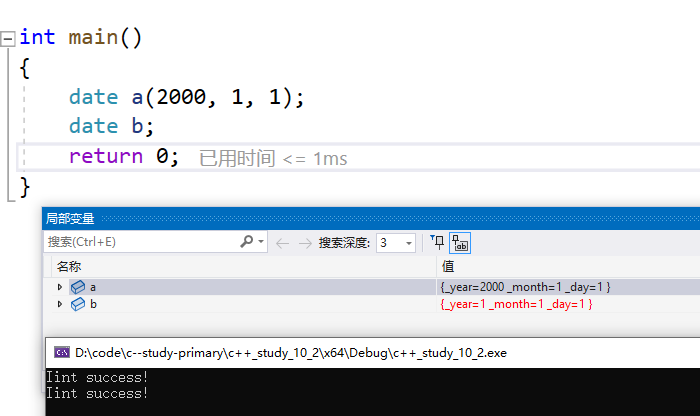
**我们可以看到我们只是定义一个对象,但是构造函数却已经成功的调用了!**1
//关于无参的一个错误写法
date c();
//编译器不清楚这究竟是一个对象声明,还是一个函数声明!
//无参定义不可以加()
在c++下栈的写法
class stack
{
public:
stack(int newcapcacity = 4)
{
int* temp = (int*)malloc(sizeof(int) * newcapcacity);
if (temp == nullptr)
{
perror("malloc fail");
exit(-1);
}
_a = temp;
_top = 0;
_capacity = newcapcacity;
}
void Push(int x)
{
if (_top == _capacity)
{
int newcapacity = 2 * _capacity;
int* temp = (int*)realloc(_a, sizeof(int) * newcapacity);
if (temp == nullptr)
{
perror("realloc fail");
exit(-1);
}
_a = temp;
_capacity = newcapacity;
}
_a[_top++] = x;
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
stack a;
a.Push(1);
a.Push(2);
a.Push(3);
a.Push(4);
a.Push(5);
//我们可以很明显的看出来方便了很多!
return 0;
}
5.如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦 用户显式定义编译器将不再生成。(体现了默认特性!)
简单点说,我们写了编译器就不会生成!
class date
{
public:
void print()
{
cout << _year << " " << _month << " " << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
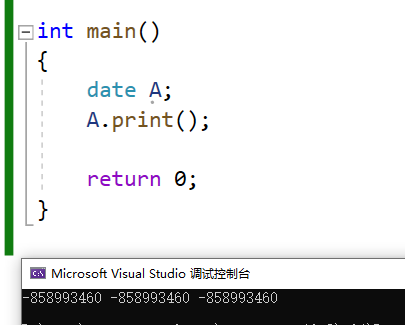
int main()
{
date A;
A.print();
return 0;
}
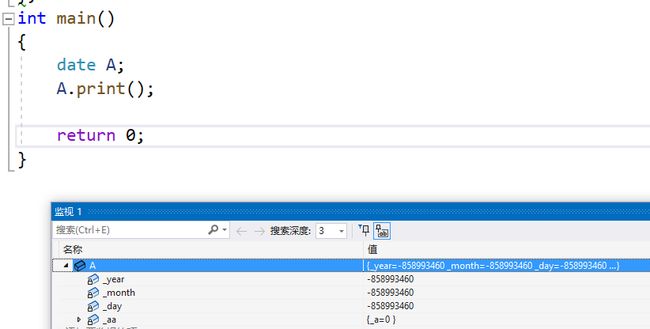
看到上面的结果,或许有会有人疑惑了,不是说会生成一个默认构造函数吗,但是为什么没有完成初始化呢?
看上去默认析构函数好像也没有什么用啊?对象A的_year/_month/_day好像都还是随机值呢!
答案是:c++把类型分为内置类型(基本类型)和自定义类型!编译器会生成的默认构造函数会去调用自定义类型的默认成员函数用于初始化自定义类型!
而c++这个默认成员函数对内置成员不会进行处理!但是会对自定义类型会调用它的默认构造!
内置类型 int/char/double … 和任意类型的指针!(什么叫任意类型的指针?我们自定义类型的指针也算在内置类型里面例如Date*这种!
自定义类型 class/struct 定义的类型 例如 Stcak/Queun/Person/date
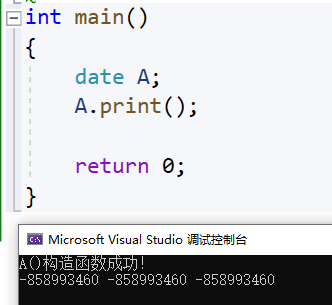
class A { public: A() { _a = 0; cout << "A()构造函数成功!" << endl; } private: int _a; }; class Date { public: void print() { cout << _year << "-" << _month << "-" << _day << endl; } private: //内置类型! int _year; int _month; int _day; //什么都没有做,只是增加了它的一个自定义类型! A _aa; }; int main() { Date A; A.print(); return 0; }
我们可以看出来虽然依旧没有处理内置函数,但是自定义类型的aa的默认构造被成功调用了!被Date的默认构造函数成功的调用了!
