金融现金贷用户数据分析和用户画像(基于12万真实数据)
在全球数字经济时代,有一种金融优势,那就是基于消费者大数据的信用!

我们不妨称之为数据信用,它是一种面向未来的财产权,它是数字货币背后核心的抵押资产,它决定了数字货币时代信用创造的方向、速度和规模。
谁能掌握风控模型和数据分析知识,谁就掌握了数字货币的发行权,就能更准确的说谁能掌握数据分析技能,精准了解客群,谁就能制合理定贷款策略!
现金贷用户如何画像?如何挖掘客户收入,工作,住房等各个维度信息?变量相关性分析还在滥用皮尔森方法吗?我们能用数据分析挖掘出美国潜在金融危机吗?
欢迎各位同学学习金融现金贷用户数据分析和用户画像,链接地址为:https://edu.csdn.net/course/detail/30610
讲师介绍
讲师Toby,持牌照消费金融模型专家,和中科院,中科大教授保持长期项目合作;和同盾,聚信立等外部数据源公司有项目对接。熟悉消费金融场景业务,线上线下业务,包括现金贷,商品贷,医美,反欺诈,汽车金融等等。模型项目200+,擅长Python机器学习建模,对于变量筛选,衍生变量构造,变量缺失率高,正负样本不平衡,共线性高,多算法比较,调参等疑难问题有良好解决方法。
课程概述
此课程用python代码对LendingClub平台贷款数据分析和用户画像,针对银行,消费金融,现金贷等场景,教会学员用python实现金融信贷申请用户数据分析。项目采用lendingclub 12万多条真实信贷数据,包括用户年收入,贷款总额,分期金额,分期数量,职称,住房情况等几十个维度。通过课程学习,我们发现2019年四季度时候,美国多头借贷情况非常严重,为全球系统性金融危机埋下种子。
课程目的
教会学员用python编程实现金融信贷申请用户数据分析和画像
实用人群
银行,消费金融,小额贷,现金贷等线上贷款场景的风控建模相关工作人员,贷前审批模型人员;大学生fintech建模竞赛,论文,专利。
学习计划和方法
1.每天保证1-2个小时学习时间,预计7-14天可以学习完整门课程。
2.每节课的代码实操要保证,建议不要直接复制粘贴代码,自己实操一遍代码对大脑记忆很重要,有利于巩固知识。
3.第二次学习时要总结上一节课内容,必要时做好笔记,加深大脑理解。
4.不懂问题要罗列出来,先自己上网查询,查不到的可以咨询老师。
课程目录
章节1python编程环境搭建
课时1.金融现金贷用户数据分析和画像_介绍视频
课时2.Anaconda快速入门指南
课时3.Anaconda下载安装
课时4.python第三方包安装(pip和conda install)
章节2金融现金贷用户数据分析和画像
课时5.描述性统计-知己知彼百战百胜
课时6.好坏客户占比严重失衡
课时7不要用相关性分析杀人
课时8变量相关性分析-你不知道的秘密
课时9贷款金额和趋势分析-2018年Q4信贷略有缩紧
课时10产品周期分析-看来lendingclub是短周期借贷平台
课时11用户工龄分析-10年工龄用户最多
课时12年收入分析-很多美国人年薪5万美金左右
课时13住房情况与贷款等级-原来美国大部分都是房奴
课时14贷款人收入水平_贷款等级_收入核实多因子分析
课时15贷款用途-美国金融危机浮出水面
课程部分内容展示
Lending Club公司背景
Lending Club 创立于2006年,主营业务是为市场提供P2P贷款的平台中介服务,公司总部位于旧金山。
公司在运营初期仅提供个人贷款服务,至2012年平台贷款总额达10亿美元规模。
2014年12月,Lending Club在纽交所上市,成为当年最大的科技股IPO。
2014年后公司开始为小企业提供商业贷款服务。
2015年全年Lending Club平台新设贷款金额达到了83.6亿美元。
2016年上半年Lending club爆出违规放贷丑闻,创始人离职,股价持续下跌,全年亏损额达1.46亿美元。
2019-2020年公司业务被迫转型,可能和美国高负债率,用户违约率上升有关。
作为P2P界的鼻祖,Lending club跌宕起伏的发展历史还是挺吸引人的。
此处介绍一下什么是P2P。概括起来可以这样理解,“所有不涉及传统银行做媒介的信贷行为都是P2P”。简单点来说,P2P公司不会出借自有资金,而是充当“中间人”的角色,连接借款人与出借人需求。
借款人高兴的是拿到了贷款,而且过程快速便利,免遭传统银行手续众多的折磨;出借人高兴的是借出资金的投资回报远高于存款利率;那么中间人高兴的是用服务换到了流水(拿的便是事成之后的抽成) 最后实现三赢。
P2P初衷是好的,但随着诸多平台建立蓄水池,违规操作和房贷,造成几十万人被骗。2018-2019年国内对P2P监管越来越严,到了2020年,P2P基本清退。只有持牌照的公司才能放贷。
贷款标准
借款人提交申请后,Lending Club 会根据贷款标准进行初步审查。贷款人需要满足以下标准才能借款:
1.FICO 分数在660 分以上

FICO分数等级划分
2.债务收入比例低于40%
3.信用报告反应以下情况:至少有两个循环账户正在使用,最近6 个月不超过5 次被调查,至少36 个月的信用记录
贷款等级grade
贷款分为A、B、C、D、E、F、G 7 个等级,每个等级又包含了1、2、3、4、5 五个子级。
二、目的
研究影响贷款等级的相关因素,并探寻潜藏在数据背后的一些规律
三、数据集获取
选取2018年第四季度数据集以及特征变量的说明文档。

官网上下载数据集
已翻译的特征说明文档
说明:部分重要的特征变量似乎缺失,多次下载的数据集中缺少fico分数、fico_range_low、fico_range_high等与fico相关的特征,所以在形成结论进行总结的时候,这些特征的结论将从相关的报告中获取。
四、数据处理
在对数据进行处理前,我们需要对数据有一个整体的认识
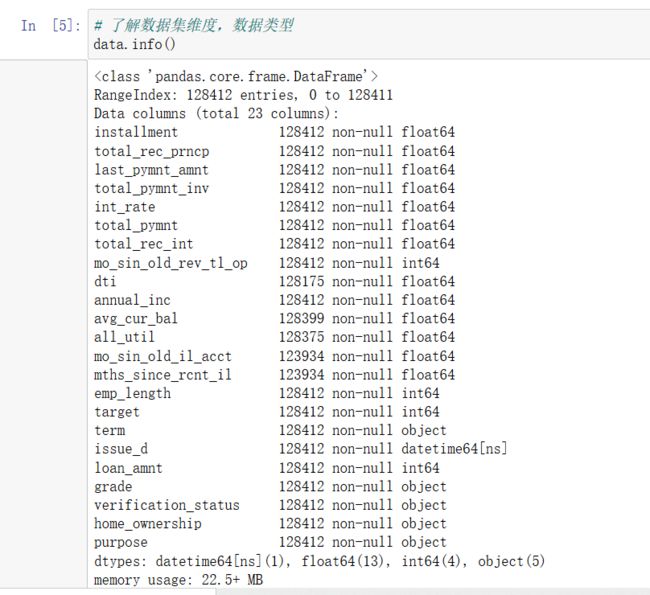
从上述的信息中可以看出:
1.128412行数据,23个特征变量(抽选比较重要的变量,原始变量有110多个)
2.13个特征变量中有86个是浮点数类型,5个是Object对象。
调用data.describe()函数对数据描述性统计,观察各个变量的计数,平均值,标准差,最大值,最小值,1/4位数和3/4位数值,并观察一下异常值。

