学习python 模块内置方法汇总_python基础知识8——常见内置模块
模块介绍
time &datetime模块
random
os
sys
shutil
shelve
xml处理
yaml处理
configparser
hashlib
re正则表达式
logging模块
1、模块:
定义:其实模块简单说就是一堆代码实现某个功能,它们是已经写好的.py文件。只需要用import应用即可。
分类:
1、自定义模块
2、内置标准模块(又称标准库)
3、开源模块
1、自定义模块,就是自己写的.py文件为了实现某个功能。
2、内置模块,就是python自身已经写好的某个功能,例如经常用的sys、os等模块都是内置模块。
3、开源模块,开源大家都明白吧,就是不收费的别人写好的模块,一般也称第三方模块。
模块的引用:
1、import modules
2、from modules import 函数
3、如果有多个模块,可以用逗号隔开,如果想把某个模块里面的所有功能都导入,可以用*,这样的话功能都加载道内存里面,占用内存资源,不建议用。
2、time &datetime模块
1 #!/usr/bin/env python
2 #—*—coding:utf-8—*—
3
4 #time和datetime
5
6 importtime,datetime7
8
9 ###time
10 #print(time.process_time())#返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
11 #>>>0.09375
12
13 #print(time.altzone)#返回与utc时间的时间差,以秒计算\
14 #>>>-32400
15
16 #print(time.asctime()) #返回时间格式"Mon Aug 22 09:31:43 2016",
17 #>>>Mon Aug 22 09:31:43 2016
18
19
20 #print(time.localtime())
21 #>>>time.struct_time(tm_year=2016, tm_mon=8, tm_mday=22, tm_hour=9, tm_min=32, tm_sec=28, tm_wday=0, tm_yday=235, tm_isdst=0)
22 #tm_year(年),tm_mon(月),tm_mday(日),tm_hour(时),tm_min(分),tm_sec(秒),tm_wday(星期,从0到6,0代表周一,一次类推),tm_yday(这一年中的地几天),tm_isdst(夏令时间标志)
23
24
25 #print(time.time())#(获取时间戳)
26 #a = time.time()
27 #b = a/3600/24/365
28 #print(b)
29 #>>>46.67149458666888
30 #2016-1970
31 #>>>46
32 #时间是村1970年开始算,为什么时间要从1970年开始算呢
33 #1970年1月1日 算 UNIX 和 C语言 生日. 由于主流计算机和操作系统都用它,其他仪器,手机等也就用它了.
34
35
36
37 #print(time.gmtime(time.time()-800000))#返回utc时间的struc时间对象格式
38 #>>>time.struct_time(tm_year=2016, tm_mon=8, tm_mday=12, tm_hour=20, tm_min=9, tm_sec=14, tm_wday=4, tm_yday=225, tm_isdst=0)
39
40
41 #print(time.asctime(time.localtime()))
42 #>>>Mon Aug 22 10:23:52 2016
43 #print(time.ctime())
44 #>>>Mon Aug 22 10:24:25 2016
45
46
47 #string_2_struct = time.strptime("2016/05/22","%Y/%m/%d")#将时间字符串转换成struct时间对象格式
48 #print(string_2_struct)
49 #>>>time.struct_time(tm_year=2016, tm_mon=5, tm_mday=22, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=143, tm_isdst=-1)
50
51
52 #string_3_struct = time.strptime("2016/05/22","%Y/%m/%d")
53 #struct_2_stamp = time.mktime(string_3_struct) #将struct时间对象转成时间戳
54 #print(struct_2_stamp)
55 #>>>1463846400.0
56
57
58 #print(time.gmtime(time.time()-86640))##将utc时间戳转换成struct_time格式
59 #>>>time.struct_time(tm_year=2016, tm_mon=8, tm_mday=21, tm_hour=2, tm_min=25, tm_sec=14, tm_wday=6, tm_yday=234, tm_isdst=0)
60
61 #a = time.timezone
62 #print(a/3600)
63 #>>>-8.0东八区
64
65 #time.sleep()#睡几秒
66
67 #time.localtime()#当前本地时间
68
69
70 #strftime()#重要!
