我的android多线程编程之路(1)之经验详解,源码分析
写在伊始
android开发这么久了,对于多线程这块一直处于似懂非懂的神奇状态,今天总结出来,分享一下,希望大家多多指正。共同交流,恳望得到您的建议。
本文简介
本文会基于自己在开发中对于线程这块的实际使用,大概从线程进程的概念,线程的创建(Thread和Runnable)和使用,线程的各个方法的介绍,线程池的介绍等,及Handler,AsyncTask,IntentService及现在使用的RxJava2.0(线程控制部分,对此部分的RxJava2.0源码分析费了好长时间,还请各位一起发现问题)进行总结,会加上自己对于源码的一些理解。本文可能较长,如果您对本文的内容有研究或者有兴趣,还请认真观看,并提出自己的一些建议和认识,我希望自己能从大家的身上认识到这块的不足,在此谢谢大家了。
本文写到最后,决定分为两个部分,第一部分是除去RxJava2.0线程调度部分的全部内容。
第二部分全部用于对RxJava2.0线程调度(Schedulers)的源码进行分析。
线程与进程简介
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一组系统资源。即进程空间或(虚空间)。在进程的概念中,每一个进程的内部数据和状态都是完全独立的。进程不依赖于线程而独立存在,一个进程中可以启动多个线程。在Windows操作系统中一个进程就是一个exe或dll程序,它们相互独立,互相也可以通信,在Android操作系统中进程间的通信应用也是很多的(这个在这先不说)。
线程是指进程中的一个执行流程,一个进程中可以运行多个线程。线程与进程相似,是一段完成某个特定功能的代码,是程序中单个顺序的流控制。但与进程不同的是,同类的多个线程共享一块内存空间和一组系统资源,所以系统在各个线程之间切换时,资源占用要比进程小得多,正因如此,线程也被称为轻量级进程。线程总是属于某个进程,线程没有自己的虚拟地址空间,与进程内的其他线程一起共享分配给该进程的所有资源。值得注意的是,线程是不能够独立执行的,必须依存在应用程序中,由应用程序提供多个线程执行控制。
多线程简介
多线程指的是在单个程序中可以同时运行多个不同的线程,执行不同的任务。多线程意味着一个程序的多行语句可以看上去几乎在同一时间内同时运行。 “同时”执行是人的感觉,在线程之间实际上轮换执行。多线程最常用的使用就是处理各种各样的耗时操作,提高程序的执行效率。
线程的两种创建方式
在Java中有两种方法实现线程体:一是继承线程类Thread,二是实现接口Runnable。
Thread方式
public class FirstThread extends Thread {
@Override
public void run() { //run方法,程序的执行代码
...
}
public static void main(String[] args){
Thread t1=new FirstThread ();
t1.start();
}
} Runnable方式(适合资源共享)
public class RunnableImpl implements Runnable{
@Override
public void run() { //run方法,程序的执行代码
...
}
}
public class TestRunnable {
public static void main(String[] args) {
RunnableImpl ri=new RunnableImpl();
Thread t1=new Thread(ri);
t1.start();
}
} 线程的五种状态及其转换
线程的状态转换是线程控制的基础。线程状态总的可以分为五大状态。分别为:
- 新建:线程对象已经创建,还没有在其上调用start()方法。
- 就绪:当线程有资格运行,但调度程序还没有把它选定为运行线程时线程所处的状态。当start()方法调用时,线程首先进入可运行状态。在线程运行之后或者从阻塞、等待或睡眠状态回来后,也返回到可运行状态。
- 运行:线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。
- 等待:这是线程有资格运行时它所处的状态。此时线程仍旧是活的,但是当前没有条件运行。换句话说,它是可运行的,但是如果某件事件出现,他可能返回到可运行状态。
- 死亡:当线程的run()方法完成时就认为它死去。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。如果在一个死去的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
线程的方法及同步问题
睡眠Thread.sleep()
Thread.sleep(longmillis)和Thread.sleep(long millis, int nanos)静态方法强制当前正在执行的线程休眠(暂停执行),以“减慢线程”。当线程睡眠时,它入睡在某个地方,在苏醒之前不会返回到可运行状态。当睡眠时间到期,则返回到可运行状态。
try {
Thread.sleep(1000); //也就是1秒
} catch (InterruptedException e) {
e.printStackTrace();
} 注意:睡眠的位置:为了让其他线程有机会执行,可以将Thread.sleep()的调用放线程run()之内。这样才能保证该线程执行过程中会睡眠。
线程让步yield()
线程的让步是通过Thread.yield()来实现的。yield()方法的作用是:暂停当前正在执行的线程对象,并执行其他线程。 yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
线程加入join()
保证当前线程停止执行,直到该线程所加入的线程完成为止。然而,如果它加入的线程没有存活,则当前线程不需要停止。比如,一个线程B“加入”到另外一个线程A的尾部。在A执行完毕之前,B不能工作。
