孙哥Spring源码第五集
第五集 创建对象和BeanPostProcessor以及GetBean()的开头分析
【视频来源于:B站up主孙帅suns Spring源码视频】【微信号:suns45】
5.1 创建对象的两种方式
作为标签来就讲,不管是默认标签还是自定义标签,最终都会被封装成BeanDefinition,BeanDefinition被我们的bean工厂来存储,
那么存储的目的是什么呢?那么显然的目的就是为了后续的应用,那么作为后续应用来讲,需要大家关注的是什么呢?存储了BeanDefinition之后beanFactory能够帮我们把对象创建出来,创建出来的这个对象
包含那些环节,那些步骤,这是接下来主要给大家讲解的内容,这个是整个spring工厂最为核心
最为复杂的地方。那它里面会涉及到很多东西,所以我们在讲解完解析之后,那么它怎么去创建对象的这个过程,我们先不着急去看spring的源码是怎么做的,我们首先要考虑的是,以我们目前所学的在spring应用层面上来讲spring创建这个对象应该分为哪些环节?或者说是哪些步骤?那么首先作为我们来讲,作为spring来说,它要想创建对象,有几种方式创建对象呢?这是我们要思考的内容,按照前面在基础的spring课程内容来讲,spring帮我们创建一个对象实际上它要分为,
这个对象是简单对象还是我们所说的复杂对象?
5.2 普通对象的创建
简单对象的话,可以new创建对象,这些我们都鉴定为简单对象,虽然我是new创建的,但是作为spring来讲它的底层一定是基于反射来完成创建
5.3 复杂对象的创建
5.3.1、FactoryBean接口的复杂对象
除此简单对象之外 还有一种是复杂对象 不能被直接new创建对象,这些对象
主要集中在一些接口类型的创建上,那我们知道作为接口类型的创建
实际上是不能直接new的,得用一些实现类
来完成接口的创建,而这些实现类在创建的过程中呢,它也一定可以是直接new的,
比如诉后Connection这个接口实现类
那我们要想创建的话,它得分好几步,Class.forName()先获取驱动,进而使用我们所谓的driverManager(),当然这种东西实际上有很多种啊,所以说作为这种对象来讲,它就不能被new,你怎么去new一个Connection
或者是Mybatis里面的 SqlSessionFactory 或者是 SqlSession它们都是
接口类型,是不能直接new的,作为他们来讲都是有一个复杂的创建过程,我们称之为复杂对象,所以作为这些复杂对象来讲,作为spring来说它有一种独特的创建方式叫做FactoryBean的创建方式,它创建起来需要三个方法实现,一个是getObject()一个是getObjectType()还有一个是isSingleton()
通过这样的方式 我们就可以把复杂对象
创建出来。当然我在讲spring基础的课程的时候也说过,除了实现FactoryBean接口的复杂对象实现方式之外,

5.3.2、静态工厂或者是实例工厂
实际上它可以通过静态工厂 或者是
实例工厂,这两种方式可以实现和FactoryBean一样的效果,唯一的区别是什么呢?FactoryBean在应用的过程当中必须实现它的接口,而静态工厂和实例工厂
都不需要实现这个接口。 与之对应的是什么?那在配置的过程当中 静态工厂需要
在bean标签里面 指定一个factory-method,那当然如果是实例工厂的话
bean表情里面除了 指定 factory-method 还要制定
factory,通过这三种方式,我们都是可以完成复杂对象的创建过程,最终就可以把这个对象给创建出来,那么这块在上节课的时候也完整性的画过。


