初识HTML超文本标记语言
文章目录
- 前端简介
-
- 引入
- 前端三剑客
- 什么是HTML?
- 超文本传输协议前戏
- HTTP超文本传输协议
-
- 1.什么是HTTP协议
- 2.四大特性
- 3.数据格式
- 4.响应状态码
- 基于HTTP协议搭建HTML
- HTML简介
- HTML文档结构
-
- head常见标签
-
- 1.meta 定义网页源信息(很多配置)
- 2.style内部支持编写CSS代码
- 3.link引入外部CSS文件
- 3.script支持内部编写js代码也可以引入外部js文件
- body内常见标签
前端简介
引入
前端:与用户直接打交道的操作界面都可以称之为前端(那些炫酷的页面)
后端:不直接与用户打交道的,内部真正执行核心业务逻辑的代码(各种编程语言写的代码:Python、Java、Go)
前端三剑客
1.HTML 网页的骨架(没有样式很难看)
2.CSS 网页的样式(给骨架美化)
3.JavaScript 网页的动态(丰富用户体验)
'''
还有一些前端配套的框架(库)
bootstrap、jQuery、vue、react、angular.js
'''
什么是HTML?
1.超文本标记语言(Hypertext MarKup Language,HTML)是一种用于创建网页的标记语言
2.本质上是浏览器可识别的规则,我们按照规则写网页,浏览器根据规则渲染我们的网页。
对于不同的浏览器,对同一个标签可能会有不同的解释(兼容性问题)
3.网页文件的扩展名:.html或.htm
注意:HTML是一种标记语言(markup language),他不是一种编程语言。HTML使用标签来描述网页。
超文本传输协议前戏
1.编写前端的步骤
- 编写一个服务端
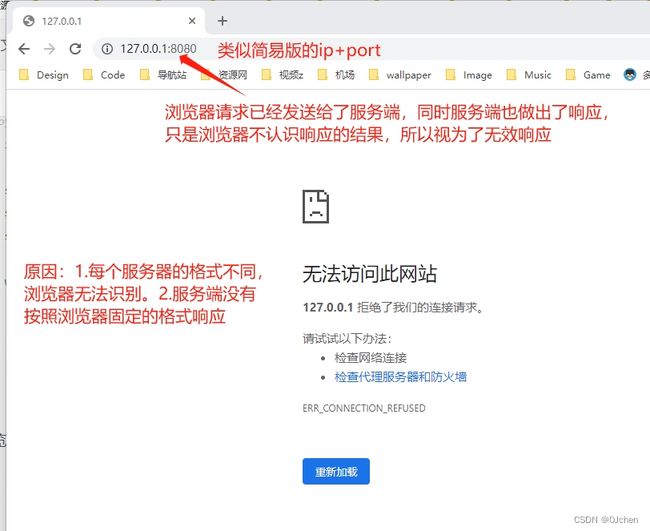
- 使用浏览器充当客户端访问服务端(BS架构)
- 浏览器端无法直接展示服务端的响应数据(因为服务端的数据没有遵循标准)
- 由于浏览器需要兼容很多服务端软件,为了实现无障碍沟通交流,产生协议(HTTP协议、FTP协议、HTTPS协议)
- 浏览器发送的请求数据格式肯定是没有问题,因为别人早就封装好了,问题出现在我们自己写的服务端响应式数据格式
2.前端BS架构
我们在编写TCP服务端的时候,针对客户端的选择可以是自己写的客户端代码,也可以是浏览器充当的客户端(B/S本质也是C/S架构)
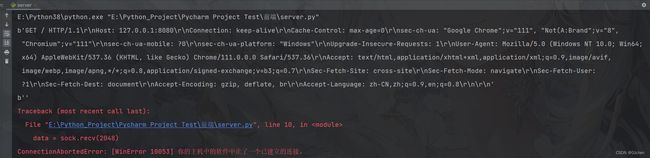
编写服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
sock,addr = server.accept()
while True:
data = sock.recv(2048)
print(data)
sock.send(b"hello world")
浏览器访问结果
解决方法
由于浏览器需要兼容很多服务端软件 为了实现无障沟通交流 产生协议(HTTP协议、FTP协议、HTTPS协议)
浏览器发送的请求数据格式肯定是没有问题 因为别人早就封装好了 问题出现在我们自己写的服务端响应数据格式
继续往下看完HTTP协议就知道怎么做了
HTTP超文本传输协议
1.什么是HTTP协议
HTTP协议(Hypertext Transfer Protocol,超文本传输协议)是用于从www服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少,我们在浏览器的地址栏里输入的网站地址叫做URL(UniformResourceLocator,统一资源定位符)。
2.四大特性
1.基于请求响应
客户端发送请求,服务端回应响应。服务端永远不会主动给客户端发消息,
如果想让服务端主动给客户端发送消息可以采用其他网络协议。