71 #a = time.localtime()#将本地时间格式化
72 #time = time.strftime("%Y/%m/%d %H:%M:%S",a)
73 #print(time)
74 #>>>2016/08/22 10:31:07
75 #前
76 #前后刚好相反
77 #后
78 ## time.strptime()#前后一定要位置一一对应(注意符号空格)
79 #time1 = time.strptime("2016-08:20 14:31:52","%Y-%m:%d %H:%M:%S")
80 #print(time1)
81
82
83 #####datetime(时间的加减)
84
85 #print(datetime.datetime.now()) #返回 2016-08-22 10:33:53.290793
86
87 #print(datetime.date.fromtimestamp(time.time()) ) #2016-08-22
88
89 #print(datetime.datetime.now() )#2016-08-22 10:34:37.885578当前时间一般使用这个
90
91 #print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天#2016-08-25 10:35:38.554216
92
93 #print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天#2016-08-19 10:35:58.064103
94
95 #print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时#2016-08-22 13:36:16.540940
96
97 #print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分#2016-08-22 11:06:34.837476
98
99 #c_time = datetime.datetime.now()
100 #print(c_time.replace(minute=3,hour=2)) #时间替换

3、random
1 #!/usr/bin/env python
2 #—*—coding:utf-8—*—
3
4 importrandom5
6 #随机数
7 #print(random.random())#0到的随机数,是一个float浮点数
8 #print(random.randint(1,2))#一和二随机
9 #print(random.randrange(1,10))#一到十随机(记得range只有头没有尾巴)
10 #11 #生成随机验证码
12 #13 #checkcode=''
14 #for i in range(5):
15 #current = random.randrange(0,5)
16 #if current == i:
17 #tmp = chr(random.randint(65,90))#chr是ascii码表,65,90是(A-Z)
18 #else:
19 #tmp = random.randint(0,9)
20 #checkcode +=str(tmp)
21 #print(checkcode)
22
23
24 #二般
25 importstring26 #print(''.join(random.sample(string.ascii_lowercase+string.digits,5)))#随机验证码可用(5位含数字和密码)
27 #28 #print(''.join(random.sample(string.ascii_lowercase+string.digits,5)))#随机验证码可用(5位含数字和密码)
29 #
30 ##打印a-z
31 #print(string.ascii_lowercase)#一
32 ##打印A-Z
33 #print(string.ascii_letters)#二
4、os
1 #!/usr/bin/env python
2 #import os
3 ## print(os.getcwd())#打印当前目录
4 #os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
5 #os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
6 #os.curdir 返回当前目录: ('.')
7 #os.pardir 获取当前目录的父目录字符串名:('..')