Object基类对象的数据分布情况
从图表中可以得到部分信息:
1.贷款共7个等级,占比最多的是B级
2.还款的形式有两种,占比最多的是36个月
3.贷款人中大多数人工龄10+年
4.贷款人的房屋状况大多是抵押贷款
5.大多数人贷款的目的是债务整合
6.id与desc特征的数据缺失率高达0.99,间接表明这两个特征可以删除掉。
同样可以按照这种方式对浮点型的数据进行数据预览,得到均值、标准差、四分位数以及数据的缺失比重等信息。
我们调用hist函数可以对数据的所有维度绘制直方图,一目了然观察所有变量数据分布。

第四季度贷款等级变化趋势
首先我们来看一下2018年第四季度业务开展情况,主要是放款笔数,金额,期限等情况。第四季度放款笔数和放款金额略有下降,业务上是有意义的,年底坏账率会上升,平台会收紧。特别是在国内,年底收紧幅度比较大。

贷款金额分析:
通过seaborn,scipy,pandas三个包,我们绘制了一个正太分布图,观察lendingclub平台给个人贷款金额大多在1万-2万美金,较高金额的贷款数量较少,此平台主要是小额贷为主。
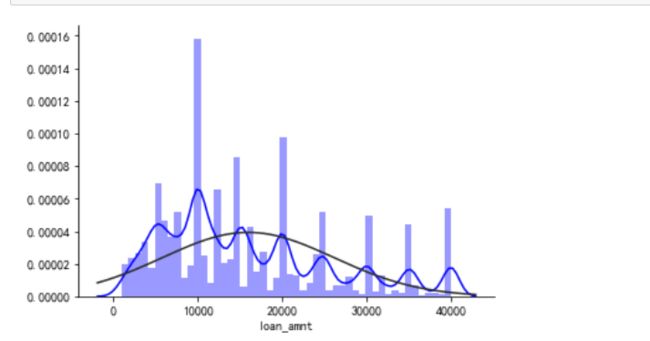
贷款周期占比

通过绘制饼状图,我们得到lendingclub平台贷款周期分为36个月与60个月,主要以36个月为主,60个月的比重31%左右。
在p2p平台上以短期贷款为主,长期贷款也有,利率较高,但周期较长。借出人收获利息,承担风险,而借入人到期要偿还本金。贷款周期越长,对借出人来说风险越高。
在国内的环境下,借出人不仅要承担推迟还款的风险,还要担心平台跑路、本息全无的高风险;对借入人来说,因为国内缺少健全的征信体系,借款方违约及重复违约成本低。
对国内的情况不再多说,话题绕回来。国外的部分国家已有健全的征信体系,一旦违约还款,违约率不断上涨,个人征信也会保留记录,对后序的贷款、买房有很大的影响。
所以如果贷款周期较长,且如果没有固定的工作和固定的收入的话(即使有未定收入也不一定如期偿还),偿还本金充满变数,很有可能违约。
接下来我们再试着对贷款人进行分析,形成一下用户画像吧。
贷款人工龄分布图
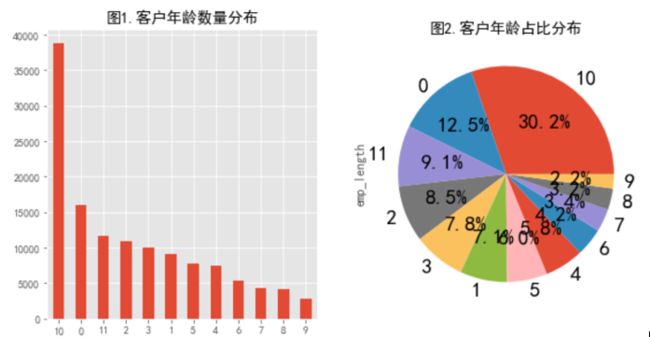
从图中可以看出,贷款人中工龄为10年以上频率最多。那么,我们可以考虑一下,为什么工龄超过10年的人有贷款需求呢?且占比这么高?
那么可以猜测一下(个人意见),首先可能是工龄越长,贷款通过率越高(筛选后占比较高),这可能和lendingclub贷前审批策略有关。
贷款人收入水平

通过上图发现,美国贷款人收入水平中年收入在0-5万美元的占比最高,30.53%左右。其次是5万-10万区间,11万-30万年收入区间占比逐步变小。
得到这张图并不容易,是对数据进行深度清洗后得到的。特别是调用了pandas的cut函数,对收入变量进行分箱处理。

贷款人年收入,贷款等级,收入验证多因子分析

lending club会对客户收入进行验证,这非常值得国内平台学习。贷款人的收入水平信息分为三种情况:已经过LC验证,收入来源已验证,未验证。这三种情况目前从图中看出LC验证,收入来源已验证,未验证的收入数据还是有显著区别。另外贷款等级与收入水平在整体上呈正相关的趋势。上图由seaborn的的factorplot函数生成。factorplot函数是用于多因子分析的,非常实用。
借款人住房状况分布图
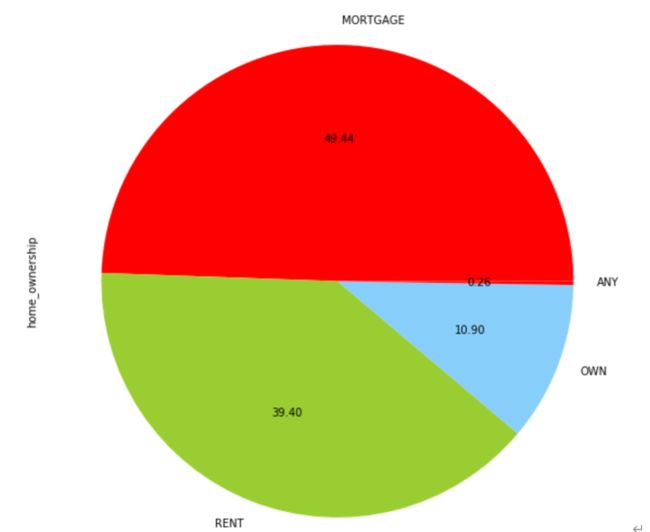
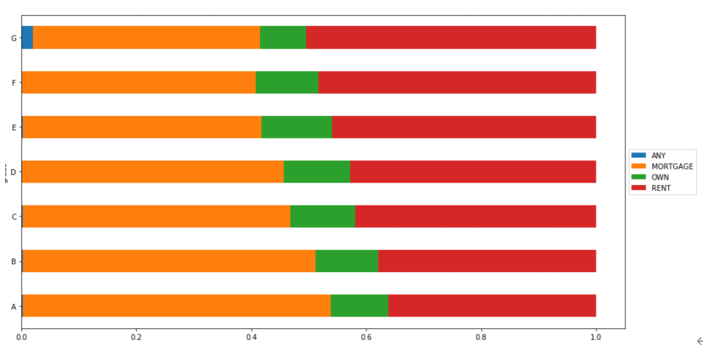
一半用户房屋状态是抵押贷款,只有10%用户拥有完全的产权。看来美国房奴大军不小呀!接着用pandas的stack和unstack函数对grade和home_ownship两个等级变量做数据深度清洗,然后绘制下图。通过观察贷款等级越高用户按揭占比越高,租房占比越低,反之亦然。自有住房占比每个等级略有不同。
贷款用途分布
上图中debt_consolidation(可以理解为债务整合,借新还旧)占比最高,占比第二高的credit_card也归属为同一类。不同平台新债还旧债属于多头借贷行为,多头借贷会提升用户负债率,而负债率会引发经济系统性危机。经济危机会进一步提高社会基尼系数,引发社会动荡。多头借贷是一个非常敏感的指标,无论公司还是地方政府都应该监控此指标。
从历史经验看,举债发展导致住户部门高杠杆和过快的债务增速,与债务危机显著相关。如日本平成大萧条,韩国信用卡危机,美国次贷危机,均是居民负责短期内快速上涨,导致收入,储蓄及资产价值无法偿付债务,从而造成金融系统系风险。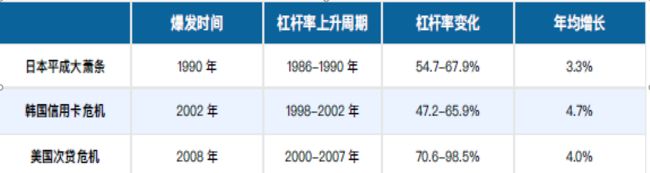
美国上个世纪开始就提倡超前消费观念刺激经济,传统储蓄观念备受冷漠。但人有不愿意还钱倾向,债务越高,金融危机风险越大。2019年美国债务占GDP比重已经高到106%,也就是说美国创造的社会财富还不够还债。1970年时,债务只占GDP38%左右,由此可见华尔街贪欲程度,可以用too much, never enough来形容。很巧的是,我们在lending club数据分析时就发现了这猫腻,发现大多借款人借款目的就是新债换旧债。无论新冠状病毒是否爆发,美国金融体系已经存在严重系统风险,而且其他国家也存在类似问题,只是负债程度不一样。

