零基础:数据分析的完整Python教程
目录
1.用于数据分析的Python基础(略)
- 为什么要学习Python进行数据分析?
- Python 2.7 v /秒3.4
- 如何安装Python?
- 在Python中运行一些简单的程序
2.Python库和数据结构
- Python数据结构
- Python迭代和条件构造
- Python库
3.使用Pandas在Python中进行探索性分析
- 系列和数据框简介
- Analytics Vidhya数据集-贷款预测问题
3.使用Pandas在Python中进行数据整理
- 系列和数据框简介
- Analytics Vidhya数据集-贷款预测问题
4.使用Pandas在Python中进行数据整理
5.用Python构建预测模型
- 逻辑回归
- 决策树
- 随机森林
2.Python库和数据结构
Python数据结构
以下是一些在Python中使用的数据结构。您应该熟悉它们,以便适当地使用它们。
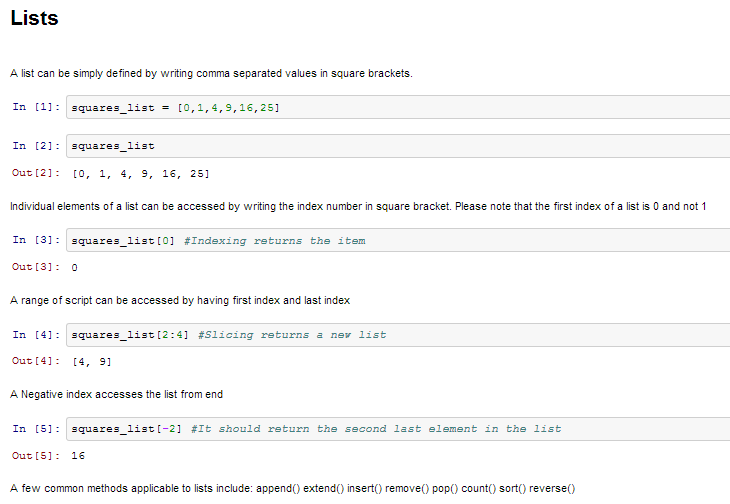
- 列表 –列表是Python中功能最丰富的数据结构之一。列表可以简单地通过在方括号中写一个用逗号分隔的值列表来定义。列表可能包含不同类型的项目,但是通常所有项目都具有相同的类型。Python列表是可变的,并且列表的各个元素都可以更改。
这是一个定义列表然后访问它的快速示例:
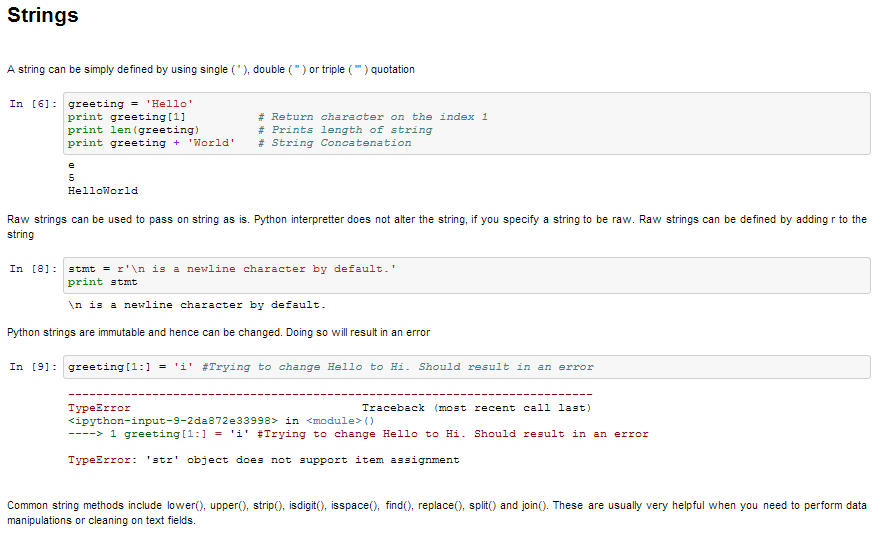
- 字符串–可以简单地通过使用单(‘),双(“”)或三(“’))反向逗号来定义字符串。用三引号引起来的字符串可以跨越多行,并且经常在文档字符串中使用(Python记录函数的方式)。\用作转义符。请注意,Python字符串是不可变的,因此您不能更改部分字符串。
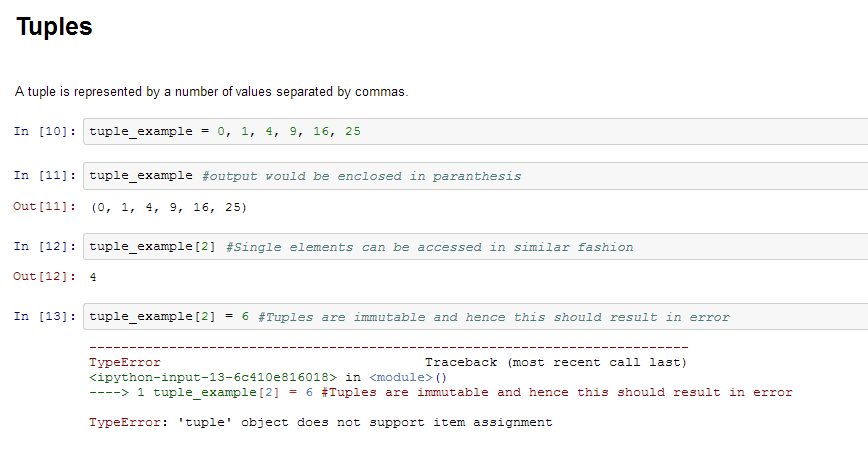
- 元组 –元组由用逗号分隔的多个值表示。元组是不可变的,并且输出用括号括起来,以便正确处理嵌套的元组。此外,即使元组是不可变的,但如果需要,它们也可以保存可变数据。
由于元组是不可变的并且不能更改,因此与列表相比,它们的处理速度更快。因此,如果您的列表不太可能更改,则应使用元组而不是列表。
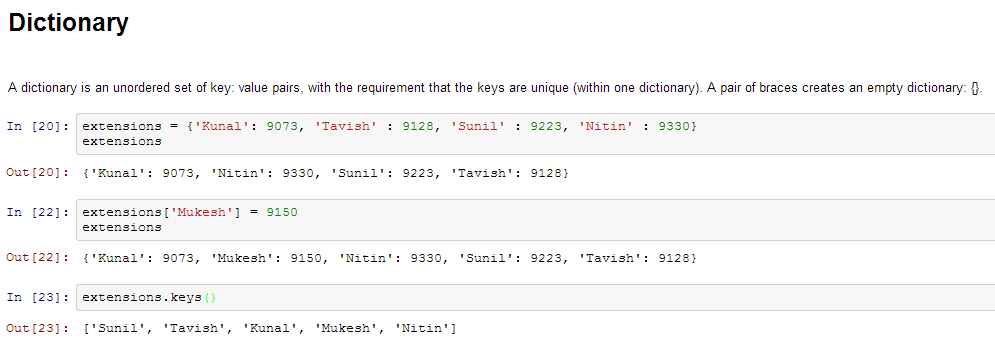
- 词典- d ictionary是无序集合的 键:值 对,与所述的要求,即,键是唯一的(一个字典内)。一对大括号创建一个空字典: {}。
Python迭代和条件构造
像大多数语言一样,Python也有一个FOR循环,这是最广泛使用的迭代方法。它具有简单的语法:
for i in [Python Iterable]:
expression(i)
这里的“ Python Iterable”可以是列表,元组或其他高级数据结构,我们将在后面的部分中进行探讨。让我们看一个简单的示例,确定数字的阶乘。
fact=1
for i in range(1,N+1):
fact *= i
谈到条件语句,这些语句用于根据条件执行代码片段。最常用的构造是if-else,其语法如下:
if [condition]:
__execution if true__
else:
__execution if false__
例如,如果我们要打印数字N是偶数还是奇数:
if N%2 == 0:
print ('Even')
else:
print ('Odd')