8 #os.makedirs('dirname1/dirname2') 可生成多层递归目录
9 #os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
10 #os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
11 #os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
12 #os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
13 #os.remove() 删除一个文件
14 #os.rename("oldname","newname") 重命名文件/目录
15 #os.stat('path/filename') 获取文件/目录信息
16 #os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
17 #os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
18 #os.pathsep 输出用于分割文件路径的字符串
19 #os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
20 #os.system("bash command") 运行shell命令,直接显示
21 #os.environ 获取系统环境变量
22 #os.path.abspath(path) 返回path规范化的绝对路径
23 #os.path.split(path) 将path分割成目录和文件名二元组返回
24 #os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
25 #os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
26 #os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
27 #os.path.isabs(path) 如果path是绝对路径,返回True
28 #os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
29 #os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
30 #os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
31 #os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
32 #os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
33
34 #更多
35 #https://docs.python.org/2/library/os.html?highlight=os#module-os
5、sys
1 #!/usr/bin/env python
2 #—*—coding:utf-8—*—
3 importsys4 #print(sys.argv ) #命令行参数List,第一个元素是程序本身路径
5 #>>>['E:/python/day5/sys(1).py']
6
7 #sys.exit(n) #退出程序,正常退出时exit(0)
8
9 #print(sys.version ) #获取Python解释程序的版本信息
10 #>>>3.5.1 (v3.5.1:37a07cee5969, Dec 6 2015, 01:38:48) [MSC v.1900 32 bit (Intel)]
11
12 #print(sys.maxint) #最大的Int值
13 #sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
14 #print(sys.platform) #返回操作系统平台名称
15 #>>>win32
16
17 #print(sys.stdout.write('please:'))
18 #>>>please:7
19
20 #val = sys.stdin.readline()[:-1]
6、shutil
1 #!/usr/bin/env python
2 importshutil3
4
5 #shutil.copyfileobj(fsrc, fdst[, length])
6 #将文件内容拷贝到另一个文件中,可以部分内容
7
8 #shutil.copyfile(src, dst)
9 #拷贝文件
10
11 #shutil.copymode(src, dst)
12 #仅拷贝权限。内容、组、用户均不变
13
14 #shutil.copystat(src, dst)
15 #拷贝状态的信息,包括:mode bits, atime, mtime, flags
16
17 #shutil.copy(src, dst)
18 #拷贝文件和权限
19
20
21 #shutil.copy2(src, dst)
22 #拷贝文件和状态信息
23
24
25 #shutil.rmtree(path[, ignore_errors[, onerror]])
26 #递归的去删除文件
27
28 #shutil.move(src, dst)
29 #递归的去移动文件(删除文件)
30
31
32 shutil.make_archive(base_name, format,...)33
34 创建压缩包并返回文件路径,例如:zip、tar35
36 base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,37 如:www =>保存至当前路径38 如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
39 format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”40 root_dir: 要压缩的文件夹路径(默认当前目录)41 owner: 用户,默认当前用户42 group: 组,默认当前组43 logger: 用于记录日志,通常是logging.Logger对象44
45 #将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录
46
47 importshutil48 ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')49
50
51 #将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
