k8s 结合 Prometheus 构建企业级监控告警系统

什么是 Prometheus?
- Prometheus 是一个开源的系统监控和报警系统,现在已经加入到 CNCF 基金会,成为继 k8s 之后第二个在 CNCF 托管的项目,在 kubernetes 容器管理系统中,通常会搭配 prometheus 进行监控,同时也支持多种 exporter 采集数据,还支持 pushgateway 进行数据上报,Prometheus 性能足够支撑上万台规模的集群。
prometheus 特点
- 1.多维度数据模型
每一个时间序列数据都由 metric 度量指标名称和它的标签 labels 键值对集合唯一确定:这个 metric 度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收 http 请求的总计数)。labels 开启了 Prometheus 的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks 的 http 请求,打上method=POST 的标签,则形成了具体的 http 请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
2.灵活的查询语言(PromQL)可以对采集的 metrics 指标进行加法,乘法,连接等操作;
3.可以直接在本地部署,不依赖其他分布式存储;
4.通过基于 HTTP 的 pull 方式采集时序数据;
5.可以通过中间网关 pushgateway 的方式把时间序列数据推送到 prometheus server 端;
6.可通过服务发现或者静态配置来发现目标服务对象(targets)。
7.有多种可视化图像界面,如 Grafana 等。
8.高效的存储,每个采样数据占 3.5 bytes 左右,300 万的时间序列,30s 间隔,保留 60 天,消耗磁盘大概 200G。
9.做高可用,可以对数据做异地备份,联邦集群,部署多套 prometheus,pushgateway 上报数据prometheus 组件
从上图可发现,Prometheus 整个生态圈组成主要包括 prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui 界面,
Prometheus server 由三个部分组成
Retrieval,Storage,PromQL
1.Retrieval 负责在活跃的 target 主机上抓取监控指标数据
2.Storage 存储主要是把采集到的数据存储到磁盘中
3.PromQL 是 Prometheus 提供的查询语言模块。
1.Prometheus Server: 用于收集和存储时间序列数据。
2.Client Library: 客户端库,检测应用程序代码,当 Prometheus 抓取实例的 HTTP 端点时,客户端库会将所有跟踪的 metrics 指标的当前状态发送到 prometheus server 端。
3.Exporters: prometheus 支持多种 exporter,通过 exporter 可以采集 metrics 数据,然后发送到prometheus server 端,所有向 promtheus server 提供监控数据的程序都可以被称为 exporter
4.Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack 等。
5.Grafana:监控仪表盘,可视化监控数据
6.pushgateway: 各个目标主机可上报数据到 pushgatewy,然后 prometheus server 统一从 pushgateway 拉取数据。

prometheus 几种部署模式
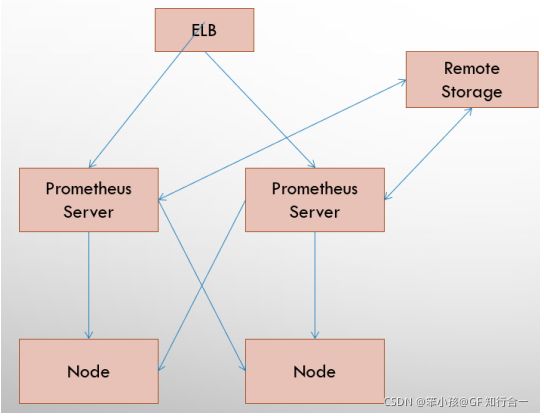
- 基本 HA 模式
基本的 HA 模式只能确保 Promthues 服务的可用性问题,但是不解决 Prometheus Server 之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server 也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
基本 HA + 远程存储方案在解决了 Promthues 服务可用性的基础上,同时确保了数据的持久化,当 Promthues Server 发生宕机或者数据丢失的情况下,可以快速的恢复。 同时 Promthues Server 可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保 Promthues Server 的可迁移性的场景。
基本 HA + 远程存储 + 联邦集群方案Promthues 的性能瓶颈主要在于大量的采集任务,因此用户需要利用 Prometheus 联邦集群的特性,将不同类型的采集任务划分到不同的 Promthues 子服务中,从而实现功能分区。例如一个Promthues Server 负责采集基础设施相关的监控指标,另外一个 Prometheus Server 负责采集应用监控指标。再有上层 Prometheus Server 实现对数据的汇聚。
prometheus 工作流程
1. Prometheus server 可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态 job 或者服务发现的方式被 prometheus server 采集到,这种方式默认的pull 方式拉取指标;也可通过 pushgateway 把采集的数据上报到 prometheus server 中;还可通过一些组件自带的 exporter 采集相应组件的数据;
2.Prometheus server 把采集到的监控指标数据保存到本地磁盘或者数据库;
3.Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
4.Alertmanager 通过配置报警接收方,发送报警到邮件,微信或者钉钉等
5.Prometheus 自带的 web ui 界面提供 PromQL 查询语言,可查询监控数据
6.Grafana 可接入 prometheus 数据源,把监控数据以图形化形式展示出prometheus 如何更好的监控 k8s?