现在您已经熟悉了Python基础知识,让我们再进一步。如果必须执行以下任务怎么办:
- 乘以2个矩阵
- 找出二次方程的根
- 绘制条形图和直方图
- 建立统计模型
- 访问网页
例如,考虑一下我们刚才看到的阶乘示例。我们可以按照以下步骤一步一步完成:
math.factorial(N)
当然,我们需要为此导入数学库。接下来让我们探索各种库。
Python库
以下是库列表,您将需要进行任何科学计算和数据分析:
- NumPy代表数值Python。NumPy最强大的功能是n维数组。该库还包含基本的线性代数函数,傅立叶变换,高级随机数功能以及与其他低级语言(如Fortran,C和C++)集成的工具
- SciPy代表科学Python。SciPy建立在NumPy之上。它是用于各种高级科学和工程模块(例如离散傅立叶变换,线性代数,优化和稀疏矩阵)的最有用的库之一。
- Matplotlib用于绘制各种图形,从直方图到折线图再到热图。.您可以在ipythonNotebook中使用Pylab功能(ipython notebook –pylab =inline)以内联方式使用这些绘图功能。如果您忽略inline选项,则pylab会将ipython环境转换为非常类似于Matlab的环境。您还可以使用Latex命令将数学添加到绘图中。
- 用于结构化数据操作和操纵的熊猫。它被广泛用于数据处理和准备。熊猫是最近才添加到Python中的,并在促进Python在数据科学家社区中的使用方面发挥了作用。
- Scikit学习用于机器学习。该库基于NumPy,SciPy和matplotlib构建,包含许多用于机器学习和统计建模的有效工具,包括分类,回归,聚类和降维。
- 用于统计建模的Statsmodels。Statsmodels是一个Python模块,允许用户浏览数据,估计统计模型和执行统计测试。描述性统计信息,统计检验,绘图功能和结果统计信息的广泛列表适用于不同类型的数据和每个估计量。
- Seaborn用于统计数据可视化。Seaborn是一个用于使用Python制作引人入胜且内容丰富的统计图形的库。它基于matplotlib。Seaborn旨在使可视化成为探索和理解数据的中心部分。
- 散景,用于在现代网络浏览器上创建交互式绘图,仪表板和数据应用程序。它使用户能够以D3.js的样式生成优雅简洁的图形。此外,它具有对非常大的数据集或流数据集进行高性能交互的能力。
- Blaze将Numpy和Pandas的功能扩展到分布式和流数据集。它可用于访问来自多个源的数据,包括Bcolz,MongoDB,SQLAlchemy,ApacheSpark,PyTables等。Blaze与Bokeh一起可以充当非常强大的工具,用于在大量数据上创建有效的可视化效果和仪表板。
- Scrapy关于网络爬虫。这是获取特定数据模式的非常有用的框架。它具有从网站主页URL开始,然后在网站内的网页中进行挖掘以收集信息的功能。
- SymPy用于符号计算。它具有从基本符号算术到微积分,代数,离散数学和量子物理学的广泛功能。另一个有用的功能是能够将计算结果格式化为LaTeX代码。
- 访问网络的请求。它的工作方式类似于标准的python库urllib2,但是更容易编写代码。您会发现urllib2的细微差别,但是对于初学者来说,请求可能会更方便。
其他库,您可能需要:
- 操作系统和文件操作的操作系统
- networkx和igraph用于基于图的数据操作
- 用于在文本数据中查找模式的正则表达式
