mysql日志文件bin-log,redo-log,undo-log总结
mysql作为数据存储的工具,需要应对非常多的场景。例如主从复制,事务,数据恢复等都是需要的功能。
bin log(二进制日志)
二进制日志记录了数据库所有的更新操作,以事件形式记录所做的逻辑操作。binlog 的主要目的是主从复制和数据恢复。
binlog的格式 MySQL Binlog解析
①Statement:每一条会修改数据的sql都会记录在binlog中。
- 优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
- 缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同的结果。因为像触发器或者存储过程在主从复制的时候可能会导致sql执行结构不一致。
*note:*相比row能节约性能与日志量,不过能节省多少取决于SQL情况,正常情况下同一条记录修改或者插入row格式所产生的日志量小于Statement产生的日志量;但是考虑到如果带条件的update操作,以及整表删除,alter表等操作,row格式会产生大量日志,因此在考虑是否使用row格式日志时应该跟据应用的实际情况,其所产生的日志量会增加多少,以及带来的IO性能问题。
②Row:不记录sql语句,仅保存哪条记录被修改。
- 优点: binlog中可以不记录执行的sql语句的信息,仅需要记录哪一条记录被修改成什么了。所以row格式的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现主从复制时的存储过程,函数,以及触发器的执行无法被正确复制的问题。
- 缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
*note:*新版本的MySQL中对row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
③Mixed:从5.1.8版本开始提供了Mixed格式,实际上就是Statement与Row的结合。
*note:*在Mixed模式下,一般的语句修改使用statment格式保存binlog。但是像一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
binlog的拓展
binglog的生成时机:
①MySQL服务器停止或重启时,MySQL会在重启时生成一个新的日志文件;
②使用flush logs命令;
③当binlog文件大小超过max_binlog_size系统变量配置的上限时;需要注意的是,该设置并不能严格控制binlog的大小,尤其是mysql执行一个比较大事务时,为了保证事务的完整性,不会做日志切换工作,只能将该事务的所有sql都记录到当前日志,所以可能会出现二进制文件大小大于max_binlog_size。
binlog的常用命令 详细分析MySQL的日志
查看是否开启了binglog
show variables like ‘log_bin’;查看及设置binlog的结构方式
show variables like ‘binlog_format’
set globle binlog_format='MIXED’查看binlog在服务器上日志信息
show {binary | master} logs查看当前正在写入的binlog文件
show master status;
查看binlog上的事件
show binlog events;
查看指定binlog文件上的事件(文件名是show {binary | master} logs中的信息)
show binlog events in ‘binlog.000001’;
删除所有日志,并让日志文件重新从000001开始
reset master;
删除指定日期以前的日志索引中binlog日志文件
purge master logs before ‘2012-03-30 17:20:00’;
删除指定日志文件的日志索引中binlog日志文件
purge master logs to ‘mysql-bin.000002’;
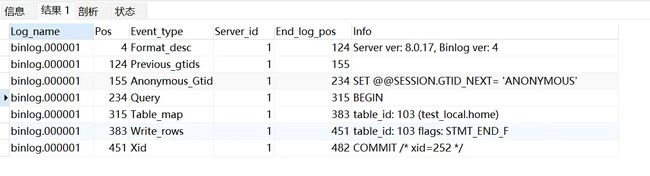
mysqlbinlog查看二进制文件信息
binlog文件是以事件(event)方式记录sql的,所以使用文件中存在多个event
①可以使用mysqlbinlog工具查看。以下插入并更新一条数据
如果是windows使用 mysqlbinlog --no-defaults binlog.000001;
如果是linux先执行 *show variables like ‘log_%’;*得到binlog的位置,然后直接使用命令 mysqlbinlog binlog.000001 查看文件
截取其中的一段:
