基于yolov3的果园苹果识别系统研究与试验
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、 图像处理识别苹果的过程
- 2.1 图像处理识别苹果
- 2.2 苹果识别的总体流程
- 2.2.1 苹果图像的采集
- 2.2.2 苹果图像的预处理
- 二、苹果识别中图像处理的算法
- 3.1 yolov3概述
- 三、系统实现
- 4.1 苹果图像收集的时间地点
- 4.2 苹果图像处理的条件
- 4.3苹果图像处理的实验方法
- 4.4苹果图像处理的实验结果
- 结 论
- 六、 目录
概要
我国是农业大国,随着种植业的发展,我国的果业的发展也突飞猛进。山东地区是苹果种植的主要区域,由于没有实现智能化采摘,导致无法及时的销售,针对这种现象本文设计了一个基于yolov3的果园苹果识别系统,yolov3算法主要针对与图像识别处理。本文以树上苹果为研究对象,对其进行图像处理,先对苹果的图像进行预处理,制作正确格式的数据集,运用yolov3进行图像数据格式的转换,平滑处理,边缘预测,在进行训练学习,最终会得出模型,选择训练过程中正确率最高的模型,进行反复的验证,使其能够在收到新的图像信息时能够识别出苹果,并将其位置正确的标出。为后续进行处理,采摘或者果实的熟度确认都提供了基础。
关键词: 图像处理 苹果识别 深度学习
一、 图像处理识别苹果的过程
2.1 图像处理识别苹果
苹果的识别处理主要有以下几步:图像的采集,对图像进行的预处理,制作数据集,运用算法进行训练,选出较好的模型进行后续的正确率的检测。[5]
首先运用设备进行图像的收集,应用框选软件对图像中的苹果进行标记,然乎制作成数据集输入到yolov3的模型进行训练会生成许多训练模型,选择正确率较高的模型下载,应用新的图片对模型进行检测,检测没有问题即可应用到实际场景中。
2.2 苹果识别的总体流程
2.2.1 苹果图像的采集
在自然状态下对树上的苹果进行拍摄,受到天气的影响,环境的亮度会有所不同,我们需要采集不同环境亮度下的苹果图片(夜晚等特殊场景除外),受到叶子遮挡的影响我们需要进行多个角度的拍摄收集,一方面可以增加数据的总量,另一方面为后续训练做铺垫,使我们最终的模型能够识别出被叶子或者其他因素遮挡的苹果,并且对其大小轮廓进行预测。采集时要对不是熟透的苹果也进行拍摄,某些苹果品种即使熟透颜色也不会整体泛红,但是它确实已经成熟,我们针对此种情况也要考虑在内,这样也为后期颜色与叶子接近的苹果也能够识别。另外受到风力等因素影响,苹果的状态不是垂直向下,也需要进行采集,某些畸形的苹果也可进行收集,为后续有些苹果受生长环境,养料养分等众多因素导致的发育畸形也能够准确的识别和确认其位置。
2.2.2 苹果图像的预处理
(1)首先对收集到的苹果图像进行标记处理首先对图片进行标记处理,我选用了labelImg软件。运用此软件对苹果的图片进行框选,框选出正确的苹果如图1所示,对于某些苹果被叶子遮挡无法看到全貌的,我们需要进行预测,预测出正确的苹果位置,如图二所示,为后续的对其进行检测做铺垫。框选之后将会生成一个xml文件,将生成的xml文件与原图片文件的命名进行一一对应。图片的像素大小也需要进行相应的调整,需要将其调制统一大小,像素最好为450450左右,例如我就应用的300225,像素太大的话会导致其运行缓慢,也有可能运行中途报错。还需要将图片的格式进行转换,对于voc数据集的话我们需要将其转换成jpg格式,有些设备收集的照片可能不是此格式,我们需要自己进行调整,否则训练过程中将有可能报错,或者直接不能运行。