用于刮网的BeautifulSoup。它次于Scrapy,因为它将在运行中仅从单个网页中提取信息。
现在我们已经熟悉了Python基础知识和其他库,下面让我们深入研究通过Python解决问题的方法。是的,我的意思是建立一个预测模型!在此过程中,我们使用了一些功能强大的库,并且还遇到了下一层数据结构。我们将引导您完成三个关键阶段:
- 数据探索–进一步了解我们拥有的数据
- 数据整理–清理并处理数据,使其更适合统计建模
- 预测建模–运行实际算法并获得乐趣
3.使用Pandas在Python中进行探索性分析
Pandas是Python中最有用的数据分析库之一,有助于在数据科学界增加Python的使用
在加载数据之前,让我们了解Pandas中的2个关键数据结构–Series 和DataFrames。
Series 和DataFrames简介
Series 可以理解为一维标记/索引数组。您可以通过这些标签访问该系列的各个元素。
DataFrames框类似于Excel工作簿–您具有引用列的列名和行,可以使用行号进行访问。本质上的区别是,在数据帧的情况下,列名和行号称为列和行索引。
系列和数据框构成Python中Pandas的核心数据模型。首先将数据集读取到这些数据帧中,然后可以非常轻松地将各种操作(例如,分组,聚合等)应用于其列。
练习数据集–贷款预测问题
您可以从此处下载数据集。这是变量的描述:
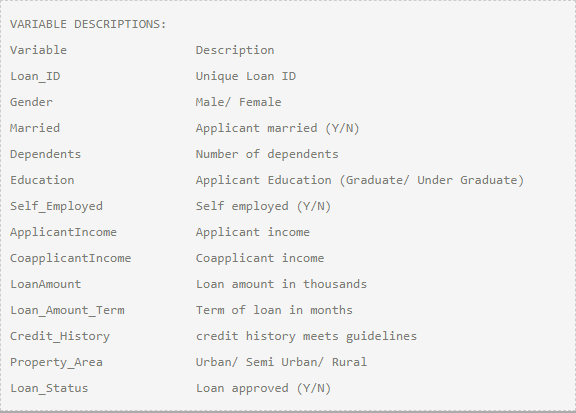
导入库和数据集:
以下是我们在本教程中将使用的库:
- Numpy
- matplotlib
- Pandas
请注意,由于Pylab环境,您不需要导入matplotlib和numpy。我仍然将它们保留在代码中,以防您在其他环境中使用该代码。
导入库后,您可以使用read_csv()函数读取数据集。在此阶段之前,代码是这样的:
import pandas as pd
import numpy as np
import matplotlib as plt
%matplotlib inline
df = pd.read_csv("/home/kunal/Downloads/Loan_Prediction/train.csv") #Reading the dataset in a dataframe using Pandas
快速数据探索
读取数据集后,您可以使用head()函数查看顶部几行
df.head(10)

这是查看前10行。或者,您也可以通过打印数据集查看更多的行
接下来,您可以使用describe()函数查看数字字段的摘要
df.describe(10)

describe()函数将在其输出中提供计数,均值,标准差(std),最小值,四分位数和最大值
这里有一些推断,您可以通过查看describe()函数的输出进行绘制:
- LoanAmount具有(614 – 592)22个缺失值。
- Loan_Amount_Term具有(614 – 600)14个缺失值。
- Credit_History具有(614 – 564)50个缺失值。
- 我们还可以看到大约84%的申请人具有credit_history。怎么样?Credit_History字段的平均值为0.84(请记住,对于拥有信用记录的用户,Credit_History的值为1,否则为0)
- ApplicantIncome分布似乎符合预期。与申请人相同
请注意,通过将平均值与中位数(即50%的数字)进行比较,我们可以了解数据中可能存在的偏斜。