线程中断interrupt()
中断某个线程,这种结束方式比较粗暴,如果t线程打开了某个资源还没来得及关闭也就是run方法还没有执行完就强制结束线程,会导致资源无法关闭
注意:另外还有wait(),notify()等多个方法。暂不介绍,后续会给一篇学习的好文。
线程同步(解决死锁问题)
此概念主要解决多线程操作中的死锁问题,及确定同一时间只有一个线程在执行操作,主要又两种实现方式,一是同步代码块,及锁在run方法中,二是同步方法,及把synchronized当作函数修饰符。
1.同步代码块
public void run() {
try {
Thread.sleep(1000);
synchronized (this) { //此方式解决锁问题
...
}
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} 2.同步方法
Public synchronized void method(){//此方式解决锁问题
...
}对于以上基础,不在多余介绍。
推荐两篇学习好文:
http://www.mamicode.com/info-detail-517008.html
http://blog.csdn.net/cuigx1991/article/details/48219741
向下会总结线程池及在android工作中对于线程方面的使用问题
线程池的简介及好处
多线程开发中,由于线程数量多,并且每个线程执行一段时间就结束,所以要频繁的创建线程,但是这样频繁的创建线程会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。在这种情况下,人们就想要一种可以线程执行完后不用销毁,同时该线程还可以去执行其他任务,在这样的情况下线程池就出现了。在线程池的编程模式下,任务是提交给整个线程池,而不是直接交给某个线程,线程池在拿到任务后,它就在内部找有无空闲的线程,再把任务交给内部某个空闲的线程,如果没有空闲的进程,任务就处于等待状态,这就是封装。使用了线程池后减少了创建和销毁线程的次数,每个线程都可以被重复利用,可执行多个任务;同时可以根据系统的承受能力,调整线程池中线程的数目,避免出现将系统内存消耗完毕这样的情况出现。
总结来说,他的好处有以下三个方面:
- 降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗
- 提高响应速度:任务到达时不需要等待线程创建就可以立即执行。
- .提高线程的可管理性:线程池可以统一管理、分配、调优和监控。
线程池详解
java的线程池支持主要通过ThreadPoolExecutor来实现,我们使用的ExecutorService的各种线程池策略都是基于ThreadPoolExecutor实现的,所以ThreadPoolExecutor十分重要。
此继承关系如下:继承关系: Executor -> ExecutorService -> AbstractExecutorService -> ThreadPoolExecutor
从ThreadPoolExecutor源码认识其创建:
public class ThreadPoolExecutor extends AbstractExecutorService {
...//注释省略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
...//注释省略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
...//注释省略
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
...//注释省略 最全
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} 参数介绍:
corePoolSize- 池中所保存的核心线程数,包括空闲线程,默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
maximumPoolSize -池中允许的最大线程数。
keepAliveTime- 当线程数大于核心数时,线程没有任务执行时最多保持多久时间就会终止,默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用;如果线程池中的线程数小于corePoolSize,一个线程空闲的时间达到keepAliveTime,就会终止
unit -参数keepAliveTime的时间单位,在TimeUnit类中有有七种静态属性:
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
workQueue- 执行前用于保持任务的队列,也就是用来存储等待执行的任务。此队列仅保持由 execute 方法提交的 Runnable 任务。一般我们也称它为阻塞队列,这个参数的选择也很重要,会对线程池的运行过程产生重大影响。
threadFactory -执行程序创建新线程时使用的工厂;
handler -由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序,常见有以下几种:
ThreadPoolExecutor.AbortPolicy:放弃任务抛异常。
ThreadPoolExecutor.DiscardPolicy:放弃任务不抛异常。
ThreadPoolExecutor.DiscardOldestPolicy:放弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:调用线程处理该任务
线程池的创建