# at 318 #211125 22:57:17 server id 1 end_log_pos 380 CRC32 0x9d439cb5 Table_map: `test`.`users` mapped to number 132 # at 380 #211125 22:57:17 server id 1 end_log_pos 432 CRC32 0x32c17723 Write_rows: table id 132 flags: STMT_END_F BINLOG ' TaSfYRMBAAAAPgAAAHwBAAAAAIQAAAAAAAEABHRlc3QABXVzZXJz>AAQDDwMRA/wDAA4BAQACA/z/ ALWcQ50= TaSfYR4BAAAANAAAALABAAAAAIQAAAAAAAEAAgAE/wABAAAAAgBh>YRUAAABhn6RNI3fBMg== '/*!*/;# at 318:说明该事件记录从文件第318个字节开始
#211125 22:57:17: 事件发生的时间戳
error_code: 错误码
server id 1: 服务器标识
end_log_pos 380:此片段在哪个字节结束,同时也是下一个片段开始的位置(# at 380)
CRC32 0x9d439cb5 CRC校验码
此外还有exec_time: 事件执行的时间,thread_id: 代理线程id,type:事件类型Query②可以使用上面的how binlog events in ‘binlog.000001’;命令查看
4-125是binlog描述信息(包括服务器版本,数据库版本,binlog版本),125-156是空白部分
接下来分别是设置事务、BEGIN、找表(test.users)、row变化、提交事务pos,End_log_pos是event在文件中的开始和结束,对应上面的# at 318,
event_type可以分为多种情况MySQL Binlog事件类型
如何使用binlog完成回滚操作 使用binlog完成回滚
前提:需要先打开binlog日志才能使用binlog完成回滚操作
完成回滚需要使用binlog2sql.py,所以也需要安装git,python和pip工具
1.首先安装binlog2sql.py,然后进入目录,安装依赖git clone https://github.com/danfengcao/binlog2sql.git cd binlog2sql pip install -r requirements.txt2.接着执行一条更新sql语句,然后使用*show master status;*查看当前正在写的日志,接着执行 binlog2sql/binlog2sql.py
update user set name='aa' where id<3;//更新语句 show master status; python binlog2sql/binlog2sql.py -h127.0.0.1 -p3306 -uroot -p123456 -dtest -tuser --start-file='binlog.000001'其中-d是数据库,-t是表名,–start-file是指sql写入哪个文件,执行完成后就会出现这个文件中已经执行过的变更操作:#start 6351 end 6744 time 2021-12-05 21:54:42分别代表改更新操作在binlog中的开始和结束字节。与上图中的pos和End_log_pos相对应。
3.然后找出需要回滚sql的开始和结束字节。生成回滚sql:python binlog2sql/binlog2sql.py -h127.0.0.1 -p3306 -uroot -p123456 -dtest -tuser --start-file='binlog.000001' --start-pos=3346 --end-pos=3556 -B
4.最后执行回滚操作,就回滚到之前的数据库了
python binlog2sql.py -h127.0.0.1 -p3306 -uroot -p123456 -dtest -tuser --start-file='binlog.000001' --start-pos=3346 --end-pos=3556 -B | mysql -h127.0.0.1 -p3306 -uroot -p123456
redo log(重做日志)
我们知道数据库事务需要包括acid(原子性,一致性,隔离性,持久性)的特性,但是如何完成这些特性?隔离性是通过数据库的锁机制来实现mysql的事务与锁。而事务的持久性则是通过redolog来完成的。持久性是指事务一旦提交那么事务的状态将一直保持。
缓冲池
数据库的数据是存储在磁盘上的,但是为了提高数据访问的效率,mysql设计了缓冲池。如果缓冲池有数据,就直接返回;如果缓冲池没有数据就先从磁盘读出来再返回。 这样做的好处是利用了缓存提高了效率,但是也带来了问题,就是如果更新数据,mysql也只会更新缓冲池中的数据(即将脏数据刷新到到内核中的页缓存)至于什么时候刷新到磁盘,就需要页缓存的执行时机了。
这样做的好处是利用了缓存提高了效率,但是也带来了问题,就是如果更新数据,mysql也只会更新缓冲池中的数据(即将脏数据刷新到到内核中的页缓存)至于什么时候刷新到磁盘,就需要页缓存的执行时机了。
这个时候如果事务提交之后没有,缓冲池中的内容已经更新成新数据,但是在刷新到磁盘的时候就宕机了,这个时候怎么办?
