大数据之路系列之flink(12)
大数据之路系列之flink——快速上手
快速上手
- 大数据之路系列之flink——快速上手
- 一、flink是什么
- 二、flink的应用场景
- 三、数据处理架构
-
- 第一代、事务处理 oltp
- 第二代.、分析处理 olap
- 第三代、有状态的流式处理
- 第四代、分布式的有状态的流式处理
- 第五代、lambda架构
- 第六代、kappa
- 四、flink sql or flink api?
- 五、flink on yarn 两种使用方式
-
- flink on yarn 第一种方式
- flink on yarn 第二种方式
- 六、停止作业
- 七、flink中的时间窗口
-
- 1.时间语义
- 2.水位线
- 3.窗口
-
- 窗口的具体实现
-
- 1.滚动窗口 tumbling window
- 2.滑动窗口 slidingwindow
- 一、什么是flink?
- 二、flink的三个核心组件
- 三、flink的流处理和批处理
- 四、Storm vs SparkStreaming vs Flink对比
- 五、Flink Streaming和Batch区别
- 六、实时计算框架的选择
- 七、flink on yarn 两种使用方式
-
- flink on yarn 第一种方式
- flink on yarn 第二种方式
- flink核心API
-
- DataStream
-
- dataSource
- transformation
-
- union
- connect
- side output
- 分区算子
一、flink是什么
对于无界和有界数据流进行状态计算。
二、flink的应用场景
实时报表、广告投放、实时推荐、实时数据采集、实时报警、订单状态追踪、信息推送、实时结算、风险检测
三、数据处理架构
第一代、事务处理 oltp
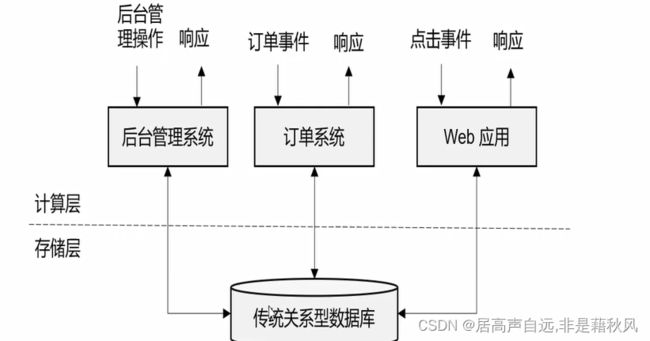
1. 传统的前后端架构,后台管理系统,前台点击后台响应,数据在传统数据库中进行操作
2. 优点:快,方便
3. 缺点:数据量有瓶颈
第二代.、分析处理 olap
1. hive、Hadoop体系
2. 优点:支持大数据处理
3. 缺点:延迟
第三代、有状态的流式处理

1.数据进入处理逻辑,计算结果直接响应,数据存放在内存中,定期持久化
2. 优点:支持大数据处理,实时响应
3. 缺点:并发瓶颈
第四代、分布式的有状态的流式处理

1.数据进入处理逻辑,计算结果直接响应,数据存放在内存中,定期持久化,同时部署多个节点,处理高并发
2. 优点:支持大数据处理,实时响应,可以处理高并发数据
3. 缺点:数据丢失风险,乱序,不能保证数据顺序
第五代、lambda架构
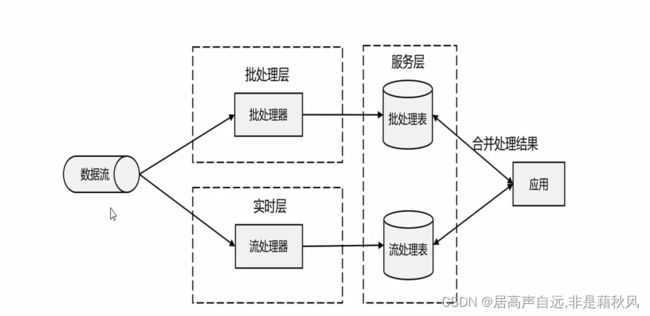
- 批处理、流处理同时对数据进行处理,流处理进行实时的计算。批处理操作准确结果。
- 优点:实时响应、结果有保证
- 缺点:两套代码
第六代、kappa
- flink通过时间窗口、时间语义保证结果的准确性。
- 同时精确一次exactly-once的状态一致性保证数据的准确性。
四、flink sql or flink api?

