分布式系统基础-分布式事务
1、数据库事务
大部分情况下,我们所说的事务都是指“数据库事务(Database Transaction)”,后来的各种非数据库的事务也都借鉴和参考了数据库事务的定义:
事务是数据库运行中的一个逻辑工作单位,工作单元内的一系列SQL命令具有原子性操作特点,这些命令要么完全成功执行,要么完全撤销或不执行,如果是后者,则表现为数据库内的最终数据没有发生任何改变。事务通常由数据库中的事务管理子系统负责处理。
数据库事务需要满足如下四个要求:
- 原子性(Atomic):事务必须是原子工作单元,对其进行数据修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):事务在完成时,必须使所有的数据都保持一致状态,事务结束时,所有的内部数据结构(如B树索引或双向链表)都必须是正确的。
- 隔离性(Isolation):由并发事务所做的修改必须与其他并发事务所做的修改隔离。
- 持久性(Duration):事务完成之后,对系统的影响是永久性的。
其中原子性(需要记录操作过程和对应结果,以便回退)、隔离性(产生锁)这两个要求,导致数据库事务的执行代价要远高于非事务性的操作。一般而言,隔离性是通过锁机制来实现的,而原子性、一致性和持久性等三个特性是通过数据库里的相关事务日志文件来实现的,这个过程中涉及大量的I/O操作。
在MySQL中,事务的相关日志文件为redo和undo文件,简单来说,redo log记录事务修改后的数据,undo log记录事务前的原始数据,由于事务随时可能需要回滚,所以在MySQL执行事务的过程中,这两个文件都会被写入数据。下面是MySQL里一个事务执行的简化过程。
- 先记录undo/redo log,确保日志刷到磁盘上持久存储。
- 更新数据记录,缓存操作并异步刷盘。
- 提交事务,在redo log中写入commit记录。
其中第3步为commit事务的操作,在这个过程中主要做以下事情。
- 清理undo段信息。
- 释放锁资源。
- 刷新redo日志,确保redo日志落盘,即使修改的数据页没有更新到磁盘,只要日志完成了,就能保证数据库的完整性和一致性。
- 清理savepoint列表。
我们可以看到,在事务执行的过程中,大量的费时操作都是在commit指令之前完成的,包括写相关的事务日志以备回滚事务或者提交,而“commit”指令所做的工作基本上可以“瞬间”完成的,在整个事务处理的过程中所占的事件比例非常少,这是事务处理的一个很重要的特点。
此外,如果在MySQL执行事务的过程中因故障终端(比如意外断电)导致数据并没有来得及持久化到磁盘中,则可以在后面通过redo log重做事务或者通过undo log回滚,从而确保数据的一致性。
2、经典的X/OpenDTP事务模型
如果一事务内的SQL要分别操作几个独立的数据库服务器上的数据,那么这种事务就变成了分布式事务了。由于分布式系统的编程难度大,而事务又是一个非常重要的功能,所以在编程方面不能有半点偏差,否则可能导致灾难性的后果,于是就有一些技术达人来研究并制定了业界首个分布式事务标准规范–X/OpenDTP,此规范提出的二阶段提交模型(2PC)与“TCP三次握手”一样,成为经典。此后J2EE也遵循了X/OpenDTP规范,设计实现了Java里的分布式事务变成接口规范–JTA。
X/OpenDTP协议设计了一个模型来描述参与分布式事务的各个角色及交互规范,如下图所示:
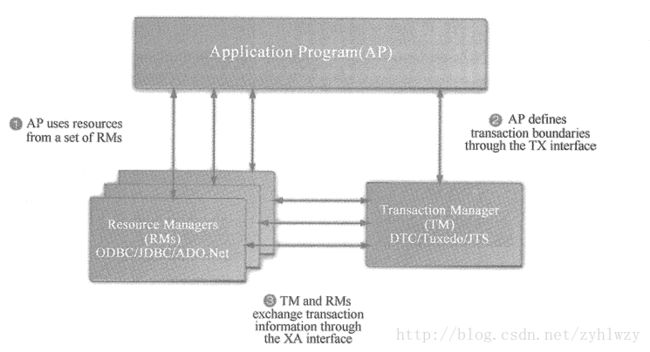
在X/OpenDTP模型中,参与事务的角色分为以下三种。
- AP:用户程序,大部分是CRUD代码的这种应用。
- RM:数据库或者很少被使用的消息中间件等。
- TM:事务管理器、事务协调者,负责接收来自用户程序(AP)发起的XA事务指令,并且调度和协调参与事务的所有RM(数据库),确保事务正确完成或者回滚。
这个模型中的几个关键点说明如下:
- AP负责触发分布式事务,这个过程中采用了特殊的事务指令(XA指令)而非普通的事务指令,这些执行是TM接管的,并发给所有相关的RM去执行。
