高阶数据结构图下篇
目录:
- 图的基本概念二
-
- 深度优先遍历(DFS)
-
- 广度优先遍历(BFS)
- kruskal(克鲁斯卡尔算法)
-
- Prim(普里姆算法)
-
- Dijkstra(迪杰斯特拉算法)
-
- Bellman-ford(贝尔曼-福特算法)
- flyod-warshall(佛洛伊德算法)
图的基本概念二
完全图:任意两个顶点之间有且仅有一条边,则称此图为无向完全图;任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图。
邻接顶点:在无向图G中,若(U,V)是E(G)中的一条边;则称U和V互为邻接顶点,有向图中,则称顶点U邻接到V。
顶点的度:顶点的度是指与它相关联的边的条数,记作deg(V)。
路径:在图G中,若从顶点vi出发有一组边使其可达到顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
路径长度:对于不带权的图,一条路径长度是指该路径上的的边的条数;对于带权的图,一条路径的长度是指该路径上各个边权值的总和
简单路径和回路:若路径上各个顶点均不重复,则称这样的路径为简单路径。若路径上第一个顶点和最后一个顶点重合,则称这样的路径为回路或环。
子图:顶点和边都是原图的一部分。
连通图:在无向图中,如果图中任意一对顶点是连通的,则称为连通图
强连通图:在有向图中,若在每一个顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图为强连通图。
生成树:一个连通图的最小连通子图称作该树的生成树,有n个顶点的连通图的生成树有n个顶点和n-1条边。
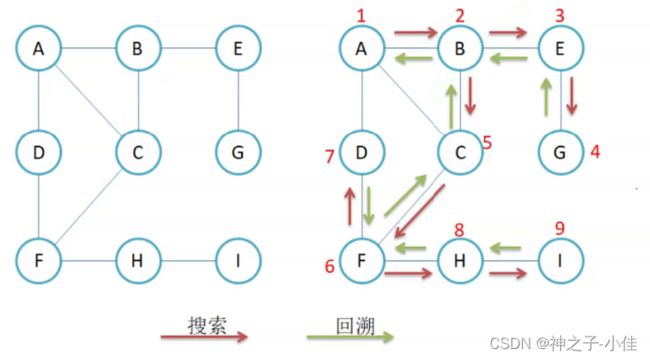
深度优先遍历(DFS):深度优先遍历借助栈结构,将可执行的节点元素逐个入栈,直到本条路径再也找不到可执行的节点。
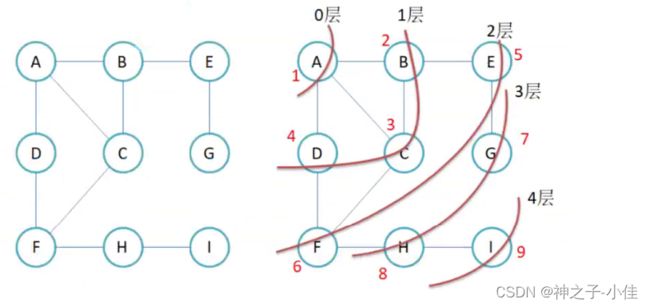
广度优先遍历(BFS):广度优先遍历,又叫宽度优先搜索或横向优先搜索,是从根结点开始沿着树的宽度搜索遍历,将离根节点最近的节点先遍历出来,在继续深挖下去。
最小生成树:构成生成树这些边加起来权值是最小的,最小的成本让这个n个顶点连通。
深度优先遍历(DFS)
深度优先遍历借助栈结构,将可执行的节点元素逐个入栈,直到本条路径再也找不到可执行的节点。
代码如下:
//递归
void _DFS(size_t srci, vector<bool>& visited)
{
cout << srci << ":" << _vertexs[srci] << endl;
visited[srci] = true;//表示这个顶点已经访问过了
// 找一个srci相邻的没有访问过的点,去往深度遍历
for (size_t i = 0; i < _vertexs.size(); ++i)
{
if (_matrix[srci][i] != MAX_W && visited[i] == false)//表示这个顶点相连且没有访问过
{
_DFS(i, visited);
}
}
}
void DFS(const V& src)
{
size_t srci = GetVertexIndex(src);
vector<bool> visited(_vertexs.size(), false);
_DFS(srci, visited);
}
广度优先遍历(BFS)
广度优先遍历,又叫宽度优先搜索或横向优先搜索,是从根结点开始沿着树的宽度搜索遍历,将离根节点最近的节点先遍历出来,在继续深挖下去。
代码如下:
void BFS(const V& src)
{
size_t srci = GetVertexIndex(src);
// 队列和标记数组
queue<int> q;
vector<bool> visited(_vertexs.size(), false);
q.push(srci);
visited[srci] = true;
int levelSize = 1;
size_t n = _vertexs.size();
while (!q.empty())
{
// 一层一层出
for (int i = 0; i < levelSize; ++i)
{
int front = q.front();//出队头数据
q.pop();
cout << front << ":" << _vertexs[front] << " ";
// 把front顶点的邻接顶点入队列
for (size_t i = 0; i < n; ++i)
{
if (_matrix[front][i] != MAX_W)//不是MAX_W就是相连的顶点
{
if (visited[i] == false)
{
q.push(i);//入队列
visited[i] = true;//表示这个顶点访问过了
}
}
}
}
cout << endl;
levelSize = q.size();
}
cout << endl;
}
kruskal(克鲁斯卡尔算法)
Kruskal算法是一种贪心算法,我们将图中的每个edge按照权值大小进行排序,每次从边集中取出权值最小且两个顶点都不在同一个集合的边加入生成树中!注意:如果这两个顶点都在同一集合内,说明已经通过其他边相连,因此如果将这个边添加到生成树中,那么就会形成环!这样反复做,直到所有的节点都连接成功。如何判断添加这条边会不会形成环,我们可以用到并查集。