专业人士预测到2025年,美国负债占GDP比重可能达到140%,负债呈现逐年上升趋势。

居民负债率上升,富人却通过房贷和货币宽松政策获利,从而导致社会基尼系数不断上升,社会贫富差距拉大,最后导致社会动荡和战争。下图是几年前全球基尼系数,可以看到美国基尼系数在40-50,实际数据可能更大。

贷款目的与人均收入水平
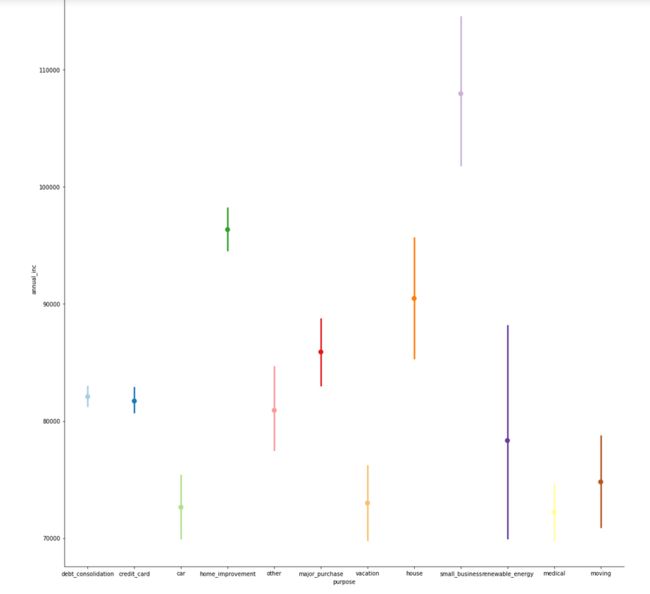
综合收入水平与贷款用途得到上图,我们可以发现在第四季度中,人均收入水平较高的人群贷款用于小生意,家庭生活改善,房子等。而贷款为了债务整合(占比最高)的人群的人均收入水平在整体的中下。收入最低的一般用于医疗开支或车辆相关。这也间接证明了多头借贷的收入会越来越低,陷入贫困陷阱。
变量相关性分析:
数据分析和画像后,我们可以用上述变量建模。建模型并非所有变量都使用,需要做变量筛选工作。变量相关性分析就是最基础的变量筛选步骤。我们用seaborn的heatmap函数绘制出下图变量相关性热力图后,我们发现部分变量呈现0.9高相关性
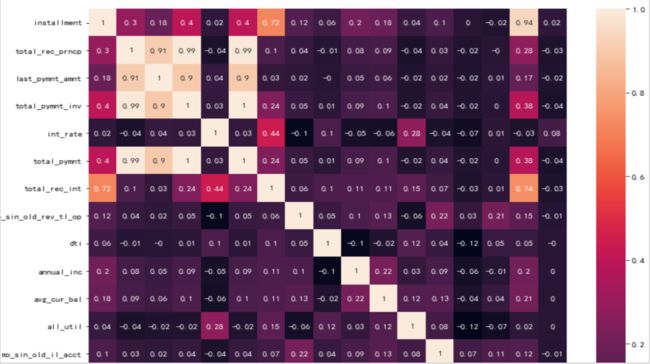
除了python,excel也可以绘制变量相关性热力图,下图由excel生成。
变量相关性取值从0-1,值越接近0,两个变量相关性越低;值越接近1,两个变量相关性越高。下图是变量相关性数据分布。

