PYTHON中的字符编码
一.储备知识
字符串的类型,文本文件的内容都是由字符组成的,但凡涉及到字符的存取,都需要考虑字符编码的问题。
1.软件运行前,软件的代码及相关数据都储存在硬盘中
2.任何软件启动,都是在硬盘中读取数据,传输到内存中,然后CPU从内存中取出指令并执行
3.软件运行的过程中,产生的数据最先存放在内存中,想要永久保存的话,则需要将数据存入硬盘中。
文件编辑器的文件读取过程
阶段一:启动文本编辑器
阶段二:文本编辑器会将写入的数据从硬盘读入到内存
阶段三:文本编辑器会将刚刚读到的数据的内容,返回到显示屏中。
二. 字符编码的介绍
字符编码前提:它只跟文本数据类型和字符类型有关,跟视频文件,音频文件这种数据类型无关。
计算机只认识二进制(01),计算机之所以能够识别各种语言文字,是因为计算机自己内部有一张字符编码表
字符编码表:一些字符与数字之间的关系。
三.字符编码的发展史
1.一家独大
计算机开始是由美国人发明的,他们想让计算机识别英文字符, 内部维护的是ASCII码表:
它的内部维护的是英文字符语数字的对应关系,他统一使用的是一个字节等于一个字符,一个字节有八位,我们要记忆的是A---Z的字母代表的字符,a---z做代表的字符,0-9所代表的字符
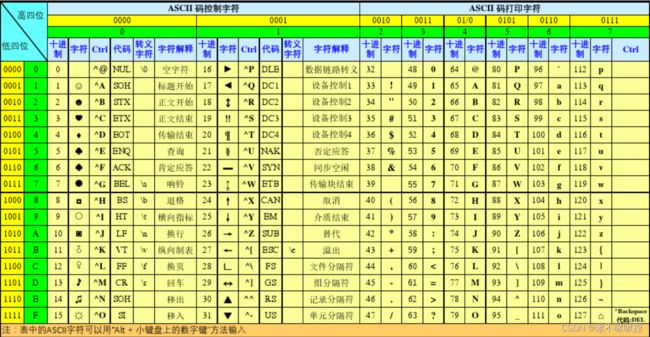
A--Z :65--90
a--z : 97--122
0--9 : 48--57
2. 群雄分割
1.中国人也想使用计算机,但是ASCII码表内并没有中文字符,所以中国自己使用的另一个GBK码表。
GBK码表:它的内部记录有英文与中文和数字的对应关系
它使用两个字节及以上来保存中文字符。
2.日本人也想使用计算机,但是ASCII码表内并没有日文字符,所以日本使用的码表,叫另
Shift+JIS 表,它的内部记录了日文字符,英文字符与数字的对应关系。
3. 韩国人也想使用计算机,但是ASCII码表内并没有韩文字符,所以韩国使用的码表,叫另
Euc-kr 表,它的内部记录了韩文字符,英文字符与数字的对应关系。
3. 天下一统
为了让全世界的人类都能够统一的使用计算机,让计算机势识别全世界的语言,把字符编码表进行了统一。
Unicode(万国码)
统一使用2个字节保存字符。
优化:从内存中得到的万国码到硬盘中得到的utf-8字符
utf-8:大家统一使用的一种编码:
1.统一使用一个字节来保存一个英文。
2.统一使用三个字节保存一个中文。
在utf-8中使用三个字节保存中问。
utf系列:utf-8,utf-16 utf-32.......
utf-8mb4:utf-8(o´ω`o)ノ储存表情
四。字符编码实战
1.如何解决乱码
1.在书写文件时,用的什么编码,那么打开时就要用什么编码就可以了
2.python解释器中不同版本代表着编码的不同:
在python2.x 中使用的是ASCII码表,并不是utf-8
而在python3.x版本中使用的是utf-8
3.如何编码和解码
编码:把人类能够读懂的字符转化为计算机能够识别的数字(二进制01)
# 编码
res ='今天程吃啥好呢'
print(res.encode())#b'\xe4\xbb\x8a\xe5\xa4\xa9\xe7\xa8\x8b\xe5\x90\x83\xe5\x95\xa5\xe5\xa5\xbd\xe5\x91\xa2' #utf-8在计算机里的字符这就是二进制输出的结果:b'\xe4\xbb\x8a\xe5\xa4\xa9\xe7\xa8\x8b\xe5\x90\x83\xe5\x95\xa5\xe5\xa5\xbd\xe5\x91\xa2'
解码:把计算机能够读懂的字符转化为人类能够识别的字符
# 编码
res = '今天吃啥好呢'
# print(res.encode())
res1 = res.encode('utf-8')
print(res1.decode('utf-8'))# 今天吃啥好呢# 编码
res = '今天吃啥好呢'
# print(res.encode())
#解码
res1 = res.encode('utf-8')
print(res1.decode('utf-8'))j
结果:今天吃啥好呢
如果遇到解码的时候,不知道对方使用什么编码时,你就试试 utf-8,或者GBK,亲测好用(o´ω`o)ノ