基于Cassandra的分布式存储数据一致性算法研究
基于Cassandra的分布式存储数据一致性算法研究 技术报告
目录
-
- 基于Cassandra的分布式存储数据一致性算法研究 技术报告
- 一、分布式数据一致性概述
-
- 1.1 CAP定理
- 1.2 BASE理论
- 1.3 分布式数据服务中的不同一致性级别
- 二、Cassandra初探
-
- 2.1 Cassandra概述
- 2.2 Cassandra数据分区策略
- 2.3 cassandra数据一致性策略
-
- 2.3.1 逆熵机制
- 2.3.3 数据写入过程
- 2.3.4 可调节的读写一致性
- 2.3.4 NWR策略
- 2.4 CQL操作Cassandra
- 三、Cassandra分布式集群搭建
-
- 3.1 集群环境
- 3.2 IP地址配置过程
- 3.1.3 Cassandra配置过程
- 四、分布式一致性协议概述
-
- 4.1 拜占庭将军问题
- 4.2 Gossip协议
- 4.3 Pow协议
- 4.4 Paxos协议
- 4.5 Raft协议
-
- 4.5.1 Raft概述
- 4.5.2 Raft算法流程
- 五、Cassandra不同一致性级别性能测试实验
-
- 5.1 YCSB简述
- 5.2 实验内容
- 5.3 实验过程
- 5.3 实验结果
- 六、总结与展望
- 参考文献
一、分布式数据一致性概述
1.1 CAP定理
CAP定理由加州大学伯克利分校Eric Brewer教授提出,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)三者不可兼得。并且由于分布式系统必须进行网络分区,将系统部署在不同的数据中心、节点上,故而分区容错性也就是CAP定义中的P必须实现。所以,当前的分布式系统只能在C和A,也就是一致性和可用性之间做出权衡与取舍,不存在完全的CAP三者兼顾的分布式系统。

与关系型数据库ACID理论相比,CAP理论的一致性针对的是数据副本,保证同样的一个数据在集群中所有不同服务器上的副本都是相同的,并且达到这种一致性的数据复制需要延迟时间;而ACID的一致性针对的是提交的事务,在事务开始之前和事务结束以后,关系型数据库的完整性约束不能破坏,也就是说数据库事务不能破坏数据的完整性以及业务逻辑上的一致性。
1.2 BASE理论
在CAP定理提出以后,由于存在一部分观点将分布式系统的可用性与一致性简单的分隔开来,形成了错误的观点,eBay的工程师在长期的分布式系统设计与实践之中提出了BASE理论。BASE理论主要阐述了再分布式系统中的可用性与一致性并不是简单的0和1的关系,而是0%到100%的渐进式关系。核心观点是我们虽然无法在分布式系统中始终保持强一致性,但是可以根据具体的业务特点、系统性能需求来调节数据一致性的级别,最终使得系统达到一个最终一致性的阶段,只是达到这个步骤所产生的延迟存在差异。
BASE理论的内容如下
- 基本可用(Basically Available)
基本可用是指系统即时出现短暂故障,但仍然能够持续提供服务,与正常系统相比只存在性能上的损失和功能上的损失。性能上的损失主要表现在延迟时间增大,功能上的损失则是例如电商网站秒杀活动时引导部分用户降级,以确保购物系统稳定性。 - 软状态(Soft State)
软状态是指分布式系统在维护各个节点一致性时的中间状态,这种状态并不影响分布式系统的可用性。具体是指不同节点在同步各自数据期间存在的一种延迟状态 - 最终一致性(Eventually Consistent)
最终一致性是指分布式系统在经过了软状态的数据同步更新后,能在延迟时间结束后达到数据一致的状态,Cassandra自身的实现就是采用最终一致性的策略。
综上,BASE理论否定了对于CAP定理错误的解读,适用于大规模分布式系统,为系统的高可用、易于拓展的需求奠定理论基础。
1.3 分布式数据服务中的不同一致性级别
根据CAP定理和BASE理论,分布式系统在提供数据服务时需要考虑到业务的需求从而设置一致性级别。目前研究表明的一致性级别主要分为:强一致性、弱一致性、最终一致性。
- 强一致性
强一致性要求最为严格,也最为符合用户直觉,任何用户在使用系统时,要求系统写入的数据直接同步更新到所有节点,用户读取数据时保证就是当时写入的值。也就是说任何写操作都立即进行同步,任何读进程都是最新的值。这种策略适用于安全性需求很高的场景如银行存取款业务。
但强一致性也会导致可用性非常低,对系统性能影响极大。 - 弱一致性
弱一致性是指分布式系统在接收到请求后立即返回,接下来再执行存放数据的同步和更新操作,不承诺立即可以读到写入的值,也不具体承诺多久之后数据能够达到一致,但会尽可能保证到某个时间级别后,数据能够达到一致状态。 - 最终一致性
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。
这种方式在分布式系统中得到应用,类似Cassandra的AP型分布式数据库都采用最终一致性的策略。
二、Cassandra初探
2.1 Cassandra概述
Cassandra是一套于2008年开源的NoSQL分布式系统,最初由facebook开发,集BigTable的数据模型与Dynamo的完全分布式架构于一身。源代码由Java编写,运行环境则需要JDK1.8和Python2.7以上(cassandra-3.1.1),可以在Apache的开源站点获取Cassandra。