这个时候redo log就派上用场了,redo log就是用来解决前滚问题的(即事务已提交,但是没有刷新到磁盘时挂了,如何保证已提交事务的持久性)
redo log简介
在mysql中,缓冲池中的数据都是以页为单位的进行读写的(包括数据页,以及之前说过的索引页),而redo log就是记录物理页变化的日志文件,形如,XX表空间+XX偏移量写入了“XX”数据。redo log和bin log都是记录的更新操作,但是redo log记录的不是逻辑变化,而是物理页变化。redo log buffer是事务日志在内存中的空间,redo log file才是事务日志在磁盘上的空间。
那么redo log是如何保证事务的持久性?
redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool。
在更新成新数据之前,mysql会先将事务中所涉及的页变化记录到redo log buffer中,然后redo log buffer会根据一定的条件将日志记录刷新到redo log file中。接着才进行更新数据页的操作,这样保证了即使脏页没有刷新到磁盘时宕机了,但是还可以通过redo log file中的日志来恢复。
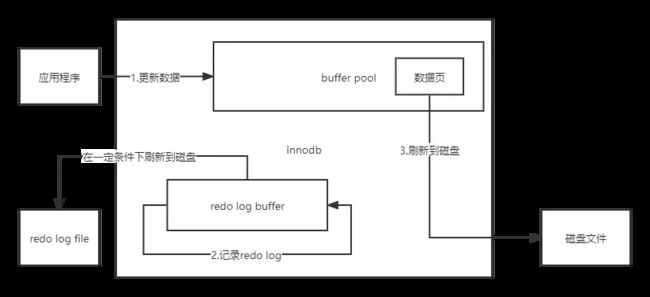
redo log与binlog的区别:redo log记录的是数据页的操作,binlog记录的逻辑操作,所以redo log具有幂等性。比如一个数据页在insert一条记录后又delete了一条记录,在redo log看来数据页没有变化,所以不用记录。而binlog则需要记录所有的操作,而且redo log属于顺序io。
binlog是在存储引擎的上层产生的,不管是什么存储引擎,对数据库进行了修改都会产生二进制日志。而redo log是innodb层产生的,只记录该存储引擎中表的修改。所以相比之下,redo log恢复数据的速度更快。
可能会有问题,既然redo log也需要从内存刷新到磁盘,那么不是也存在刷新到磁盘时mysql宕机的情况吗,既然这样,为什么不直接将脏页刷新到磁盘,略过redo log?这是因为:
- ①刷脏页是随机IO,每次修改的数据位置随机,会增加磁盘寻址的时间消耗。但redo log是以追加操作写入磁盘,属于顺序IO,速度更快。
- ②刷脏页是以页(大小是16KB)为单位的,一个页上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
- ③redo log buffer写入磁盘都是以扇区为单位,保证每次写入都能成功。所以不存在像脏页那样刷新到磁盘的过程中失败的情况。
如果redo log还没有刷新到磁盘的时候就宕机了该怎么办?
如果这个时候脏页还没有更新到磁盘,那么即使宕机也没有影响,因为日志和数据都没有刷新到磁盘,相当于失败了。redo log刷新到磁盘的时间要早于脏页刷新到磁盘的时候,所以不存在脏页刷新到磁盘,而redo log还在内存中的情况。
######redo log 写入磁盘的时机MySQL中的 redo 日志文件
redo log buffer写入磁盘的时机包括事务提交时和未提交阶段两种情况:我们知道内存中的数据写入磁盘是包括两个阶段,先将数据写入到内核中页缓存,然后页缓存不定时刷新到磁盘。
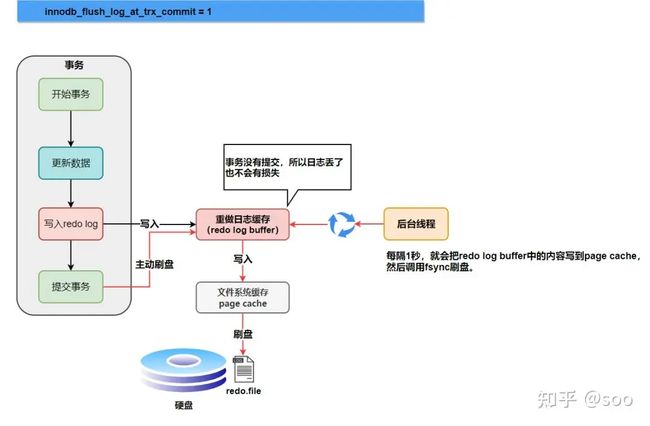
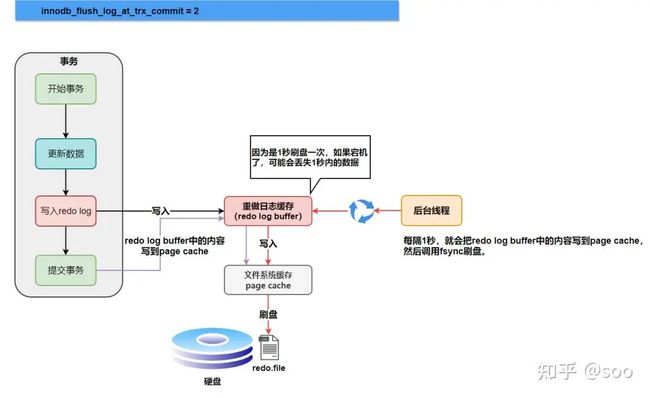
①innodb_flush_log_at_trx_commit 参数是事务提交时redo log buffer刷新到磁盘的时机。参数值包括0, 1, 2
- 0:不做处理,从后面可知后台 master 线程会周期性任务刷新
- 1:在事务提交时 redo log buffer 同步写入 disk。在将redo log写入到页缓存时会伴随 fsync 调用强制刷新到磁盘