- 对于 Kubernetes 而言,可以把当中所有的资源分为几类:
1、基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
2、容器基础设施(Container):为应用提供运行时环境
3、用户应用(Pod):Pod 中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
4、内部服务负载均衡(Service):在集群内,通过 Service 在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
5、外部访问入口(Ingress):通过 Ingress 提供集群外的访问入口,从而可以使外部客户端能够访问到部署在 Kubernetes 集群内的服务
因此,在不考虑 Kubernetes 自身组件的情况下,如果要构建一个完整的监控体系,我们应该考虑,以下 5 个方面:
1)、集群节点状态监控:从集群中各节点的 kubelet 服务获取节点的基本运行状态;
2)、集群节点资源用量监控:通过 Daemonset 的形式在集群中各个节点部署 NodeExporter 采集节点的资源使用情况;
3)、节点中运行的容器监控:通过各个节点中 kubelet 内置的 cAdvisor 中获取个节点中所有容器的运行状态和资源使用情况;
4)、从黑盒监控的角度在集群中部署 Blackbox Exporter 探针服务,检测 Service 和 Ingress 的可用性;
5)、如果在集群中部署的应用程序本身内置了对 Prometheus 的监控支持,那么我们还应该找到相应的 Pod 实例,并从该 Pod 实例中获取其内部运行状态的监控指标。



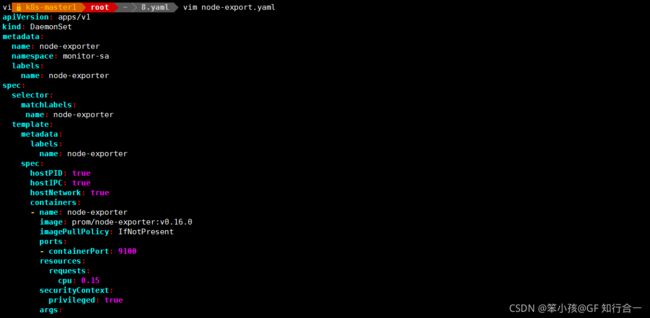
安装采集节点资源指标组件 node-exporter
node-exporter 是什么?
采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括 CPU, 内存,磁盘,网络,文件数等信息。安装 node-exporter 组件,在 k8s 集群的控制节点操作
# kubectl create ns monitor-sa
# vim node-export.yaml

-
通过 node-exporter 采集数据
curl http://主机 ip:9100/metrics
#node-export 默认的监听端口是 9100,可以看到当前主机获取到的所有监控数据
curl http://192.168.2.30:9100/metrics | grep node_cpu_seconds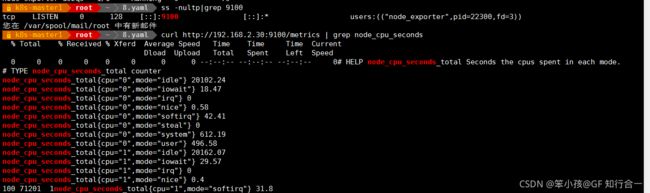
#HELP:解释当前指标的含义,上面表示在每种模式下 node 节点的 cpu 花费的时间,以 s 为单位
#TYPE:说明当前指标的数据类型,上面是 counter 类型
node_cpu_seconds_total{cpu="0",mode="idle"} :
cpu0 上 idle 进程占用 CPU 的总时间,CPU 占用时间是一个只增不减的度量指标,从类型中也可以看出 node_cpu 的数据类型是 counter(计数器)
counter 计数器:只是采集递增的指标
curl http://192.168.2.30:9100/metrics | grep node_load
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.13
node_load1 该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此 node_load1 反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为 gauge(标准尺寸)
gauge 标准尺寸:统计的指标可增加可减少
node-exporter 官方网站:
https://prometheus.io/docs/guides/node-exporter/
node-exporter 的 github 地址:
https://github.com/prometheus/node_exporter/