JDK中,java.util.concurrent.Executors类,提供了创建四种线程池的方法。(你会发现,RxJava中使用的也是这几种线程池,这部分源码会在后面讲解,我们先了解一下)
newFixedThreadPool
newFixedThreadPool,用来创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。定长线程池的大小通常根据系统资源进行设置:Runtime.getRuntime().availableProcessors()。
public class NewFixedThreadPoolTest {
public static void main(String[] args) {
// 创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); //也可自己指定大小
// 创建线程 Runtime.getRuntime().availableProcessors()的个数 我这写三个
Thread t1 = new MyThread();
Thread t2 = new MyThread();
Thread t3 = new MyThread();
// 将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
// 关闭线程池
pool.shutdown();
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println( "正在执行"+Thread.currentThread().getName());
}
} newScheduledThreadPool
newScheduledThreadPool来创建一个定长线程池,并且支持定时和周期性的执行任务(其余代码同第一条)
//定时执行
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(20); // 长度20
scheduledThreadPool.schedule(task, 10, TimeUnit.SECONDS); // 延迟10s执行
//周期性执行
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(20); // 长度20
scheduledThreadPool.scheduleAtFixedRate(task,10, 5, TimeUnit.SECONDS); // 延迟10s执行,每个5s执行一次。 newCachedThreadPool
newCachedThreadPool用来创建一个可缓存线程池,该线程池没有长度限制,对于新的任务,如果有空闲的线程,则使用空闲的线程执行,如果没有,则新建一个线程来执行任务。如果线程池长度超过处理需要,可灵活回收空闲线程。
//其余同第一条
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
newSingleThreadExecutor
SingleThreadExecutor模式只会创建一个线程。它和FixedThreadPool比较类似,不过线程数是一个。如果多个任务被提交给SingleThreadExecutor的话,那么这些任务会被保存在一个队列中,并且会按照任务提交的顺序,一个先执行完成再执行另外一个线程。
SingleThreadExecutor模式可以保证只有一个任务会被执行。这种特点可以被用来处理共享资源的问题.
//其余同第一条
ExecutorService pool = Executors.newSingleThreadExecutor();自定义线程池
当然我们也可以自定义线程池,说实话,我没用过,还请自行百度。嘿嘿。我这只说明这是可以的。
多线程操作之Handler
handler的优缺点:handler对于对后台任务时,简单清晰,但是handler对于操作单个后台任务,代码过于繁琐。
对于handler的使用操作,我不想多说了,其实就是在主线程中创建Handler对象并实现handlmessage()方法,创建runnable线程,先在线程中执行耗时操作,开启一个线程会相应的产生一个looper,在初始化looper的时候会创建一个消息队列MessageQueue();执行完耗时操作,通过handler将消息发送到消息队列中、、looper轮询消息队列将消息取出来交给Handler,Handler接收到取出来的消息,并根据消息类型做出相应的处理。
下面我会说一些自己对handle对于源码的理解,有不对还请指出:
弄清楚handler,就要弄清楚这四个东西,handler Message Looper MessageQueue。
首先,我们从Looper 轮询器和MessageQueue的创建说起:
先声明下,主线程的Looper不需要程序员创建的,系统会创建,通过prepareMainLooper()->Looper.Prepare(); 然后会通过一个threadLocal(线程单例,一个线程就有一个对象) 把Looper对象和当前线程建立起一一对应的关系。Looper.Prepare()会调用Looper的private构造方法 并且把创建的looper对象保存到threadLocal中。在Looper构造中会创建一个MessageQueue对象 并且通过一个final类型的成员变量把MessageQueue保存起来。这样确保一个Looper对应唯一的messageQueue。所以 一个线程最多只能有一个looper, 一个looper对应唯一的MessageQueueu 也就是一个线程有唯一的Looper唯一的messageQueue。
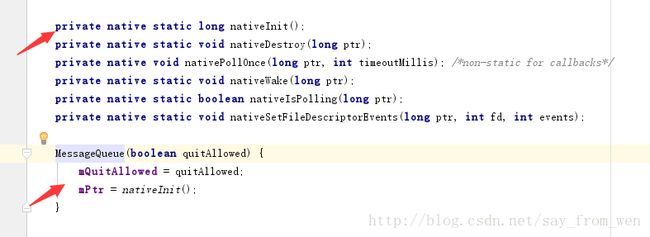