市场借贷是可能存在歧视或不公平借贷行为的场所。我们研究了从1935年至40年的Redlining与当今的对等2人同行贷款格局之间的空间相关性。
红色-1930年代主要的Redlining城市| 绿色— 2012年Lending Club最高的贷款申请被拒绝| 洋红色-Lending Club在2012年的最高利率
问题表述
作为平等住房贷款人,对等2人贷款市场应该 筛选贷款申请,“不考虑种族,肤色,宗教,国籍,性别,残障或家庭地位”。系统地拒绝使用特定邮政编码的贷款可能会伤害少数群体申请人。这是一个名为做法圈阅1935年-1940之间,当购房者贷款公司或‘HOLC’创建的地图,在近250个美国城市的颜色编码信用和风险在附近的水平。这些地图最近已被数字化,可以在MAPPING INEQUALITY上查看。尽管有联邦《公平住房法》,现代的Redlining最近在美国61个城市中被曝光。另一项调查确定了几家银行,这些银行显然从其客户的投资组合中排除了少数群体。
我们使用Python,Pandas,Jupyter Notebook和Geopandas库来可视化Lending Club(世界上最大的P2P借贷平台)的2400万笔贷款申请。目的是调查邮政编码在1930年代“红线”的申请人是否更可能被当今的市场拒绝。如果不是,我们将核实此类贷款申请人的违约率是否更高。从2006年至2007年至今,我们还希望探讨这些关系在Lending Club整个生命周期中如何演变。
整理数据收集
该映射不等式的网站提供了一个选项,以下载shapfiles这是“美国所有城市的红线”,在20世纪30年代回来。shapefile包含描述每个城市中的邻域(区域)的多边形的经纬度坐标,这些多边形由HOLC界定。
import geopandas as gpd
df_redlines_map = gpd.read_file('data / HOLC_ALL.shp')
df_redlines_map.head()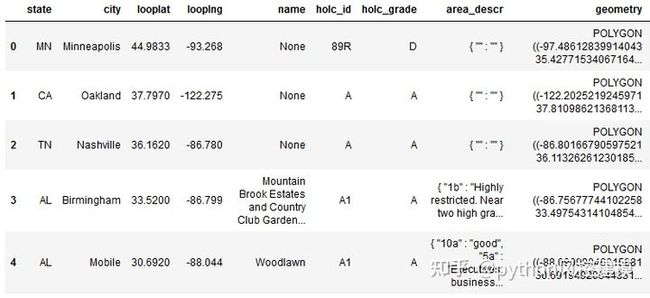
图1
每行代表一个具有以下特征的多边形(区域):
州:美国州
城市:美国城市,
looplat,looplng:多边形的起始坐标,
名称:地区名称
holc_id:区域nr,
holc_grade:HOLC(安全)等级,
area_descr:区域描述,
geometry:构建多边形的所有坐标的集合。
该HOLC等级描述了被分配到20世纪30年代的区域回信用,如下所示:
A-最佳
B-仍可取
C-绝对下降
D-危险
我们清除那些HOLC等级无效的多边形。
df_redlines_map = df_redlines_map [df_redlines_map.holc_grade!='E']1红线功能工程
在深入分析之前,我们不但要查看HOLC分配的等级分布,不仅要在每个邮政编码内,还要在州一级。这就需要对1930年代每个地区的人口进行估算。天真的方法是使用每个HOLC等级的区域计数。由于相应多边形的大小相差很大,因此我们可能无法完全了解总体大小。因此,我们选择使用区域面积(以km2为单位)作为基准单位。
我们首先以平方公里为单位计算每个区域的面积及其地理中心(“质心”)。
proj = partial(pyproj.transform, pyproj.Proj(init='epsg:4326'), pyproj.Proj(init='epsg:3857'))
df_redlines_map['area'] = [transform(proj, g).area/1e+6 for g in df_redlines_map['geometry'].values]
df_redlines_map['centroid_lat'] = df_redlines_map.geometry.centroid.y
df_redlines_map['centroid_long'] = df_redlines_map.geometry.centroid.x
df_redlines_map.head()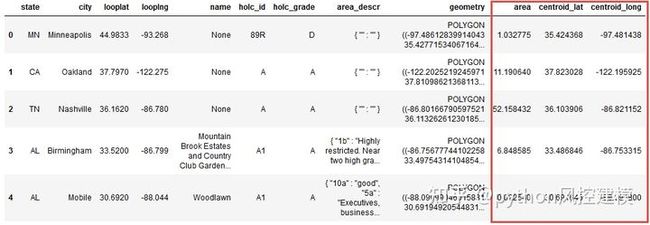
图2
现在,我们将使用其质心的坐标添加每个区域的邮政编码。为此,我们依靠免费的Python库uszipcode,该库使用其自己的最新地理编码数据数据库对每100个区域进行地理解码。
from uszipcode import SearchEngine
i = 0
while i < df_redlines_map.shape[0]:
df_redlines_map.loc[i:i+100,'zipcode'] = df_redlines_map[i:i+100].apply(lambda row: search.by_coordinates(row.centroid_lat,row.centroid_long, radius=30, returns=1)[0].zipcode, axis=1)
i = i + 100
df_redlines_map.head()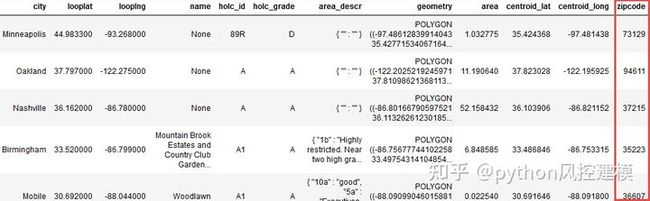
图3
计算每个邮政编码的总红线区域现在很简单。
df_redlines = df_redlines_map.groupby(['zipcode'])。agg({'area':np.sum})。reset_index()。rename(columns = {'area':'zip_area'}))
df_redlines.head()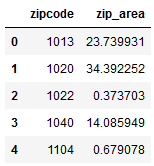
图4
现在,我们可以计算每个州的总红线面积。
df_redlines_state = df_redlines_map.groupby(['state'])。agg({'area':np.sum})。reset_index()。rename(columns = {'area':'state_area'})
df_redlines_state.head()图5
使用先前的计算,我们可以获得每个州内HOLC等级的百分比分布。
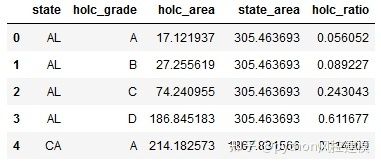
图6
我们还可以为每个邮政编码计算相似的值。
df_redlines_details = df_redlines_map.groupby(['zipcode','holc_grade']).agg({'area': np.sum}).reset_index().rename(columns={'area': 'holc_area'})
df_redlines_details = df_redlines_details.merge(df_redlines[['zipcode','zip_area']], on='zipcode', how='left')