在 k8s 集群中安装 Prometheus server 服务
- 创建 sa 账号
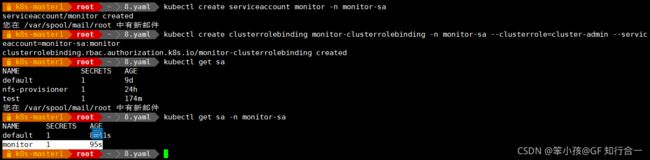
#在 k8s 集群的控制节点操作,创建一个 sa 账号
# kubectl create serviceaccount monitor -n monitor-sa
#把 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
# kubectl create clusterrolebinding monitor-clusterrole-binding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
#注意:有时候执行上面授权会报错,那就需要下面的授权命令:
# kubectl create clusterrolebinding monitor-clusterrole-binding-1 -n monitor-sa --clusterrole=cluster-admin --user=system:serviceaccount:monitor:monitorsa
创建数据目录
#在 k8s-02 节点创建存储数据的目录:
mkdir /data -p
chmod 777 /data/
安装 prometheus 服务
以下步骤均在 k8s 集群的控制节点操作:
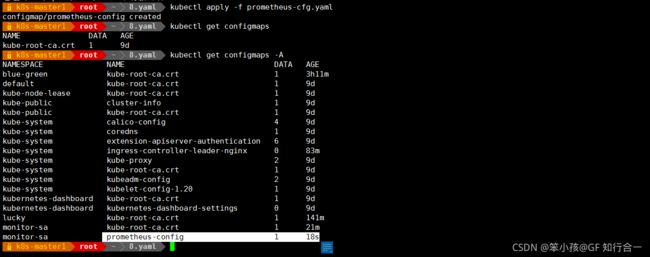
创建一个 configmap 存储卷,用来存放 prometheus 配置信息
vim prometheus-cfg.yaml
global:
scrape_interval: 15s #采集目标主机监控据的时间间隔
scrape_timeout: 10s # 数据采集超时时间,默认 10s
evaluation_interval: 1m #触发告警检测的时间,默认是 1m
scrape_configs:
#scrape_configs:配置数据源,称为 target,每个 target 用 job_name 命名。又分为静态配置和服务发现
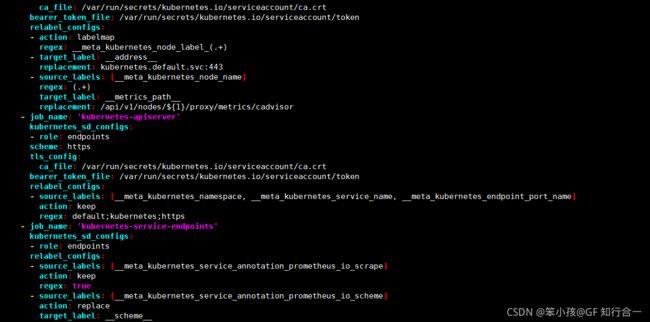
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
#使用的是 k8s 的服务发现
- role: node
# 使用 node 角色,它使用默认的 kubelet 提供的 http 端口来发现集群中每个 node 节点。
relabel_configs:
#重新标记标签
- source_labels: [__address__] #配置的原始标签,匹配地址
regex: '(.*):10250' #匹配带有 10250 端口的 url: ip:10250
replacement: '${1}:9100' #把匹配到的 ip:10250 的 ip 保留替换成${1}
target_label: __address__ #新生成的 url 是${1}获取到的 ip:9100
action: replace #替换
- action: labelmap #匹配到下面正则表达式的标签会被保留
regex: __meta_kubernetes_node_label_(.+)
Prometheus 配置参考:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Prometheus 基于 k8s 服务发现参考:
https://github.com/prometheus/prometheus/blob/release2.31/documentation/examples/prometheus-kubernetes.yml
通过 deployment 部署 prometheus
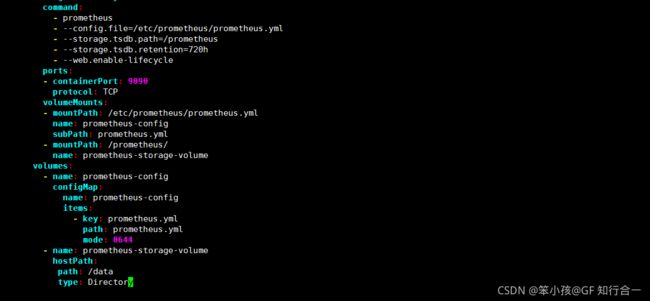
- vim prometheus-deploy.yaml
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus #旧数据存储目录
- --storage.tsdb.retention=720h #何时删除旧数据,默认为 15 天。