Cassandra名称来源于古希腊神话的凶事预言家,logo自然而然的设计为一只放光的预言之眼,个人理解的寓意是“提前预见不可靠分布式系统中的故障”。确实,cassandra官方文档首页就声明其特点:“Manage massive amounts of data, fast, without losing sleep”,管理海量数据而不存在单点故障。
不存在任何单点故障、线性拓展、去中心化,构成了Cassandra的强大优势。
2.2 Cassandra数据分区策略
Cassandra使用令牌环进行一致性哈希,将每个节点映射到连续哈希环上的一个或多个令牌来对所存储数据进行分区存放,并且受具体键空间的副本数量策略影响。
相比朴素的一致性哈希,Cassandra的一致性哈希策略将所有节点根据哈希值形成环,环的哈希值取值范围为[0~2^32-1],n个数据节点随机分布在哈希环上,形成n个range,即哈希值范围,再将所存储的数据进行一致性哈希,分布在哈希环上。每个range哈希值范围都有一个主节点与之对应,在键空间副本数量为1时,数据会保存到哈希环所在range范围内的主节点上,副本数量增加时,则会依次向后递推保存在副本数量的不同节点上。 这种方式与直接进行哈希取模相比的优势在于提升了Cassandra的伸缩性。在简单的哈希取模中,添加、删除一个节点的数据移动时间复杂度可以达到O(n)级别,而在令牌环一致性哈希内,具有M个数据记录、N个节点的增加、删除节点操作时间复杂度仅为O(M/N),在性能上有很大提升。
这种方式与直接进行哈希取模相比的优势在于提升了Cassandra的伸缩性。在简单的哈希取模中,添加、删除一个节点的数据移动时间复杂度可以达到O(n)级别,而在令牌环一致性哈希内,具有M个数据记录、N个节点的增加、删除节点操作时间复杂度仅为O(M/N),在性能上有很大提升。
但是这样的设计也存在一个问题,就是假如两个物理节点靠的很近,则会导致一台机器拼命工作,另外一台机器饥饿的问题,同样的还会存在机器处理能力不均匀等问题,故无法避免负载上的不均衡。所以,Cassandra的设计中增加了虚拟节点这一负载均衡策略,即每个物理节点多个令牌,映射到环上多个虚拟节点,以实现负载均衡。
2.3 cassandra数据一致性策略
2.3.1 逆熵机制
在cassandra中依靠Gossip协议并配合Merkle Tree检查机制实现逆熵,在杂乱无章的通信之中寻求最终的一致,节点之间定期互相检查数据对象的一致性。并且,Gossip是一种P2P的点对点对等协议,不存在主节点,每个节点靠线程支配每隔一秒使用TCP协议随机向其他节点交换信息,交换的信息包括自己的信息和他们所知道的信息,依靠版本号判断消息是否更新,用新消息覆盖掉旧消息。cassandra集群内节点故障检测和恢复都是通过Gossip实现。
Cassandra群集中的每个节点都独立并定期运行Gossip任务。集群中的每个节点每秒完成以下任务:
- 更新本地节点的心跳版本,并构造集群内每个节点状态的本地视图;
- 在集群中随机选择一个其他节点来交换带有的信息;
- 在一定概率下尝试与任何无法到达的节点(如果存在)交换信息;
- 若步骤2不发生,则尝试与任意一个seeds节点交换信息。
整体上,Gossip算法在运行时可以退化成一颗多叉树,容易得出其算法执行时间复杂度为O(logN),N为节点数量,高效实现了最终一致性。
而Merkle Tree则是构建一颗叶子全部是节点存储数据的哈希值的哈希树,所有分支结点都是子结点所存放哈希值的哈希值。在节点数据一致性比较中直接进行哈希树根结点比较,如果数据一致,则所有叶子结点值相同,自底向上依次生成的哈希值也相同,故两个节点生成Merkle Tree的根结点也相同,如果根结点不同,则可以快速的顺藤摸瓜找到不同的叶子,也就可以快速找到不一致的数据进行修复,最终实现在不同节点数据比对中实现最终一致性。
2.3.3 数据写入过程
Cassandra是一个写优先的分布式存储系统,写入、更新、删除都采用写入操作,牺牲部分读性能换取高性能写。
数据写入步骤如下:
- 将数据的操作日志写到磁盘CommitLog,即Cassandra.yaml配置文件指定的提交日志文件路径下;
- 将数据写入Memtable,即处在内存中的table数据结构;
- 将Memtable数据刷入磁盘中的data路径,形成真实存储的SSTable文件;
- 将多个SSTable文件执行合并操作,完成写入。