df_redlines_details['holc_ratio'] = df_redlines_details.holc_area/df_redlines_details.zip_area
df_redlines_details.head()

图7
稍后我们将看到,一些有趣的可视化要求我们将等级值转换为特征。这使我们能够计算每个区域内A,B,C和D子区域的面积比,如下所示。考虑到没有HOLC区域的邮政编码,我们用零填充缺失的比率值。
for grade in ['A', 'B', 'C', 'D']: df1 = df_redlines_map[df_redlines_map.holc_grade==grade].groupby(['zipcode']).agg({'area': np.sum}).reset_index().rename(columns={'area': grade + '_area'}) df_redlines = df_redlines.merge(df1, on='zipcode', how='left') df_redlines[grade + '_ratio'] = df_redlines[grade + '_area'] / df_redlines.zip_areadf_redlines.fillna(0, inplace=True)这些比率有助于我们估算所谓的HOLC拒绝比率,该比率定义为1930年代由于Redlining而在邮政编码内被拒绝的贷款申请的百分比。假设A区申请人的比例为0%,C区和D区申请人的比例为100%,B区申请人的比例为90%。我们为B区选择90%,因为它接近文献中发现的平均拒绝率
df_redlines ['holc_reject_ratio'] =(.9 * df_redlines.B_ratio + df_redlines.C_ratio + df_redlines.D_ratio)
df_redlines.head()
图8
红线探索
下面的条形图显示,HOLC认为的大多数区域在1930年代被列为危险或绝对下降。
redlines_labels = {'grade': ['A', 'B', 'C', 'D'],
'desc':['A - Best', 'B - Still Desirable', 'C - Definitely Declining', 'D - Hazardous'],
'color': ['g', 'b', 'y', 'r']
}
fig, ax = plt.subplots(1,1,figsize=(15,5))
sns.countplot(y='holc_grade',data=df_redlines_map, palette=redlines_labels['color'], ax=ax)
ax.set_title('Count of zones per grade');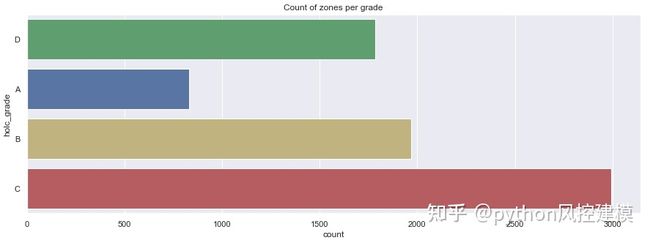
图9
HOLC涂红线的区域通常不是很大,小于5 km2。我们注意到很少有离群点,其表面达到以下180 km2。
fig, ax = plt.subplots(1,1,figsize=(15,5))
sns.boxplot(y="holc_grade", x="area", palette=redlines_labels['color'],data=df_redlines_map, ax=ax)
sns.despine(offset=10, trim=True)
ax.set_title('Distribution of zone areas (km^2) per HOLC grade');
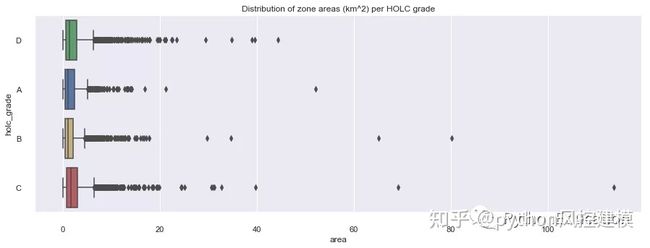
图10
根据HOLC在1930年代分类,AL(阿拉巴马州)和KS(堪萨斯州)的危险区最大。NH(新罕布什尔州)和IN(印第安纳州)州的区域大部分被分类为“绝对下降”。
fig, ax = plt.subplots(1,1,figsize=(20,5))
sns.barplot(x="state", y="holc_ratio", hue='holc_grade', data=df_redlines_state_details, ax=ax)
ax.set_title('Holc Grade Ratio per state');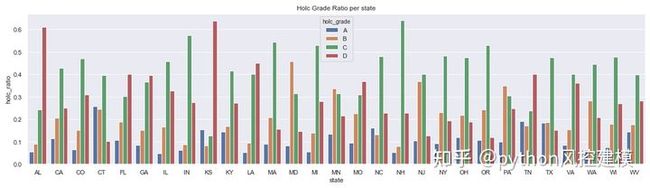
贷款特征工程
在浏览Redlining数据之后,现在让我们看一下今天的贷款。从Lending Club网站下载了2007年第一季度至2018年第二季度之间收到的所有贷款申请。合并和整理的数据由此处引用的项目的作者提供给我们。
df_loan = pd.read_csv('data / df_reject_ratio_2007-2018.csv')
df_loan.head()
图12
每个贷款申请都由以下功能描述:
issue_d:收到申请的日期。
邮政编码:申请人(借款人)的邮政编码的3位数字。Lending Club不会出于隐私考虑而发布完整的邮政编码。
被拒绝:如果申请被Lending Club拒绝,则标记值为1,否则为0。
等级:表示利率的类别(仅适用于未拒绝的申请)。
“基于每笔贷款申请和信用报告,每笔贷款都被分配了从A到G的等级以及相应的利率。” 每个贷款等级及其相应的当前利率都显示在Lending Club网站上。
print('There have been {} loans requests received at Lending Club since 2007, of which {} have been rejected'.format(df_loan.shape[0], df_loan[df_loan.rejected==1].shape[0]))
There have been 24473165 loans requests received at Lending Club since 2007, of which 22469074 have been rejected探索大型时间序列的一种常用方法是根据较大的时间单位(例如季度)汇总感兴趣的特征。Lending Club数据的问题是issue_d的格式,许多行的格式为YYYY-MM-DD,但是我们也可以找到格式为b-YYYY的日期。例如,我们看到带有2007–05–26和2011年12月的行。将日期转换为季度时,希望以不同的方式处理每种格式。
具体来说,我们将数据分为两组,每种日期格式一组。
df1 = df_loan [(df_loan.issue_d.str.len()== 10)]
df1 ['issue_q'] = pd.to_datetime(df1.issue_d,format ='%Y-%m-%d')。dt。 to_period('Q')
df1.head()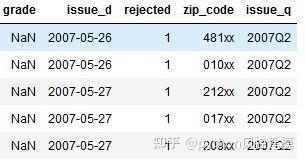