52 importshutil53 ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
7、shelve
1 importshelve2 d = shelve.open('shelve_test')3
4 #写
5 #name = {"zhangsan","lisi","wanger"}
6 #info = {"age":25,"job":"IT"}
7 #d["name"] = name
8 #d["info"] = info
9 #d.close()
10 #写完以后,它会自动生成三个文件,.dat和.dir和.bak
11
12 #读
13 #print(d.get("name"))
14 #print(d.get("info"))
8、xml处理
1
2
3
4 2
5 2008
6 141100
7
8
9
10
11 5
12 2011
13 59900
14
15
16
17 69
18 2011
19 13600
20
21
22
23
1 #!/usr/bin/env python
2 #—*—coding:utf-8—*—
3
4 importxml.etree.ElementTree as ET5
6 tree = ET.parse("xml.xml")7 root =tree.getroot()8 print(root.tag)9
10 #遍历xml文档
11 #for child in root:
12 #print(child.tag, child.attrib)
13 #for i in child:
14 #print(i.tag,i.text)
15 #>>>结果
16 #data
17 #country {'name': 'Liechtenstein'}
18 #rank 2
19 #year 2008
20 #gdppc 141100
21 #neighbor None
22 #neighbor None
23 #country {'name': 'Singapore'}
24 #rank 5
25 #year 2011
26 #gdppc 59900
27 #neighbor None
28 #country {'name': 'Panama'}
29 #rank 69
30 #year 2011
31 #gdppc 13600
32 #neighbor None
33 #neighbor None
34
35
36
37 #只遍历year 节点
38 #for node in root.iter('year'):
39 #print(node.tag,node.text)
40 #>>>data
41 #>>>year2008
42 #>>>year 2011
43 #>>>year 2011
9、yaml处理
yaml和xml差不多,只是需要自己安装一个模块,参考链接:参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
10、configparser
这个比较好玩一点,大家多知道mysql配置文件my.cnf文件的格式吧
1 #类似这样的配置文件,一块一块的分类
2 [DEFAULT]3 ServerAliveInterval = 45
4 Compression =yes5 CompressionLevel = 9
6 ForwardX11 =yes7
8 [bitbucket.org]9 User =hg10
11 [topsecret.server.com]12 Port = 50022
13 ForwardX11 = no
1 #生成类似格式的文件
2 importconfigparser3
4 config =configparser.ConfigParser()5 config["DEFAULT"] = {'ServerAliveInterval': '45',6 'Compression': 'yes',7 'CompressionLevel': '9'}8
9 config['bitbucket.org'] ={}10 config['bitbucket.org']['User'] = 'hg'
11 config['topsecret.server.com'] ={}12 topsecret = config['topsecret.server.com']13 topsecret['Host Port'] = '50022' #mutates the parser
14 topsecret['ForwardX11'] = 'no' #same here
15 config['DEFAULT']['ForwardX11'] = 'yes'
16 with open('example.ini', 'w') as configfile:17 config.write(configfile)
1 #读
2 #import configparser
3 #config = configparser.ConfigParser()
4 #config.sections()
5 #
6 #config.read('example.ini')
7 #
8 #print(config.defaults())
9 #>>>OrderedDict([('compressionlevel', '9'), ('compression', 'yes'), ('serveraliveinterval', '45'), ('forwardx11', 'yes')])
10 #print(config['bitbucket.org']["User"])
11 #>>>hg
12 #print(config["topsecret.server.com"]["host port"])
13 #50022
1 #删除(创建一个新文件,并删除bitbucket.org)
2 importconfigparser3 config =configparser.ConfigParser()4 config.sections()5
6 config.read('example.ini')7 rec = config.remove_section("bitbucket.org")#删除该项
8 config.write(open("example.cfg","w"))9 [DEFAULT]10 compressionlevel = 9
11 compression =yes12 serveraliveinterval = 45
13 forwardx11 =yes14
15 [topsecret.server.com]16 host port = 50022
17 forwardx11 = no
11、hashlib
1 #!/usr/bin/env python
2