5.4 注入
5.4.1 注入的介绍
通过这其实还远远没有达到使用的需求,如果spring仅仅能帮我们完成对象的创建的话,相对来说spring的容器/工厂相对来说是比较弱智的。如果我们这么写其实已经把代码写的很高级了,实际上如果站在spring的角度来讲,我们认为这就比较单一了,所以上说这两种方式,最终核心解决的都是一个问题,这个问题是什么呢?就是把对象创建出来。比如说我现在有一个User类,甭管你是通过简单对象或者复杂对象的创建,它们都只能获取到对象,那对于简单对象来讲给我们是没有任何意义的,为什么呢?因为我们在使用对象的过程当中,对象它肯定是会存在成员变量的,比如说我的这个User里面存在id和name属性,如果想让我的对象有价值有意义
能够使用的话,我们还要考虑在开发的过程当中
对对象的属性进行赋值,那么这个赋值称之为注入,所以当这个时候
,我们已经有了对象之后,那下面实际上我们就要考虑的是什么呢?考虑的是注入的问题了,那现在我们很自然的要问大家下面的一个问题了,这个问题是
这个注入分为几种方式?
5.4.2 注入的几种方式
其实我们说的注入大概分为3种形式 set注入,构造注入,autowire 自动注入。
set是 property标签 构造是 constructor-arg标签
自动注入是在bean标签 autowire=“” 或者是 beans default-autowire=“”
中所有的bean 都会被管理。
算上注解的话也是自动注入,这么细化下来 应该是3种 注入方式。
5.4.3 为什么要补充autowire注入
这里我为什么要把autowire
补进来呢,因为后续我们在学习源码的过程中,你就会发现有专门处理自动注入的工厂,这个工厂就叫做AutowiredBeanFactory,如果你不了解这些东西,你就看不懂,为什么说源码难以阅读呢,是因为spring给我们提供了100个特性,但是作为开发来讲呢,可能我们只用其中的40%-60%就够了,还有剩下的40%左右在开发当中
很少应用,在应用层面上来说够了,如果要关注源码的话,那这些东西在源码当中都会有体现的,因为它必须都得支持,如果你不懂这些东西,没有基本认知的话,最后再看源码的时候
就会很懵逼,死翘翘。autowire
可以写在bean标签里面代表bean标签会被自动注入,当然也可以写在beans里面代表这个beans里面的所有bean都可以自动注入。后续自动注入大家很少用了,大家就慢慢淡忘了,但是它一定是存在的。
5.4.4 set注入的重要性
那这样我们就知道了,当我们有个对象之后,就开始考虑什么了?考虑对对象的成员变量进行注入进行赋值,那这个赋值其实是分为三类的,一类是set注入,一类是构造注入,一类是autowire自动注入,自动注入在应用层面很少用了,比较常用的是注解
注解也算是autowire的一种变种,这些形式是大家必须掌握的。所以我们在说
在spring工厂里面当我们一旦存储了这些bean的信息之后,就要考虑创建对象了,而创建对象的这个过程当中,至少目前为止通过我们的分析,
了解到它分为首先要创建对象,第二要对对象的成员变量进行注入。那下面的事儿就是什么?在这三种注入当中最常应用的是那种注入的呢?我一直强调的是set注入,也是spring潜意识更加推荐的方式。
5.4.5 set注入的好处
第一个:在基础课程的时候讲为什么要选择set注入呢?因为set注入好,那么好在哪?第一它不会发生重载,构造注入会产生重载,就会把这个简单问题复杂化了。
第二个:spring在内部注入的时候它大量的编码在开发底层代码的时候,产生注入的这个过程使用的都是set。
第三个:set注入可以避免我们循环引用的问题
5.4.6 set注入的两种方式
作为set注入来讲,大家要清晰的是什么呢?
在使用set注入的时候实际上会有两种注入形式。
形式一:一种是程序猿完成的注入,8种基本类型注入【value标签、List标签】和自建类型注入【ref-bean或者简写ref】都是程序猿做的,应用层面就够了。
形式二:另外一种是容器spring自己的注入 Aware。
5.4.7 Aware注入
set注入是实例化后很重要的一个工作,是第二部分工作,整个的注入分为两大类,一类是程序员注入,JDK原生提供,
另外一类是容器级别的注入,主要体现在Aware
是知道的意思,所谓的知道是什么意思呢?我们所能接触到的就是BeanNameAware
当前的对象 获得 他在工厂中的ID(beanName),还有一个是BeanFacotryAware
当前的对象中 获得工厂对象。当对象实现了BeanNameAware 接口之后,就可以
获得 他在工厂中的ID。 当对象实现了BeanFacotryAware 接口之后,就可以 获得
获得工厂对象。实际上这是一种自省,类似于反射,我通过程序能了解程序的基本信息,比如我有多少个构造方法,有多少个类,原来这些东西都写在代码里面是人知道的,程序不知道,通过反射的方式可以让程序知道这件事,同样当我们让spring工厂生产一个对象的时候,这个对象的本事它要获得在工厂的ID和生产的工厂是什么,就可以实现BeanNameAware和BeanFactoryAware。
测试
5.4.7.1 获得ID
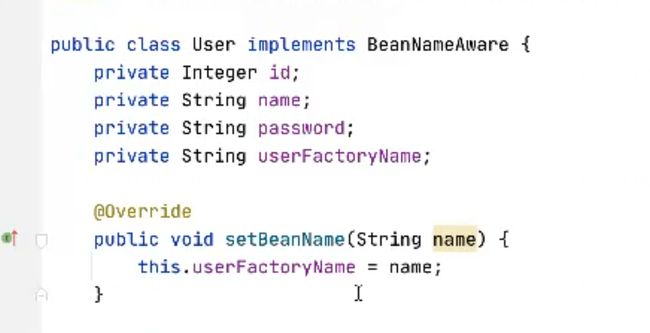
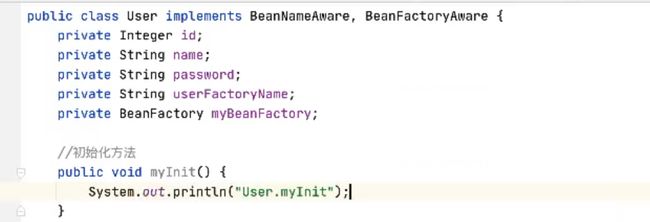
看代码写了一个User类,让我的spring来生产这个对象,在配置文件里面配置bean
id=u,我想让User获得它在工厂中的标签id,传统方式是获取不了的,现在无需解决这个问题,现在只需让这个接口实现BeanNameAware这个接口之后,我们就可以在User内部获取id值
u,实现接口就得实现接口方法setBeanName,我们是实现我们不会调用,是spring容器未来会调用这个方法,我们只需要写这个方法的实现就可以了,谁调用谁负责这个参数传递就可以了,这个name就是User在工厂中的id值,那显然让spring去提供,它最终才能提供,想在user中使用,存起来就行。定义一个变量userFactoryName,通过setBeanName就行赋值,提供一个方法去查看获得的name是否是正确的,这样就完成了接口的实现,我们在测试类里面可以进行相应的测试。