- RM负责执行XA指令,每个RM只负责执行自己的指令。
- TM负责整个事务过程中的协调工作,检查和验证每个RM的事务执行情况。
3、X/OpenDTP二阶段提交协议
下面我们说说X/OpenDTP模型中最为知名的二阶段提交协议。在X/OpenDTP模型中,当一个分布式事务所涉及的SQL逻辑都执行完成,并到了大家(RM)要最后提交事务的关键时刻,为了避免分布式系统所固有的不可靠性导致提交事务意外失败,TM果断决定实施两步走的方案。
- 先发起投票表决,通知所有 RM先完成事务提交过程所涉及的各种复杂的准备工作,比如redo、undo日志,尽量把提交过程中所有消耗时间的操作和准备都提前完成,确保后面100%成功提交事务。如果准备工作失败,则赶紧告知TM。
- 真正提交阶段,在该阶段,TM将基于第1阶段的投票结果进行抉择,即提交或取消事务。当且仅当所有参与的RM同意提交时,TM才通知所有的RM正式提交事务,否则TM将通知所有参与的RM取消事务。RM在接收到TM发来的指令后将执行相应的操作。
下图给出了二阶段提交协议的通信过程(以两个RM为例)。
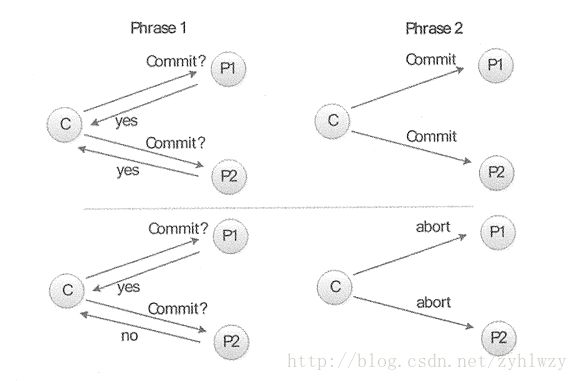
二阶段提交的精妙之处在于,它充分考虑到了分布式系统的不可靠因素,并且采用非常简单的方式(两阶段完成)就把由于系统不可靠从而导致事务提交失败的概率降到最小。下面给出了一个形象的解释过程,来说明二阶段提交时如何做到这一点的:
假如一个事务的提交过程总共需要30秒的操作,其中Prepare阶段需要花费28秒(主要是确保事务日志落地磁盘等各种耗时的I/O操作),真正的Commit阶段只需要花费两秒,那么Commit阶段发生错误的概率与Prepare阶段相比,只有它的2/28(<10%),也就是说,如果Prepare阶段成功了,则Commit阶段由于时间非常短,失败的概率很小,会大大增加分布式事务成功的概率!不得不说,二阶段提交的精妙设计洞穿分布式系统的本质。
但为什么我们在现实中很少会用到二阶段提交的XA事务呢?主要原因有以下几点。
- 互联网电商应用兴起,对事务和数据的绝对一致性要求并没有传统企业应用要求那么高。
- XA事务的介入增加了TM中间件,使得系统复杂化,而且通常支持TM的中间件都是收费的,也增加了软件成本。
- 互联网开发中的很多人并不很懂XA相关的技能。
- XA事务的性能不高,因为TM要等待RM的回应,所以为了确保事务尽量成功提交,TM等待超时的时间通常比较长,例如30秒甚至5分钟,如果RM出现故障或者响应迟缓,则整个事务的性能严重下降。
4、互联网中的分布式事务解决方案
目前互联网领域有几种流行的分布式事务解决方案,但是都没有像之前所说的XA事务一样,形成了X/OpenDTP那样的标准工业规范,而是在某些具体的行业里获得了较多的认可,下面我们对这些方案进行介绍。
4.1、业务接口整合,避免分布式事务
此方案是将一个业务流程中需要在一个事务里执行的多个相关业务接口包装整合到一个事物中,这种方式属于“就具体问题具体分析”的做法。就问题场景来说,可以将服务A、B、C整合为一个服务D来实现单一事务的业务流程服务。如果在项目一开始就考虑到分布式事务的复杂情况,则采取这种方案,精心规划和设计系统,避免分布式事务;对于实在不能避免的,则采取其他措施去解决,这应该是最好的做法。
4.2、最终一致性方案之eBay模式
这是eBay于2008年公布的关于BASE准则的论文中提到的一个分布式事务解决方案,在业界影响比较大。eBay的方案其实是一个最终一致性方案,它主要采用了消息队列来辅助实现事务控制流程,方案的核心是将需要分布式处理的任务通过消息队列的方式来异步执行。如果事务失败,则可以发起人工重试的纠正流程。人工重试被更多的应用于支付场景,通过对账系统对事后问题进行处理。
支付场景:如果某个用户(user)产生了一笔交易,则需要在交易表(transaction)中增加记录,同时修改用户表的金额(余额),由于这两个表属于不同的远程服务,所以就涉及分布式事务和数据一致性的问题。
大致流程如下:
1、用户表(user)记录用户交易的汇总信息,交易表(transaction)记录交易的详细信息。