flinksql是最高层的,意味着sql是经过封装的能更简单的实现需求,但是对于复杂的需求,没有进行封装的只能是使用api来执行。
越高层的越简明,方便;越底层的越丰富,灵活。
五、flink on yarn 两种使用方式
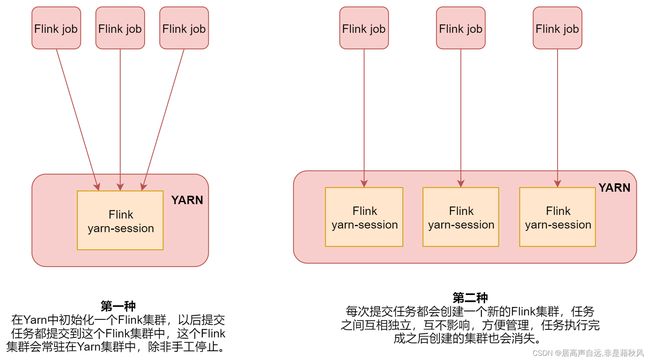
第一种适合运行规模小,短时间的作业
第二种适合长时间的作业
flink web页面 8081
flink on yarn 第一种方式
第一步:初始化一个长时间运行的flink集群
第二步:使用 flink命令向flink集群提交任务
1.创建一个长时间运行flink集群
bin/yarn-session.sh -jm 1024m -tm 1024m -d
-jm主节点的内存,-tm从节点内存,-d表示这个进程在后台运行
2.向集群中提交任务
bin/flink run ./examples/batch/WordCount.jar
flink on yarn 第二种方式
老版命令:
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
当停止服务后,flink的集群也会停止,如果此时想看flink的web页面就需要配置历史
[root@bigdata04 flink-1.11.1]# vi conf/flink-conf.yaml
启动flink的历史进程
[root@bigdata01 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata02 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata03 hadoop-3.2.0]# bin/mapred --daemon start historyserver
六、停止作业
1.页面cancel
2.命令 flink cancel jobId
七、flink中的时间窗口
1.时间语义
### 1.事件时间 event time
事件发送的时间,比如点击事件发送的时间
### 2.处理时间 process time
项目处理中的时间
默认和主要的是使用事件时间
2.水位线
water mark
单调递增的时间,由于是使用事件时间,系统不知道到底是什么时候了,所以要虚拟一张时间表出来,3点数据到了就是三点,四点数据到了就是四点或者是定期来根据数据刷新下时间(实时刷新时间或者是周期性刷新时间)。但是为了应对迟到的数据,可以设置最大乱序时间,也就是把表调慢一点时间,用来等一下迟到的数据。
到底要设置多久?
实时流想要获取计算窗口数据,理论上都得有一个取舍,不能设置过大的乱序时间,真正产生乱序的原因是网络延迟,需要从历史经验看设置多少,基本上都是秒级别以下
3.窗口

将无线的数据切成有限的数据块进行处理,就是窗口
窗口的分类:时间窗口和计数窗口
窗口的具体实现
1.滚动窗口 tumbling window
指定时间段里面的数据进行计算。最常见的
2.滑动窗口 slidingwindow
连续时间内的计算(行程码)
一、什么是flink?
分布式、高性能、高可用、流处理
批处理是流处理的一个极限特例
二、flink的三个核心组件

data source :数据源 负责接收数据
transformations 算子 负责对数据进行处理
data sink 负责输出组件 负责将计算好的数据输出到其他存储介质中
三、flink的流处理和批处理
在大数据中,批处理和流处理一般情况被认为是两种不同的任务,一个大数据框架一般会被设计成只能处理其中一种任务。
Strom只能支持流处理任务,而MapReduce和spark只能支持批处理任务。spark streaming是批处理的一个特例。只是一个及其细粒度的批处理。
flink可以通过灵活的执行引擎,同时支持批处理和流处理
流处理和批处理系统的最大的不同是在于节点之间的数据传输方式。
流处理:当一条数据处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点进行继续处理。
批处理:当一条数据处理完成后,序列化到缓存中,等缓存写满以后,就会持久化到本地硬盘上,当所有数据都处理完成后,开进行网络传输到下一个节点上。
流处理;低延迟
批处理:高吞吐
flink:灵活的方式,flink是通过缓存快进行网络传输,用户可以指定宦存块大小,如果缓存块设置成0,那么就是流处理;反之设置成很大就是批处理。
四、Storm vs SparkStreaming vs Flink对比