二、苹果识别中图像处理的算法
3.1 yolov3概述
Yolov3简介[6]
对于深度学习的目标检测算法主要分为两种类型:一类是one-stage的YOLO系列算法,另一类two-stage的R-CNN系列,yolov3属于一阶段模型,一阶段模型的推理速度较快,但是相对的准确度可能会下降一些。
Yolo(you look only once)算法是一阶段目标检测算法的代表,它可以只用一次完整的过程就能够对目标完成位置上的定位和类型的识别,是现在目标检测算法中速度很快的了,最新的yolo算法已经更新到第五代了,实现了多尺度预测。yolo系列算法是当前在目标检测领域常用的算法,其主要用途在对图像的识别处理上。
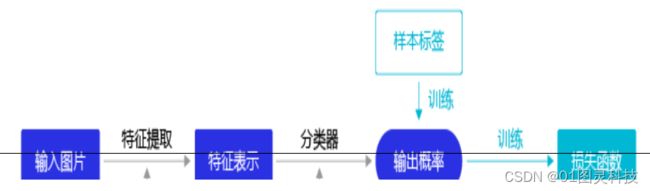
图4
yolov3目前可以实现在3个不同的地方的3个尺寸不一的特征图上使用11的卷积核进行检测[7][8],其中的2个特征图需要经过上采样和特征融合获取,Yolov3版本的主干网络是darknet-53网络如图5所示,其网络成熟更多,也运用了残差网络与上一代相比可能在处理大量的数据图片效率略低,但是他的准确率却超出上一代很多。由于残差模块的添加在解决深层次网络的图像处理上能力得到很大提升。Yolov3的功能是对图像的识别,本质上属于卷积神经网络,卷积神经网络又是深度学习的代表算法之一。因为yolov3采用了不同尺度的特征图进行预测,不同尺寸的输入图像就能够得到不同大小的输出特征图,这些最终的特征图里面就包含着检测框重要信息例如:位置信息,置信度信息,类别等,通过这些信息就能够对检测狂进行定位。另外Yolov3采用了深度可分离卷积的操作来代替传统的卷积,对于深度可分离卷积也可以分解成深度卷积和卷积核尺寸为11的点卷积的组合,二者在效果上差别不大。标准的2D卷积需要使用128个过滤器,但是深度可分卷积可以将2D卷积中的333的单个过滤器换成331的过滤器。每一个核与输入层仅有一个通道。每一个这样的卷积就能够为我们提供一个大小为551的映射图。将这些映射图叠加在一起以后可以创建出553的图像,经过这一些列操作,就可以得到大小为553的输出。其原理图如下图5:
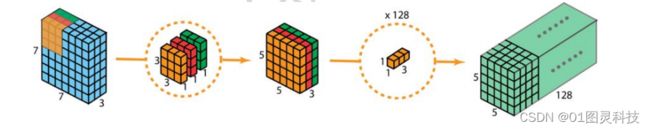
yolov3 Darknet53是一个全卷积神经网络,yolov3网络使用的是 Darknet53 作为特征提取网络,其中 yolov3只有卷积层,采用的大多数是 3*3 的卷积,并且相比于上一代取消了池化层,通过调节卷积层的步长来做到 控制输出的特征图的尺寸大小[9]。
53层卷积,每个后面都会随着bath normalization层和leaky ReLU层,因为取消了池化层所以需要用步幅为2的卷积层代替池化层进行特征图的降采过程,这样可以有效的防止池化层导致的底层网络的特征的损失,daknet53除了最后一个FC(全连接层)就相当于剩下的52个卷积当作网络主体。[10][11]