- --web.enable-lifecycle #开启热加载
注意:在上面的 prometheus-deploy.yaml 文件有个 nodeName 字段,这个就是用来指定创建的这个 prometheus 的 pod 调度到哪个节点上,我们这里让 nodeName=k8s-02,也即是让 pod 调度到 k8s-02 节点上,因为 k8s-02 节点我们创建了数据目录/data,所以大家记住:你在 k8s 集群的哪个节点创建/data,就让 pod 调度到哪个节点创建 service
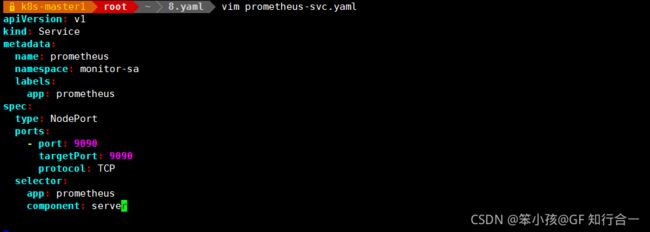
vim prometheus-svc.yaml
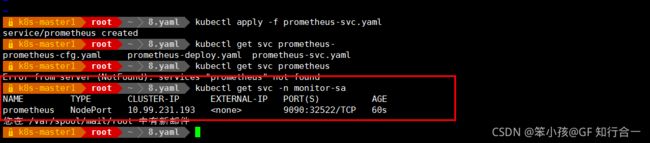
通过上面可以看到 service 在宿主机上映射的端口是 32522,这样我们访问 k8s 集群的控制节点的 ip:32522,就可以访问到 prometheus 的 web ui 界面了
- 访问 prometheus web ui 界面
- http://192.168.2.30:32522/
热加载:
curl -X POST http://10.244.121.4:9090/-/reload





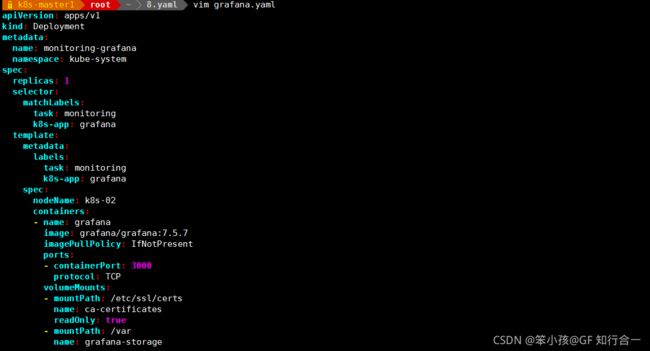
安装和配置可视化 UI 界面 Grafana
在k8s 的各个控制节点和 k8s 的各个工作节点都作如下操作
mkdir /var/lib/grafana/ -p &&chmod 777 /var/lib/grafana/vim grafana.yaml
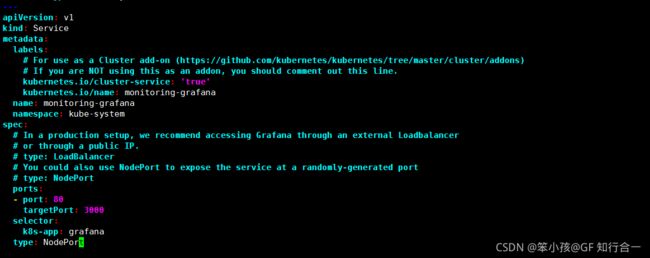
#查看 grafana 前端的 service
# kubectl get svc -n kube-system | grep grafana#登陆 grafana,在浏览器访问
http://192.168.2.30:30495/配置 grafana 界面
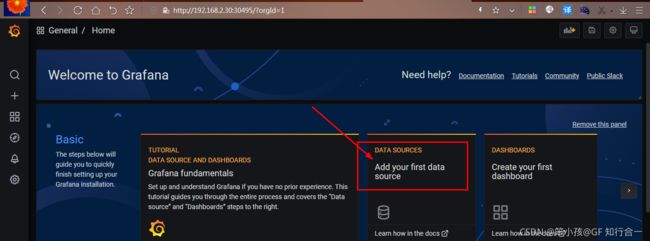
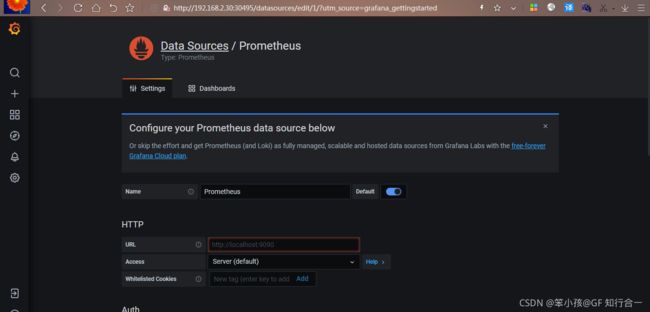
- 开始配置 grafana 的 web 界面:
选择 Add your first data source选择 Prometheus,出现如下:
Name: Prometheus
HTTP 处的 URL 如下:
http://prometheus.monitor-sa.svc:9090
配置好的整体页面如下:
点击左下角 Save & Test,出现如下 Data source is working,说明 prometheus 数据源成功的被 grafana 接入了
导入监控模板,可在如下链接搜索
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes可直接导入 node_exporter.json 监控模板,这个可以把 node 节点指标显示出来也可直接导入 docker_rev1.json,这个可以把容器资源指标显示出来
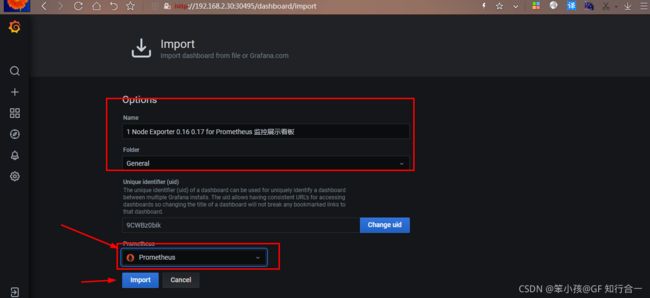
- 怎么导入监控模板,按如下步骤
上面 Save & Test 测试没问题之后,就可以返回 Grafana 主页面
点击左侧+号下面的 Import选择一个本地的 json 文件,我们选择的是上面让大家下载的 node_exporter.json 这个文件,选择之后出现如下:
注: Name 下面的名字是 node_exporter.json 定义的
Prometheus 后面需要变成 Prometheus,然后再点击 Import,就可以出现如下界面:
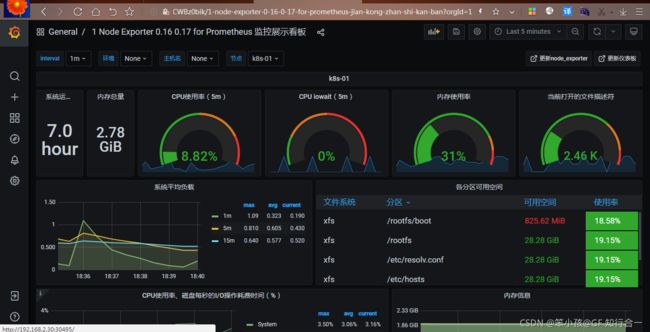
导入 docker_rev1.json 监控模板,步骤和上面导入 node_exporter.json 步骤一样,导入之后显示如下:
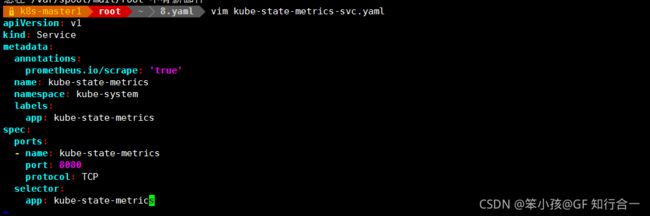
kube-state-metrics 组件解读
- 什么是 kube-state-metrics?