5.4.7.2 获得工厂对象
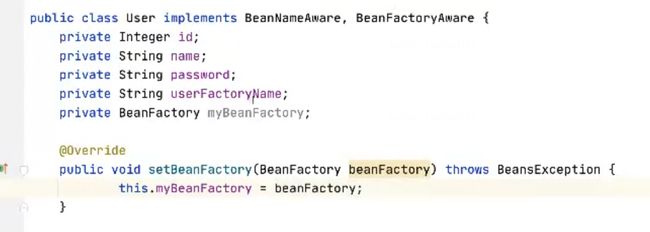
获得工厂对象怎么办?有些同学想的是,我想使用我直接再new一个工厂,但是你要知道我想使用的是当前的工厂,当前的这个概念是非常重要的,当前指的是生产user的工厂,而这个工厂已经卸载了test1中,而你此时在User中再创建一个工厂,存在了两个工厂,我们一直在强调一个概念,spring的工厂是重量级资源,那么一种类型的工厂我们只创建一个实例,那么什么情况下被允许创建多个工厂呢?当出现父子容器父子工厂的情况下,这种场景是被允许父和子两个工厂存在的,但绝不允许有平级的两个工厂,这条路是错误的被堵死了,那么该怎么办呢?这时候的解决方式
只能通过BeanFactoryAware这个接口
获得的这个工厂就是test方法中的工厂,是靠spring传给我们的,获取这个工厂之后,就可以存下来,进行输出打印,当后续有user对象之后,可以进行相应的测试。


5.4.8 普通set注入和容器注入的区别
我们在实现Aware的接口的时候,其实也实现了set方法,我们想要这个aware接口,就要对应的实现set方法,和id,name,password都是一样的,只不过区别在于什么地方呢?
id,name,password这些值是我在spring的配置文件当中来完成对于他们的赋值的,而aware方法中需要的这些东西,我们可办不到给它提供,是spring容器给它提供,所以我把自己写的这些属性叫做程序猿赋值,把实现Aware这些接口的叫做容器注入。现在很自然的有个问题,这个问题就是容器的注入
这些set方法允许在前 还是 自定义属性赋值运行在前呢,这是下面的一个问题。
5.4.9 普通set注入和Aware注入的优先级
是自定义属性赋值在前,需要大家注意的就是
程序猿注入的在前,容器的的注入在后。
配置文件:

User类:

运行
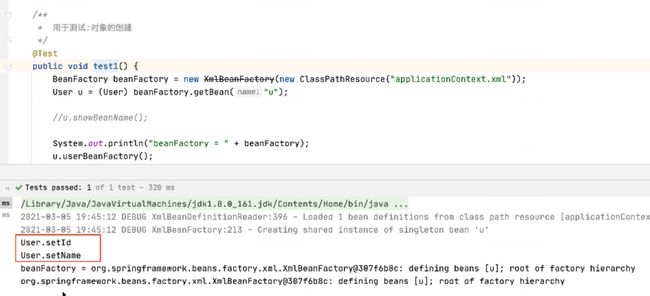
发现用户在前,容器在后。
5.4.10 BeanNameAware实战
这些整个就是我们有了对象之后,第二件事情要做的,程序员注入或者容器进行注入。
当我们了解容器注入的语法之后,其实这个事情是好理解的,我想获取beanName就去实现相应的BeanNameAware接口,想获取bean工厂就去实现相应的BeanFactoryAware的接口,这些后续在实战当中该怎么使用的呢?其实这块是比较复杂的。
比如说我想在User提供的这些方法中打日志,打日志的过程当中我想知道我到底我的这个User类在工厂当中叫什么名字,我把它记录在日志里面,那么很自然的我就想要它的id值了,这个时候就通过BeanNameAware来获取了,我想获得我的ID值去记录日志,其实
这个想法是很牵强的,基本上我在开发当中没怎么用到,但是这个是我们可以说的一个点,所以说BeanNameAware这个点是比较好理解的。
5.4.11 BeanFacotryAware实战解决scope=prototype失效的问题
不好理解的是BeanFacotryAware它的这个用法是特别有意思的,解决scope=prototype在注入过程中会失效的问题
场景:


基于场景进行讨论

把UserDao做成了UserService的成员变量,作为现在的整个代码的开发来讲,如果我们想要userDao做为service的成员变量且保证它运行安全,那么必须得有一个前提,userDao必须是线程安全的情况下,我们才可以service的成员变量,那假定我的这个userDao是线程不安全的,这是一种假设,假设userDao是线程不安全的,如果我要想保证程序访问的可靠性的话,那我该怎么办呢?有几种解决办法呢?
有两种手段,
一种手段是上锁,程序的吞吐会有问题。
另外一种是人手一份,userDao不止创建一个,一个用户一个UserDao,在有来新的用户的话,我在给它提供另外一个UserDao对象,这样就解决了安全问题,每个人一份是我们更加推荐的。
此时有一个问题是在工厂中UserDao是否帮我们生成了多个呢?需要修改成scope为Prototype,才能每一次都创建新的。

假定有两个用户访问
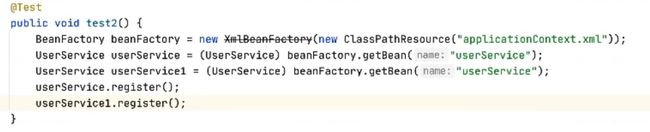
发现userDao没有变化,还是同一个对象
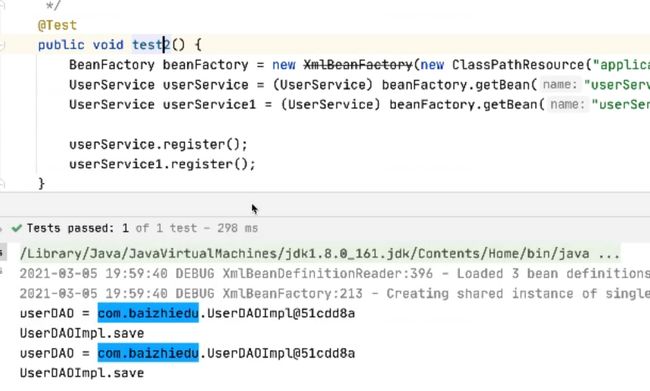
通过注入获取UserDao发现scope=prototype会失效,怎么解决呢?使用
BeanFactoryAware来解决直接获取UserDao发现确实是人手一份,通过注入的方式发现UserDao的scope=prototype会失效
解决:不使用注入的方式