目前的图像识别要求的网络深度越来越深,但是训练时会发现在浅层网络一个被训练很好的的一个模型,到了对应的深层网络没有办法训练的更好。理论上来讲,即使不能比浅层训练的更好,但是也不能应该会比其差。然Yolov3引入了残差模块,如图6其工作原理,残差网络于告诉公路网络相比会发现,残差网络可以走“近路”,不需要进行复杂的计算。这也就导致残差网络中不会有额外的参数加入,这样计算量会大大减小,减轻负担。
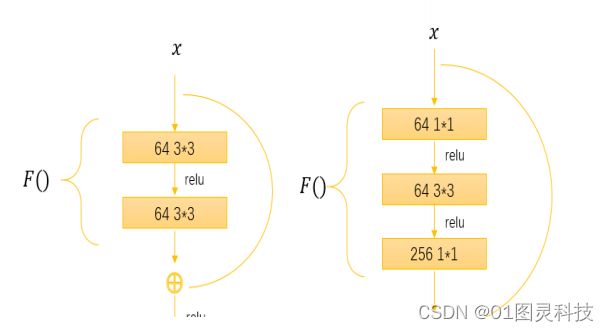
图6
正常来讲参数流动是自上而下,但是残差网络用了一个shortcut来为不相邻的我网络层之间加了一条通道加速参数流动。[12]
假如我们使用一个标准的优化算法来训练一个普通网络,没有残差网络的情况下就会清楚的看到随着网络深度的增加错会呈现出一个先减小后增加的趋势。当网络深度达到一定的深度其错误就会表现的极为明显很明显这不是我们想要看到的结果,但是有了残差网络就会不一样,如果在浅层网络训练的结果不理想,那么随着网络深度的慢慢加深,我们得到的训练结果会越来越好,产生的错误只会越来越少。
三、系统实现
4.1 苹果图像收集的时间地点
目前距离我最近的大型苹果种植区域在莱阳,现在不是苹果结果的时间,但是可以从当地村民手中收集些许苹果是结果是的图片。如图10

图10
4.2 苹果图像处理的条件
对收集到的图片进行挑选,去除某些受外界因素过大的图像信息,尽量挑选自然条件下的苹果果实,我们要尽量逢迎大众苹果的形态进行测试。对于部分因遮挡而不完整的苹果图片也要预留,这种情况没有办法避免,如果裸露在外部分较大,应对其轮廓进行预测,并且标注。如果大部分被叶子或其他遮挡物遮挡,可不进行标注。防止对模型的成功率来影响。[18][19]
4.3苹果图像处理的实验方法
经过对图片的框选之后,我们需要将图片和框选之后得到的xml文件进行读入。
这些图片通过yolo时,yolo会将其转化为416×416大小的网格,增加灰度条用于防止失真,之后图片会分成三个网格图片(13×13,26×26,52×52)在配置数据集的时候我们也需要对其格式进行转换,例如我们现在就需要voc格式的数据集。
然后需要配置运行yolov3_darknet53所需的环境,由于电脑的受限,我选择在云平台上完成使用aistudio配置好环境。先安装调试paddledetection安装成功后可进行代码调试,根据软件说明书,测试时出现图11结果即为测试成功然后将采集到的苹果图像数据进行预处理,制作好所需要的数据集。
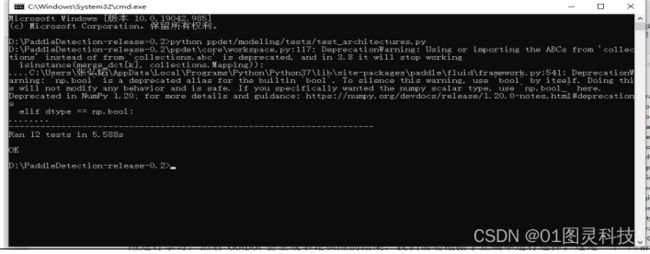
图11
将数据集传入云端平台,在本地进行训练的路径无法使用,包括其中的环境变量等配置,都需要进行更改。上传完成数据集,配置好环境,即可对图像开始训练,数据集被读入,然后经过相应的格式转换,转换成计算机可以处理识别的形式,然后对得到的数据进行平滑处理,然后在进行边缘预测,确定图像中研究对象苹果的位置,大小等信息,对其进行学习,通过yolov3_darknet53 不断的卷积以后会生成一个特征模型,然后用所得到的特征模型进行预测训练,训练开始生成的模型正确率可能会不高,一般这些模型不会被用作最后的检测,根据8:2的比例来设定训练集和测试集的,过多轮的训练进行学习,即80%的数据作为学习数据,20%的数据作为哦检查用的数据,每200轮会产生一个模型并且告诉成功率,然后output会生成多轮训练的结果,我们需要根据其正确率进行选择。