- 2:将 redo log 日志数据页缓存中,所以在事务成功提交后并不能保证 redo log 数据一定存储到磁盘上了
②事务执行期间,redo log buffer以下情况也会刷新到磁盘:
- master 线程(也就是上面的后台线程)周期性任务每秒一次,调用fsync将 redo log buffer 强制刷新到磁盘。
- 当redo log buffer剩余空间小于1/2时(innodb_log_buffer_size参数),将 redo log buffer 刷新到磁盘
- 当 redo log file 大小已经达到某个域值时(日志文件组轮流写文件),触发 async/sync flush checkpoint,及时将一些脏页刷新到磁盘,并同时将redo log buffer刷新到磁盘,然后更新redo log file 相应的 log sequence number值。
######checkpoint 关于checkpoint机制
redo log file可以执行前滚操作,恢复已经提交但是没有同步到磁盘的数据,但是有个问题?数据文件从哪里开始恢复,从头开始恢复的话就太傻了,而且还需要redo log file有足够大的空间来保存日志。所以需要为已经刷新到磁盘的数据打个结点,即结点之前的数据已经保存到磁盘上了,只需要恢复结点之后的数据。这个机制就是checkpoint。
checkpoint 的目的:1、缩短数据库的恢复时间;2、缓冲池不够用时,将脏页刷新到磁盘;3、重做日志不可用时,刷新脏页。
对于InnoDB存储引擎而言,是通过LSN(Log Sequence Number)来标记版本的。LSN是8字节的数字,每个页有LSN,重做日志中也有LSN,Checkpoint也有LSN。可以通过命令show engine innodb status;来查看,其中有四个比较主要的lsn:show engine innodb status; LOG --- Log sequence number 53248280//内存中数据页的lsn Log flushed up to 53248280//刷新到redo log file中的lsn Pages flushed up to 53248280//刷新到磁盘的数据页的lsn Last checkpoint at 53248280//上一次检查点所在位置的lsn按照更新数据的流程可知,先更新内存数据,接着更新redo log buffer,几乎同时redo log刷新到redo log file,接着脏页刷盘到磁盘,最后更新打结点。所以四者是依次递减的关系。
有了checkpoint机制,redo log恢复数据的完整流程就是:重启innodb时,checkpoint表示已经完整刷到磁盘上data page上的LSN,因此恢复时仅需要恢复从checkpoint开始的日志部分。例如,当数据库在上一次checkpoint的LSN为10000时宕机,且事务是已经提交过的状态。启动数据库时会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从检查点开始恢复。
######数据页刷盘机制
什么时候触发checkpoint?也就是脏页刷新。在InnoDB存储引擎内部,有两种Checkpoint,分别为:Sharp Checkpoint、Fuzzy Checkpoint
Sharp Checkpoint 发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,即参数innodb_fast_shutdown=1。但是若数据库在运行时也使用Sharp Checkpoint,那么数据库的可用性就会受到很大的影响。所以在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
①Master Thread Checkpoint
以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘。