2.3.4 可调节的读写一致性
可调节的读写一致性是Cassandra的一大优势,可以根据业务需求分别设置不同的读写一致性以适应不同场景。
| 级别 | 描述 |
|---|---|
| ONE | 只有单个副本必须响应 |
| TWO | 两个副本必须响应 |
| THREE | 三个副本必须响应 |
| QUORUM | 多数副本(n / 2 +1)必须响应 |
| ALL | 所有副本都必须响应 |
| ANY | 仅写操作支持,单副本响应,一致性最低,可用性最高 |
除上表所示内容之外,还存在诸如LOCAL_QUORUM、EACH_QUORUM、LOCAL_ONE三个级别,这三种情况在多数据中心情况下使用,不做赘述。
Cassandra默认的一致性级别为ONE,可以通过cqlsh工具的CONSISTENT命令来进行查看
 针对经常性使用的QUORUM策略,接下来引入NWR策略进行讲解。
针对经常性使用的QUORUM策略,接下来引入NWR策略进行讲解。
2.3.4 NWR策略
NWR策略广泛应用于NoSQL分布式系统的一致性级别控制中,其中N代表系统内同一份数据在系统中所具有的副本数,W表示完成一次写操作需要成功写入的最小副本数,R则代表一次读操作需要成功读取的最小副本数。
当W+R>N时,例如有5个副本,一个写请求写入3个副本,一次读请求读出3个副本,满足W+R>N。效果图如下:
 由于读写必定发生重叠,显然在读请求时至少会读出一个写请求写入的数据,故当W+R>N时系统是满足强一致性的。
由于读写必定发生重叠,显然在读请求时至少会读出一个写请求写入的数据,故当W+R>N时系统是满足强一致性的。
而当W+R<=N时,例如W=2、R=3、N=5,则可能会出现如下图所示读写不一致情况:
 此时写集合为{Node1,Node3},读集合为{Node2,Node4,Node5},没有产生重叠,导致读写不一致。
此时写集合为{Node1,Node3},读集合为{Node2,Node4,Node5},没有产生重叠,导致读写不一致。
Cassandra基于NWR策略实现了QUORUM一致性策略,要求副本中的多数派(N/2+1)进行响应之后才返回成功。但是基于QUORUM机制还不能完全实现强一致性,在Cassandra中依靠读修复(READ REPAIR)机制进行实现。
2.4 CQL操作Cassandra
CQL为Cassandra Query Language的缩写,目前作为Cassandra默认并且主要的交互接口。CQL和SQL语法很相似,主要特性在于列不用预先定义,可以随时增删列,在表(列族)中增加字段,这个特性非常适合于分布式系统,保证了高可用;并且支持集合类型list、map、set,以及任意字节blob,计数器列count,时间戳timestamp等数据类型。
值得注意的是,CQL语句在创建键空间时指定了副本的复制策略和副本数量,如以下代码:
CREATE KEYSPACE test_keyspace WITH replication = {'class' : 'SimpleStrategy', 'replication_factor': 3};
该行代码指定了副本策略为SimpleStrategy,即为不考虑数据中心的简单策略,适合单数据中心,而replication_factor为3则声明该键空间在3个节点保存副本。
可以通过Cassandra的cqlsh工具通过配置文件指定端口(默认9042)连接到Cassandra数据库,当然也可以通过各种图形化工具如TablePlus连接数据库。
针对使用CQL语句对Cassandra进行增删改查的操作,可以通过com.datastax.cassandra的Java客户端驱动编程实现,实例程序如下:
<dependency>
<groupId>com.datastax.cassandragroupId>
<artifactId>cassandra-driver-coreartifactId>
<version>3.6.0version>
dependency>
package day0409;
import java.util.List;
import com.datastax.driver.core.BoundStatement;
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.PreparedStatement;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
/*
使用QueryBuilder动态构建CQL的同时使用PreparedStatement预定义参数
*/
public class Main{
public static void main(String[] args) {
Cluster cluster = null;
Session session = null;
try {
// 定义一个cluster类
cluster = Cluster.builder().addContactPoint("192.168.84.130").build();
// 获取session对象
session = cluster.connect();
//创建键空间
String createKeySpaceCQL = "create keyspace if not exists "
+"mykeyspace01 with replication={'class':'SimpleStrategy','replication_factor':3}";
session.execute(createKeySpaceCQL);
//创建列族(表)
String createTableCQL = "create table if not exists "
+"mykeyspace01.student(name varchar primary key,age int)";
session.execute(createTableCQL);
// 插入数据
PreparedStatement insertStatement =
session.prepare("insert into mykeyspace01.student(name,age) values(?, ?)");
BoundStatement bind = insertStatement.bind("lisi", 27);
session.execute(bind);
// 查询数据
query03(session);
// 修改数据
PreparedStatement updateStatement =
session.prepare("update mykeyspace01.student set age=? where name=?");
session.execute(updateStatement.bind(28, "lisi"));
query03(session);
// 删除数据
PreparedStatement dellteStatement =
session.prepare("delete from mykeyspace01.student where name=?");
session.execute(dellteStatement.bind("lisi"));
query03(session);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
session.close();
cluster.close();
}
}
private static void query03(Session session) {
System.out.println("-----------开始查询---------------");
PreparedStatement statement =
session.prepare("select * from mykeyspace01.student where name=?");
BoundStatement bind = statement.bind("lisi");
ResultSet rs = session.execute(bind);
List<Row> dataList = rs.all();
for (Row row : dataList) {
System.out.println("==>name:" + row.getString("name"));
System.out.println("==>age:" + row.getInt("age"));
}
System.out.println("-------------结束查询-------------");
}
}
进行断点调试,单步执行,在数据库中使用cqlsh进行SELECT观察到对应表实时数据。