MessageQueue在创建的过程中会调用nativeInit方法 创建出一个nativeMessageQueue,创建NativeMessaageQueue的时候还会创建一个C++的Looper,java层的MessageQueue和NativeMessageQueue通过一个成员变量mPtr建立起关联 mPtr保存了nativeMessageQueue的指针。
说了这么多,是时候看一眼源码了,请对应上述描述一起观看。
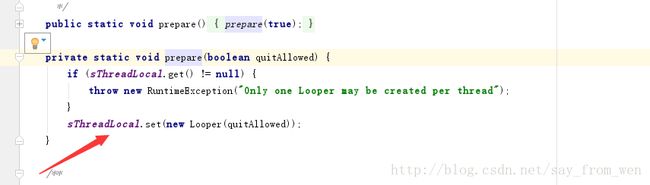
Looper.prepareMainLooper(),他会调用prepare方法:

Looper.prepare():创建的looper对象保存到threadLocal
MessageQueue和NativeMessageQueue的创建:

需要注意 如果在主线程中调用Looper.prepareMainLooper或者Looper.prepare() 程序会抛出异常。
Looper.loop让消息循环
Looper取消息的代码中,有一个死循环,需要理解为什么要有死循环?死循环为什么不会阻塞主线程?
看一下loop源码,里面有一个for循环。那么先来解释下再看源码吧,对于主线程,也就是我们的android程序,我们是绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出,例如,binder线程也是采用死循环的方法,通过循环方式不同与Binder驱动进行读写操作,当然并非简单地死循环,无消息时会休眠。
对于不会阻塞主线程的问题?
真正会卡死主线程的操作是在回调方法onCreate/onStart/onResume等操作时间过长,会导致掉帧,甚至发生ANR,looper.loop本身不会导致应用卡死。这里会涉及到linux中一个管道(pipe)的概念。他的原理:在内存中有一个特殊的文件,这个文件有两个句柄(引用),一个是读取句柄,一个是写入句柄。原因简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里(下面源码中会有标记),此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源,也不会造成主线程的阻塞。
public static void loop() {
6. final Looper me = myLooper();
7. if (me == null) {
8. throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
9. }
10. final MessageQueue queue = me.mQueue;
11.
12. // Make sure the identity of this thread is that of the local process,
13. // and keep track of what that identity token actually is.
14. Binder.clearCallingIdentity();
15. final long ident = Binder.clearCallingIdentity();
16.
17. for (;;) {
18. Message msg = queue.next(); // might block 可能会阻塞 就是到消息队列中取出下一条消息
19. if (msg == null) {
20. // No message indicates that the message queue is quitting.
21. return;
22. }
23.
24. // This must be in a local variable, in case a UI event sets the logger
25. Printer logging = me.mLogging;
26. if (logging != null) {
27. logging.println(">>>>> Dispatching to " + msg.target + " " +
28. msg.callback + ": " + msg.what);
29. }
30.
31. msg.target.dispatchMessage(msg);
32.
33. if (logging != null) {
34. logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
35. }
36.
37. // Make sure that during the course of dispatching the
38. // identity of the thread wasn't corrupted.
39. final long newIdent = Binder.clearCallingIdentity();
40. if (ident != newIdent) {
41. Log.wtf(TAG, "Thread identity changed from 0x"
42. + Long.toHexString(ident) + " to 0x"
43. + Long.toHexString(newIdent) + " while dispatching to "
44. + msg.target.getClass().getName() + " "
45. + msg.callback + " what=" + msg.what);
46. }
47.
48. msg.recycle();
49. }
50. }
MessageQueue的next方法
final Message next() {
3. int pendingIdleHandlerCount = -1; // -1 only during first iteration
4. int nextPollTimeoutMillis = 0;
5.