- kube-state-metrics 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod,需要注意的是 kube-state-metrics 只是简单的提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等;调度了多少个 replicas?现在可用的有几个?多少个Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?我有多少 job 在运行中。
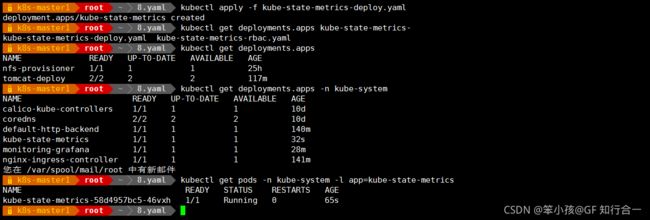
安装和配置 kube-state-metrics
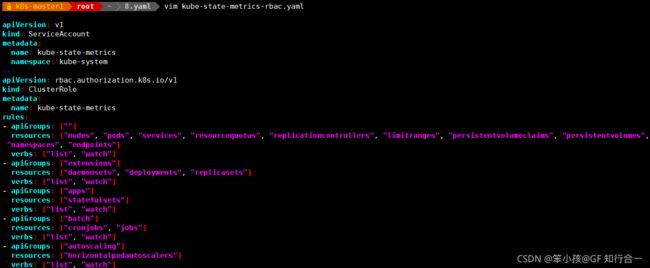
- 创建 sa,并对 sa 授权
# vim kube-state-metrics-rbac.yaml
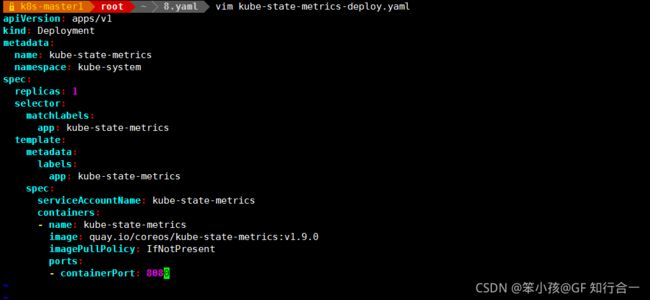
vim kube-state-metrics-deploy.yaml
创建 service
vim kube-state-metrics-svc.yaml
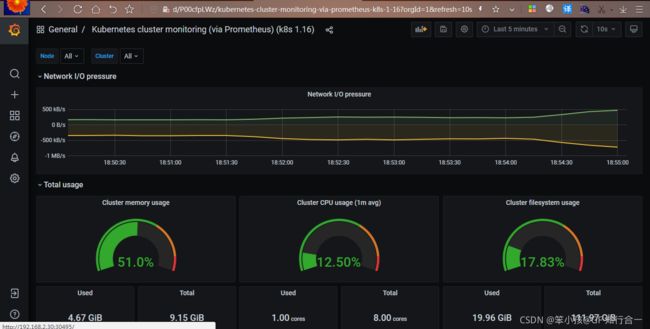
在 grafana web 界面导入 Kubernetes Cluster (Prometheus)-1577674936972.json 和Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
安装和配置 Alertmanager-发送报警到邮箱
vim alertmanager-cm.yaml
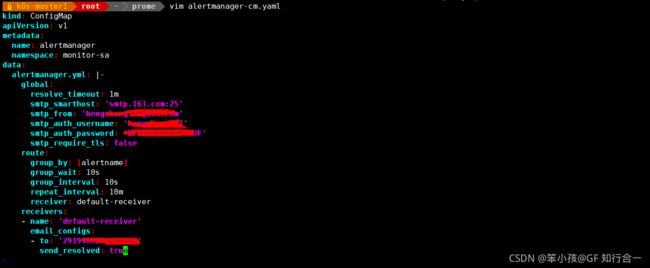
route: #用于配置告警分发策略
group_by: [alertname] # 采用哪个标签来作为分组依据
group_wait: 10s # 组告警等待时间。也就是告警产生后等待 10s,如果有同组告警一起发出
group_interval: 10s # 两组告警的间隔时间
repeat_interval: 10m # 重复告警的间隔时间,减少相同邮件的发送频率
receiver: default-receiver # 设置默认接收人
receivers:
- name: 'default-receiver'
email_configs:
- to: ''
send_resolved: true
alertmanager 配置文件解释说明:
smtp_smarthost: 'smtp.163.com:25'
#用于发送邮件的邮箱的 SMTP 服务器地址+端口
smtp_from: '#这是指定从哪个邮箱发送报警
smtp_auth_username: ''#这是发送邮箱的认证用户,不是邮箱名
smtp_auth_password: ''#这是发送邮箱的授权码而不是登录密码
email_configs:
- to: ''
#to 后面指定发送到哪个邮箱,不应该跟smtp_from 的邮箱名字重复
创建报警配置
vim prometheus-alertmanager-cfg.yaml
注意:配置文件解释说明
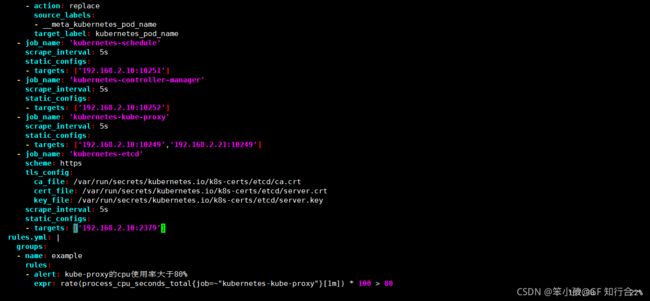
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.30:10251'] #控制节点的 ip:schedule 端口
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.30:10252'] #控制 节点的 ip:controller-manager 端口
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.30:10249','192.168.2.41:10249']#控制 和 k8s-02节点的 ip:kube-proxy 端口
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.30:2379']#控制节点的 ip:etcd 端口
kubectl delete -f prometheus-cfg.yaml
kubectl apply -f prometheus-alertmanager-cfg.yaml
安装 prometheus 和 alertmanager