三、Cassandra分布式集群搭建
3.1 集群环境
因条件有限,本文所搭建Cassandra分布式集群采用伪分布式方式,在个人笔记本电脑内使用VMware Workstation Pro创建三台虚拟Linux服务器,分别在三台虚拟机服务器上配置cassandra节点,三台虚拟机均使用NAT模式配置静态内网IP地址,并关闭防火墙。
相关配置清单如下
- 物理主机CPU:Intel i5-1135G7 八核16线程 主频2.40GHz
- 物理主机内存:16GB(可用15.8GB)
- 物理主机操作系统Windows10 64位
- 虚拟节点服务器操作系统:CentOS7.6
- 虚拟节点CPU核心数:2*1
- 虚拟节点内存:2GB
- Cassandra版本:3.11稳定版
- JDK1.8、Python2.7
- 远程连接工具:MobaXterm
- IP地址设置:
| 主机名 | IP地址 | mask |
|---|---|---|
| Cassandra | 192.168.84.128 | 255.255.255.0 |
| seed1 | 192.168.84.129 | 255.255.255.0 |
| seed2 | 192.168.84.130 | 255.255.255.0 |
| 物理主机 | 192.168.84.2 | 255.255.255.0 |
注意这里修改了主机名称后要vim /etc/hosts修改hosts文件内的主机名,否则启动节点时Gossip线程启动发送消息会报错。
本文所述集群配置了两个seed节点{seed1,seed2},需要指出的是Cassandra不存在主节点,seed节点的意义在于能够让集群添加新的节点,若无seed,则不能再添加新节点。而且seed节点要先启动,若两台seed都没启动就启动非seed节点,将直接启动报错。只要启动了一台seed节点,就可以线性的递增设备增强集群性能,推荐在集群内设置多个seed节点。
3.2 IP地址配置过程
配置IP地址是一个重要过程,是集群能够顺利通信的基础,具体步骤如下:
- 配置物理机静态内网地址
windows10系统可以直接点右下角图标再点网络设置进入配置界面

2. 进入更改适配器选项
 3. 选择虚拟机使用的适配器
3. 选择虚拟机使用的适配器

4. 选中后右键属性,点Internet协议版本4

5. 配置静态IP地址作为三台虚拟机的网关IP

6. 配置虚拟网络编辑器
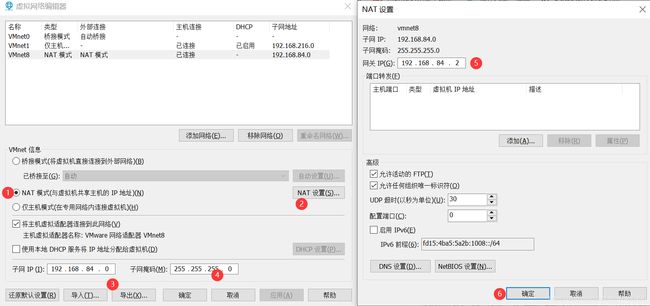
并且注意把每台虚拟机设置为NAT模式

7. 进入虚拟机CentOS内配置静态内网IP
远程连接上虚拟机后,使用cd /etc/sysconfig/network-scripts/命令切换到网络相关配置目录,注意这里要修改的文件是以ifcfg-eno为前缀,后面的数字不同机器不一样。

8. 使用vim工具修改为静态IP地址
IPADDR:该节点要配置的内网IP
GATEWAY:节点路由,在之前的虚拟网络编辑器中配置过,和主机配置的IP地址一致
NETMASK:子网掩码,常规知识
DNS1/DNS2:和物理主机前面配置的一致即可

以上就是集群IP地址配置的全过程,下图为本集群网络拓扑结构:
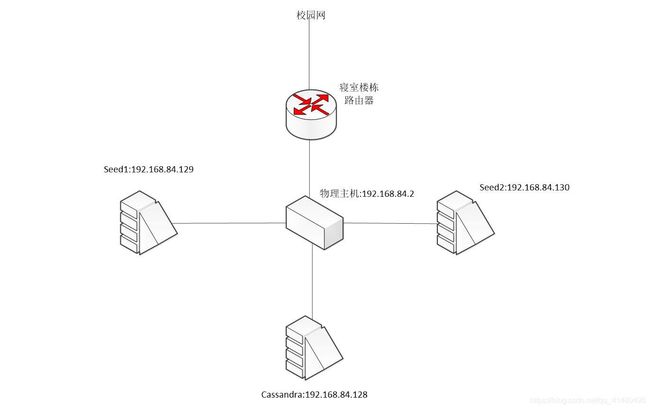
3.1.3 Cassandra配置过程
- 工作目录创建
由于搭建的是一套分布式集群,每台虚拟机上都搭建一套相同的Cassandra,为了方便管理和维护,本文所述集群将使用自定义的commitlog、data、hints、saved_caches路径。
切换到根路径/,接着使用mkdir cassandra创建主目录,以此类推建立以下目录结构

其中app存放cassandra应用程序的程序根目录和数据存放目录,package存放程序安装包和相关依赖。当然这里是考虑本集群测试的场景,如果大规模应用的话data、commitlog等最好存放在不同磁盘以提升并行性能。
2. cassandra程序安装
安装cassandra之前需要确保虚拟机系统安装JDK和Python,使用3.11版本时JDK1.8和Python2.7即可,可以通过yum工具直接下载或者直接本机下载远程上传到/cassandra/package目录下解压并配置系统变量,不做赘述。
接着从Apache Cassandra开源网站下载Cassandra压缩包,直接将程序解压到cassandra/app/cassandraRoot中即可。
3. 修改cassandra.yaml配置文件
主要配置内容如下:
# 第10行 用于标识集群名称 识别同一个集群
cluster_name: 'wxCassandra Cluster'
# 第73行 Cassandra存储hint目录 未自定义则使用默认
hints_directory: /cassandra/app/DATA/hints
# 第190行 Cassandra真实SSTable存储位置
data_file_directories:
- /cassandra/app/DATA/data
# 第196行 提交日志存储位置
commitlog_directory: /cassandra/app/DATA/commitlog
# 第368行 缓存数据保存位置
saved_caches_directory: /cassandra/app/DATA/saved_caches
#416行开始 seed相关配置
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
#以,方式隔开存放各个seed节点IP地址
- seeds: "192.168.84.129,192.168.84.130"
#第612行和第689行的两个地址 均改成当前节点IP
listen_address: 192.168.84.128
rpc_address: 192.168.84.128
当然这里也要注意细节比如“:”后面的空格不能省略,“-”后面也要带空格。
- 启动集群
完成配置后,cd /cassandra/app/cassandraRoot后输入bin/cassandra -R即可在后台运行cassandra服务,注意先启动seed节点。
三个节点集群启动成功如下图:



通过三个节点的启动日志可以观察到Gossip协议在集群初始阶段的响应过程。
集群启动后,输入bin/nodetool status查看集群各节点状态

至此,Cassandra集群搭建完毕。
四、分布式一致性协议概述
4.1 拜占庭将军问题
古老的拜占庭帝国,幅员辽阔,国土分成大量的军区,每个军区有一个将军,但是相对来说兵力有限;在遭遇战争时,各个将军需要联合起来对抗敌军,一起进攻或者一起撤退,依靠信使进行通信;可是若信使被敌军利用,或者出现拥兵自重准备联合外敌造反,也就是恶意传令误导友军的将军,很有可能会导致传令出现问题,每个将军之间号令不齐,最终导致战争失败,这就是著名的拜占庭将军问题。
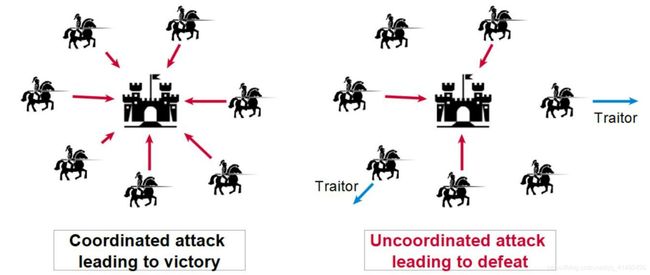
拜占庭将军问题是由莱斯利·兰伯特提出的点对点通信中的基本问题,通过对拜占庭帝国将军之间通信存在的问题间接论述了在存在消息丢失的不可靠信道上试图通过消息传递的方式达到一致性是不可能的。
延伸到分布式一致性协议上来讲,拜占庭将军问题存在的情况其实都真实反映一致性协议需要考虑的种种问题,例如硬件错误、网络拥塞、恶意攻击以及各种未知错误。
目前的主流一致性协议有诸如Gossip、Pow这样存在拜占庭将军问题但尽量解决的多主一致性协议,也有诸如Paxos、Raft这样的避免拜占庭将军问题的单主一致性协议。
4.2 Gossip协议
Gossip又被称为流行病算法,它与流行病毒在人群中传播的性质类似,由初始的几个节点向周围互相传播,到后期的大规模互相传播,最终达到一致性。
Gossip协议广泛应用于P2P对等网络,在Cassandra、Redis等对等分布式存储系统中得到应用,并且如路由器泛洪算法也是采用Gossip的思想。
4.3 Pow协议
Pow协议即工作量证明算法(Proof-of-work),被应用在比特币与区块链中,只有某个节点工作量足够大才能获得主动权。
为了尽量解决拜占庭将军问题,Pow协议让所有竞争者进行计算能力上的较量,竞争者消耗大量的硬件算力获得比特币。如果此时有恶意节点想要对平台进行破坏,那么至少该节点要达到整个平台硬件算力的一半,使得搞破坏的节点需要付出比收益更大的代价,从而扼杀其破坏动机,间接维护了平台的安全性。
4.4 Paxos协议
Paxos一致性算法由分布式领域专家Lamport提出,被认为是分布式共识算法的根本,Raft就是从Paxos协议改进而来,该协议中分布式系统内的节点存在三种角色,分别是提议者、接受者、学习者,同时每个节点可以同时作为多种角色。
Paxos的执行过程大致如下:
- 提议者向接收者发送预请求[N],N为版本号,若该接受者之前接受过其他版本号>N的请求,则会拒绝该预请求,否则接受该请求并拒绝此后到来的更低版本请求,并向提议者发送接受许可。
- 在提议者明确接受者收到发送的请求之后,也就是收到接受许可之后,便发送正式请求[N,V],其中N为上一步骤中请求的版本号,V为请求发送的值。
- 如果在这期间没有其他节点发送更高版本号的请求,在正式接受到提议者发来的版本号之后,接受者就正式将此[N,V]发给学习者和原来的提议者,并且之后到来的其他节点请求都打回并且告诉他们现在的V值。
- 学习者最终根据各个接受者的结果进行数据存储,不参与共识协商,只接受达成共识的值。