6. for (;;) {
7. if (nextPollTimeoutMillis != 0) {
8. Binder.flushPendingCommands();
9. }
10. nativePollOnce(mPtr, nextPollTimeoutMillis);
11. //这里会阻塞 用到linux底层的pipe 和epoll机制 传入两个参数
11. //第一个参数 nativeMessageQueue的指针 第二个参数就是消息超时时间
12. // Linux的一个进程间通信机制:管道(pipe)。原理:在内存中有一个特殊的文件,这个文件有两个句柄(引用),一个是读取句柄,一个是写入句柄
13. synchronized (this) {
14. if (mQuiting) {
15. return null;
16. }
17.
18. // Try to retrieve the next message. Return if found.
19. final long now = SystemClock.uptimeMillis();
20. Message prevMsg = null;
21. Message msg = mMessages;
22. if (msg != null && msg.target == null) {
23. // Stalled by a barrier. Find the next asynchronous message in the queue.
24. do {
25. prevMsg = msg;
26. msg = msg.next;
27. } while (msg != null && !msg.isAsynchronous());
28. }
29. if (msg != null) {
30. if (now < msg.when) {
31. // Next message is not ready. Set a timeout to wake up when it is ready.
32. nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
33. } else {
34. // Got a message.
35. mBlocked = false;
36. if (prevMsg != null) {
37. prevMsg.next = msg.next;
38. } else {
39. mMessages = msg.next;
40. }
41. msg.next = null;
42. if (false) Log.v("MessageQueue", "Returning message: " + msg);
43. msg.markInUse();
44. return msg;
45. }
46. } else {
47. // No more messages.
48. nextPollTimeoutMillis = -1;
49. }
50.
51. // If first time idle, then get the number of idlers to run.
52. // Idle handles only run if the queue is empty or if the first message
53. // in the queue (possibly a barrier) is due to be handled in the future.
54. if (pendingIdleHandlerCount < 0
55. && (mMessages == null || now < mMessages.when)) {
56. pendingIdleHandlerCount = mIdleHandlers.size();
57. }
58. if (pendingIdleHandlerCount <= 0) {
59. // No idle handlers to run. Loop and wait some more.
60. mBlocked = true;
61. continue;
62. }
63.
64. if (mPendingIdleHandlers == null) {
65. mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
66. }
67. mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
68. }
69.
70. // Run the idle handlers.
71. // We only ever reach this code block during the first iteration.
72. for (int i = 0; i < pendingIdleHandlerCount; i++) {
73. final IdleHandler idler = mPendingIdleHandlers[i];
74. mPendingIdleHandlers[i] = null; // release the reference to the handler
75.
76. boolean keep = false;
77. try {
78. keep = idler.queueIdle();
79. } catch (Throwable t) {
80. Log.wtf("MessageQueue", "IdleHandler threw exception", t);
81. }
82.
83. if (!keep) {
84. synchronized (this) {
85. mIdleHandlers.remove(idler);
86. }
87. }
88. }
89.
90. // Reset the idle handler count to 0 so we do not run them again.
91. pendingIdleHandlerCount = 0;
92.
93. // While calling an idle handler, a new message could have been delivered
94. // so go back and look again for a pending message without waiting.
95. nextPollTimeoutMillis = 0;
96. }
97. }
通过handler处理消息
msg.target.dispatchMessage();msg的callback是一个runnable对象 如果msg的callback不为空,消息交给这个callback处理.
如果msg的callback为空,则判断handler的mCallback接口,这个接口中就一个方法handleMessage。如果这个callback不为空交给这个handleMessage处理
如果上面两个都为空才交给handler的handleMessage处理消息(也就是我们在代码中写的方法)
/**
2. * Handle system messages here.
3. */
4. public void dispatchMessage(Message msg) {
5. if (msg.callback != null) {
6. handleCallback(msg);
7. } else {
8. if (mCallback != null) {
9. if (mCallback.handleMessage(msg)) {
10. return;
11. }
12. }
13. handleMessage(msg);
14. }
15. }
handler的创建
public Handler(Callback callback, boolean async) {
2. if (FIND_POTENTIAL_LEAKS) {
3. final Class extends Handler> klass = getClass();
4. if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()&&(klass.getModifiers() & Modifier.STATIC) == 0) {
7. klass.getCanonicalName());
8. }
9. }
10.