特点:
1.只能使用图中权值最小的边来构成最小生成树
2.只能使用恰好n-1条边来连接图中的n个顶点
3.选用的n-1条边不能构成回路
代码如下:
W Kruskal(Self& minTree)
{
size_t n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (size_t i = 0; i < n; ++i)
{
minTree._matrix[i].resize(n, MAX_W);
}
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (i < j && _matrix[i][j] != MAX_W)
{
minque.push(Edge(i, j, _matrix[i][j]));
}
}
}
// 选出n-1条边
int size = 0;
W totalW = W();
UnionFindSet ufs(n);
while (!minque.empty())
{
Edge min = minque.top();
minque.pop();
if (!ufs.InSet(min._srci, min._dsti))
{
cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
minTree._AddEdge(min._srci, min._dsti, min._w);
ufs.Union(min._srci, min._dsti);
++size;
totalW += min._w;
}
else
{
cout << "构成环:";
cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
}
if (size == n - 1)
{
return totalW;
}
else
{
return W();
}
}
Prim(普里姆算法)
Prim算法是另一种贪心算法,和Kuskral算法的贪心策略不同,Kuskral算法主要对边进行操作,而Prim算法则是对节点进行操作,每次遍历添加一个点,这时候我们就不需要使用并查集了。
代码如下:
W Prim(Self& minTree, const W& src)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (size_t i = 0; i < n; ++i)
{
minTree._matrix[i].resize(n, MAX_W);
}
vector<bool> X(n, false);
vector<bool> Y(n, true);
X[srci] = true;
Y[srci] = false;
// 从X->Y集合中连接的边里面选出最小的边
priority_queue<Edge, vector<Edge>, greater<Edge>> minq;
// 先把srci连接的边添加到队列中
for (size_t i = 0; i < n; ++i)
{
if (_matrix[srci][i] != MAX_W)
{
minq.push(Edge(srci, i, _matrix[srci][i]));
}
}
cout << "Prim开始选边" << endl;
size_t size = 0;
W totalW = W();
while (!minq.empty())
{
Edge min = minq.top();
minq.pop();
// 最小边的目标点也在X集合,则构成环
if (X[min._dsti])
{
//cout << "构成环:";
//cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
else
{
minTree._AddEdge(min._srci, min._dsti, min._w);
//cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
X[min._dsti]= true;
Y[min._dsti] = false;
++size;
totalW += min._w;
if (size == n - 1)
break;
for (size_t i = 0; i < n; ++i)
{
if (_matrix[min._dsti][i] != MAX_W && Y[i])
{
minq.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
if (size == n - 1)
{
return totalW;
}
else
{
return W();
}
}
总结这两种算法:
构成最小生成树的方法:Kruskal算法和Prim算法。这两个算法都采用了逐步求解的贪心策略。Kruksal算法是对边进行操作,先取出边,然后判断边的两个节点,这样的话,如果一个图结构非常的稠密,那么Kruksal算法就比较慢了,而Prim算法只是对节点进行遍历,并使用visited进行标记,因此会相对于Kruksal算法,在稠密图方面好很多,因此Kruksal算法常用于稀疏图,而Prim算法常用于稠密图!