2、进行一笔交易时,需要在交易表(transaction)插入交易详情,需要更新用户表(user)中交易相关内容,比如采购总额(amt_sold),销售总额(amt_bought)等。
3、采用消息队列来分离事务:先启动一个事务,在交易表(transaction)增加记录之后,并不直接去更新用户表(user),而是将要对user表的操作动作作为消息插入消息队列中。
begin
insert into transaction values(***);
put_to_queue "update user(***)";
put_to_queue "update user(***)";
commit;注意,消息队列对transaction的操作使用同一套存储资源,因此这里的事务不涉及分布式操作。
4、开启独立进程,从消息队列上获取上述消息,进行接下来的处理过程:
for each message in queue
begain;
if message.type = '指定条件' then
update user set 指定字段=值 where 条件
else
update user set 指定字段=值 where 条件
dequeue message;
commit;
end初看这个方案没有什么问题,但实际上还未解决分布式的问题。为了使第一个事务不涉及分布式的操作,消息队列必须与transaction表使用同一套存储系统,但是是为了使第二个事务也是本地的,消息队列存储又必须与user表在一起。这两者是不可能同时满足的,我们假设消息队列与transaction表使用同一套存储资源,则后面从消息队列消费消息的逻辑可能会产生不一致的错误:数据库已经更新了user余额信息,但接下来从消息队列中删除消息时发生了异常,比如进程死机或者消息服务突发故障,则此消息还在系统中,下次又会被投递,产生消息被重复投递的问题。除非此消息的处理逻辑具有幂等性,可以重复触发,否则重复投递消息会引发事故。
那么如何解决这个问题呢?eBay给出了一个简单思路:增加一个message_applied(msg_id)来记录被成功消费过的消息,过滤重复投递的消息。
于是,上面处理流程中第4点改为下面的方式:
for each message in queue
begain;
select count(*) as cnt from message_applied where msg_id=message.id;
if cnt = 0 then
if message.type = '指定条件' then
update user set 指定字段=值 where 条件
else
update user set 指定字段=值 where 条件
end
insert into message_applied values(message.id);
end
commit;
if 上述事务成功
dequeue message;
delete from message_applied where msg_id=message.id;
end
end上述模型中的消息中间件不一定是一个标准的通用的消息中间件,也可以是一个基于数据库存储的简单实现的消息服务,这个消息服务的实现只需要保证下面几点即可:
- 消息要跟第一个事务中涉及的数据在同一个存储资源系统中,从而可以使用本地事务模型,保证事务的原则性结果。
- 消息的服务性能要好。
4.3、X/OpenDTP模型的支付宝的DTS框架
DTS(Distributed Transaction Service)框架是支付宝在X/OpenDTP模型的基础上改进的一个设计,定义了类似2PC的标准两阶段接口,业务系统只需要实现对用的接口就可以使用DTS的事务功能。DTS从架构上分为xts-client和xts-server两部分,前者是一个嵌入到客户端应用的jar包,主要负责事务数据的写入和处理;后者是一个独立的系统,主要负责异常事务的恢复。DTS最大的特点是放宽了数据库的强一致约束,保证了数据的最终一致性(Eventually Consistent)。
参考:架构揭秘从分布式到微服务