那这个除了初始化自定义类型的成员函数还有什么意义呢?不是还是要写一个构造函数用来初始化自定义类型吗?而且这样还会导致默认构造函数无法生成去调用自定义类型默认构造函数去初始化,这样不就是都要重写吗?这有什么意义呢?
例如下面这种类型:
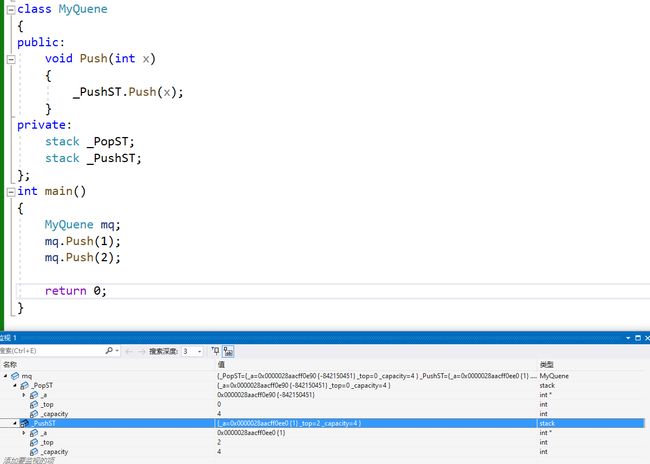
class stack { public: stack(int newcapcacity = 4) { int* temp = (int*)malloc(sizeof(int) * newcapcacity); if (temp == nullptr) { perror("malloc fail"); exit(-1); } _a = temp; _top = 0; _capacity = newcapcacity; } ~stack()//这就是栈的析构函数! { free(_a); _a = nullptr; _top = 0; _capacity = 0; } void Push(int x) { if (_top == _capacity) { int newcapacity = 2 * _capacity; int* temp = (int*)realloc(_a, sizeof(int) * newcapacity); if (temp == nullptr) { perror("realloc fail"); exit(-1); } _a = temp; _capacity = newcapacity; } _a[_top++] = x; } private: int* _a; int _top; int _capacity; }; class MyQuene { public: void Push(int x) { _PushST.Push(x); } //......剩下读者可以加自己实现 private: stack _PopST; stack _PushST; }; int main() { MyQuene mq; mq.Push(1); mq.Push(2); return 0; }
我们可以看出mq完全不需要写构造函数,因为默认构造函数已经够用了!mq的默认构造函数去调用了stack的默认构造函数去初始化了!mq的两个变量!所以完全不需要自己去写构造函数
那如果遇到要同时使用自定义类型和内置类型又想要使用默认构造去初始化自定义类型的时候我们应该怎么办?
答案是可以使用缺省值!
class stack { //.... } class MyQuene { public: void Push(int x) { _PushST.Push(x); } //......剩下读者可以加自己实现 private: stack _PopST; stack _PushST; int a = 10;//答案是可以使用缺省值!这里不是初始化! }; class Date { public: Date(int year = 1, int month = 1, int day = 1) { _year = year; _month = month; _day = day; } private: int _year = 0; int _month = 0; int _day = 0; }; //用时有缺省值和构造函数的话,还是以构造函数为主!
默认构造函数
**无参的构造函数和全缺省的构造函数都称为默认构造函数,但是这两个有且只能有一个!因为同时存在有会二义性。 **
无参构造函数、全缺省构造函数、我们没写编译器默认生成的构造函数,都可以认为是默认构造函数。
不传参数就可以调用的构造函数的就是默认构造!
class Date { public: Date(int year = 1, int month = 1, int day = 1) { _year = year; _month = month; _day = day; } Date() { _year = 1; _month = 1; _day = 1; } private: int _year = 0; int _month = 0; int _day = 0; }; int main() { Date a; return 0; }
class Date { public: Date(int year, int month = 1, int day = 1) { _year = year; _month = month; _day = day; } private: int _year = 0; int _month = 0; int _day = 0; }; int main() { Date a; return 0; }
因为已经自己写了显性的构造函数所以编译器不会自动生成的默认构造函数,但是又不是无参或者全缺省,导致了不存在默认构造函数!
class stack { public: stack(int newcapcacity) { int* temp = (int*)malloc(sizeof(int) * newcapcacity); if (temp == nullptr) { perror("malloc fail"); exit(-1); } _a = temp; _top = 0; _capacity = newcapcacity; } //... private: int* _a; int _top; int _capacity; }; class MyQuene { public: void Push(int x) { _PushST.Push(x); } //......剩下读者可以加自己实现 private: stack _PopST; stack _PushST; }; int main() { MyQuene mq; mq.Push(1); mq.Push(2); return 0; }
这种情况虽然MyQuene自身会生成默认构造函数,但是stack类没有默认构造也会导致这个问题!
