网站不被谷歌收录的常见原因及解决办法
现如今的互联网中,流量获取的渠道多种多样,但对于独立站而言,Google仍然是一个重要的流量来源。这是因为Google拥有庞大的用户基础,通过Google可以让潜在用户更容易发现我们的网站。然而,现实情况是,一些网站可能长时间没有被谷歌收录,这导致了这些独立站很少有人访问的尴尬处境。那么,遇到网站很多页面都没有被Google收录,或长时间没有被收录的情况,说明网站可能存在一些问题。本文总结了一些网站不被谷歌收录的常见问题和解决办法,希望能对你有所启发。
Google是如何收录的?
Google的收录方式是通过爬虫自动访问你的网站,并将网站的内容和信息添加到它的索引数据库中。Google的爬虫会根据算法规则对你的网站进行评估,判断是否对用户有用,并决定是否将你的网站添加到它的索引数据库中。
- 爬取(Crawling)和索引(Indexing)是搜索引擎对互联网页面进行处理和组织的两个主要过程。
爬取(Crawling):爬取指的是搜索引擎通过程序(爬虫)自动访问互联网上的网页,从中提取网页内容和链接。爬虫会从一个起始网址开始,通过网页中的链接不断抓取其他网页,并将这些页面的内容存储在搜索引擎的数据库中。爬取是搜索引擎发现新网页和更新现有网页内容的过程。 - 索引(Indexing):索引是将爬取的网页内容进行组织和存储的过程。搜索引擎会对爬取到的网页进行分析,并将网页的关键信息提取出来,如标题、正文、URL等。然后,这些信息会被添加到搜索引擎的索引数据库中。索引是搜索引擎根据网页内容建立快速访问的数据结构,以支持后续的搜索操作。
通过爬取和索引,搜索引擎能够建立起一个包含大量网页信息的索引数据库。当用户输入搜索查询时,搜索引擎会在索引数据库中匹配相关的网页,并根据一定的算法展示给用户最相关的搜索结果。爬取和索引是搜索引擎实现准确高效搜索的基础步骤。
如何检查你的页面是否被Google索引和收录?
如何计算收录率
网站的收录率是指搜索引擎已经索引的网站页面数量与网站总页面数量的比例。计算网站的收录率可以帮助你了解搜索引擎对你的网站的覆盖程度,以及是否有页面未被索引。以下是计算网站收录率的方法:
- 确定网站总页面数量:首先,你需要确定你的网站有多少个页面。这包括主页、子页面、文章、产品页面、标签页、类别页等。你可以使用网站地图(sitemap)来帮助你列出所有的页面,或者使用网站分析工具来获取这些信息。
- 确定已收录的页面数量:你可以借助Google Search Console统计收录的网页数,也可以借助一些方法工具。
- 计算收录率:将被Google索引的页面数量除以网站总页面数量,然后将结果乘以100以获得百分比。收录率的公式如下:
收录率 = (已被Google索引的页面数量 / 总页面数量) * 100例如,如果你的网站总共有100个页面,而Google已经索引了80个页面,那么你的网站的收录率为80%。
如何检查网页是否被Google索引和收录
- 使用site:命令进行Google搜索:在Google搜索栏中输入“site:yourwebsite.com”(将”yourwebsite.com”替换为你的网站域名),然后按下Enter。这将显示与你的网站相关的所有被Google索引的页面。如果有页面显示在搜索结果中,那么它们已经被Google收录。
- 使用Google Search Console:Google Search Console是一个强大的工具,用于管理你的网站在Google搜索中的表现。如果你还没有将你的网站添加到Google Search Console,可以注册一个免费帐户,并验证你的网站所有权,具体操作可以参考《快速被Google谷歌收录教程》。在Google Search Console中,你可以查看有关你的网站索引情况的详细信息,包括哪些页面被索引,是否存在索引错误以及哪些关键词带来了流量。