Dijkstra(迪杰斯特拉算法)
迪杰斯特拉算法是由荷兰计算机科学家狄克斯特拉于1959年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有向图中最短路径问题,同时算法要求图中所以边的权重非负。迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。
代码如下:
void Dijkstra(const V& src, vector<W>& dist, vector<int>& pPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = 0;
pPath[srci] = srci;
// 已经确定最短路径的顶点集合
vector<bool> S(n, false);
for (size_t j = 0; j < n; ++j)
{
// 选最短路径顶点且不在S更新其他路径
int u = 0;
W min = MAX_W;
for (size_t i = 0; i < n; ++i)
{
if (S[i] == false && dist[i] < min)
{
u = i;
min = dist[i];
}
}
S[u] = true;
// 松弛更新u连接顶点v srci->u + u->v < srci->v 更新
for (size_t v = 0; v < n; ++v)
{
if (S[v] == false && _matrix[u][v] != MAX_W
&& dist[u] + _matrix[u][v] < dist[v])
{
dist[v] = dist[u] + _matrix[u][v];
pPath[v] = u;
}
}
}
}
Bellman-ford(贝尔曼-福特算法)
美国应用数学家Richard Bellman (理查德.贝尔曼)于1958 年发表了该算法。此外Lester Ford在1956年也发表了该算法。因此这个算法叫做Bellman-Ford算法。其实EdwardF. Moore在1957年也发表了同样的算法,所以这个算法也称为Bellman-Ford-Moore算法。Bellman-ford 算法比dijkstra算法更具普遍性,因为它对边没有要求,可以处理负权边与负权回路的问题。缺点是时间复杂度过高,高达O(VE), V为顶点数,E为边数。
代码如下:
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& pPath)
{
size_t n = _vertexs.size();
size_t srci = GetVertexIndex(src);
// vector dist,记录srci-其他顶点最短路径权值数组
dist.resize(n, MAX_W);
// vector pPath 记录srci-其他顶点最短路径父顶点数组
pPath.resize(n, -1);
// 先更新srci->srci为缺省值
dist[srci] = W();
//cout << "更新边:i->j" << endl;
// 总体最多更新n轮
for (size_t k = 0; k < n; ++k)
{
// i->j 更新松弛
bool update = false;
cout << "更新第:" << k << "轮" << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// srci -> i + i ->j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
update = true;
cout << _vertexs[i] << "->" << _vertexs[j] << ":" << _matrix[i][j] << endl;
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
}
}
}
// 如果这个轮次中没有更新出更短路径,那么后续轮次就不需要再走了
if (update == false)
{
break;
}
}
// 还能更新就是带负权回路
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// srci -> i + i ->j
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
return false;
}
}
}
return true;
}
flyod-warshall(佛洛伊德算法)
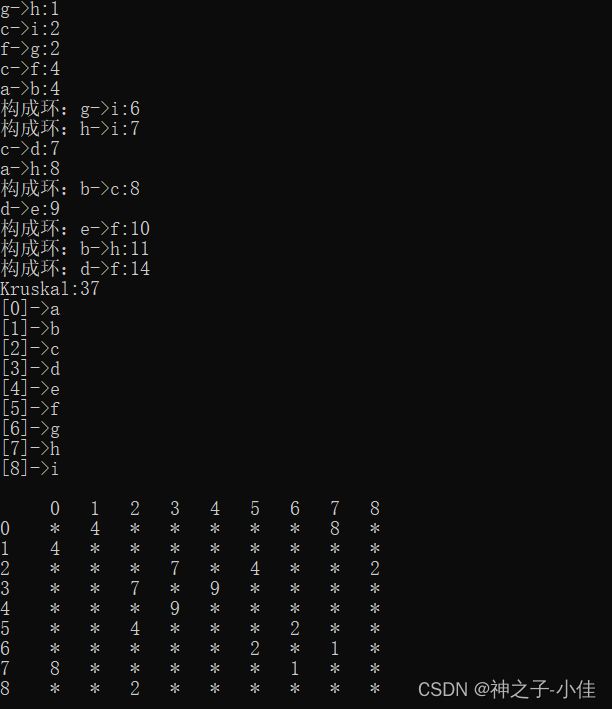
Floyd-Warshall算法是有Floyd于1962年提出,其可以计算有向图中任意两点之间的最短路径,此算法利用动态规划的思想将计算的时间复杂度降低为 。其核心思想是,最短路路径的本质就是比较在两个顶点之间中转点,比较经过与不经过中转点的距离哪个更短。类似Bellman-Ford算法,我们将此操作也称为松弛。
代码如下:
void FloydWarshall(vector<vector<W>>& vvDist, vector<vector<int>>& vvpPath)
{
size_t n = _vertexs.size();
vvDist.resize(n);
vvpPath.resize(n);
// 初始化权值和路径矩阵
for (size_t i = 0; i < n; ++i)
{
vvDist[i].resize(n, MAX_W);
vvpPath[i].resize(n, -1);
}
// 直接相连的边更新一下
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (_matrix[i][j] != MAX_W)
{
vvDist[i][j] = _matrix[i][j];
vvpPath[i][j] = i;
}
if (i == j)
{
vvDist[i][j] = W();
}
}
}
// abcdef a {} f || b {} c
// 最短路径的更新i-> {其他顶点} ->j
for (size_t k = 0; k < n; ++k)
{
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// k 作为的中间点尝试去更新i->j的路径
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W
&& vvDist[i][k] + vvDist[k][j] < vvDist[i][j])
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
// 找跟j相连的上一个邻接顶点
// 如果k->j 直接相连,上一个点就k,vvpPath[k][j]存就是k
// 如果k->j 没有直接相连,k->...->x->j,vvpPath[k][j]存就是x
vvpPath[i][j] = vvpPath[k][j];
}
}
}
// 打印权值和路径矩阵观察数据
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (vvDist[i][j] == MAX_W)
{
//cout << "*" << " ";
printf("%3c", '*');
}
else
{
//cout << vvDist[i][j] << " ";
printf("%3d", vvDist[i][j]);
}
}
cout << endl;
}
cout << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
//cout << vvParentPath[i][j] << " ";
printf("%3d", vvpPath[i][j]);
}
cout << endl;
}
}
}