vim prometheus-alertmanager-deploy.yaml
注意:
配置文件指定了 nodeName: k8s-02
生成一个 etcd-certs,这个在部署 prometheus 需要
# kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-alertmanager-deploy.yaml
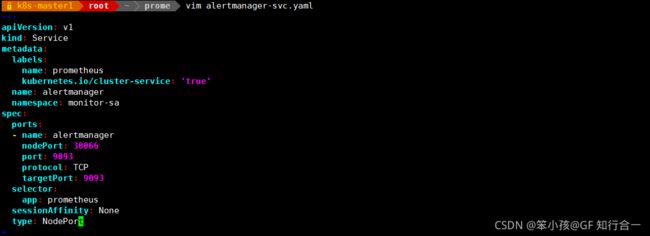
vim alertmanager-svc.yaml
注意:上面可以看到 prometheus 的 service 暴漏的端口是 32522,alertmanager 的 service 暴露的端口是 30066
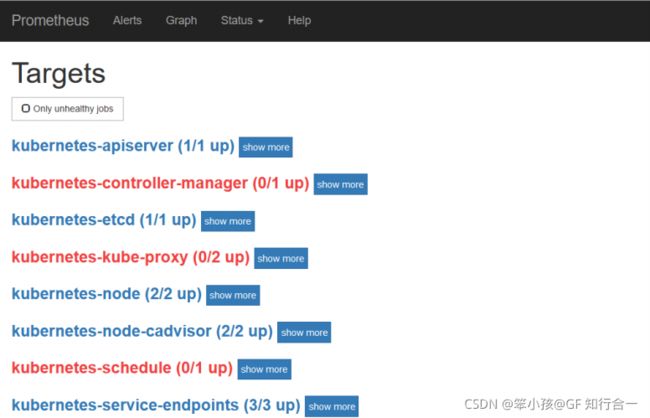
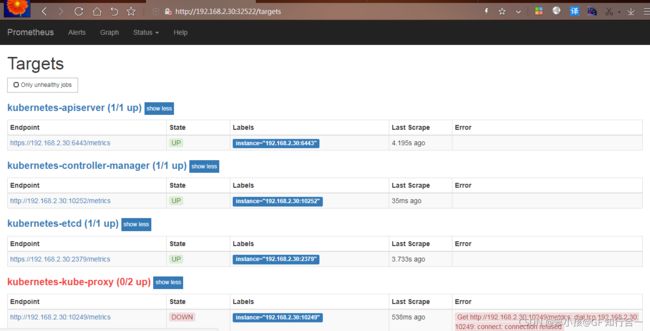
访问 prometheus 的 web 界面
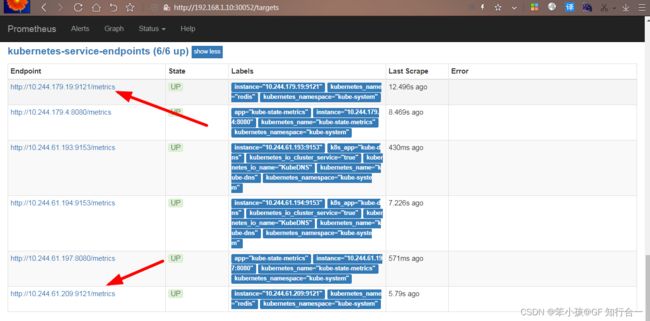
点击 status->targets,可看到如下
可按如下方法处理;
vim /etc/kubernetes/manifests/kube-scheduler.yaml
修改如下内容:
把--bind-address=127.0.0.1 变成--bind-address=192.168.2.30
把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.2.30
把—port=0 删除
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
把--bind-address=127.0.0.1 变成--bind-address=192.168.2.30
把 httpGet:字段下的 hosts 由 127.0.0.1 变成 192.168.2.30
把—port=0 删除
修改之后在 k8s 各个节点执行
systemctl restart kubelet
kubectl get cs
显示如下:
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
ss -antulp | grep :10251
ss -antulp | grep :10252
可以看到相应的端口已经被物理机监听了
点击 status->targets,可看到如下kubernetes-kube-proxy 显示如下:
是因为 kube-proxy 默认端口 10249 是监听在 127.0.0.1 上的,需要改成监听到物理节点上,按如下方法修改,线上建议在安装 k8s 的时候就做修改,这样风险小一些:
kubectl edit configmap kube-proxy -n kube-system
把 metricsBindAddress 这段修改成 metricsBindAddress: 0.0.0.0:10249然后重新启动 kube-proxy 这个 pod
kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
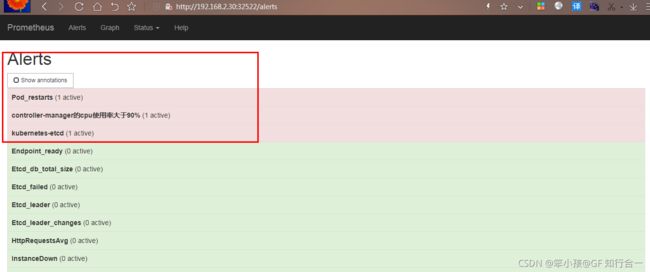
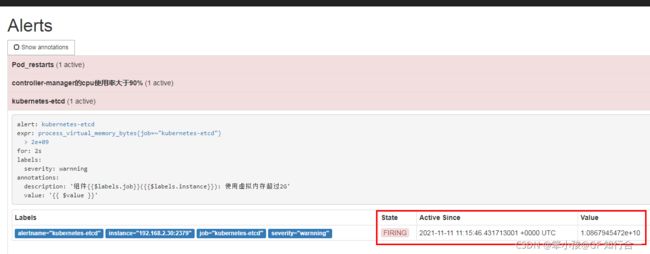
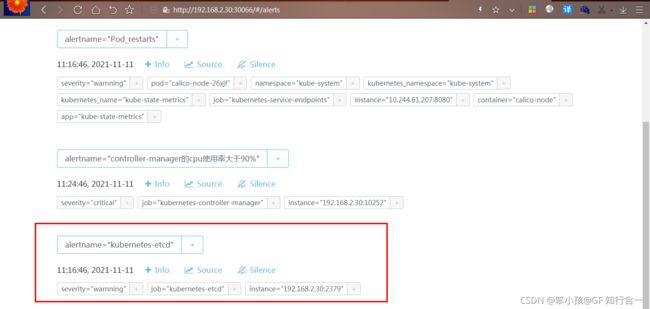
把 kubernetes-etcd 展开,可看到如下:
FIRING 表示 prometheus 已经将告警发给 alertmanager,在 Alertmanager 中可以看到有一个alert。
登录到 alertmanager web 界面,浏览器输入 192.168.2.30:30066
修改 prometheus 任何一个配置文件之后,可通过 kubectl apply 使配置生效,执行顺序如下:
kubectl delete -f alertmanager-cm.yaml
kubectl apply -f alertmanager-cm.yaml
kubectl delete -f prometheus-alertmanager-cfg.yaml
kubectl apply -f prometheus-alertmanager-cfg.yaml
kubectl delete -f prometheus-alertmanager-deploy.yaml