初步查看该协议可能会觉得难以理解,其实Lamport在其论文原文中就有一段生动形象的表述:
希腊城邦中的一些位高权重的人们(“发起者”)会提出新的"法案",这些法案需要立法委员(“接收者”)达成一致即多数同意才能通过。于是权贵们会预先给立法委员一些金钱,让他们通过自己的法案,这对应的就是"预请求",如果立法委员已经收到过更高贿赂的"预请求",他们会拒绝,否则会同意。权贵们贿赂成功后,会告诉立法委员新的法案,在收到新法案之前,如果立法委员没有收到更高的贿赂,他们会选择接受这个法案,否则会拒绝。在立法委员接受法案后便立即提交上层,之后的任何贿赂由于已经交上去了法案,无法修改,也就只能告诉权贵们现在已经上交的法案。
以上就是Paxos协议的基本内容,由于Paxos过于理论化,难以直接工程化,实现困难,于是工业界在Paxos之上进行改良,设计出了如Raft等优秀的单主一致性算法。
4.5 Raft协议
4.5.1 Raft概述
Raft协议是斯坦福大学Diego Ongaro、John Ousterhout两人于2013年在论文中提出的一种更易于理解的分布式共识算法,本质上是继承了Paxos协议思想,但依靠其模块化的拆分和简化的设计使得Raft算法在工程上更容易实现,Raft 把一致性协议划分为Leader选举、日志复制、状态机等低耦合模块。
Raft集群中每个节点有三种状态:领导者、候选人、跟随者。
- 追随者:完全被动,不能发送任何请求,只接受并响应来自领导者和候选人的信息,每个节点启动后的初始状态一定是追随者,并且保持持续性进入随机倒计时的状态。
- 候选人:用来竞选一个新领导者,并且由追随者触发超时发生身份转变产生。
- 领导者:处理所有来自客户端的请求,以及复制自身日志到所有追随者。
三种身份状态转换图如下:

Raft的特点是强领导制,系统中必须存在并且同一时刻只能有一个领导,只有领导接受从客户端发送来的请求,并主动向所有跟随者发送“心跳节拍”维持领导地位。
4.5.2 Raft算法流程
Raft算法的执行逻辑在其每一个时间片段内可以分成选举阶段和日志传输阶段,和Paxos不同的是Raft算法的日志是连续并且按序传输的。按照Raft论文原文描述,Raft执行中的每个时间片段为一个term,相当于一届任期时间段,其逻辑时间片段图如下:

Raft算法具体执行步骤如下:
- 在分布式集群初始化阶段,每个节点都是跟随者身份,此时系统为每个节点开启一个150ms~300ms的随机倒计时,在倒计时结束后节点成为候选人,并且向自己投一票,再向其他节点发起“拉票”请求。如果某个非候选人节点,也就是倒计时还未结束的节点收到拉票通知并且他之前没投票,则会给这位抢占先机的候选人投票并且不再为其他候选人投票,将投票信息发送给候选人。
- 得票数最多的候选人成为领导者,并且获得任期,在任期内其他节点立即成为追随者。领导者不断以一个时间间隔向追随者发送心跳广播,以维持自己领导地位,否则一旦有追随者发现没收到广播请求,在随机的倒计时结束后就会“自立”为候选人并要求其他人投票。
- 客户端请求只向集群领导者发送,请求到达领导者后领导者先写入本节点日志,然后再发送写日志广播给所有追随者。
- 追随者收到领导者的写日志广播后,只要不在宕机状态,就将日志写入本节点日志中,并向领导发送写日志成功广播。
- 领导者收到多数派追随者写日志成功的广播后,将存放的日志提交至系统,完成数据写入,并向所有追随者发送写入数据广播。
- 追随者在接收到写入数据广播后,立即将日志数据进行写入。
五、Cassandra不同一致性级别性能测试实验
5.1 YCSB简述
ycsb全程为Yahoo! Cloud Serving Benchmark,是一款雅虎公司开发的分布式系统开源测试工具。在配置ycsb之前需要先配置Maven3环境以所需提供依赖包,本文选择Maven3.8.1、ycsb0.17.0,将ycsb环境及运行程序放在集群非seed节点上。如下图,在app目录下解压并重命名ycsb程序包,并测试maven环境。

ycsb对分布式系统进行测试的步骤如下:
- 配置相关参数文件,可以参考workloads目录下的文件参数,对测试数据的数据量、操作数、各种操作所占百分比,以及操作在概率上的分布分别进行配置;
- 使用load指令运行程序,在测试键空间的指定TABLE内加载预先定义的数据行。
- 待加载完毕,通过run指令执行测试,在load数据的基础上通过workload配置的参数去执行测试实验。
- 得到run指令输出日志,主要记录总执行时间、吞吐量、读写平均延迟。
工作负载主要参数:
- recordcount:测试记录数
- operationcount:测试操作数
- readproportion:读取操作所占百分比
- updateproportion:更新操作所占百分比
- insertproportion:插入操作所占百分比
- scanproportion:扫描操作所占百分比
- requestdistribution:操作在概率上分布类型
- threadcount:操作线程数
以上参数均在workloads目录下使用vim进行配置,可以使用cp命令拷贝自带的几个workload文件快速更改配置。同时,以上参数在load、run指令中均可使用-p附带参数进行覆盖,灵活性强。
5.2 实验内容
根据上述分析,本文设计Cassandra分布式集群在不同一致性算法下的延迟以及吞吐量测试实验。由于个人水平有限,使用ant工具编译生成IDEA项目并研究数日Cassandra源代码和大量硕博学位论文后无果,故无法在Cassandra中真正修改一致性算法并重新编译为可执行程序。本文所述实验使用ONE、QUORUM、ALL三种Cassandra自带的一致性级别分别模拟实现弱一致性算法、多数派算法、强一致性算法三种算法。
- ONE级别实现弱一致性算法:当采用ONE一致性级别时,对于插入或者删除操作,执行节点仅保证该修改已经写到一个存储节点的commitlog和Memtable中;对于读操作,执行节点在获得一个存储节点上的数据之后立即返回结果。
- QUORUM级别实现多数派算法:当采用QUORUM一致性级别且设置副本数为N时,对于插入和删除,保证写入(N/2)+1个副本节点才向客户端返回成功,对于读取操作,则向(N/2)+1个副本节点进行查询,返回时间戳最新的数据。即写入和读取操作都按照NWR策略争取到多数节点的支持。
- ALL级别实现强一致性算法:当采用ALL级别时,执行写入操作时节点保证数据写入所有副本节点才向客户端返回成功,执行读取操作时节点向所有副本进行查询并返回最新时间戳数据。由于本实验集群节点数为3并且测试键空间副本数也为3,故设置ALL一致性级别即实现强一致性。
实验内容主要是在已经部署启动的Cassandra集群上依次设置ONE、QUORUM、ALL三种一致性级别,接着在每种一致性级别下分别使用ycsb工具配置不同工作负载进行测试,实现在固定记录行数下不同线程数时不同一致性算法的性能测试实验,针对实验结果使用Excle绘制折线图并进行分析。
5.3 实验过程
(1)首先启动Cassandra集群,注意先启动seed节点再启动非seed节点,启动成功后在任意节点处于cassandraRoot目录下使用bin/nodetool status指令查看各节点状态。
 若各节点状态均为UN,则集群状态正常。
若各节点状态均为UN,则集群状态正常。
(2)接着创建ycsb测试需要的键空间和表,bin/cqlsh 192.168.84.129连接上集群数据库后,使用如下命令创建具有三个副本的键空间和测试表:
CREATE KEYSPACE ycsb WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
use ycsb;
CREATE TABLE usertable (
y_id text PRIMARY KEY,
field0 text,
field1 text,
field2 text,
field3 text,
field4 text,
field5 text,
field6 text,
field7 text,
field8 text,
field9 text
);
执行查询语句验证表创建完成和表结构