- 使用网站分析工具:除了Google Search Console,还有一些第三方网站分析工具,如SEMrush、Ahrefs和Moz,可以帮助你监测你的网站的索引情况。这些工具提供了有关你的网站在搜索引擎中的表现以及哪些页面被索引的详细数据。
- 手动检查页面是否被索引:如果你想手动检查特定页面是否被Google索引,可以在Google搜索栏中输入该页面的URL,然后查看是否有相应的搜索结果。如果搜索结果中包含了你的页面,那么它已经被索引。
网站不被谷歌收录的常见原因及解决办法
新网站未被收录
如果你的网站是新建的,可能需要一些时间才能被搜索引擎索引。新网站通常需要等待搜索引擎的爬虫来发现和索引其内容。一般来讲收录的时间可能需要数天至数周。
如果你想让Google更快速、更全面地发现和索引你网站,你可以主动将你网站的sitemap提交给Google Search Console。如果不知道如何操作,这篇文章《快速被Google谷歌收录教程》有详细介绍。在竞争激烈的行业中,搜索引擎可能更加挑剔,对新网站的索引速度较慢。需要更多的努力来提高网站的质量和相关性。
robots.txt文件阻止索引
robots.txt文件是位于WordPress 根目录中的文本文件,它用于指导搜索引擎爬虫确定哪些页面应该被抓取,哪些不应该被抓取。正确配置的robots.txt文件有助于避免爬虫抓取不必要的内容,同时也有助于管理抓取配额,以确保合理利用资源。
如果你的网站的robots.txt文件中包含了不允许搜索引擎爬取的指令,如”Disallow: /”,搜索引擎将不会索引你的网站内容。确保robots.txt文件正确配置以允许搜索引擎爬取重要页面。
那么如果检查网站的robots.txt文件呢?首先打开浏览器,直接在地址栏里输入:
http://yourdomain.com/robots.txtAllow就是允许被爬取的网页,Disallow就是不允许被爬取的网页。
检查你的robots.txt设置。如果你发现以下代码段:
User-agent: Googlebot
Disallow: /
User-agent: *
Disallow: /User-agent代表用户代理,行中的星号(*)表示适用于所有可能的爬虫,即所有爬虫都必须根据robots文件中的规则进行合理的网站内容抓取。
Disallow行中的正斜杠(/)告诉爬虫,网站的所有页面都被禁止抓取。
这几行代码段的含义是告诉谷歌爬虫不被允许爬取你网站的任何页面。要解决这个问题,非常简单,只需删除这些代码即可。
然后,仔细检查robots.txt文件中的任何其他“Disallow”规则。如果其中包含你希望被索引的页面,请务必将相应的“Disallow”规则删除掉。
Meta标签Noindex指示不被索引
有时,网站页面的HTML头部可能包含了标签,这会告诉搜索引擎不要索引该页面。检查你的网站的HTML代码,确保没有这些标签。
检查方法:页面右击->查看网页源代码->搜“noindex”,

检查网页源代码
如果你发现有以下这行代码:
那你要做的就是去掉这行代码。
如何找到带有Noindex标签的网页?
首先,在Google Search Console中绑定你的网站,然后选择“Indexing”–“Pages”。
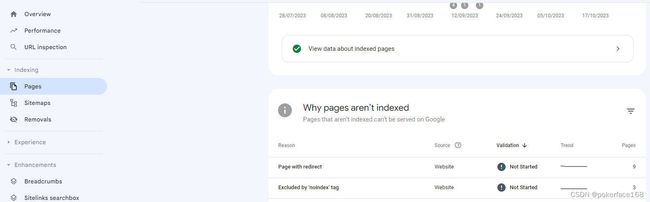
检查noidex标签网页
接下来,你可以在该页面中查看网页不被索引的原因。如果一个网页带有Noindex标签,那么它就会被归类到“Excluded by ‘noindex’ tag”,这表示这些页面被排除在索引之外。
你可以点击这个原因,然后查看具体的网页列表。如果你发现列表中包含不应该带有Noindex标签的页面,可以进入你的网站后台进行编辑和修改。
如果你想加快这些页面的重新索引过程,可以在Google Search Console中提交这些页面,让搜索引擎重新检查它们。