取而代之的是此时的Dao应该是beanFactory来获取,这个时候就可以享受到scope=prototype。这时候会有一个问题如何从UserService中获取工厂,进而getBean获取UserDao,这时候只需要实现BeanFactoryAware,实现它之后通过setBeanFactory方法把BeanFactory存储在UserService内部。

然后通过BeanFactory获取userDao实现方法

找到测试类,进行测试,通过BeanFactoryAware接口解决了userDao的scope=Prototype问题。当然解决这个问题可以通过Lookup-Method=xxx来解决这种情况就很少见了,很少有人使用。后续等我们使用了更高级的工厂,通过实现ApplicationContextAware接口可以获取applicationContext,在当时讲解spring基础
事务嵌套不起作用的时候
AOP的坑,就是通过ApplicationContextAware来解决的,忘记了可以回头看一下,也是通过Aware来解决的,那么就把set注入给大家讲完了,在讲解创建对象的时候,除了对象创建本身,以及set注入之外,那大家一定要注意的是,set注入它一定是分为两种情况的,一种是我们自己完成的,一种是容器完成的,容器是通过各种aware方式回调的方式注入进去的,这就是set注入,对象创建完成之后马上就要进行set注入。
构造注入的话,很显然会提前一点,它是在完成实例化对象时同时完成我们所说的构造注入,当然我们说了它很少用,可以忽略它,但它的时机一定是伴随着对象创建。
5.5 初始化
注入完成之后,我们现在已经讲了,创建对象本身 下面就是set注入 一种是
容器注入
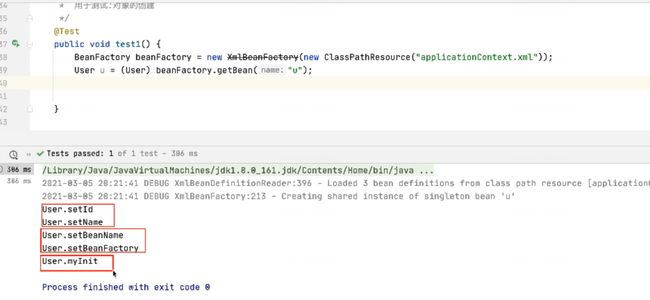
一种是用户注入,这个事儿完事之后,spring会把对象交给我们吗?不是这样,spring下面会干什么?按照spring的流程来讲,需要大家注意的是它注入完成之后貌似给我们的感觉好像是这个对象已经有了,实际上在spring的内部逻辑里面还远远没有完事儿,下面很重要的工作是什么?是初始化,初始化spring可以采用两种方式来完成,一个是使用init-method的方式来完成,另外一种是通过实现接口InitializingBean的方式来完成,这两种方式都可以对注入好的对象来进行初始化,那我们来看它的运行效果
5.5.1 init-method第一种初始化的方式
还是以user为例,随便写一个方法作为初始化方法myInit(),作为这个初始化方法的作用,就是spring允许我们准备好一个对象完成注入之后,再来处理初始化方法为这个对象做一些初始化的功能,那最终这个方法会被谁来调用呢?spring的容器【工厂】,我们写完这个方法之后,最终spring在创建完对象注入完成之后,会帮我们调这个方法,完成一些初始化工作,什么是初始化工作?就是编程性的一些准备工作
,比如我这个类需要IO的话,在这个初始化方法中就要创建InputStream,为后续的IO读取做一些准备性工作。那当讲完这儿之后,这个功能理解了,也知道spring最后会帮我们调用了,那下面会有一个很重要的问题是,这个方法谁会调用?spring,但是这个方法的名字是谁写的?是程序员写的是随意的,那么spring怎么知道调用这个方法呢?
很自然的是我们要告诉spring,怎么告诉它 在配置文件中告诉它。
这样spring才会认可myInit方法