(3)在ycsb程序workloads目录下配置工作负载参数文件,分别实现如下表配置:
| 工作负载配置文件 | 读取 | 更新 | 分布 |
|---|---|---|---|
| demo1 | 50% | 50% | zipfian |
| demo2 | 95% | 5% | zipfian |
| demo3 | 5% | 95% | zipfian |
例举demo1配置如下:

(4)设置测试记录数固定为10万条,在不同线程数量[20~120,步长为10]下开展测试实验。使用如下命令在20线程情况下通过工作负载demo1加载10万条数据到ycsb键空间下usertable表中并写执行日志到outLoad.txt:
bin/ycsb load cassandra-cql -P workloads/demo1 -p operationcount=100000 -p
recordcount=100000 -p fieldlength=100 -p fieldcount=10 -threads 20 -s > outLoad.txt
在另一个节点使用cqlsh连接数据库,进入ycsb键空间使用如下命令验证10万条数据加载完毕:
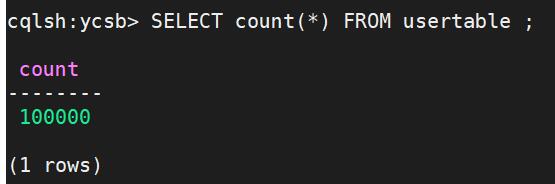
再使用如下命令运行工作负载,并写日志到outRun.txt:
bin/ycsb run cassandra-cql -P workloads/demo1 -p operationcount=100000 -p
recordcount=100000 -p fieldlength=100 -p fieldcount=10 -threads 20 -s > outRun.txt
测试运行结束后,vim outRun.txt记录总执行时间、吞吐量、读/写延迟共四个数据到Excle表格中:

可以直观发现,在demo1的工作负载下读写各占一半,但明显写快于读。
每当切换工作负载时,要先清空测试表中数据并重新将工作负载测试记录装载。切换到启动了cqlsh工具的节点,使用TRUNCATE将表截断,并验证表是否已经清空。

继续调整线程数重复实验内容,从20以步长10依次递增到120线程为止,分别进行实验;完成demo1的负载测试后,再完成demo2、demo3的负载测试;完成ONE一致性级别的测试后,再切换到QUORUM、ALL一致性级别重复实验。本实验针对10万行数据记录,共进行测试实验99组,得出实验数据如下表:



5.3 实验结果
根据实验所得99组数据,分别绘制在工作负载demo1、demo2、demo3情况下的测试结果折线图,折线图中纵坐标为标题,横坐标为测试线程数,所有数据均在测试记录行数10万行情况下取得。
(1)半读半写工作负载demo1:




由上图可以看出,在半读半写情形下,就吞吐量而言QUORUM一致性策略较好,ONE一致性策略最差;平均读延迟和平均写延迟方面则ONE依然最差,而ALL、QUORUM相差不大;测试程序运行时间上来看ONE也是耗时最多的,QUORUM在线程数量少时有一定优势。
(2)主要读(95%)工作负载demo2:

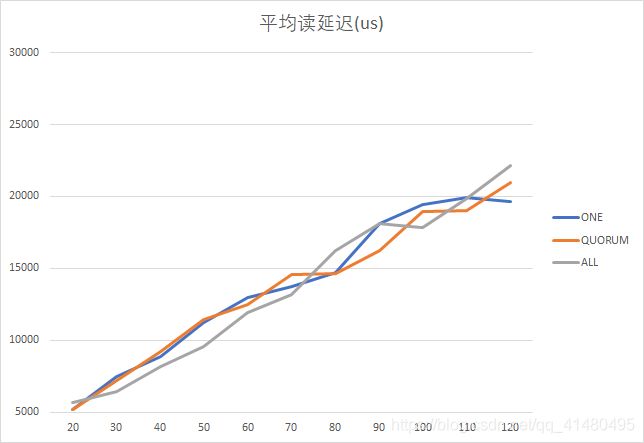


由上图可以看出,在主读情况下,ALL一致性策略在线程数量70的情况下各方面都表现优秀,具有高吞吐量、低读写延迟的特点;而ONE一致性策略在线程数大于100时各方面都出现转折,表现出了良好的性能;QUORUM一致性策略的表现则很平稳。
(3)主写(95%)工作负载demo3:
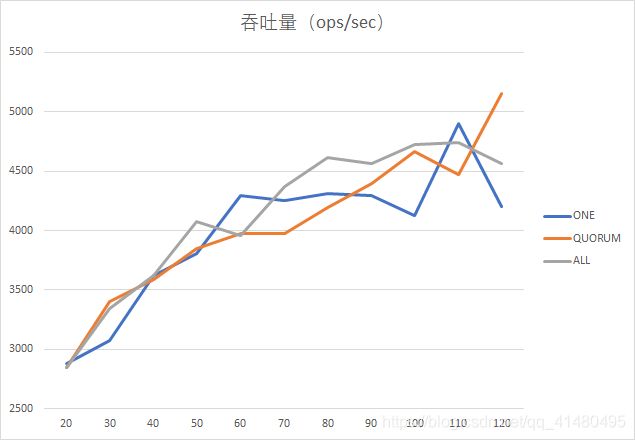



由上图可以看出,在主写情形下,当线程数量少于40时ONE一致性策略表现不佳,并且线程数量大于110时ONE一致性策略的性能突然恶化,仅在图表的中间区域保持稳定;当线程数小于40时QUORUM和ALL两种一致性策略区别不大,但当线程数处于[40,100]的区间时,ALL策略更好,当超过110时,QUORUM的性能开始优化。
(4)结论
本文对ONE、QUORUM,ALL三种一致性策略在不同情形之下的性能做出了一定比较,验证了其在不同并发线程数量下的吞吐量与延迟变化折线。QUORUM基于NWR的思想,是一种优秀的一致性策略,在本文所述实验中其性能得到了较好的展现。同时,针对不同的现实业务需求,应该正确调整Cassandra的一致性级别,根据实际并发情况和安全性要求对一致性算法进行调整。
六、总结与展望
在这一周里我系统的自学了关于分布式数据服务一致性的知识,并动手实现了Cassandra的分布式集群,阅读了大量的技术博客、硕博论文、外国著名文献,收获很丰富,遗憾在于没能成功的深入研究Cassandra数据库的9万余行源代码,仅对Gossip协议实现部分有所理解,尝试复现硕博论文中的对于读修复和提示移交策略的优化算法以及时钟向量算法、实时调整一致性策略的学习算法,但是没有做出来,对于Paxos、Raft算法也仅停留在理解上。所以本质上我应该没有把老师布置的任务完整实现,在这个过程中我看到了自己目前所存在的差距,思考了很多。
一周时间过的很快,在开始接到任务时难以入寐,当晚就查阅了关于Cassandra、CQL的相关资料,在知乎、B站、CSDN、博客园等国内技术交流平台寻找大量自学资源,并且在新笔记本上安装虚拟机软件,装CentOS,配置环境,第一天成功配置启动了单机版Cassandra,第二天傍晚成功配置启动三台节点的分布式集群,当然在虚拟机的NAT模式和IP地址的配置方面也踩了不少坑,所以文中介绍的较为详细。第三天比较全面的研究了CQL,并实现了Java、Python客户端CQL指令操作Cassandra,熟悉了CQL的数据类型,特别是集合类型。第四天开始在阅读大量硕博论文的基础上尝试去实现Cassandra的自定义一致性算法,但是国内网站这方面的资料基本不存在,仅有的少数几篇硕博论文上的思想可供参考,在这个过程中我体会到了科研人员的压力,我认为对我日后读研的生活有所帮助。后面在开源社区查找一致性算法相关资料,对Paxos、Raft等算法进行全面的理解,并查看了部分Cassandra源代码。到了最后两天,再难有更多收获的情况下便开始技术报告的写作。
时光虽短,逐梦不止。感谢徐子晨老师为我布置的任务,这一周的压力很大,任务比以往做过的软件开发、工程训练、数学建模等任务都要重,但我在这一周的收获也是此前从未有的,在分布式系统数据服务一致性领域已经建立起了比较完整的框架,对本科阶段学习的大数据也有了新的体会,在动手能力上则是自学了几种工具的使用以及完整搭建、维护分布式存储集群的过程,让我对平时使用的大流量应用软件工作过程有了新的理解。
最后,再次感谢徐子晨老师的信任与关照!希望在前湖的研究生时光能与老师再会。
参考文献
[1] 马凯君. Cassandra的数据一致性分析与优化[D]. 电子科技大学,2017.
[2] 蔡婷婷. 分布式数据库可协调的一致性策略的研究[D]. 大连海事大学,2017.
[3] 许春艳. NoSQL中基于向量时钟的最终一致性方法研究[D]. 华中科技大学,2014.
[3] Leslie Lamport. The part-time parliament. ACM Transactions on Computer Systems, 16(2):133–169, May 1998.
[4] Ongaro, Diego, and John Ousterhout. “In search of an understandable consensus algorithm.” 2014 {USENIX} Annual Technical Conference ({USENIX}{ATC} 14). 2014.
[5] https://cassandra.apache.org/doc/latest/
[6] https://zhuanlan.zhihu.com/p/130332285
[7] https://zhuanlan.zhihu.com/p/130974371
[8] https://zhuanlan.zhihu.com/p/127184931