对于非数字值(例如Property_Area,Credit_History等),我们可以查看频率分布以了解它们是否有意义。可以通过以下命令打印频率表:
df[‘Property_Area’].value_counts()
同样,我们可以查看信用证港口历史记录的唯一值。请注意,dfname [‘column_name’]是访问数据帧中特定列的基本索引技术。它也可以是列的列表。
https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
分布分析
既然我们已经熟悉了基本数据特征,那么让我们研究各种变量的分布。让我们从数字变量开始-即ApplicantIncome和LoanAmount
首先使用以下命令绘制ApplicantIncome的直方图:
df[‘ApplicantIncome’].hist(bin = 50)

在这里,我们观察到极值很少。这也是为什么需要50个容器才能清楚地描述分布的原因。
接下来,我们查看箱形图以了解分布。可以通过以下方式绘制票价的箱形图:
df.boxplot(column = ‘ApplicantIncome’ )
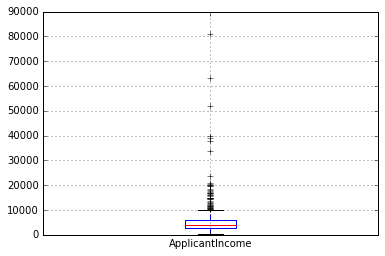
这确认了许多异常值/极端值的存在。这可以归因于社会上的收入差距。部分原因可能是由于我们正在寻找具有不同教育水平的人。让我们按教育来区分它们:
df.boxplot(column = ‘ApplicantIncome’,by = Education )
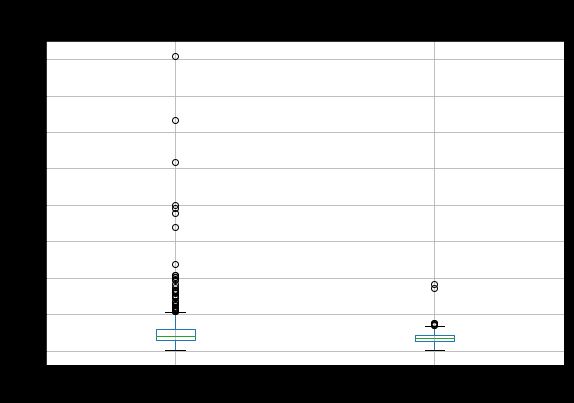
我们可以看到,毕业生和非毕业生的平均收入之间没有实质性差异。但是,收入较高的毕业生人数较多,这似乎与众不同。
现在,让我们使用以下命令查看LoanAmount的直方图和箱线图:
df[‘LoanAmount’].hist(bin = 50)
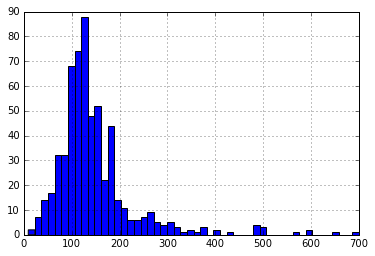
df.boxplot(column = ‘LoanAmount’ )
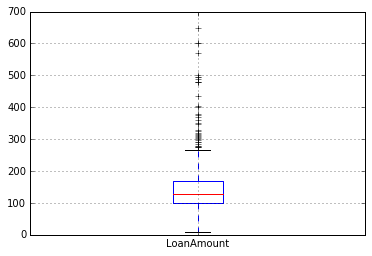
同样,还有一些极限值。显然,ApplicantIncome和LoanAmount都需要一定数量的数据处理。LoanAmount具有缺失值和极值,而ApplicantIncome具有一些极值,这需要更深入的了解。我们将在接下来的部分中进行介绍。
分类变量分析
现在,我们了解了ApplicantIncome和LoanIncome的分布,让我们更详细地了解分类变量。我们将使用Excel样式数据透视表和交叉表。例如,让我们根据信用历史记录来查看获得贷款的机会。可以使用以下数据透视表在MS Excel中实现此目的:
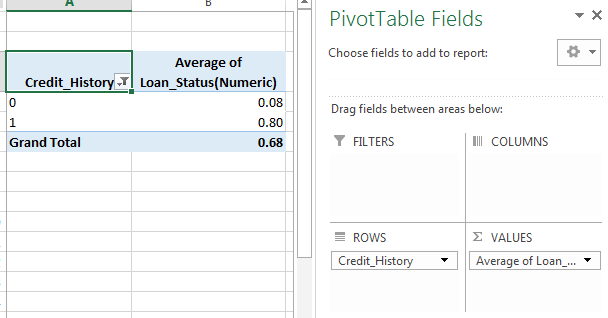
注意:此处的贷款状态已编码为1(是)和0(否)。因此,平均值表示获得贷款的概率。
现在,我们将研究使用Python生成相似见解所需的步骤。请参考本文以了解Pandas中不同的数据处理技术。
temp1 = df['Credit_History'].value_counts(ascending=True)
temp2 = df.pivot_table(values='Loan_Status',index=['Credit_History'],aggfunc=lambda x: x.map({'Y':1,'N':0}).mean())