kubectl apply -f prometheus-alertmanager-deploy.yaml









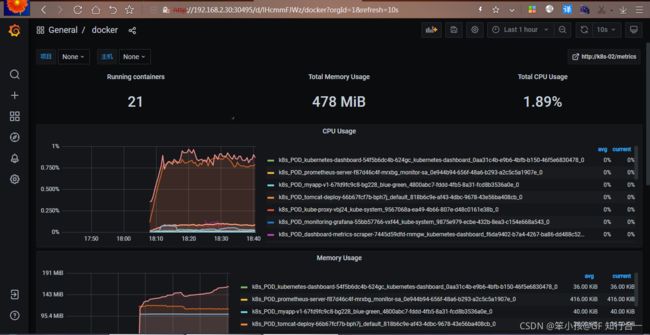

















prometheus 监控 redis
- 配置一个 Redis 的 exporter,通过 redis 进行暴露监控
在 Redis 上添加 prometheus.io/scrape=true
redis.yamlapiVersion: apps/v1 kind: Deployment metadata: name: redis namespace: kube-system spec: replicas: 2 selector: matchLabels: app: redis template: metadata: labels: app: redis spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchLabels: topologyKey: kubernetes.io/hostname containers: - name: redis image: redis:4 resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 6379 - name: redis-exporter image: oliver006/redis_exporter:latest resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 9121 --- kind: Service apiVersion: v1 metadata: name: redis namespace: kube-system annotations: prometheus.io/scrape: "true" prometheus.io/port: "9121" spec: selector: app: redis ports: - name: redis port: 6379 targetPort: 6379 - name: prom port: 9121 targetPort: 9121kubectl apply -f redis.yaml
redis 这个 Pod 中包含了两个容器,一个就是 redis 本身的主应用,另外一个容器就是 redis_exporter
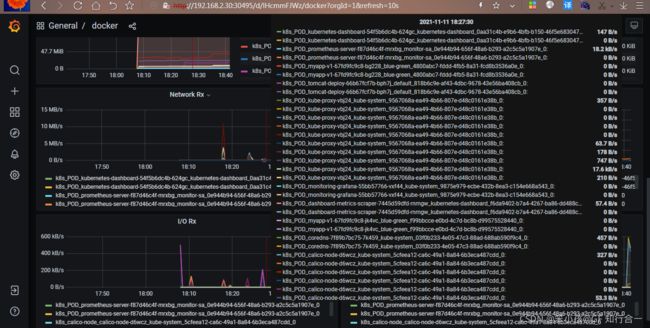
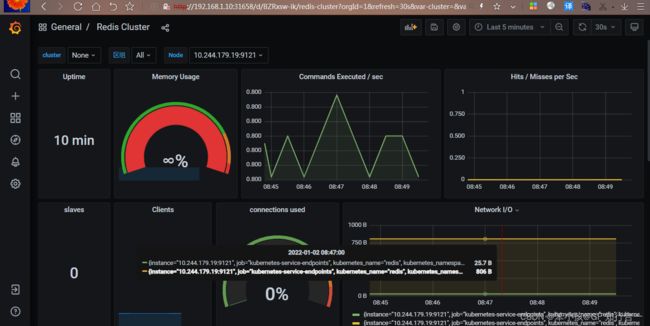
由于 Redis 服务的 metrics 接口在 redis-exporter 9121 上,所以我们添加了 prometheus.io/port=9121 这样的 annotation,在 prometheus 就会自动发现 redis 了在 grafana 导入 redis 的 json 文件 Redis Cluster-1571393212519.json,监控界面如下:
prometheus 监控 tomcat
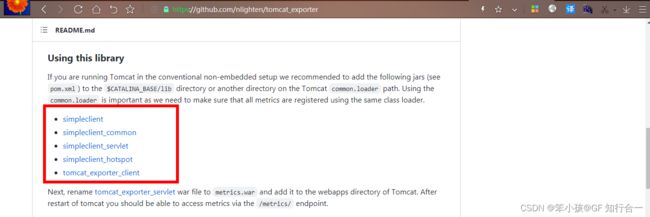
- tomcat_exporter 地址
https://github.com/nlighten/tomcat_exporter
下载 jar 包
- 制作 tomcat 镜像,按如下步骤
mkdir /root/tomcat_image
cd /root/tomcat_image
vim Dockerfile
FROM tomcat
ADD metrics.war /usr/local/tomcat/webapps/
ADD simpleclient-0.8.0.jar /usr/local/tomcat/lib/
ADD simpleclient_common-0.8.0.jar /usr/local/tomcat/lib/
ADD simpleclient_hotspot-0.8.0.jar /usr/local/tomcat/lib/
ADD simpleclient_servlet-0.8.0.jar /usr/local/tomcat/lib/
ADD tomcat_exporter_client-0.0.12.jar /usr/local/tomcat/lib/
docker build -t='gaofei0428/tomcat_prometheus:v1' .