df2 = df_loan [(df_loan.issue_d.str.len()!= 10)]
df2 ['issue_q'] = pd.to_datetime(df2.issue_d,format ='%b-%Y')。dt.to_period(' q')
df2.head()图14
现在,我们可以合并两个数据集。
df_loan = df1.append(df2)我们进一步使用该数据计算Lending Club贷款拒绝率,该比率定义为每个季度每个邮政编码拒绝的贷款申请的百分比。
df_loan_reject_ratio = df_loan[['issue_q','zip_code','rejected']].groupby(['issue_q','zip_code']).agg(['count', 'sum'])
df_loan_reject_ratio.columns = df_loan_reject_ratio.columns.droplevel(level=0)
df_loan_reject_ratio = df_loan_reject_ratio.rename(columns={'count':'lc_total_requested', 'sum':'lc_total_rejected'})
df_loan_reject_ratio['lc_total_accepted'] = df_loan_reject_ratio.lc_total_requested - df_loan_reject_ratio.lc_total_rejected
df_loan_reject_ratio['lc_reject_ratio'] = df_loan_reject_ratio.lc_total_rejected/df_loan_reject_ratio.lc_total_requested
df_loan_reject_ratio = df_loan_reject_ratio.reset_index()
df_loan_reject_ratio.head()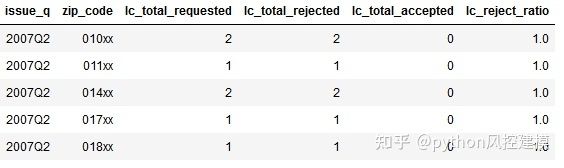
图15
上面的摘要表为每个季度和邮政编码提供了以下数量:
lc_total_requested:收到的贷款申请数量,
lc_total_rejected:拒绝贷款申请的数量,
lc_total_accepted:已接受贷款申请的数量,
lc_reject_ratio:lc_total_rejected与lc_total_requested的比率。
同样,我们计算Lending Club贷款等级比率(每个邮政编码和季度具有特定利率的贷款百分比)。
df_loan_grades = df_loan[df_loan.rejected==0][['issue_q','zip_code','issue_d']].groupby(['issue_q','zip_code']).count().reset_index().rename(columns={'issue_d':'total_accepted'})
for grade in ['A', 'B', 'C', 'D', 'E', 'F', 'G']:
df1 = df_loan[(df_loan.rejected==0)&(df_loan.grade==grade)][['issue_q','zip_code','issue_d']].groupby(['issue_q','zip_code']).count().reset_index().rename(columns={'issue_d': 'LC_' + grade + '_accepted'})
df_loan_grades = df_loan_grades.merge(df1, on=['issue_q','zip_code'], how='left')
df_loan_grades['LC_' + grade + '_ratio'] = df_loan_grades['LC_' + grade + '_accepted'] / df_loan_grades.total_accepted
图16
例如,LC_A_accepted是已接受并分配了利率A的申请数。LC_A_ratio是相应的百分比率。
贷款和红线数据合并
现在,我们准备合并贷款和Redlining数据,使我们可以尝试不同的可视化效果,并在研究2007-2018年的贷款与Redlining时提出有趣的问题。
由于Lending Club仅从申请人的邮政编码中披露了五分之三的数字,因此我们将必须汇总数据并根据123xx邮政编码模式进行合并。
df_redlines ['zip_code'] = df_redlines ['zipcode']。astype('str')
df_redlines ['zip_code'] = df_redlines ['zip_code']。str.pad(5,'left','0')
df_redlines [ 'zip_code'] = df_redlines ['zip_code']。str.slice(0,3)
df_redlines ['zip_code'] = df_redlines ['zip_code']。str.pad(5,'right','x')
df_redlines_aggr = df_redlines.fillna(0).groupby('zip_code')。agg({'zip_area':np.sum,
'A_area':np.sum,'B_area':np.sum,'C_area':np.sum,' D_area”:np.sum,“ A_ratio”:np.mean,“ B_ratio”:np.mean,“ C_ratio”:np.mean,“ D_ratio”:np.mean,“ holc_reject_ratio”:np.mean})。 ()
df_redlines_aggr.head()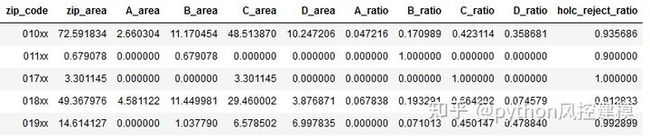
图17
上表显示了1930年代以123xx邮政编码模式表示的区域中按HOLC排序的A,B,C或D区域的总面积(km2),其中123是Lending公开的邮政编码数字的代表数字俱乐部。还提供了每个HOLC等级的总面积比以及HOLC的总拒收率。
继续这个聚合的Redlining数据集,我们现在将添加贷款数据。对于缺少贷款数据或Redlining数据的123xx地区,空比率被0代替。
df_redlines_loan = df_loan_reject_ratio.merge(df_loan_grades,on = ['zip_code','issue_q'],how ='left')。merge(df_redlines_aggr,on ='zip_code',how ='left')
df_redlines_loan.issue_q。 .astype('str')
df_redlines_loan.fillna(0,
inplace = True)df_redlines_loan.head()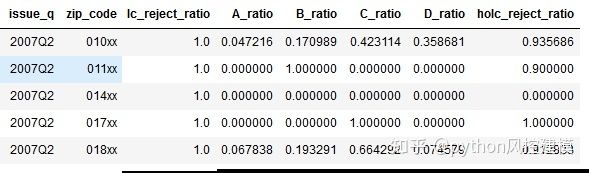
图18
结果
查看下面的线图,我们可以看到,与1930年代相比,Lending Club似乎平均拒绝接受更多的贷款。我们可以预期,废品率在未来还会进一步增加。
fig, ax = plt.subplots(1,1,figsize=(15,5))
sns.lineplot(x="issue_q", y="lc_reject_ratio",data=df_redlines_loan, ax=ax, label='LendingClub reject ratio')
plt.axhline(df_redlines_loan[df_redlines_loan.holc_reject_ratio>0].holc_reject_ratio.mean(), color='r', label='HOLC reject ratio')
plt.axhline(df_redlines_loan.lc_reject_ratio.mean(), color='black', label='LendingClub reject ratio Average')
plt.xlabel('quater')
plt.ylabel('ratio')
plt.title('Average Loan Reject Ratio over time')
plt.legend()
plt.xticks(rotation=45);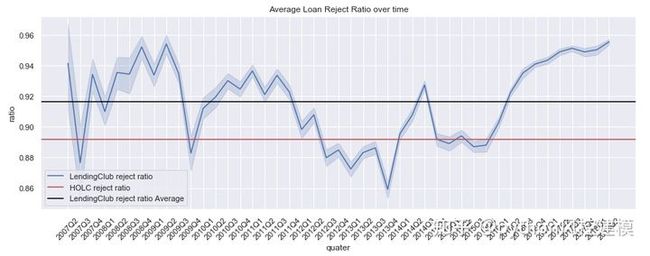
图19
下面的散点图显示Lending Club的贷款拒绝率与HOLC之间存在正相关。这提出了以下假设:1930年代HOLC拒绝最多或几乎所有贷款的区域与Lending Club今天可能拒绝很多贷款的区域相同。
fig, ax = plt.subplots(1,1,figsize=(15,5))