11. mLooper = Looper.myLooper();
12. if (mLooper == null) {
13. throw new RuntimeException(
14. "Can't create handler inside thread that has not called Looper.prepare()");
15. }
16. mQueue = mLooper.mQueue;
17. mCallback = callback;
18. mAsynchronous = async;
19. }
创建handler的时候 先到当前的线程中获取looper 如果当前线程没有looper的话那么会抛异常。
如果当前线程以经创建了looper那么把这个Looper保存到一个final类型的成员变量中 通过这个Looper找到对应的messageQueue,通过final成员变量保存这个MessageQueue 这样 确保在哪个线程创建的handler消息会发送到对应线程的MessageQueue中,如果在子线程中使用handler 必须先调用Looper.prepare();再创建handler Looper.Loop()让消息队列循环起来。子线程中使用消息机制可以重复利用线程 。
通过handler发送消息
handler发送消息 sendMessage sendEmptyMessage… 实际上都是调用 sendMessageAtTime这个方法
sendMessageAtTime调用了enqueueMessage这个方法 这个方法实际上就是把消息放到消息队列的过程
1. private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
2. msg.target = this;
3. if (mAsynchronous) {
4. msg.setAsynchronous(true);
5. }
6. return queue.enqueueMessage(msg, uptimeMillis);
7. }
消息队列 enqueueMessage
1.
2. final boolean enqueueMessage(Message msg, long when) {
3. if (msg.isInUse()) {
4. throw new AndroidRuntimeException(msg + " This message is already in use.");
5. }
6. if (msg.target == null) {
7. throw new AndroidRuntimeException("Message must have a target.");
8. }
9.
10. boolean needWake;
11. synchronized (this) {
12. if (mQuiting) {
13. RuntimeException e = new RuntimeException(
14. msg.target + " sending message to a Handler on a dead thread");
15. Log.w("MessageQueue", e.getMessage(), e);
16. return false;
17. }
18.
19. msg.when = when; //重要
20. Message p = mMessages;
21. //msg.next 重要
21. if (p == null || when == 0 || when < p.when) {
22. // New head, wake up the event queue if blocked.
23. msg.next = p;
24. mMessages = msg;
25. needWake = mBlocked;
26. } else {
27. // Inserted within the middle of the queue. Usually we don't have to wake
28. // up the event queue unless there is a barrier at the head of the queue
29. // and the message is the earliest asynchronous message in the queue.
30. needWake = mBlocked && p.target == null && msg.isAsynchronous();
31. Message prev;
32. for (;;) {
33. prev = p;
34. p = p.next;
35. if (p == null || when < p.when) {
36. break;
37. }
38. if (needWake && p.isAsynchronous()) {
39. needWake = false;
40. }
41. }
42. msg.next = p; // invariant: p == prev.next
43. prev.next = msg;
44. }
45. }
46. if (needWake) {
47. nativeWake(mPtr);
48. }
49. return true;
50. }
消息如何在消息队列中排序?
上面源码中我标记了两个重要的注释,他们决定了这个问题。
实际上Messagequeue通过 一个成员变量 mMessage保存了消息队列的第一条消息 消息在消息队列中的排序是根据消息要执行的时间(就是when)先后顺序进行排序,先执行的消息排在前面 下一条消息通过message的next属性进行保存 。
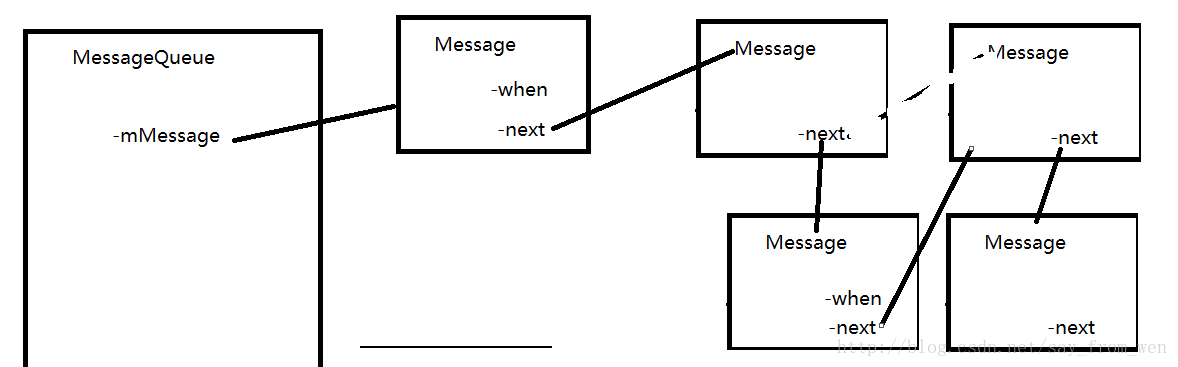
enqueueMessage 就是根据新加入进来的消息 要执行的时间跟已有的消息进行比较找到合适的位置放到消息队列中。如果消息需要立即执行,会执行nativeWake,实际上就是向管道中写了一个w,那么messageQueue的next方法就不会阻塞可以取出消息。
//没错 就这两行代码
if (needWake) {
nativeWake(mPtr);
}
最后,讲一下message(消息)的创建和回收
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;//从消息池中取出第一条消息