3 importhashlib4
5 #m = hashlib.md5()
6 #m.update(b"hello")
7 #print(m.digest())#进行二进制加密
8 #print(len(m.hexdigest())) #16进制长度
9 #print(m.hexdigest())#16进制格式hash
10 #>>>b']A@*\xbcK*v\xb9q\x9d\x91\x10\x17\xc5\x92'
11 #>>>32
12 #>>>5d41402abc4b2a76b9719d911017c592
13
14
15 #md5
16 #hash = hashlib.md5()
17 #hash.update(('admin').encode())
18 #print(hash.hexdigest())
19 #>>>21232f297a57a5a743894a0e4a801fc3
20
21
22 #sha1
23 #hash = hashlib.sha1()
24 #hash.update(('admin').encode())
25 #print(hash.hexdigest())
26 #>>>d033e22ae348aeb5660fc2140aec35850c4da997
27
28 #sha256
29 #hash = hashlib.sha256()
30 #hash.update(('admin').encode())
31 #print(hash.hexdigest())
32 #>>>8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
33
34
35
36 #sha384
37 #hash = hashlib.sha384()
38 #hash.update(('admin').encode())
39 #print(hash.hexdigest())
40 #>>>9ca694a90285c034432c9550421b7b9dbd5c0f4b6673f05f6dbce58052ba20e4248041956ee8c9a2ec9f10290cdc0782
41
42
43 #sha512
44 #hash = hashlib.sha512()
45 #hash.update(('admin').encode())
46 #print(hash.hexdigest())
47 #>>>c7ad44cbad762a5da0a452f9e854fdc1e0e7a52a38015f23f3eab1d80b931dd472634dfac71cd34ebc35d16ab7fb8a90c81f975113d6c7538dc69dd8de9077ec
48
49
50 #更吊的
51 importhmac52 h = hmac.new(('wueiqi').encode())53 h.update(('hellowo').encode())54 print(h.hexdigest())55 #更多关于md5,sha1,sha256等介绍的文章看这里https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
12、re正则表达式
1 ##!/usr/bin/env python
2 #3 #'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
4 #'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
5 #'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
6 #'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
7 #'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
8 #'?' 匹配前一个字符1次或0次
9 #'{m}' 匹配前一个字符m次
10 #'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
11 #'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
12 #'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
13 #14 #15 #'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
16 #'\Z' 匹配字符结尾,同$
17 #'\d' 匹配数字0-9
18 #'\D' 匹配非数字
19 #'\w' 匹配[A-Za-z0-9]
20 #'\W' 匹配非[A-Za-z0-9]
21 #'s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
22 #23 #'(?P...)' 分组匹配 re.search("(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
24
25
26 #常用的匹配方法
27 #re.match 从头开始匹配
28 #re.search 匹配包含
29 #re.findall 把所有匹配到的字符放到以列表中的元素返回
30 #re.splitall 以匹配到的字符当做列表分隔符
31 #re.sub 匹配字符并替换
32
33 #仅需轻轻知道的几个匹配模式
34 #35 #re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
36 #M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
37 #S(DOTALL): 点任意匹配模式,改变'.'的行为
re.match是从头开始的
1 #正则表达式的练习
2 importre3 >>> re.match("^baidu","baidu.com")4 <_sre.sre_match object span="(0," match="baidu">#match就是匹配到的结果,如果没有返回,就证明没有匹配到
1 >>> ret = re.match("^www\d","www123baidu456")#一个\d表示匹配后面的一个数字
2 >>>ret.group()3 'www1'
4 >>> ret = re.match("^www\d+","www123baidu456")#加上一个+代表匹配后面紧跟着的所有数字
5 >>>ret.group()6 'www123'#如果没有就是None
1 >>> re.match(".","www123baidu456")#匹配一个字符