sns.scatterplot(x=’lc_reject_ratio’, y=’holc_reject_ratio’, data=df_redlines_loan[df_redlines_loan.holc_reject_ratio>0], ax=ax)
plt.title(‘Loan Reject Ratio per zipcode — LendingClub versus HOLC’);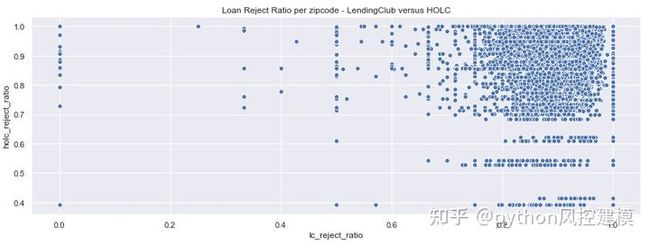
图20
如下图所示,Lending Club的拒绝率分布似乎是在大面积区域复制HOLC拒绝率分布,这些地区在1930年代被划分为“危险”或“明显下降”。
fig, ax = plt.subplots(1,1,figsize=(15,5))
sns.distplot(df_redlines_loan[df_redlines_loan.holc_reject_ratio>0].holc_reject_ratio, color='r', hist = False, kde = True, kde_kws = {'shade': True, 'linewidth': 3}, label='HOLC', ax=ax)
sns.distplot(df_redlines_loan[df_redlines_loan.holc_reject_ratio>0].lc_reject_ratio, color='g', hist = False, kde = True, kde_kws = {'shade': True, 'linewidth': 3}, label='LendingClub', ax=ax)
plt.xlabel('ratio')
plt.title('Loan Reject Ratio Distribution over zipcodes');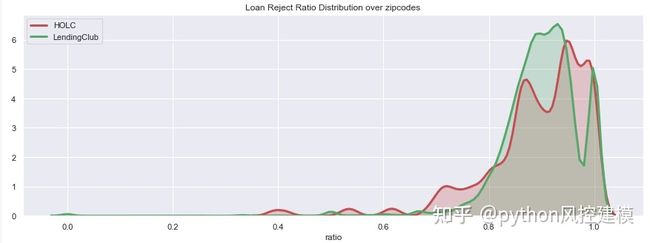
图21
查看下面的热图,HOLC和Lending Club功能之间的相关性非常弱。通常,这可能意味着了解某个地区的HOLC等级并不能帮助我们自信地预测Lending Club的贷款拒绝或贷款利率。
corr = df_redlines_loan.corr()
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
ax.set_title('Correlation between HOLC and LendingClub');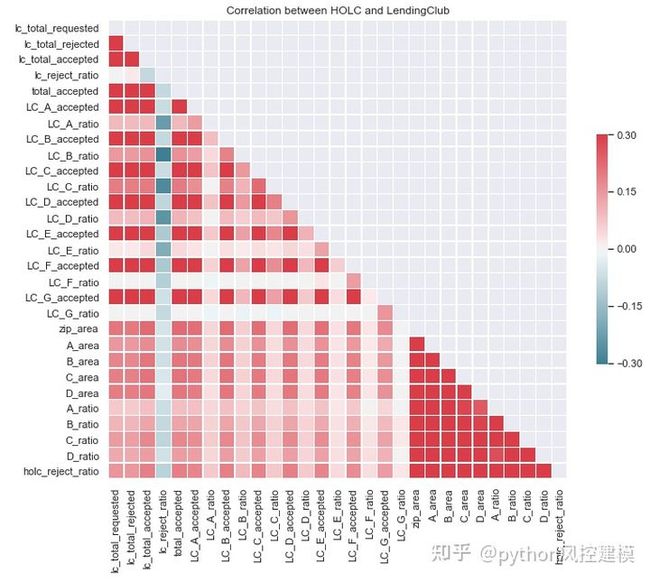
Figure 22
以下分布图表明,在红线区域中几乎没有Lending Club申请人的最低利率(A)。大多数申请人获得中等利率(B,C或D)。只有极少数的申请人需要处理非常高的利率(E,F或G)。这种分布表明,借贷俱乐部可能不会考虑圈阅获得贷款撇账的风险时。
f = df_redlines_loan [[df_redlines_loan.holc_reject_ratio == 1)&(df_redlines_loan.lc_reject_ratio!= 1)]。sort_values(by ='lc_reject_ratio',ascending = False).reset_index()[['zip_code','hol lc_reject_ratio”,“ LC_A_ratio”,“ LC_A_ratio”,“ LC_B_ratio”,“ LC_C_ratio”,“ LC_D_ratio”,“ LC_E_ratio”,“ LC_F_ratio”,“ LC_G_ratio”]]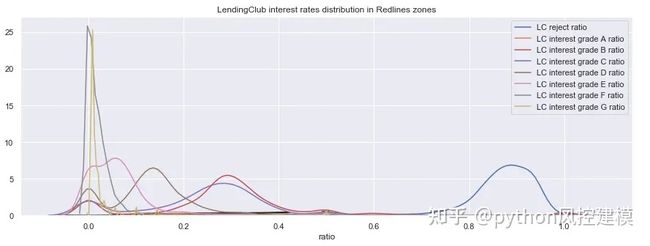
图23
结论1
我们的研究提供了Lending Club进行现代Redlining的一些证据。假设1930年的红线图和当今的Lending Club接受贷款请求和评估违约风险的政策之间存在内在联系,这一假设仍然有效。
Lending Club使用的数据有一些不公平的算法或历史偏见的迹象。从我们的探索性数据分析,尤其是HOLC拒绝率和Lending Club拒绝率之间的正线性趋势来看,这是显而易见的。
之前,我们通过将当今的贷款申请与旧的Redlining邮政编码进行交叉关联,研究了Redlining地图与当今信用状况之间的相关性。在对等2对等借贷市场中,我们发现了一些算法不公平或历史偏见的迹象。尤其是,我们对80年前被分类为危险或绝对下降的相同Redlining地区的贷款申请拒绝率与今天的拒绝率之间呈正线性趋势感到惊讶。
1930年在美国的Redlining为近一个世纪的房地产实践制定了规则,种族不平等深深地影响着城市,以至于我们今天都感受到了他们的遗产。
早在20世纪30年代,日ē购房者贷款公司或‘HOLC’创建地图,彩色编码的信用并使用以下等级在近250个美国城市在附近的风险水平:
A-最佳
B-仍可取
C-绝对下降
D-危险
之前,我们从MAPPING INEQUALITY网站下载了相应的Redlining shapefile,并计算了每个HOLC路基的表面分布(比)。
df_redlines.head()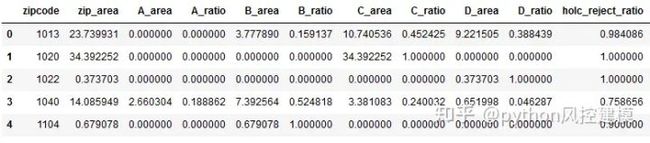
我们还使用LendingClub网站(最大的对等2对等贷款市场)上的2,400万笔贷款申请,以估算每个季度每个邮政编码的平均贷款申请拒绝率。
df_loan_reject_ratio.head()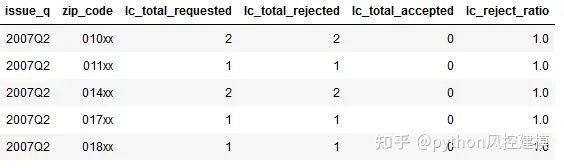
在LendingClub,每笔贷款都被指定从A到G的等级以及相应的利率。我们计算了各个邮政编码之间的成绩分布。
df_loan_grades.head()
在我们的故事的第二部分中,我们想在美国的地理地图上可视化Redlining区域,贷款拒绝率和贷款利率分布。
基线图
我们的可视化效果被构建为多层地图,并以美国等高线图为背景。相应的制图边界shapefile可从人口普查局获得。
df_map_us = gpd.read_file('data / states.shp')
df_map_us.head()
由于我们希望将最终地图限制在美国本土,而不是夏威夷群岛以及太平洋或加勒比海的美国岛屿领地,因此我们将这些州排除在外。
dfu = df_map_us [〜df_map_us.STATE_ABBR.isin(['AK','HI','AA','AE','AP','PR','RI','VI'])]Redlining热点地图
我们地图的下一层应显示1930年代的Redlining热点。
因为我们在第1部分中对每个邮政编码的Redlining数据进行了汇总,所以我们需要使用美国邮政编码的制图边界shapfile。该文件可从人口普查局网站下载。
df_zipcodes = gpd.read_file('data/cb_2017_us_zcta510_500k.shp')
df_zipcodes.rename(columns={'ZCTA5CE10':'zipcode'}, inplace=True)
df_redlines.zipcode = df_redlines.zipcode.astype('str')
df_redlines.zipcode = df_redlines.zipcode.str.pad(5, 'left', '0')为了能够将美国邮政编码多边形与Redlining摘要数据连接在一起,我们创建了一个新列,其中包含123xx邮政编码模式。
df_zipcodes ['zip_code'] = df_zipcodes ['zipcode']。astype('str')
df_zipcodes ['zip_code'] = df_zipcodes ['zip_code']。str.pad(5,'left','0')
df_zipcodes [ 'zip_code'] = df_zipcodes ['zip_code']。str.slice(0,3)
df_zipcodes ['zip_code'] = df_zipcodes ['zip_code']。str.pad(5,'right','x')我们使用免费的Python库uszipcode添加州和县信息。
search = SearchEngine(simple_zipcode=True)
df_zipcodes['state'] = df_zipcodes.apply(lambda row: search.by_zipcode(row.zipcode).state, axis=1)
df_zipcodes['county'] = df_zipcodes.apply(lambda row: search.by_zipcode(row.zipcode).county, axis=1)
df_zipcodes.head()
图1
接下来,我们将Redlining数据与邮政编码多边形合并。
df_redlines_maps = df_zipcodes.merge(df_redlines,on ='zipcode',how ='left')我们将多边形限制在美国本土。