sPool = m.next; //把当前消息池的第二条消息作为消息池的第一条
m.next = null;//要去除的消息的下一条置null
sPoolSize--;//消息池大小-1
return m;//把这条消息返回去
}
}
return new Message();
}
如果使用obtain方法来获取消息 那么就会利用到android的消息池 注意这个消息池是全局的 消息池的大小50条
消息的回收 在Looper.loop()方法中 当Handler处理消息之后 会调用message.recycle()方法回收消息
public void recycle() {
clearForRecycle();//把要回收的消息 所有的成员变量恢复到刚new出来的状态
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {//把这条消息放到消息池的第一条消息
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
void clearForRecycle() {
flags = 0;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
when = 0;
target = null;
callback = null;
data = null;
}到这里handler就说完了,感觉写的好乱啊,不过凑活看吧,应该是可以看明白的,是吗?请疯狂call 1。
多线程操作之AsyncTask
AsyncTask的优缺点:AsyncTask操作简单方便,过程可控,但是AsyncTask对于多异步操作更新UI会变得很繁琐。
对于使用代码,本文不提,如想使用,请自行百度。只讲下具体操作,onPreExecute()运行在主线程中,开启线程前的准备操作,doInBackground()运行在子线程中,onPreExecute()之后的操作,用于处理耗时操作,通过调用publishProcess()向 onProcessUpdata()推送消息,onProcessUpdata()运行在主线程中,当调用 publishProcess()方法时就会开启此方法,接收到推送过来的数据,更新UI进度页面
onPostExecute()运行在主线程中,当子线程耗时操作执行完毕后会调用此方法, doInBackground()返回的参数传递到这里来用于更新UI。调用execute()方法开启AsyncTask,类似runnable的start()方法
下面我会说一些自己对AsyncTask对于源码的理解,有不对还请指出:
看了源码才知道,真心的,AsyncTask实际上就是对handler的封装。只是用到了线程池。说真的,不想写了,你会看到,他的方法中全是通过Handler 做的一些操作。具体的还请自行观看,如果您理解了handler,这个也就理解了。
private static Handler getHandler() {
synchronized (AsyncTask.class) {
if (sHandler == null) {
sHandler = new InternalHandler();
}
return sHandler;
}
}但是会说一下他的线程池SerialExecutor。可以看到,SerialExecutor是使用ArrayDeque这个队列来管理Runnable对象的,如果我们一次性启动了很多个任务,首先在第一次运行execute()方法的时候,会调用ArrayDeque的offer()方法将传入的Runnable对象添加到队列的尾部,然后判断mActive对象是不是等于null,第一次运行当然是等于null了,于是会调用scheduleNext()方法。在这个方法中会从队列的头部取值,并赋值给mActive对象,然后调用THREAD_POOL_EXECUTOR去执行取出的取出的Runnable对象。之后如何又有新的任务被执行,同样还会调用offer()方法将传入的Runnable添加到队列的尾部,但是再去给mActive对象做非空检查的时候就会发现mActive对象已经不再是null了,于是就不会再调用scheduleNext()方法。
那么后面添加的任务岂不是永远得不到处理了?当然不是,看一看offer()方法里传入的Runnable匿名类,这里使用了一个try finally代码块,并在finally中调用了scheduleNext()方法,保证无论发生什么情况,这个方法都会被调用。也就是说,每次当一个任务执行完毕后,下一个任务才会得到执行,SerialExecutor模仿的是单一线程池的效果,如果我们快速地启动了很多任务,同一时刻只会有一个线程正在执行,其余的均处于等待状态。
private static class SerialExecutor implements Executor {
final ArrayDeque mTasks = new ArrayDeque();
Runnable mActive;
public synchronized void execute(final Runnable r) {
mTasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (mActive == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((mActive = mTasks.poll()) != null) {
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
} 如何取消AsyncTask
AsyncTask.cancel(true);
1、如果是true,如果线程执行,则会被打断
2、如果是false,线程将会被运行执行完成
执行这个方法实际上并没有结束掉我们想要结束的异步任务~
cancel的作用:AsyncTask不会不考虑结果而直接结束一个线程。调用cancel()其实是给AsyncTask设置一个”canceled”状态。这取决于你去检查AsyncTask是否已经取消,之后决定是否终止你的操作。对于mayInterruptIfRunning——它所作的只是向运行中的线程发出interrupt()调用。在这种情况下,你的线程是不可中断的,也就不会终止该线程。
真正结束代码:
@Override
public void onProgressUpdate(Integer... value) {
// 判断是否被取消
if(isCancelled()) return;
.........