4.4苹果图像处理的实验结果
这是生成的部分模型,我设定训练20000轮,我们需要选择最好的模型进行识别,yolov3也会自己生成一个认为最成功的模型会对其进行特别的标注如图12:
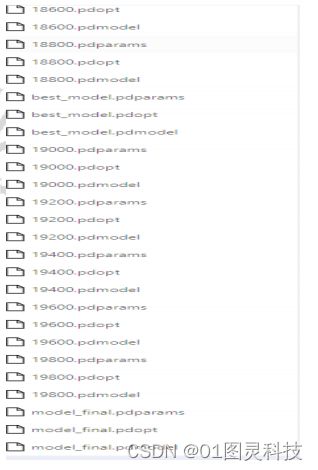
图12
因为我设定的轮数为20000轮,程序结束如图说明已经完成训练,已生成模型,从图可以看出最好的模型为18800轮的,所以测试的时候我选择18800的模型。如图13
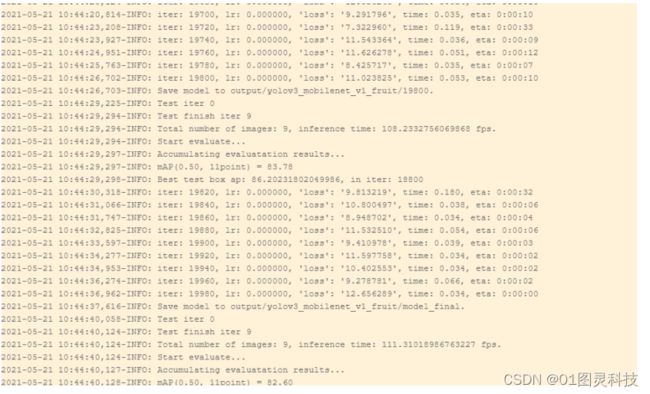
图13
结 论
本文制作了基于yolov3的果园苹果识别系统,选择以果园的苹果为目标对象。主要系统的介绍了图像的获取,预处理等过程。
本文的试验结论如下:
1.通过软件对图像标注.确保其准确性,在后续的训练中不会出错,能够正确的完成训练并生成模型。
2.将预处理过后的图片信息经过yolov3darknet-53完成对图像的学习识别,生成可用得到模型,应用于实际环境
3.本文第四章试验结果能够正确的识别苹果,并且可以完整标出苹果的位置和个数。可以为后续开展各种工作打下了基础。
4.由于苹果生长的天气,环境,水分,养分等因素,生长畸形,或者叶子树干遮挡面积过大无法识别属于正常的错误范围内,模型的成功率保持在90%左右。
5.对于此次试验,其中样本图片的数量不是特别充足,生成的数据模型部分可能无法使用(每200轮的训练就会生成一次模型,但是成功率特别低的应当舍弃无法使用)
6.对于深度学习还可以进行其他种类的目标可以进行识别和位置确认,但是都需要大量的实验数据作为基础。如果需要达到100%的正确率可能很难,但是随着实验数据的增加我们一直在向这个目标靠近。
7.考虑到苹果的种类问题例如:苹果包含绿颜色苹果,那我们需要对这些绿颜色苹果单独进行数据集的制作,单独进行训练,不能与红颜色混为一谈,否则产生的模型可能无法识别出苹果,或者与理想的结果差距较大。
六、 目录
基于yolov3的果园苹果识别系统研究与试验1
Research and experiment of orchard apple recognition system based on yolov32
第一章 引言1
1.1 研究的背景和目的1
1.2 图像处理国内外发展现状1
1.2.1 图像处理的国外研究现状2
1.2.2 图像处理的国内研究现状2
1.3 图像处理在识别苹果方面的发展前景2
1.4 论文的主要研究内容和结构3
第二章 图像处理识别苹果的过程4
2.1 图像处理识别苹果4
2.2 苹果识别的总体流程4
2.2.1 苹果图像的采集4
2.2.2 苹果图像的预处理4
2.2.3 苹果图像的数据集的制作5
2.2.4 输入到paddledetection里运用yolov3进行训练5
第三章 苹果识别中图像处理的算法8
3.1 yolov3概述8
3.2损失函数10
3.3预测原理11
3.4目标检测流程12
第四章 图像处理识别苹果的试验验证16
4.1 苹果图像收集的时间地点16
4.2 苹果图像处理的条件16
4.3苹果图像处理的实验方法16
4.4苹果图像处理的实验结果17
结论20
参考文献21
致谢23