docker push gaofei0428/tomcat_prometheus:v1
在 worker 节点 pull
docker pull gaofei0428/tomcat_prometheus:v1
(2)基于上面的镜像创建一个 tomcat 实例
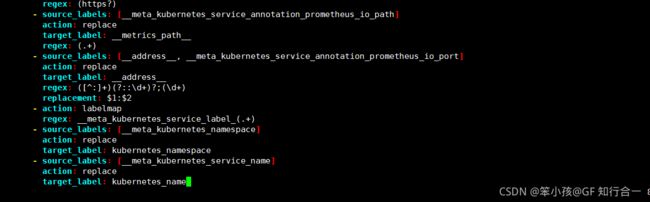
vim tomcat-deploy.yaml编辑 prometheus-cfg.yaml 添加apiVersion: apps/v1 kind: Deployment metadata: name: tomcat-deployment namespace: default spec: selector: matchLabels: app: tomcat replicas: 2 template: metadata: labels: app: tomcat annotations: prometheus.io/scrape: 'true' spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchLabels: topologyKey: kubernetes.io/hostname containers: - name: tomcat image: gaofei0428/tomcat_prometheus:v1 ports: - containerPort: 8080 securityContext: privileged: true- job_name: 'k8s-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_namekubectl delete --f prometheus-cfg.yaml
kubectl apply --f prometheus-cfg.yaml


prometheus 监控 elasticsearch
- 部署 exporter:
https://github.com/prometheuscommunity/elasticsearch_exporter/blob/master/examples/kubernetes/deployment.yml- cat el-deployment.yml
apiVersion: apps/v1 kind: Deployment metadata: name: elastic-exporter namespace: kube-logging spec: replicas: 2 #strategy: # rollingUpdate: # maxSurge: 2 # maxUnavailable: 0 # type: RollingUpdate selector: matchLabels: app: elastic-exporter template: metadata: labels: app: elastic-exporter spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchLabels: topologyKey: kubernetes.io/hostname containers: - command: - /bin/elasticsearch_exporter - --es.uri=http://elasticsearch:9200 - --es.all image: quay.io/prometheuscommunity/elasticsearch-exporter:latest securityContext: capabilities: drop: - SETPCAP - MKNOD - AUDIT_WRITE - CHOWN - NET_RAW - DAC_OVERRIDE - FOWNER - FSETID - KILL - SETGID - SETUID - NET_BIND_SERVICE - SYS_CHROOT - SETFCAP readOnlyRootFilesystem: true livenessProbe: httpGet: path: /healthz port: 9114 initialDelaySeconds: 30 timeoutSeconds: 10 name: elastic-exporter ports: - containerPort: 9114 name: http readinessProbe: httpGet: path: /healthz port: 9114 initialDelaySeconds: 10 timeoutSeconds: 10 resources: limits: cpu: 100m memory: 128Mi requests: cpu: 25m memory: 64Mi restartPolicy: Always securityContext: runAsNonRoot: true runAsGroup: 10000 runAsUser: 10000 fsGroup: 10000kubectl apply -f el-deployment.yml
在 elasticsearch-exporter 的 pod 前端创建一个 svc
vim elastic-exporter-svc.yamlkind: Service apiVersion: v1 metadata: name: elastic-exporter-svc namespace: kube-logging labels: app: elastic-exporter-svc spec: selector: app: elastic-exporter ports: - port: 9114 name: elastic-exporter
编辑 prometheus-cfg.yaml 在 末尾添加
- job_name: 'elasticsearch' scrape_interval: 60s scrape_timeout: 30s metrics_path: "/metrics" static_configs: - targets: ['elastic-exporter-svc.kube-logging.svc.cluster.local:9114']kubectl delete -f prometheus-cfg.yaml
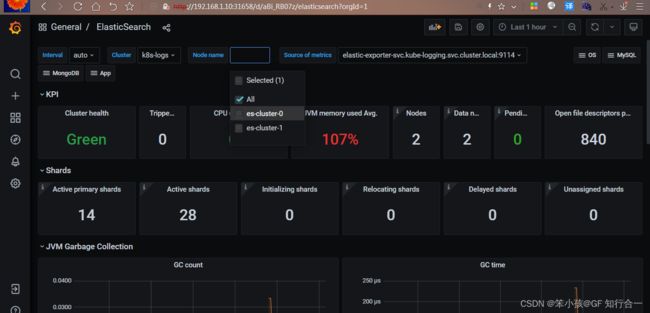
kubectl apply -f prometheus-cfg.yaml下载 json
导入 json



- 完整 cat ../prometheus/prometheus-cfg.yaml
kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: | global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: 'k8s-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'elasticsearch' scrape_interval: 60s scrape_timeout: 30s metrics_path: "/metrics" static_configs: - targets: ['elastic-exporter-svc.kube-logging.svc.cluster.local:9114']