②FLUSH_LRU_LIST Checkpoint
保证LRU列表中需要有足够的空闲页可供使用,如果不够则刷盘。innodb_lru_scan_depth控制LRU列表中可用页的数量
③async/sync flush checkpoint
指的是重做日志文件不可用的情况,这时需要强制将一些页刷新回磁盘。
硬盘上存储的redo log日志文件不只一个,而是以一个日志文件组的形式出现的。每个日志文件大小都相同。日志刷盘时,采用循环写入的方式(如左图)。日志文件组有两个比较重要的指针,分别是write pos(刷新到redo log file的lsn)和checkpoint(脏页已经刷新到磁盘的lsn)。
checkpoint->write pos之间的是已经记录到日志文件组,但是还没有刷新到磁盘的脏页数据。
write pos->checkpoint是可以写入redo log的部分。
当checkpoint->write pos之间记录超过一定阈值时,说明重做日志文件组容量不够了,需要触发脏页刷盘。之后checkpoint后移。
④Dirty Page too much
当buffer pool中脏页的数量太多时,会导致InnoDB引擎强制执行Checkpoint。其目的还是为了保证缓冲池中有足够可用的页。


如果脏页刷新到磁盘的过程中发生了宕机,数据怎么恢复?
例如一页大小为16k,如果刷新到4k时,数据库发生宕机怎么办。此时数据页部分有效,数据恢复时不能比较lsn了,因为数据页面本身是错误的。此时需要用到innodb的两次写MySQL两次写的
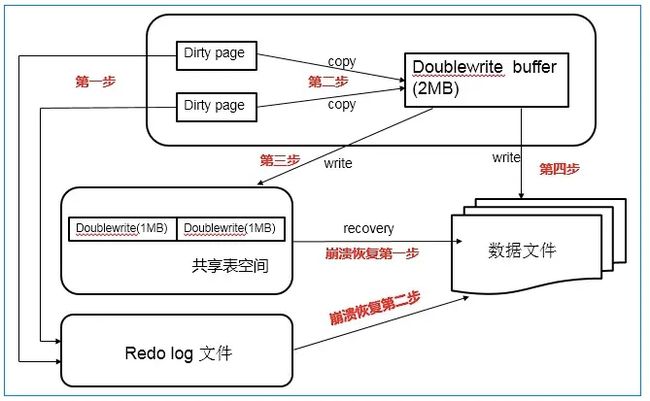
简单来说,就是在写数据页之前,先把这个脏页写到一块独立的物理文件位置,然后再刷新到磁盘。这样在宕机重启时,数据库会先检查页面是否合法,如果发现一个页面的校验结果不一致,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,这就是double write。
两次写包括两部分,一个是在内存中的doublewrite buffer,一个是磁盘共享表空间。具体工作流程:
①先将脏页记录写入redo log中;
②当脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的doublewrite buffer中;
③接着从两次写缓冲区分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB;
④待第二步完成后,再将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写);(脏页数据固化后,即进行标记对应doublewrite数据可覆盖)
undo log(回滚日志)
上面说redolog的是完成事务的持久性,而undolog则是完成事务的原子性。原子性保证事务所有操作要么同时都完成,要么同时都不完成。一旦发生错误就需要回滚之前所有的操作,而事务的回滚就需要用到回滚日志。
undo log属于innodb存储引擎层,记录的是事务发生之前的状态。例如insert语句的undo log记录的是delete。
undo log的作用一共有两个:①事务回滚②多版本并发控制(MVCC)
note:一致性是指事务执行结束后,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。一致性是事务追求的最终目标,前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,一致性还需要数据库层面和应用层的保障。
参照:
聊聊redo log是什么?
简单了解InnoDB底层原理 (qq.com)
基于Redo Log和Undo Log的MySQL崩溃恢复流程 - 知乎 (zhihu.com)
详细分析MySQL的binlog日志
MySQL Binlog 介绍
什么是ACID