print ('Frequency Table for Credit History:')
print (temp1)
print ('\nProbility of getting loan for each Credit History class:')
print (temp2)

现在我们可以观察到,我们得到了类似于MS Excel的枢轴表。可以使用“ matplotlib”库通过以下代码将其绘制为条形图:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Credit_History')
ax1.set_ylabel('Count of Applicants')
ax1.set_title("Applicants by Credit_History")
temp1.plot(kind='bar')
ax2 = fig.add_subplot(122)
temp2.plot(kind = 'bar')
ax2.set_xlabel('Credit_History')
ax2.set_ylabel('Probability of getting loan')
ax2.set_title("Probability of getting loan by credit history")
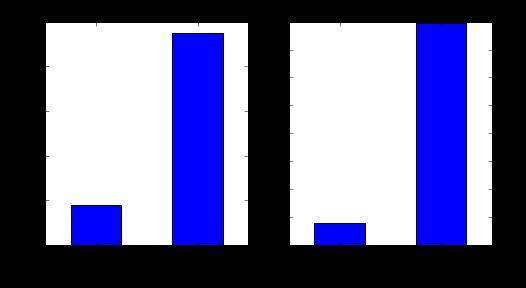
这表明,如果申请人具有有效的信用记录,则获得贷款的机会是八倍。您可以按已婚,自雇,Property_Area等绘制类似的图。
或者,也可以通过将它们组合成堆叠图表来可视化这两个图:
temp3 = pd.crosstab(df['Credit_History'], df['Loan_Status'])
temp3.plot(kind='bar', stacked=True, color=['red','blue'], grid=False)
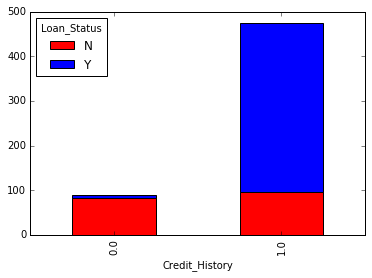
您还可以将性别添加到混合中(类似于Excel中的数据透视表):
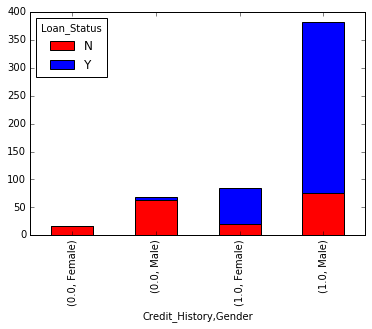
如果您还没有意识到,我们在这里刚刚创建了两种基本的分类算法,一种基于信用记录,另一种基于2个分类变量(包括性别)。您可以对此进行快速编码,以在AV Datahacks上创建第一个提交。
我们刚刚看到了如何使用Pandas在Python中进行探索性分析
接下来,让我们进一步研究ApplicantIncome和LoanStatus变量,进行数据处理并创建一个数据集以应用各种建模技术。我强烈建议您在阅读更多内容之前,先处理另一个数据集和问题,并通过一个独立的示例进行研究。
4.用Python处理数据:使用Pandas
数据处理-需求概述
在探索数据的过程中,我们发现了数据集中的一些问题,需要先解决这些问题,然后才能为好的模型准备好数据。此练习通常称为“数据整理”。这是我们已经意识到的问题:
- 一些变量中缺少值。我们应该根据缺失值的数量和变量的预期重要性来明智地估计这些值。
- 在查看分布时,我们看到ApplicantIncome和LoanAmount似乎在任一端都包含极值。尽管它们可能具有直觉上的意义,但应适当对待。