测试
5.5.2 InitializingBean第二种初始化方式
实现spring规定的InitialzingBean接口,这里需要对接口进行实现,这个方法同样也是初始化方法。
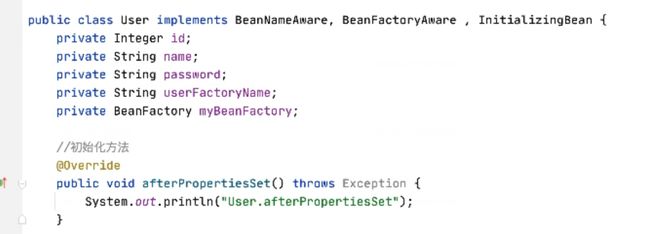
5.5.3 第一种和第二种初始化方式的区别是什么
myInit是需要告诉spring,InitialzingBean不需要告诉spring,是spring提供的接口,是set注入完成之后处理的。
所以在我们实际的开发当中这两种方式二选其一,正常是不会同时出现这两个初始化方法的。
5.5.4 init-method InitializingBean优先级
InitialzingBean和自定义初始化方法那个调用更快呢?spring会先调用谁呢?
InitialzingBean更快被调用


不保准吗?调整顺序,发现结果还是一样的。


如果两者都存在的话,先调用InitialzingBean再调用自定义方法,spring的东西优先级是最高的,因为接口是spring自己定的。
这样就完成了初始化,这个对象或者说是这个实例就可以正常运行了,我们所创建的这个对象是圆满的就可以交给客户了。
5.6 销毁
客户可以进行编码操作了。应该掌握的对象过程就是 创建对象 set注入 容器注入
用户注入 初始化 InitialzingBean初始化
init-method,最后对象就可以有了,这就是一个完整的对象了。对象用完了容器会对它进行销毁,为什么?因为我们不可能一直让它占着我们的内存空间,它一定会销毁,销毁它一定会有销毁的方法,销毁的方法类比初始化方法也有两种方式来完成的,这两种方式分别是
定义一个销毁方法,随便定义随便命名,这个方法是在对象真正被销毁之前,来做一些释放资源的工作,类似于IO操作的话,IO的关闭这就是释放资源,再比如说我们不需要的一些对象
把它置为null,这都是释放的工作
5.6.1 自定义销毁方法
最终myDestory谁来调用呢,肯定交给spring

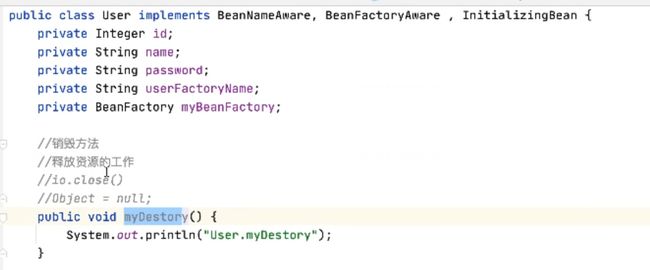
5.6.2 接口定义销毁方法
实现DisposableBean接口

5.6.3 自定义销毁方法和接口定义销毁方法的优先级
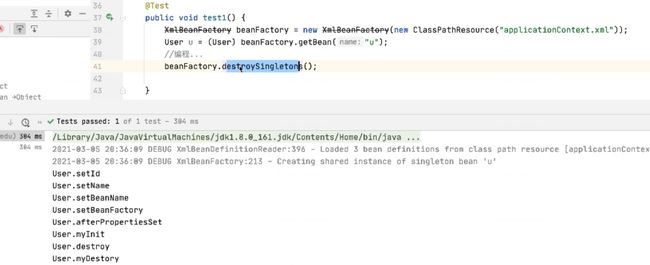
先调接口再调自定义销毁方法。
5.7 流程总结
第一块儿对象的创建 -》第二块儿注入-》第三块儿初始化工作-》第四块儿
可以应用的对象交给用户来使用 -》第五块儿就是销毁
一种是destory-method 另外一种就是DisposableBean的方式。