2.基于TCP/IP作用于应用层的协议
3.无状态
服务端不会保存客户端的状态(不保存客户端的状态信息)
就是这个协议它不能够在浏览器中保存数据,现在使用的:淘宝、支付宝、京东等这些网站都需要登录
(cookie、session、token、jwt等保存的,他们才是真正的保存用户数据的)
4.无/短连接
客户端与服务端不会长久保持连接(两者请求响应之后立马断绝关系)
3.数据格式
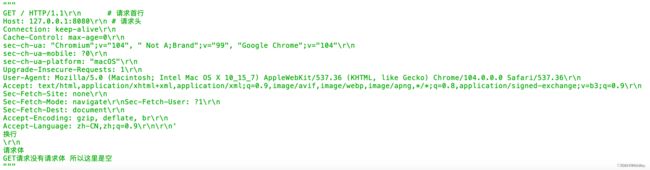
请求数据格式
1> 请求首行(请求方式:有很多种 协议名称及版本)
2> 请求头(一堆K:V键值对)
3> 换行
4> 请求体(携带一些敏感的数据 不是所有的请求都有请求体)
响应数据格式
1> 响应首行(响应状态码)
2> 响应头(一堆K:V键值对)
3> 换行
4> 响应体(一般情况下就是浏览器要展示给用户看的数据)
4.响应状态码
利用数字来展示一些复杂的描述性信息
1XX:服务端已经接收到你的请求正在处理,你可以继续提交或者等待
2XX:200 OK服务端给出了相应响应
3XX:重定向
4XX:404 Not Found请求资源不存在(绝大多数时候都是遇到的这种情况) 403请求不符合条件
5XX:服务端内部错误(出现网页打不开的情况)
我们在公司中还会自定义更多的状态码,一般情况下从10000开始
'''
公司还会自定义状态码 一般以10000开头
参考: 聚合数据 APL
作用:
后端写给前端的状态码
'''
详细分解
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
代码 说明
100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
表示成功处理了请求的状态代码。
代码 说明
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
代码 说明
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
代码 说明
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足”期望”请求标头字段的要求。
5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
代码 说明
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
基于HTTP协议搭建HTML
import socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
sock,addr = server.accept()
while True:
data = sock.recv(2048)
print(data)
'遵循HTTP响应格式'
sock.send(b'HTTP/1.1 200 OK \r\n\r\n')
'格式化字体'
sock.send(b'hello world
')
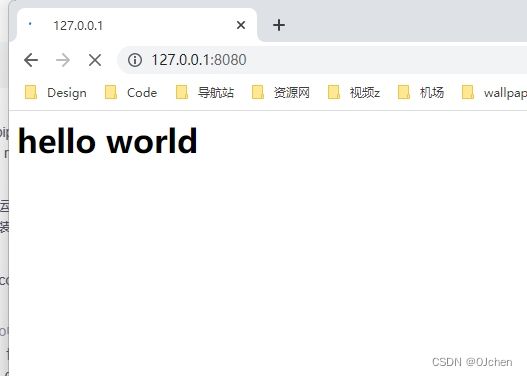
代码实现的过程:浏览器发送请求>>HTTP协议>>服务端接收请求>>服务端返回响应>>服务端把HTML文件内容发送给浏览器>>浏览器渲染页面
HTML简介
HTML简称超文本标记语言,是所有的浏览器展示页面必备
浏览器展示的界面我们也称做HTML页面,存储HTML语言的文件一般都是.html
HTML语法注释
'单行注释'
<! -- 注释内容 -->
'多行注释'
<!--
注释
内容
-->
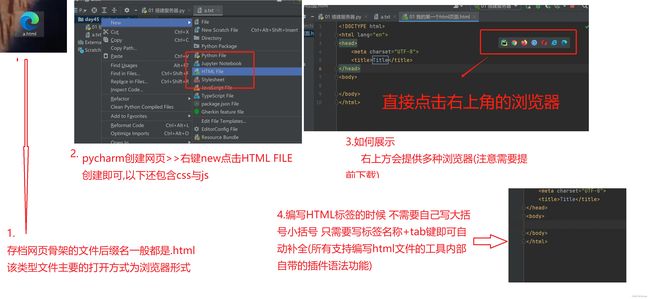
HTML文件结构
<html> 所有的代码都必须卸载html标签内部