除了数字字段的这些问题外,我们还应该查看非数字字段,例如性别,财产领域,已婚,教育和受抚养人,以查看它们是否包含有用的信息。
如果您不熟悉Pandas,我建议您 在继续之前阅读 本文。它详细介绍了一些有用的数据处理技术。
检查数据集中的缺失值
让我们看一看所有变量中的缺失值,因为大多数模型都无法处理缺失数据,即使它们确实存在,对它们进行估算也往往会有所帮助。因此,让我们检查数据集中的空值/ NaN数
df.apply(lambda x: sum(x,isnull()),axis=0)
该命令告诉我们每列中缺少值的数量,因为isnull()返回1(如果该值为null)
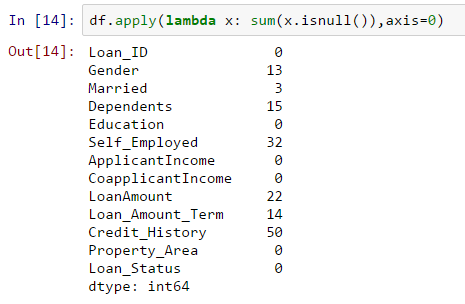
尽管缺失值的数量不是很高,但是有很多变量,因此应该对每个变量进行估计并将其添加到数据中。通过本文详细了解不同的插补技术。
注意:请记住,缺失值不一定总是NaN。例如,如果Loan_Amount_Term为0,这有意义吗?还是您会认为缺失?我想您的答案不见了,您说得对。因此,我们应该检查不可行的值。
如何填写LoanAmount中的缺失值?
有很多方法可以填补贷款金额的缺失值-最简单的方法是用均值替换,可以通过以下代码完成:
df['LoanAmount'].fillna(df['LoanAmount'].mean(),inplace = Ture)
另一个极端可能是建立一个监督学习模型,以基于其他变量来预测贷款额,然后将年龄和其他变量一起用于预测生存期。
因为,现在的目的是找出数据处理的步骤,所以我宁愿采用一种方法,该方法介于这两个极端之间。一个关键的假设是,一个人是受过教育还是自谋职业,可以结合起来对贷款金额进行很好的估计。
首先,让我们看一下箱线图,看是否存在趋势:

因此,我们看到每个组的贷款金额中位数都有一些变化,可以用来估算这些值。 但是首先,我们必须确保“个体经营”和“教育”变量中的每个值都不应缺少。
正如我们之前所说,Self_Employed具有一些缺失的值。让我们看一下频率表:
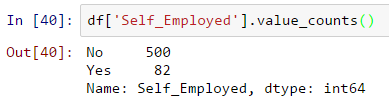
由于〜86%的值为“否”,因此将丢失的值归为“否”是安全的,因为成功的可能性很高。可以使用以下代码完成此操作:
df['Self_Employed'].fillna(‘No’,inplace = Ture)
现在,我们将创建数据透视表,该表为我们提供了自雇和教育功能的所有唯一值组的中值。接下来,我们定义一个函数,该函数返回这些单元格的值并将其应用于填充贷款金额的缺失值:
table = df.pivot_table(values='LoanAmount', index='Self_Employed' ,columns='Education', aggfunc=np.median)
# 定义函数以返回次数据透视表定义值
def fage(x):
return table.loc[x['Self_Employed'],x['Education']]
#替换丢失的值
df['LoanAmount'].fillna(df[df['LoanAmount'].isnull()].apply(fage, axis=1), inplace=True)
这应该为您提供一种估算贷款金额缺失值的好方法。
注意:仅当您没有使用以前的方法(即使用均值)填充Loan_Amount变量中的缺失值时,此方法才有效。
如何处理LoanAmount和ApplicantIncome分配中的极值?