请求索引
请注意:要使noindex规则生效,页面不得受到robots.txt文件的阻止,并且搜索引擎爬虫必须能够访问该页面。如果页面在robots.txt文件中被排除,或者搜索引擎爬虫无法访问该页面,那么noindex标签将不会生效,该页面仍然可能会出现在搜索结果中,尤其是如果其他页面链接到它,它的内容可能仍然会被索引。
内部链接中带有’nofollow’
Nofollow链接是那些带有 ‘rel=”nofollow”‘ 属性的链接。它们的存在是为了防止传递链接权重给目标页面。
Google对于 ‘nofollow’ 的处理方式如下:
实际上,使用 ‘nofollow’ 会导致目标链接页面从索引中排除。
然而,如果其他网站链接到目标页面并且没有使用 ‘nofollow’,或者如果目标页面的URL已经被提交到Google的网站地图中,那么目标页面仍然有可能出现在我们的索引中。
因此,对于你自己网站内部的链接,要确保所有这些内部链接都是 ‘follow’ 链接。
所以,如果你希望页面被Google索引,请确保在链接到目标页面的内部链接中删除 ‘nofollow’ 属性。
内容质量低
如果你的网站内容质量较低,包括重复内容、低质量内容或不原创内容,搜索引擎可能会减少或停止索引你的网站。
你可以从以下几个方面优化网站:
- 提升网站内容质量:谷歌最注重用户体验。因此,关注网站每个页面的内容质量至关重要。提供高质量的内容可以为用户提供更好的体验。因此,务必确保网站内容富有实质,避免冗长无用的内容。同时,不要忽视图像的SEO,为图像添加有意义的Alt标签。
- 优化网站结构:保持网站结构扁平化,使URL简洁清晰,避免使用动态乱码,尽量在URL中包含关键词。
提高网站加载速度:确保网站加载速度快,这对用户体验和搜索引擎排名至关重要。 - 创建定制的404错误页面:配置一个自定义的404错误页面,以帮助用户在找不到页面时导航到其他有用的内容。
- 优化每个页面的SEO TDK:为每个页面设置良好的SEO标题、描述和关键词(TDK),这有助于搜索引擎更好地了解页面内容并提高搜索结果的吸引力。
缺少内部链接
Google通过页面中的内部链接来发现新内容,所以如果你的网页缺少内部链接,搜索引擎难以自动发现它们。同时,访客也无法通过网站内部导航直接访问这些页面。
这种没有其他内部链接指向的页面也被成为孤页,那么如何修复呢?
- 如果该页面不重要,你可以考虑删除它,并在你的网站地图中将其排除。这将确保搜索引擎不会浪费时间爬取不重要的页面。
- 如果该页面重要,你应该在其他网页中添加内部链接指向该页面。这样可以确保搜索引擎和访客可以轻松找到并访问这个重要页面,提高网站的可访问性和搜索引擎可索引性。
不合规的SEO实践或被惩罚
使用不合规的SEO(搜索引擎优化)技术,如关键词堆砌、门户页面或其他黑帽SEO方法,可能导致搜索引擎不收录你的网站,甚至对其进行惩罚。
如果你的网站违反了搜索引擎的规则和政策,可能会受到惩罚,包括从索引中排除。这些违规可能包括恶意软件、垃圾信息、侵犯版权的内容等。
写在最后
网页未被搜索引擎索引和收录通常有两个主要原因,而有时这两个问题可能同时存在:
- 技术问题影响索引: 技术问题包括robots.txt文件配置错误、页面加载速度慢、服务器问题、重复内容、404错误等。这些问题可能导致搜索引擎难以爬取和索引你的页面。
- 低质量内容或价值不明显: 如果搜索引擎认为你的网页内容质量低下、不原创或没有足够的价值,它们可能会选择不索引你的网页。搜索引擎的目标是提供有质量和相关性的搜索结果,因此质量问题可能导致收录问题。
在实际情况中,技术问题通常是影响页面收录的主要原因,但也需要注意网站内容的质量和相关性。通过采取适当的技术措施,如修复技术问题、优化页面速度、配置正确的robots.txt文件,以及改善内容的质量和相关性,可以解决页面索引和收录的问题,提高你的网站在搜索引擎中的表现。