}
@Override
protected Integer doInBackground(Void... mgs) {
// Task被取消了,马上退出
if(isCancelled()) return null;
.......
// Task被取消了,马上退出
if(isCancelled()) return null;
}
...多线程操作之IntentService
IntentService和普通的Service区别在于,IntentService在oncreate()方法中单独开启一个线程用于耗时操作,通过onHandleIntent(Intent intent)方法来处理耗时操作,在耗时操作执行完毕之后,会自动关闭service不用手动关闭。如果同时new出多个IntentService对象进行耗时操作,oncreate()和ondestory()方法会执行一次,onstart()、onstartcommand()、onHandleIntent()会执行多次。执行完毕自动关闭service。
IntentService的优先级比线程更高,因为它是一种服务,因而IntentService比较适合执行一些高优先级的后台任务。
但是IntentService在使用中是有局限性的:
- 不可以直接和UI做交互。为了把它执行的结果展现在UI上,需要将结果发送给Activity。
- 工作队列是顺序执行的,如果一个任务正在IntentService中执行,此时再发送一个任务请求,这个任务会一直处于等待状态直到前面的任务执行完成。
- 正在执行的任务无法中断。
对于使用代码,本文不提,如想使用,请自行百度。
下面我会说一些自己对IntentService对于源码的理解,有不对还请指出:
首先分析OnCreate方法:IntentService内部封装了Handler(mServiceHandler)和HandlerThread,在onCreate方法中实例化了这两个变量。
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}在HandlerThread中的run方法创建Looper对象,因而mServiceLooper是从thread中获取Looper对象,并将其传给mServiceHandler.
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}在handleMessage方法中会执行onHandleIntent方法(处理耗时操作),执行完后悔调用stopSelf(msg.arg1),当所有任务处理完后,IntentService会自动停止。
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
/**
* Old version of {@link #stopSelfResult} that doesn't return a result.
* @see #stopSelfResult
*/
public final void stopSelf(int startId) {
if (mActivityManager == null) {
return;
}
try {
mActivityManager.stopServiceToken(
new ComponentName(this, mClassName), mToken, startId);
} catch (RemoteException ex) {
}
}每次启动IntentService时都会调用onStartCommand方法,而进一步执行onStart方法。而在onStart方法中主要是使用mServiceHandler发送消息,将任务消息发送给消息队列,进而Handler来处理消息,处理消息的时候是在HandlerThread线程当中执行的,其实也就是说onHandleIntent就是在HandlerThread线程中执行的。
每次启动一个IntentService,就发送一个任务来处理,所有的任务会按照一定启动的顺序来执行处理。
public int onStartCommand(Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
public void onStart(Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}至于service中得到的结果你如何发送给activty,我就不管了,N中方法你都可以做到,具体的来根据你的业务来定。
写在最后
对于RxJava Schedulers源码分析的部分,个人感觉会写的长一点,导致本文过长。故文章分为了两部分,具体还请看下一篇文章。 我的android多线程编程之路(2)之RxJava Schedulers源码分析。谢谢提建议,关注,一起进步!