如果我们不写stack的构造函数初始化仅仅使用编译器生成的默认构造函数,我们可以使用全缺省
class stack { private: //int* _a = nullptr; int* _a = (int*)malloc(sizeof(int)*4);//也可以使用的malloc!但是其实它现在不会去调用!只有使用的时候才会调用! int _top = 0; int _capacity = 0; }; class MyQuene { public: void Push(int x) { _PushST.Push(x); } //......剩下读者可以加自己实现 private: stack _PopST; stack _PushST; };


析构函数
通过前面构造函数的学习,我们知道一个对象是怎么来的,那一个对象又是怎么没呢的? 析构函数:与构造函数功能相反,析构函数不是完成对对象本身的销毁,局部对象销毁工作是由编译器完成的。而对象在销毁时会自动调用析构函数,完成对象中资源的清理工作。
析构函数的功能和我们以前写的数据结构的destroy功能类似
以数据结构的栈为例,当我们要使用栈后,总要调用函数接口去销毁栈中的资源
例如:一些malloc出来的空间!而对象本身是由编译器去销毁的!
但是就跟我们老是忘记调用函数初始化一样,我们也经常会忘记在最后调用函数去销毁!所以与构造函数相对的就有了析构函数!
析构函数的特征
析构函数是特殊的成员函数,其特征如下
- 析构函数名是在类名前加上字符 ~。(按位取反,就是要告诉你和构造函数的功能是相反的!)
- 无参数无返回值类型。(没有参数意味着也不支持重载!只有多个参数才支持重载!)
- 一个类只能有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。注意:析构 函数不能重载
- 对象生命周期结束时,C++编译系统系统自动调用析构函数
什么是生命周期结束!就是出了函数域!
作用域不一定影响生命周期!(命名空间就不影响生命周期!)
影响生命周期的域是 局部域和全局域
平时的变量有三个
一个是局部对象 !局部对象在栈帧里面,函数结束就销毁了!
第二个全局变量!全局域里面的函数只有main函数结束,里面的变量才销毁!
最后一个是malloc的变量,只有手动销毁才会销毁!
class stack
{
public:
stack(int newcapcacity = 4)
{
int* temp = (int*)malloc(sizeof(int) * newcapcacity);
if (temp == nullptr)
{
perror("malloc fail");
exit(-1);
}
_a = temp;
_top = 0;
_capacity = newcapcacity;
}
~stack()//这就是栈的析构函数!
{
free(_a);
_a = nullptr;
_top = 0;
_capacity = 0;
cout << "destructor success!" << endl;
}//完成的资源清理工作!
void Push(int x)
{
if (_top == _capacity)
{
int newcapacity = 2 * _capacity;
int* temp = (int*)realloc(_a, sizeof(int) * newcapacity);
if (temp == nullptr)
{
perror("realloc fail");
exit(-1);
}
_a = temp;
_capacity = newcapacity;
}
_a[_top++] = x;
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
stack a;
stack b;
//a,b出了函数作用域就销毁!就是main函数!
//出了之后会自动调用析构函数!主要用于销毁第三类由malloc生成的变量!
//像是日期类就不用析构函数了,但是非要写一个是允许的!
return 0;
}
自动调用析构函数,清理了stack里面的资源!
关于析构函数和构造函数相比以前数据结构的简化
在以前我们使用原先c语言的数据结构的时候有多个需要调用destroy的地方我们往往很容易忘记调用,从而导致内存泄漏!
但是有了析构和构造函数这些问题我们统统可以不用去管!

- 如果类中没有显式定义析构函数,则C++编译器会自动生成一析构函数,一旦 用户显式定义编译器将不再生成。(体现了默认特性!)
和上面我们说的构造函数一样,默认析构函数不会去处理内置类型,而是会去调用自定义类型的默认析构函数去处理自定义类型的资源
class A
{
public:
~A()
{
free(_a);
cout << "A()析构函数成功!" << endl;
}
A()
{
_a = (int*)malloc(sizeof(int) * 4);
}
private:
int* _a;
};
class date
{
public:
void print()
{
cout << _year << " " << _month << " " << _day << endl;
}
private:
int _year;
int _month;
int _day;
A _aa;
};