Attention Is All You Need阅读笔记
NIPS 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
一、简介
提出了Transformer,它是一个避免recurrence(递归)和convolutions(卷积)的模型体系结构,完全依赖于一种注意力机制来计算输入和输出之间的全局依赖关系。并且允许更多的并行化,加速训练。
二、模型
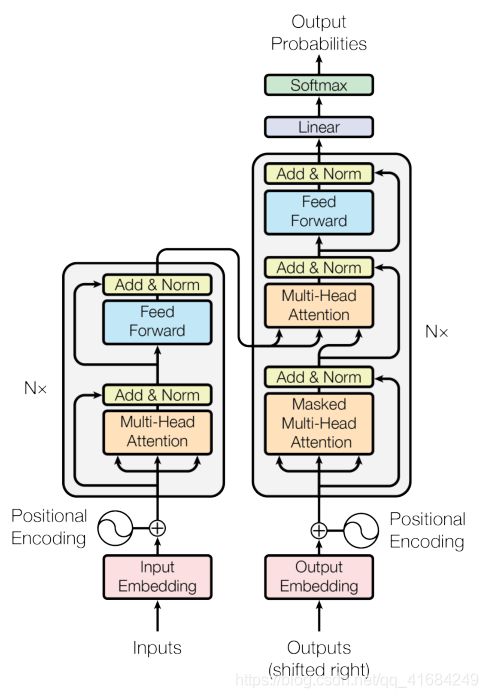
该模型是一个encoder-decoder(编码器-解码器)的结构。
Encoder:
编码器的作用是将输入序列x映射到连续表示序列z。
编码器由N=6个相同的层堆叠组成。每层都有两个子层,一个是Multi-Head Self-Attention mechanism(多头自注意力机制),另一个是positionwise fully connected Feed-Forward network(位置全连接前馈网络)。
为了便于residual connection(残差连接),模型中所有子层以及嵌入层产生的都是维度512的输出。
Deconder:
在给定z的情况下,解码器一次一个元素地生成输出序列y。每一步,模型都是自回归的,即在生成下一步时,使用先前生成地输出作为附加输入。
解码器由N=6个相同的层堆叠组成。每层都有三个子层,一个是Masked Multi-Head Attention,另外两个于编码器的子层相同。
Masked Multi-Head Attention在对编码器输出执行多头关注的情况下,还防止了当前位置关注后续位置的情况。这种掩码与偏移一个位置的输出embedding相结合, 确保对第i 个位置的预测 只能依赖小于i 的已知输出。
解码器的输入也有Q、K和V三个,其中K和V由编码器给出,Q由上一次结果给出。
三、Attention
一个attention function(注意力函数)可以描述为将query(查询)和一组key-value(键值对)映射到输出。其中,query、key、value、输出都是向量。输出通过value的加权求和计算得到,其中分配给每个值的权重是由query与对应key的compatibility function(兼容性函数)计算的。
3.1 Scaled Dot-Product Attention:
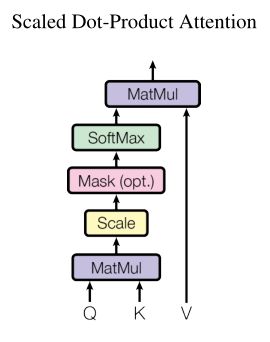
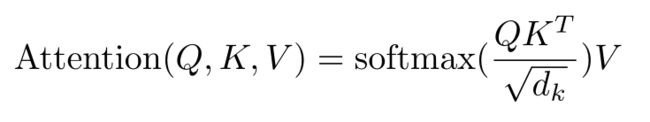
输入的是n个单词嵌入,然后将单词嵌入通过网络(Wq,Wk,Wv)转换成queries(Q)、keys(K)和values(V)。其中,Q由多个query组成,K由多个key组成,V由多个value组成。
MatMul:

MatMul操作是一个点积操作。
如图所示,将Q中的query与K中的每个key相乘,从而得到query对于K中每个key的注意力值。第一个query会与K中的每个key相乘,从而得到a11,a12和a13。
Scale:

两个最常用的注意力函数是加性注意和点积注意。其中点积注意在实践中要快的多,空间效率也更高,因为点积注意可以使用高度优化的矩阵乘法来实现。
但是,当key的维度较大时,加性注意效果优于点积注意。可能的原因是点积的幅度变大,从而将softmax函数推入其梯度极小的区域。为了抵消这种影响,使用了Scale,将MatMul计算的注意力除以√dk。
SoftMax:
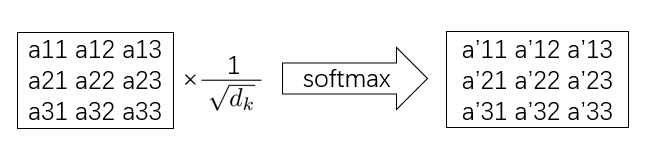
然后对每一组(如a11,a12,a13)使用softmax,使得a11+a12+a13=1。从而得到了value的权重。
加权平均(MatMul):

最后的输出通过value的加权求和计算得到。
3.2 Multi-Head Attention
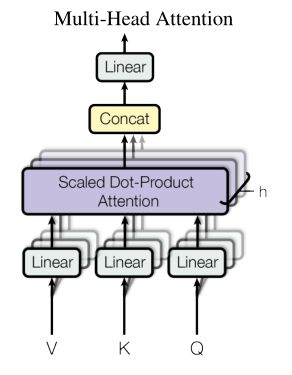
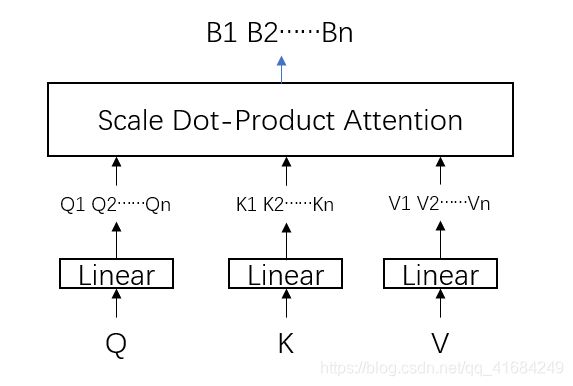
将Q、K和V通过全连接层进行学习得到多个投影。
然后对每一对投影(例如Q1、K1和V1这样子为一对)进行3.1的注意力机制学习,最终得到输出B1、B2…Bn。
实验投影了8组,投影的QKV的维度为64。

然后将得到的B1、B2…Bn进行拼接以后经过一个全连接层,从而得到最后的输出B。
3.3 Position-wise Feed-Forward Networks
![]()
编码器和解码器的每一层都包含一个前馈网络,该网络由两个全连接层组成,其间使用ReLU激活函数。
先变成2048维然后变为512维。
3.4 Positional Encoding
由于模型不包含递归和卷积,为了使模型利用序列的顺序,我们必须注入一些关于序列的相对或者绝对位置的信息。
为此,我们将位置编码加入到输入嵌入中。位置编码有可学习的,也有固定的,本次工作,我们使用不同频率的正弦和余弦函数。我们之所以选择正弦曲线,是因为它允许模型扩展到比训练中遇到的序列长度更长的序列。
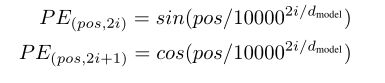
其中pos 是位置,i 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。波长形成了从2π到10000·2π的几何数列。
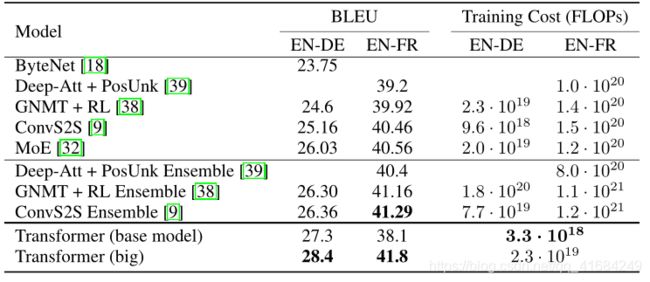
四、实验
我们在标准的WMT 2014英语-德语数据集上进行了训练,其中包含约450万个句子对。 这些句子使用byte-pair编码[3]进行编码,源语句和目标语句共享大约37000个词符的词汇表。 对于英语-法语翻译,我们使用大得多的WMT 2014英法数据集,它包含3600万个句子,并将词符分成32000个word-piece词汇表[38]。 序列长度相近的句子一起进行批处理。 每个训练批次的句子对包含大约25000个源词符和25000个目标词符。