native:表示来一条数据处理一条数据
mirco-batch:表示划分小批,一小批一小批的处理数据
组合式:需要写代码,比较麻烦
声明式:使用函数,代码量比较小
五、Flink Streaming和Batch区别
流处理:Streaming
执行环境:streamExecutionEnvironment
批处理:Batch
执行环境:ExecutionEnvironment
六、实时计算框架的选择
1:需要关注流数据是否需要进行状态管理
2:消息语义是否有特殊要求At-least-once或者Exectly-once
3:小型独立的项目,需要低延迟的场景,建议使用Storm
4:如果项目中已经使用了Spark,并且秒级别的实时处理可以满足需求,建议使用SparkStreaming
5:要求消息语义为Exectly-once,数据量较大,要求高吞吐低延迟,需要进行状态管理,建议选择Flink
七、flink on yarn 两种使用方式
第一种适合运行规模小,短时间的作业
第二种适合长时间的作业
flink on yarn 第一种方式
第一步:初始化一个长时间运行的flink集群
第二步:使用 flink命令向flink集群提交任务
1.创建一个长时间运行flink集群
bin/yarn-session.sh -jm 1024m -tm 1024m -d
-jm主节点的内存,-tm从节点内存,-d表示这个进程在后台运行
2.向集群中提交任务
bin/flink run ./examples/batch/WordCount.jar
flink on yarn 第二种方式
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
当停止服务后,flink的集群也会停止,如果此时想看flink的web页面就需要配置历史
[root@bigdata04 flink-1.11.1]# vi conf/flink-conf.yaml
…
jobmanager.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.web.address: 192.168.182.103
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.archive.fs.refresh-interval: 10000
启动flink的历史进程
[root@bigdata01 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata02 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata03 hadoop-3.2.0]# bin/mapred --daemon start historyserver
flink核心API
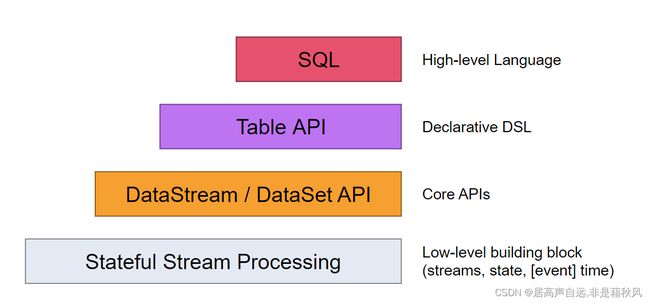
核心API:提供了针对流数据和批数据的处理,对于低级API进行封装,filter、sum、max、min等高级函数。
TableAPI:通过Dataset和dataStream创建出一个table,使用filter、join或者select操作。最后还可以将一个table转成DataSet或者DataSteam
SQL:直接使用sql语句。
DataStream
dataSource、transformation、datasink
dataSource
数据源
DataSource 容错保证
Socket at most once
Collection exactly once
Kafka exactly once 需要使用0.10及以上版本
transformation
算子 解释
map 输入一个元素进行处理,返回一个元素
flatMap 输入一个元素进行处理,可以返回多个元素
filter 对数据进行过滤,符合条件的数据会被留下
keyBy 根据key分组,相同key的数据会进入同一个分区
reduce 对当前元素和上一次的结果进行聚合操作
aggregations sum(),min(),max()等
union 合并多个流,多个流的数据类型必须一致
connect 只能连接两个流,两个流的数据类型可以不同
split 根据规则把一个数据流切分为多个流
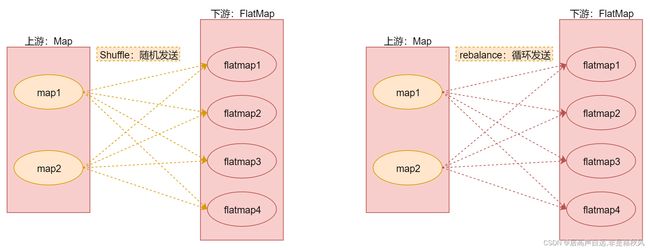
shuffle 随机分区
rebalance 对数据集进行再平衡,重分区,消除数据倾斜
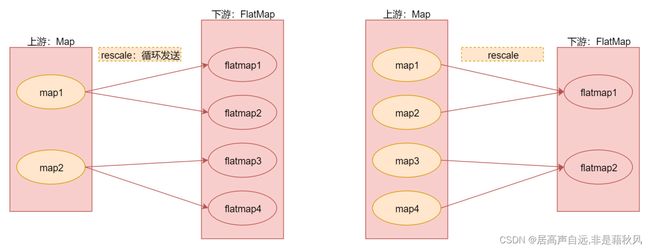
rescale 重分区
partitionCustom 自定义分区
union
合并多个数据流,应用在多数据源的数据类型一致,处理规则也一致。
connect
只能连接两个流,但是两个流的数据类型可以不同
side output
可以将数据流进行切分
分区算子
算子 解释
random 随机分区
rebalance 对数据集进行再平衡,重分区,消除数据倾斜
rescale 重分区
custom partition 自定义分区
rebalance 是全量重分区,recale不会
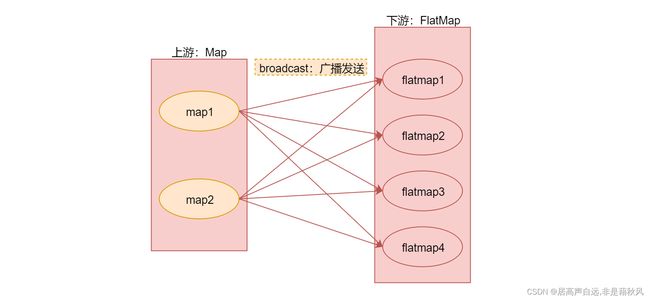
广播变量适合大数据集join小数据集的场景