<head> head内的数据一般都不是给用户看的
<meta charset='utf-8'> 字符编码
<title></title> 网页标题,在浏览器标题栏显示
</head>
<body></body> body内的数据就是浏览器展示给用户看的
</html>
HTML标签分类
单标签(自闭和标签)
<img />
双标签(有开始有结束) 有头有尾
<a></a>
<!DOCTYPE html> # 文挡声明 HTML
<html lang='en'> # 语言默认英文ENGLISH
<head> # head内的数据一般都不是给用户看的
<title>title</title> # 网页标题
<meta charset='utf-8'/> # 字符编码
</head>
<body></body> # body内的数据就是浏览器展示给用户看的
</html>
HTML文档结构
head常见标签
| 标签 | 意义 |
|---|---|
| title | 定义网页标题 |
| style | 定义内部样式表 |
| script | 定义JS代码或引入外部JS文件 |
| link | 引入外部样式表文件或网站图标 |
| meta | 定义网页源信息 |
1.meta 定义网页源信息(很多配置)
meta 定义网页源信息
主要用于描述网页,与之对应的属性值为content,content中的内容主要便于搜索引擎机器人查找信息和分类信息用
eg:
<meta name="keywords" content="查询关键字" >
<meta name="description" content="网页简介">
补充知识
1.指定该网址2秒后跳转到指定网页
<meta http-equiv="refresh" content="2;URL=https://www.baidu.com">
2.keywords 关键字搜索
<meta name="keywrods" content="旋转,跳跃,rap">
3.description 网页描述信息(简介)
<meta name="desciption" content="强盛集团">
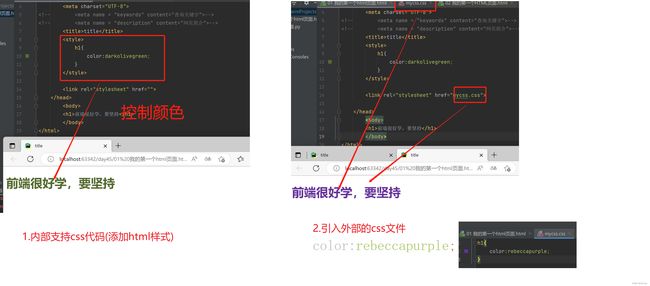
2.style内部支持编写CSS代码
<style>
h1 {
color: red;
}
</style>
3.link引入外部CSS文件
<link rel="stylesheet" href="mycss.css">
3.script支持内部编写js代码也可以引入外部js文件
1.内部写js代码
<script>
prompt('好好活着','不要浪费生命')</script>
2.引入外部js文件
<script src="myjs.js"></script>
ps:了解每个标签大致的作用即可
body内常见标签
| 标签 | 意义 |
|---|---|
| h1-h6 | 标题标签 |
| p | 段落标签 |
| u | 下划线 |
| i | 斜体 |
| s | 删除线 |
| b | 加粗 |
| br | 换行 |
| hr | 分割线 |
注意:有很多样式,可能存在多中标签可以实现
<style>
h1{
color:red;
}
u,i,s,b{
color: blue;
}
</style>
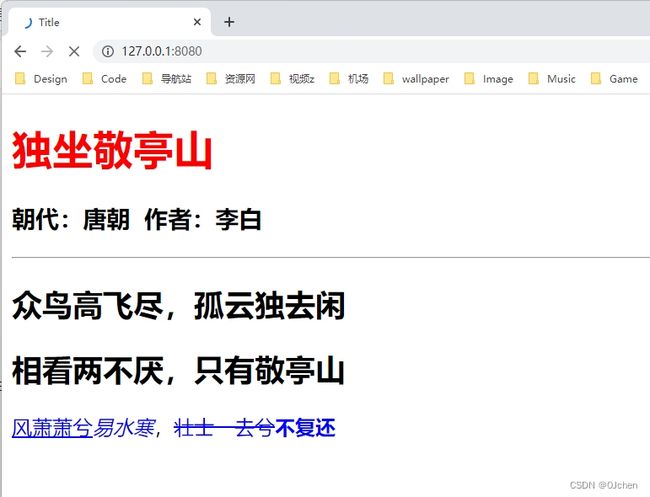
<body>
<h1>独坐敬亭山</h1>
<h3>朝代:唐朝 作者:李白</h3>
<hr>
<h2>众鸟高飞尽,孤云独去闲</h2>
<h2>相看两不厌,只有敬亭山</h2>
<! --下划线(u)、斜体(i)、删除线(s)、粗体(b) -- >
<u>风萧萧兮</u><i>易水寒</i>,<s>壮士一去兮</s><b>不复还</b>
</body>