让我们首先分析LoanAmount。由于极高的价值实际上是可能的,即有些人可能会因特殊需要而申请高价值贷款。因此,让我们尝试对数转换以消除其影响,而不是将它们视为离群值:
df['LoanAmount_log'] = np.log(df[‘LoanAmount_log’])
df[‘LoanAmount_log’].hist(bins = 20)
再次查看直方图:
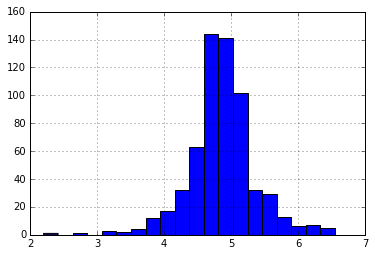
现在,分布看起来更接近于正态分布,极值的影响已大大减弱。
即将来临的申请人收入。一种直觉可能是某些申请人的收入较低,但支持共同申请人。因此,将两个收入合并为总收入并对其进行对数转换可能是一个好主意。
df['TotalIncome'] = df['ApplicantIncome'] + df['CoapplicantIncome']
df['TotalIncome_log'] = np.log(df['TotalIncome'])
df['LoanAmount_log'].hist(bins=20)
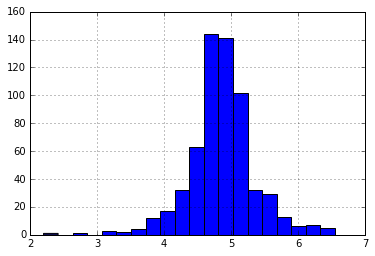
现在我们看到分布比以前好得多。我将由您自己来填写性别,已婚,受抚养人,贷款额度,信贷历史记录的缺失值。另外,我建议您考虑可以从数据中得出的其他信息。例如,为LoanAmount / TotalIncome创建一个列可能很有意义,因为它可以使申请人了解贷款的还款能力。
接下来,我们将研究制作预测模型。
5.用Python构建预测模型
之后,我们使数据对建模有用,现在让我们看一下在我们的数据集上创建预测模型的python代码。Skicit-Learn(sklearn)是为此目的在Python中最常用的库,我们将继续学习。我鼓励您通过本文来复习sklearn 。
由于sklearn要求所有输入均为数字,因此我们应通过编码类别将所有分类变量转换为数字。在此之前,我们将填充数据集中的所有缺失值。可以使用以下代码完成此操作:
df['Gender'].fillna(df['Gender'].mode()[0], inplace=True)
df['Married'].fillna(df['Married'].mode()[0], inplace=True)
df['Dependents'].fillna(df['Dependents'].mode()[0], inplace=True)
df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mode()[0], inplace=True)
df['Credit_History'].fillna(df['Credit_History'].mode()[0], inplace=True)
from sklearn.preprocessing import LabelEncoder
var_mod = ['Gender','Married','Dependents','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
df[i] = le.fit_transform(df[i])
df.dtypes
接下来,我们将导入所需的模块。然后,我们将定义一个通用分类函数,该函数将模型作为输入并确定准确性和交叉验证分数。由于这是一篇介绍性文章,因此我不会详细介绍编码。请参阅本文以获取有关R和Python代码的算法的详细信息。另外,通过本文复习交叉验证也将是一件好事,因为它是衡量电源性能的非常重要的指标。
#从scikit 导入模型学习模块:
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold #For K-fold cross validation
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import metrics
#Generic function for making a classification model and accessing performance:
def classification_model(model, data, predictors, outcome):
#Fit the model:
model.fit(data[predictors],data[outcome])
#对训练集进行预测:
predictions = model.predict(data[predictors])
#Print accuracy
print ("Accuracy : %s" % "{0:.3%}".format(accuracy))
#Perform k-fold cross-validation with 5 folds
#对k进行5倍 k 交叉验证
kf = KFold(data.shape[0], n_folds=5)
error = []
for train, test in kf:
#过滤训练数据
train_predictors = (data[predictors].iloc[train,:])
#用来训练算法的目标.
train_target = data[outcome].iloc[train]
#使用预测变量和目标训练算法.
model.fit(train_predictors, train_target)
#Record error from each cross-validation run
error.append(model.score(data[predictors].iloc[test,:], data[outcome].iloc[test]))
print ("Cross-Validation Score : %s" % "{0:.3%}".format(np.mean(error)))
#Fit the model again so that it can be refered outside the function:
model.fit(data[predictors],data[outcome])
逻辑回归
让我们建立第一个Logistic回归模型。一种方法是将所有变量都放入模型中,但这可能会导致过拟合(如果您还不知道此术语,请不要担心)。简而言之,采用所有变量可能会使模型理解特定于数据的复杂关系,并且不能很好地概括。阅读有关Logistic回归的更多信息
我们可以很容易地做出一些直观的假设来使球滚动。在以下情况下获得贷款的机会会更高:
- 拥有信用记录的申请人(还记得我们在探索中观察到的吗?)