5.8 BeanPostProcessor
按道理来说
对象完成创建之后就交给调用者来使用了,但是这里需要大家注意的是什么呢?实际上在这个过程当中啊,它还有一个地方是会引入生命周期相关内容的,这个就是我们所说的
非常复杂的问题了
叫BeanPostProcessor,BeanPostProcessor是来干嘛的呢?它是来完成对象加工的,按道理来说
对象完成了注入 就已经有了,
按道理不初始化就可以直接用了,我们这个对象进而可以交给BeanPostProcessor进行整体的加工,之后BeanPostProcessor加工完成之后,交给初始化,来做初始化操作,初始化操作完成之后的对象
再一次交给BeanPostProcessor再做处理,把最终加工对象把交给客户。
5.8.1 加工是什么意思?为什么不在原始对象上进行加工呢?
你不是要加功能吗,我直接在对象上加不就完了吗,在对象创建的时候就把对象写好,把功能写好加到这儿不就完了吗,为什么还要通过BeanPostProcessor来进行加工呢?能听的明白吗?
BeanPostProcessor是一个可选的机制,注入完成后完成加工,初始化完成之后再进行加工,你会发现这个过程太过复杂了,那加工不就是增加功能吗,增加功能完全可以,直接改对象的代码就可以了,就加工完了不就行了,为什么要通过BeanPostProcessor进行加工呢?
这是为什么呢?
加工可没说只加工一个对象,bean工厂日后会创建很多的对象,我是不是可以通过加工的方式为需要加工的对象进行统一来进行处理,这是一个代码复用的问题,如果我要把单个的对象一个一个改代码增加功能,那这个代码就冗余了,现在统一把代码写到BeanPostProcessor里面
可以对工厂创建的所有对象进行加工,这样我的代码冗余就少了,能听的明白吗。加工统一处理,减少冗余代码,第二点
作为我加工来讲
加工的功能一定不是主要的功能,一定是一些次要的功能,而次要的功能是可有可无的,如果我要是直接把它写在创建对象的代码里面
改起来麻烦,而加工的话 我想加就加 不想加 我就抽出来,达到解耦的状态。
5.8.2 BeanPostProcessor的好处
像生产午餐肉这种东西,我们以前是加防腐剂,我们就对它加防腐剂,但事实证明防腐剂对人身体不好,我就不需要加防腐剂,我就把防腐剂的代码干掉,
只有BeanPostProcessor在对于加工或者不加工进行切换的过程当中对现有的代码是没有任何影响的。
所以spring才采用了这种方式 对对象完成了加工,
它的好处第一点 减少加工代码的冗余
第二点是什么 解掉 加工代码的耦合,
只要把这个类干掉就不会影响创建对象的过程。
如果这块儿有问题的话,我强烈建议你会听Spring基础课程。
这就是BeanPostProcessor需要大家注意的一个地方。
5.8.3 BeanPostProcessor加工时机
第一次加工是 set注入完成之后 做的加工BeanPostProcessorBefore
第二次加工是 初始化调用完成之后再做的加工 BeanPostProcessorAfter
5.8.4 参数以及返回值的含义
这两个方法对应的就是BeanPsotProcessor的加工时期,注入完了对象交给
BeanPostProcessorBefore,对象怎么交给这个方法?这个需要大家关注,Spring工厂创建的对象怎么交给你这个让你加工呢?
就是通过bean的参数,bean就是已经被容器创建好并注入完成的,我把这个对象作为方法参数传给你,你在这个方法里面对它做加工,
那么你最终怎么再把这个加工对象返回给容器继续初始化呢?
通过postProcessorBeforeInitialization方法的返回值,返回类型是Object,
那么这个返回值它的作用是什么呢?
我把这个对象再返回给你初始化方法,它对应的其实是加工对象。换句话来说通过这个方法的回调,二者就达到了一个对应关系,我创建好的对象交给你这个方法的参数,你帮我去加工,加工完成之后,你把加工对象作为返回值给我工厂,工厂就直接初始化了,做完初始化之后对象再通过postProcessorAfterInitialization方法的参数bean去再一次做加工,最终postProcessorAfterInitialization方法的返回值Object
它对应的就是最终要返回给客户的最终对象。
通过这么一个回调的往复,达成了一个互动,容器创建好了对象
怎么交给BeanPostProcessor加工,通过参数传过去,在你的方法体内对它做加工,之后你把它的返回值
返回给Spring,Spring就直接让它初始化了,初始化完成之后可能又新增了一些功能,再交给BeanPostProcessor
还是通过参数交给它 再对其 进行加工,把这个返回值最终返回给调用者
,这是一个完整性的过程,当然你具体加工的是什么,我并不关心也不关注,这就是它们的一个往复过程。
5.8.5 代码演示
创建BeanPostProcessor
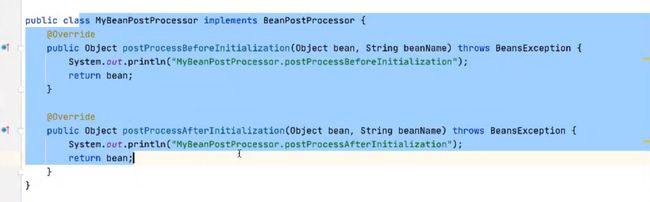
工厂创建的所有bean都会经过BeanPostProcessor来加工。