df_redlines_maps = df_redlines_maps [〜df_redlines_maps.state.isin(['AK','HI','AA','AE','AP','PR','RI','VI'])]]我们通过在没有HOLC Redlining区域的情况下为邮政编码填充零来处理丢失的数据。
df_redlines_maps.fillna(0,inplace = True)
df_redlines_maps.head()
图2
现在,我们准备使用Geopandas创建我们的第一张地图。下图显示了具有两层的地图:
美国基线图为浅蓝色,
该红线在红色区。
dfm = df_redlines_maps[df_redlines_maps.zip_area>0]
fig, ax = plt.subplots(1, figsize=(50, 50))
dfm.plot(facecolor='red', linewidth=0.8, ax=ax, edgecolor='0.8', alpha=0.8)
dfu.plot(ax=ax, alpha=.1)
ax.axis('off')
ax.set_title('HOLC Redlining Zones', fontdict={'fontsize': '20', 'fontweight' : '3'});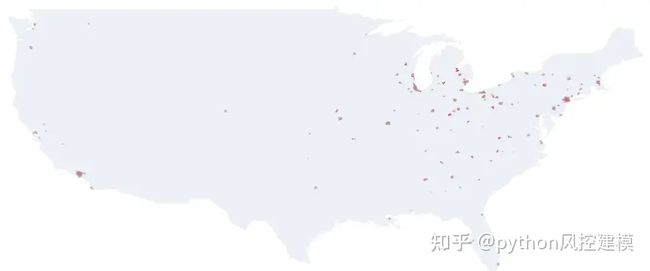
图2
为了更好地查看Redlining区域并区分危险等级,我们将使用每个区域的质心而不是完整的多边形向地图添加另一层
dfmc = dfm.copy()
dfmc.rename(columns = {'geometry':'borders'})。set_geometry('borders')
dfmc ['centroid_column'] = dfmc.centroid
dfmc = dfmc.set_geometry('centroid_column')现在,我们可以在Redlining区域绘制圆。圆圈越多,区域越暗,从而创建热图。
dfm = df_redlines_maps[df_redlines_maps.zip_area>0]
fig, ax = plt.subplots(1, figsize=(50, 50))
dfm.plot(facecolor='red', linewidth=0.8, ax=ax, edgecolor='0.8', alpha=0.8)
dfu.plot(ax=ax, alpha=.1)
ax.axis('off')
ax.set_title('HOLC Redlining Zones', fontdict={'fontsize': '20', 'fontweight' : '3'});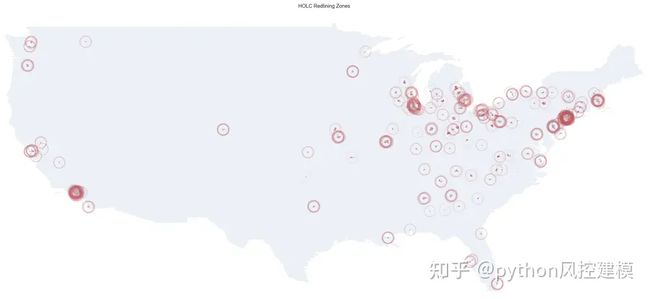
图3
上面的地图看起来像是由MAPPING INEQUALITY (源)生成的地图的精细复制,如下所示。图5
地图层0:美国基准州的地图-浅蓝色的形状显示了美国各州,
图层1:HOLC红线地图-红色圆圈表示在最圈阅发生在20世纪30年代的地方,
地图第2层:LendingClub拒绝率-绿色形状,显示LendingClub拒绝90%以上申请人的地方,
地图层3:LendingClub利率-洋红色形状,显示LendingClub平均分配最高利率的地方。
地图上的颜色可以解释如下:
绿色表示LendingClub的拒收率非常高(> 90%),
深紫色表明HOLC的红线和LendingClub的废品之间存在很强的相关性。当红色形状(来自HOLC)被绿色形状(来自LendingClub)覆盖时,可获得紫罗兰色。
深洋红色表示HOLC红线与LendingClub高利率之间的强烈相关性。
一年之后,即2008年,废品在HOLC区域以外的地方散布开来。但是,HOLC区仍然是那些利率最高的区。
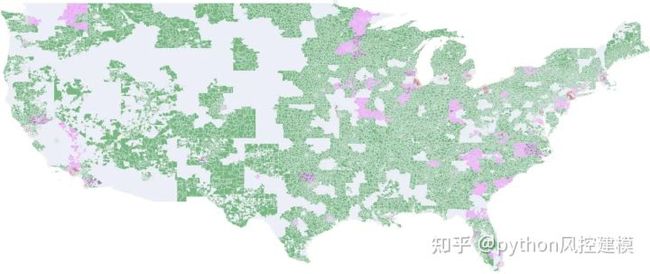
贷款与Redlining地图
现在,我们将在地图顶部添加一个新层,以可视化具有高LendingClub拒绝率的区域。我们选择90%的阈值,该阈值比1930年代的HOLC拒绝率高一些。
dfr = df_loan_reject_ratio [df_loan_reject_ratio.lc_reject_ratio> .9]同样,我们添加了一个新层以突出显示LendingClub为一半以上的贷款分配高利率的区域。
dfg = df_loan_grades.fillna(0)
dfg = dfg [dfg.LC_A_ratio + dfg.LC_B_ratio + dfg.LC_C_ratio <.5]我们的目标是可视化从2007年到2018年之间关于Redlining的对等2对等贷款的地理格局如何演变。我们可以通过如下为每个季度生成一个地图来实现此目的。
dfz = df_zipcodes[~df_zipcodes.state.isin(['AK','HI', 'AA', 'AE','AP','PR','RI','VI'])]
quarters = df_loan_reject_ratio.issue_q.unique()
for q in quarters:
fig, ax = plt.subplots(1, figsize=(50, 50))
dfm.plot(facecolor='red', linewidth=0.8, ax=ax, edgecolor='0.8', alpha=0.8)
dfmc.plot(marker='o', facecolors='none', edgecolors='r', linewidth=0.2, markersize=100, alpha=.2, ax=ax)
ax.axis('off')
dfz.merge(dfr[dfr.issue_q==q], on='zip_code', how='inner').plot(facecolor='green', ax=ax, alpha=.5)
dfz.merge(dfg[dfg.issue_q==q], on='zip_code', how='inner').plot(facecolor='magenta', ax=ax, alpha=.3)
f = dfu.plot(ax=ax, alpha=.1)
f.get_figure().savefig(q+"_loans_reject_ratio.png", dpi=300)在下面,我们可以看到为2007Q2创建的地图。记录了大量贷款申请拒绝的区域与以前的HOLC Redlining区域之间似乎存在关联。
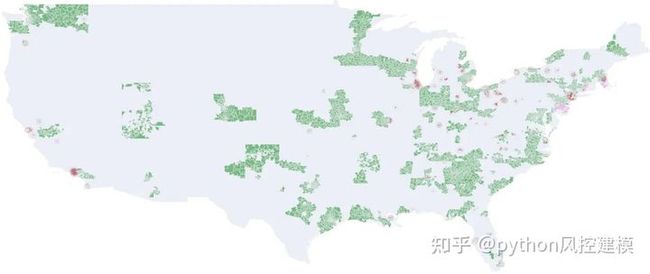
图6
在2012年第一季度之后,我们再也看不到HOLC与LendingClub之间的任何清晰链接。但是,与2012年之前相比,我们可以记录更多的贷款申请拒绝,但是几乎在所有州都发现了这些拒绝,不仅是在Redlining地区。
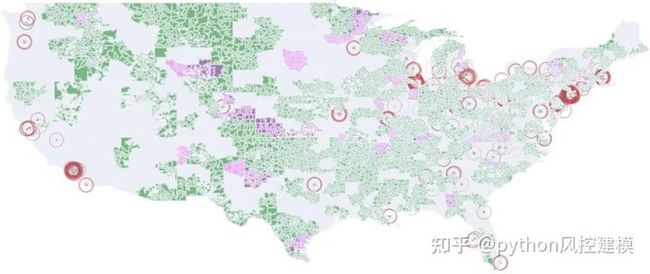
图7
随着LendingClub在2012年之后获得更多的市场份额,我们可以看到其活动在美国各地平均分配,如这张2016Q3图表所示。
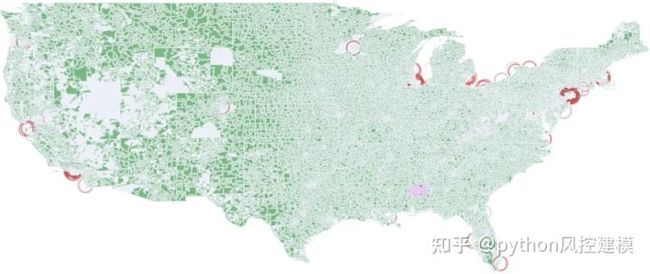
图8
当查看2018年第二季度地图时,似乎已忘记HOLC Redlining,并且不会影响任何LendingClub统计数据。
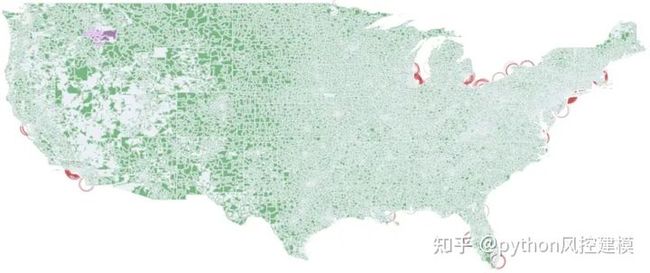
地图动画
使用plot.ly,Dash或类似工具的多层地图动画是一项艰巨的任务。我们发现使用每个季度生成的45张地图来构建GIF,可以更容易地模拟Choropleth地图动画。这是通过首先手动裁剪Geopandas生成的每个地图图像周围的空白来实现的。下一步是使用免费软件IrFanView的批量转换功能将图像的分辨率降低到500x500px。使用相同的工具,我们在每个图像上添加了一个叠加文本,显示了年份和季度。最后,我们使用免费的图像编辑软件Gimp来创建GIF动画。
图10:红色-1930年代主要的Redlining城市| 绿色— Lending Club在2007–2018年间最高的贷款申请被拒绝| 洋红色-Lending Club在2007–2018年的最高利率
结论2
这项工作引起了一些问题,可能需要进一步调查:
LendingClub使用的数据是否包含某种与HOLC重排共线的偏差,例如FICO得分,就业时间,种族?
邮政编码,性别和种族在哪些方面影响LendingClub的决策?
要考虑到HOLC Redlining,必须对风险评估算法进行哪些调整,而哪些显然不属于过去?
我们在该项目中演示了探索性数据分析。使用Geopandas构建了多层地图,作为空间时间序列可视化的展示。我们引入了其他数据科学概念:算法公平性,Web爬网,数据清理,功能工程和相关性分析。
希望本文能引起人们对数据科学中伦理考虑的认识,尤其是在对与人相关的数据使用机器学习时。
如果想了解更多相关知识,欢迎各位朋友报名《python金融风控评分卡模型和数据分析微专业课》:
地址为:https://edu.csdn.net/combo/detail/1927