java字符串编码和解码问题
java字符串编码和解码问题
学习目标
-
- java字符串编码和解码问题
-
- 1、什么是编码和解码
- 2、为什么会出现乱码?
- 3、如何解决乱码问题?
-
- 3-1、IO流
- 3-2、String
- 3-3、Charset
- 3-4、上面3种解决不了,用第四种办法
1、什么是编码和解码
1、在java开发中经常会遇到中文文字编码问题,该怎么解决?
首先我们先了解一下,什么是编码?什么是解码?
//举个例子:
(1)编码: String -> byte[ ];
常用方法: str.getBytes(charsetName)
(2)解码: byte[ ] -> String;
常用方法: new String(byte[ ],charsetName);
例1:
String str = "皮卡丘":
编码:byte[] bytes= str.getBytes("编码方式");//常用编码方式 gbk、utf-8、gb2312、iso-8859-1等等。
解码:String b = new String(bytes,"解码方式");//解码方式对应常用编码方式。
2、为什么会出现乱码?
**原因:**这个问题就是因为编码和解码是采用了不同的或者是不兼容的编码方案。比如一个用UTF-8编码的后的字符。再用GBK去解码,由于两个字符集的编码库不一样。同一个汉字在两个编码库的位置也不一样。于是就出现了乱码。
当我们读取文件的时候实际读取的是字节。然后根据文件的编码格式,将字节解码成字符串。乱码问题容易出现的地方就是这里。
思路:不要妄想将一个乱码的字符串变成一个非乱码的。这个思路是错误的。应该从乱码之前的字节着手处理。
1、正确演示
正常显示的字符串无乱码解码后的字符串对象可以用任意方式编码。但解码要正常显示,必须用对应的编码方式解码。(对于中文要保证正常显示必须采用中文编码/解码方式)
public class Test3 {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "皮卡丘";
String b1 = new String(str.getBytes("gbk"),"gbk");
String b2 = new String(str.getBytes("utf-8"),"utf-8");
String b3 = new String(str.getBytes("gb2312"),"gb2312");
System.out.println(b1); //皮卡丘
System.out.println(b2);//皮卡丘
System.out.println(b3);//皮卡丘
}
}
2、错误演示
当没采用对应方式解码时(也就是所谓的乱码)怎么转成正常显示而无乱码。
public class Test4 {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "皮卡丘";
//这里的b1就是采用的gbk的方式解码的,所以 b1不会乱码的
String b1 = new String(str.getBytes("gbk"),"gbk");
//这里用gbk而没有用对应的UTF-8方式解码,所以 b2将会是乱码的
String b2 = new String(str.getBytes("UTF-8"), "gbk");
System.out.println(b1); //皮卡丘
System.out.println(b2); //鐨崱涓�
}
}
3、如何解决乱码问题?
这个问题其实就是java中如何使用编码规则,因为使用好了编码规则。才可以很好地解决乱码问题。
3-1、IO流
编码的目的上面已经说了,主要是字节和字符之间的转化。既然涉及到字节和字符很容易我们就能想到java中的IO流。也就是说java中编码的转换其实就是IO流中的类来实现的。
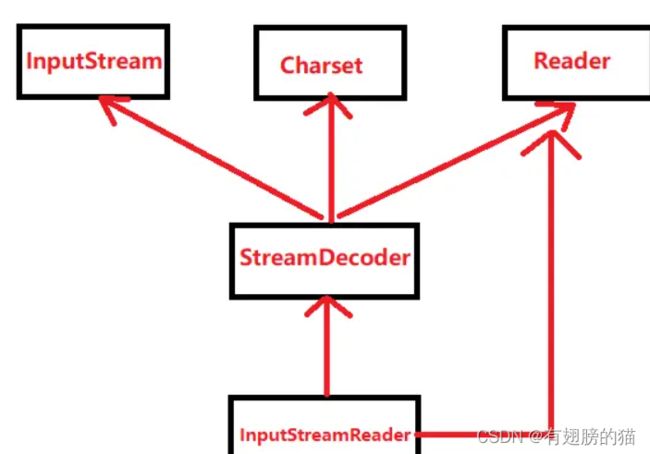
最核心的就是上面几个类,当然这里只是给出了输入的一部分,还有一些输出的类。
示例:首先是IO流实现,这种通过输入输出流可以直接的指定编码规则。
public void convertionFile() throws IOException{
File file = new File("./愚公要移山.txt");
FileInputStream fis = new FileInputStream(file);
InputStreamReader inReader = new InputStreamReader(fis, "gbk");
FileOutputStream fos = new FileOutputStream(file);
OutputStreamWriter outReader = new OutputStreamWriter(fos, "utf-8");
//这种输入gbk,输出utf-8肯定会出现错误
}
3-2、String
String类中也提供了一些转码的方法。下面我们会通过实例来说明。为什么String可以实现呢?这是因为String底层保存的其实就是一个一个字节,而且String还有方法直接转化为字符。所以String肯定也能实现。
public void convertionString() throws IOException{
String s = "愚公要移山,码农飞上天";
// 正常情况下转码的过程
byte[] b = s.getBytes("gbk");// 编码
String sa = new String(b, "gbk");// 解码
System.out.println(sa);
// 错误状态下转码的过程
b = sa.getBytes("utf-8");// 编码使用utf-8
sa = new String(b, "gbk");// 解码使用gbk
System.err.println(sa);
//控制台输出:
//愚公要移山,码农飞上天
//鎰氬叕瑕佺Щ灞憋紝鐮佸啘椋炰笂澶?
}
3-3、Charset
这个Charset是javaNIO中的一个类,整个流程就是读取数据,然后转化为byte,也就是字符。然后重新编码成字符就OK了。
public void convertionCharset() throws IOException{
Charset charset = StandardCharsets.UTF_8;
// 从字符集中创建相应的编码和解码器
CharsetEncoder encoder = charset.newEncoder();
CharsetDecoder decoder = charset.newDecoder();
// 构造一个buffer
CharBuffer charBuffer = CharBuffer.allocate(64);
charBuffer.put('A');
charBuffer.flip();
// 将字符序列转换成字节序列
ByteBuffer bb = encoder.encode(charBuffer);
// 将字节序列转换成字符序列
bb.flip();
CharBuffer cb = decoder.decode(bb);
}
3-4、上面3种解决不了,用第四种办法
适用于 读取文本文件 txt文件 等。
在web开发中,tomcat对于传输的字符串都是采用iso-8859-1编码/解码方式。而客户端(浏览器端对于中文都是用gbk或utf-8中文编码/解码方式),所以传到后台都会是乱码的。
容器一般都是有处理的,所以中文能正常显示和存储。但有些情况也是会出现乱码的,解决方法如下:
String b = new String(str.getBytes("iso-8859-1","客户端的编码/解码方式")//中文解码方式一般用的是utf-8或者gbk。
如: String b1 = new String(str.getBytes("iso-8859-1","utf-8");
结论:了保证双方数据一致性,双方在读和写的过程中使用的编码一定要一致,用不相同的编码翻译过的数据就不能逆向使用。