测试,在低级工厂体现不出来,把xmlBeanFactory给注释了,使用
ClassPathXmlApplicationContext

5.8.6 BeanPostProcessor实战总结
一般在实战过程中很少做两次加工,一般都是在After中进行加工。

对id进行加工处理

加工完成之后直接交给了用户,id值从10->100,这就是加工的效果,这个加工其实没有什么实战价值。
5.9 doGetBean()分析
到现在为止,一个Spring对象被工厂创建的完整环节基本都掌握了,Spring
BeanFactory源码中是如何创建对象?首先第一个问题是 Spring Bean
Factory在什么位置创建对象的呢?
5.9.1 new XmlBeanFactory()作用
1、BeanFactory beanFactory = new XmlBeanFactory(new
ClassPathResource(“”));做了哪些事儿呢?
2、、从xml中读取标签->封装成BF->最后进行注册 到一个Map里面
key是beanName,Value是BF。
5.9.2 beanFactory.getBean()作用
1、帮我们创建对象,基于BeanDefinition来完成的。
2、整个创建对象的过程 创建对象 属性填充 初始化 这些步骤。
3、经过这个流程把对象创建了交给用户了,在创建对象的时候需要分scope
是singleton
还是prototype,prototype你要我就给你一个新的,实际上spring引入了singleton就是有些对象只需要经历一次这样的过程就够了,后续再有别的客户用,实际上使用还是同一个对象,再有客户使也是这一个对象。所以这时候就会分,对象每一次都会创建新的还是只创建一个?而每次都创建新的这个事儿
是简单的,每次只创建一个的这件事反而是复杂的,我们怎么让一个对象不管用户几个人几次调用永远只创建一个呢?或者说永远只创建一呢?这个问题怎么解决?如何保证某一个对象只创建一次,但是可以被多个用户调用呢?如何保证这件事儿呢?
2.3.1、把单例对象进行缓存-> singletoonsMap key是id 或者是beanName
value是
对象,除第一次外,后续使用从Map里面拿就行了,这个就是我们说的对单例对象的缓存,有些人称之为
一级缓存,还有二级缓存以及三级缓存,所谓的一二三级缓存,spring内部没有这种叫法
spring会有不同的Map
这些Map要配合使用,后面我们会一点一点把它打开,所以我们说创建对象它一定是要基于BeanDefinition,一定是要包括这若干个环节的,一定是要解决单例对象的缓存问题的,这三个问题是整个创建对象的宏观上的思考,存在于哪?存在于beanFactory.getBean()方法,那当然这里面还会涉及到各种复杂的注入,以及我们所说的循环引用的问题,那这个基本思路能听明白吗?
接下来我们要刨根问底儿去研究beanFactory.getBean()这个方法,在整个工厂的创建中因为有很多特性我们在编程当中是用不到的,但是为了让工厂有这个能力
代码实现过程当中 它是一定要写的。看代码
5.9.3 transfomedBeanName(name)
String beanName = transfomedBeanName(name)现在的这个name就是等于beanName

下面的一个问题是,什么情况下beanName和name有可能不一样呢?
(1)、别名的情况下,正常情况下id和别名都可以获取到bean。所以你可以认为name不一定非得是id,可能是别名,但是beanName它一定是id,这就是转化的原因。

(2)、在id前面加一个&号,按道理FactoryBean获取的是它所创建的复杂对象,如果想要获取FactroyBean实例的话,必须在FactoryBean前面加一个&号。现在的话,这个程序肯定是会报错的,因为我的User不是FactoryBean的实现类,但是我想演示的是,transfomedBeanName的变化,此时我的name叫做&u我的beanName叫u。

- 、总结transfomedBeanName方法就是获取这个bean的id值,
如果getBean(name)----------id,
如果getBean(&id)-------------id name值等于
getBean(name),beanName必须等于id值。