2 <_sre.sre_match object span="(0," match="w">
3 >>> re.match(".+","www123baidu456")#加上一个加就匹配所有了
4 <_sre.sre_match object span="(0," match="www123baidu456">
re.search
1 >>> re.match(".","www123baidu456")#语法二,查找
2 <_sre.sre_match object span="(0," match="w">
3 >>> re.match(".+","www123baidu456")4 <_sre.sre_match object span="(0," match="www123baidu456">
1 >>> re.search("@.+@$","123@baidu@")#匹配某个关键字中间(包含关键字)
2 <_sre.sre_match object span="(3," match="@baidu@">
1 ?#匹配次或0次
1 re.search("b?","bbbaidu")
2 <_sre.sre_match object span="(0," match="b">
3 >>> re.search("b?","aidu")#?前面的可以有,也可以没有,没有就匹配后面的4 <_sre.sre_match object span="(0," match="">
1 >>> re.search("[0-9]{4}","daf123bbbk4567")#{4}代表连续几个数字
2 <_sre.sre_match object span="(10," match="4567">
换个套路,如果我想匹配字符串里面所有的数字或者字母呢
1 >>> re.findall("[0-9]{1,3}","daf34dkafjl675kdla98dfasfa536")2 ['34', '675', '98', '536']3
4 >>> re.findall("[0-9]{1,2}","daf34dkafjl675kdla98dfasfa536")5 ['34', '67', '5', '98', '53', '6']6
7
8 >>> re.findall("[0-9]{1,5}","daf34dkafjl675kdla98dfasfa536")9 ['34', '675', '98', '536']10
11
12 >>> re.findall("[0-9]{1}","daf34dkafjl675kdla98dfasfa536")13 ['3', '4', '6', '7', '5', '9', '8', '5', '3', '6']14
15
16 >>> re.findall("[0-9]{1,4}","daf34dkafjl675kdla98dfasfa536")17 ['34', '675', '98', '536']
>>> re.findall("[0-9]{3}","daf34dkafjl675kdla98dfasfa536")
['675', '536']
1 #换个方法|(或)
2 >>> re.search("abc|ABC","ABCabc").group()3 'ABC'
4 >>> re.findall("abc|ABC","ABCabc")5 ['ABC', 'abc']
1 #分组匹配
2 >>> re.search("(abc){2}","ddddabccdfabc")#需要连续两个abc才能匹配到,见下面
3 >>> re.search("(abc){2}","ddddabcabc")4 <_sre.sre_match object span="(4," match="abcabc">
#转意符
>>> re.search("(abc){2}\|","ddddabcabc|")#告诉python管道符在这里不是管道符就是一个竖杠用\转意
#分组转意
>>> re.search("(abc){2}\|\|=","ddddabcabc||=")<_sre.sre_match object span="(4," match="abcabc||=">
>>> re.search("(abc){2}(\|\|=){2}","ddddabcabc||=||=")#还是因为管道符在正则表达式里面是或的意思,两个管道符都需要转意
1 #分割split
2 >>> re.split("[0-9]","abc123dfe456gjkd")3 ['abc', '', '', 'dfe', '', '', 'gjkd']4 >>> re.split("[0-9]+","abc123dfe456gjkd")5 ['abc', 'dfe', 'gjkd']
#sub替换
>>> re.sub("[0-9]","|","abc123dfe456gjkd")'abc|||dfe|||gjkd'
>>> re.sub("[0-9]","|","abc123dfe456gjkd",count=2)'abc||3dfe456gjkd'
#re.I#忽略大小写
>>> re.search("[a-z]+","abcdHJ",flags=re.I)<_sre.sre_match object span="(0," match="abcdHJ">
#多行模式flags = re.m(匹配去掉换行继续匹配\n不)
>>> re.search("[a-z]+","\nabcdHJ",flags=re.M)<_sre.sre_match object span="(1," match="abcd">
#匹配任意字符
>>> re.search(".+","\nabcdHJ",flags=re.S)<_sre.sre_match object span="(0," match="\nabcdHJ">
13、logging模块
用于便捷记录日志且线程安全的模块
日志等级:
注意:只有大于当前日志等级的操作才会被记录。
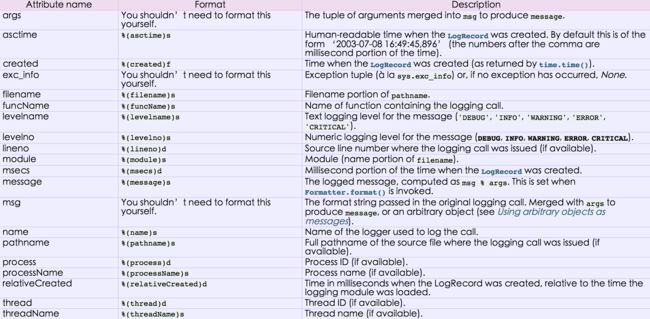
日志格式:
%(name)s:Logger的名字
%(levelno)s:数字形式的日志级别
%(levelname)s:文本形式的日志级别
%(pathname)s:调用日志输出函数的模块的完整路径名,可能没有
%(filename)s:调用日志输出函数的模块的文件名
%(module)s:调用日志输出函数的模块名
%(funcName)s:调用日志输出函数的函数名
%(lineno)d:调用日志输出函数的语句所在的代码行
%(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d:线程ID。可能没有
%(threadName)s:线程名。可能没有
%(process)d:进程ID。可能没有
%(message)s:用户输出的消息