- 申请人和共同申请人收入较高的申请人
- 受过高等教育的申请者
- 具有高增长前景的市区物业
因此,让我们使用“ Credit_History”创建第一个模型。
outcome_var = 'Loan_Status'
model = LogisticRegression()
predictor_var = ['Credit_History']
classification_model(model, df,predictor_var,outcome_var)
准确性:80.945%交叉验证得分:80.946%
# 我们可以尝试不同的变量组合:
predictor_var = ['Credit_History','Education','Married','Self_Employed','Property_Area']
classification_model(model, df,predictor_var,outcome_var)
准确性:80.945%交叉验证得分:80.946%
通常,我们希望添加变量会提高准确性。但这是一个更具挑战性的案例。不那么重要的变量不会影响准确性和交叉验证分数。Credit_History主导了该模式。现在我们有两个选择:
- 功能工程:获取新信息并尝试进行预测。我将把这个留给您的创造力。
- 更好的建模技术。接下来让我们探讨一下。
决策树
决策树是用于建立预测模型的另一种方法。已知提供比逻辑回归模型更高的准确性。了解有关决策树的更多信息。
model = DecisionTreeClassifier()
predictor_var = ['Credit_History','Gender','Married','Education']
classification_model(model, df,predictor_var,outcome_var)
准确性:81.930%交叉验证得分:76.656%
在这里,基于分类变量的模型无法产生影响,因为信用历史记录控制着它们。让我们尝试一些数字变量:
#We can try different combination of variables:
predictor_var = ['Credit_History','Loan_Amount_Term','LoanAmount_log']
classification_model(model, df,predictor_var,outcome_var)
准确性:92.345%交叉验证得分:71.009%
在这里,我们观察到尽管添加变量的准确性有所提高,但交叉验证误差却有所降低。这是模型过度拟合数据的结果。让我们尝试一个更复杂的算法,看看是否有帮助:
随机森林
随机森林是解决分类问题的另一种算法。阅读有关随机森林的更多信息
随机森林的一个优点是我们可以使它与所有要素一起使用,并且它返回一个要素重要性矩阵,可用于选择要素。
model = RandomForestClassifier(n_estimators=100)
predictor_var = ['Gender', 'Married', 'Dependents', 'Education',
'Self_Employed', 'Loan_Amount_Term', 'Credit_History', 'Property_Area',
'LoanAmount_log','TotalIncome_log']
classification_model(model, df,predictor_var,outcome_var)
准确性:100.000%交叉验证得分:78.179%
在这里,我们看到训练集的准确性是100%。这是过度拟合的最终案例,可以通过两种方式解决:
- 减少预测变量的数量
- 调整模型参数
让我们尝试这两个。首先,我们看到特征重要性矩阵,从中可以提取最重要的特征。
#Create a series with feature importances:
featimp = pd.Series(model.feature_importances_, index=predictor_var).sort_values(ascending=False)
print (featimp)
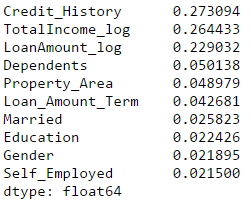
让我们使用前5个变量创建模型。另外,我们将稍微修改随机森林模型的参数:
model = RandomForestClassifier(n_estimators=25, min_samples_split=25, max_depth=7, max_features=1)
predictor_var = ['TotalIncome_log','LoanAmount_log','Credit_History','Dependents','Property_Area']
classification_model(model, df,predictor_var,outcome_var)
准确性:82.899%交叉验证得分:81.461%
请注意,尽管准确性降低了,但是交叉验证得分却有所提高,表明该模型具有很好的泛化能力。请记住,随机森林模型不是完全可重复的。由于随机化,不同的运行会导致轻微的变化。但是输出应该留在球场上。
您可能已经注意到,即使在随机森林上进行了一些基本参数调整之后,我们所达到的交叉验证准确性也仅比原始逻辑回归模型略高。该练习为我们提供了一些非常有趣且独特的学习方法:
- 使用更复杂的模型不能保证获得更好的结果。
- 避免在不了解基本概念的情况下将复杂的建模技术用作黑匣子。这样做会增加过度拟合的趋势,从而使您的模型难以解释
- 功能工程是成功的关键。每个人都可以使用Xgboost模型,但真正的艺术和创造力在于增强您的功能以使其更适合该模型。
最后
在学习python中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入python交流学习
多多交流问题,互帮互助,这里有不错的学习教程和开发工具。
(python兼职资源+python全套学习资料)

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。