PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
-
- 0. 前言
- 1. 图像分割
-
- 1.1 基本概念
- 1.2 图像分割分类
- 1.3 UNet 网络架构
- 1.4 上采样
- 2. 使用 U-Net 实现语义分割
-
- 2.1 数据集分析
- 2.1 数据集分析
- 2.2 使用 PyTorch 实现图像分割模型
- 小结
- 系列链接
0. 前言
图像分割 (Image segmentation) 是计算机视觉领域中的一个重要任务,旨在将图像划分为具有语义信息的不同区域或对象。与目标检测任务不同,图像分割要求像素级别的精确定位和分类,将每个像素标记为属于哪个类别或属于哪个区域。图像分割方法有很多种,包括传统的基于阈值、边缘检测、区域生长等方法,以及现代的基于深度学习的方法,如全卷积网络、U-Net、Mask R-CNN,利用深度神经网络的强大表征能力,能够对图像进行更准确和精细的分割。在本节中,我们将介绍图像分割的基本概念,并训练一个基于 U-Net 架构的图像分割模型。
1. 图像分割
1.1 基本概念
图像分割是计算机视觉领域中的一项重要技术,它可以将一张图像分成若干个部分,并给每个部分打上标记,以预测像素所对应于对象,将图像中的像素分配到不同的区域或对象中。
在使用目标检测模型预测对象的类别及其边界框时,图像通过神经网络传递,经过展平层后,在全连接网络中预测类别和边界框偏移。而在图像分割中,输出形状与输入图像的形状相同,将卷积的输出展平后重建图像可能会导致图像信息丢失。此外,在图像分割中,原始图像中的轮廓和形状在输出图像中不会发生变化,因此使用带全连接层的网络对于图像分割而言并非最优模型。
在进行图像分割时,需要注意以下两个方面:
- 原始图像中目标对象的形状和结构在图像分割输出结果中保持不变
- 由于输入和输出结果均为图像,因此利用全卷积网络可以更好地捕捉到图像中的空间信息和上下文信息
1.2 图像分割分类
按照图像中对象被分割后的结果,可以将图像分割分为语义分割、实例分割和全景分割三种类型,不同类型的分割结果如下图所示。

语义分割 (Semantic Segmentation) 是为了便于图像分析而为图像中的每个像素分配标签的过程,属于某个对象的所有像素都被突出显示,比如用值 1 覆盖车辆对象像素(假设像素值在 0 - 1 之间),用值 0.5 覆盖人物对象像素,而其他像素则使用其他值显示。它的目标是对图像中的整体结构进行理解和解释,并且不需要区分不同实例之间的差异。
实例分割 (Instance Segmentation) 可以看作是目标检测和语义分割的结合,实例分割为属于同一对象类的不同对象实例分配不同的标签。相比目标检测标记对象的边界框,实例分割可以精确检测对象的边缘信息;相比语义分割,实例分割可以标注出图像上同一类对象的不同个体。例如,在一张道路图片中,实例分割能够识别并分割出不同的汽车,并给每个汽车分配不同的标识。
全景分割 (Panorama Segmentation) 可以看作是语义分割和实例分割的结合,需要同时对图像中所有物体和背景进行检测和分割。其中,对背景区域的分割属于语义分割,而对物体的分割属于实例分割。
1.3 UNet 网络架构
UNet 是一种常见的图像分割神经网络架构,它采用了类似 Encoder-Decoder 的结构,主要由下采样 (downsampling) 和上采样 (upsampling) 两部分组成。经典 U-Net 架构如下
(其中输入图像的形状为 3 x 96 x 128,图像中存在的 21 个类别,即输出包含 21 个通道):
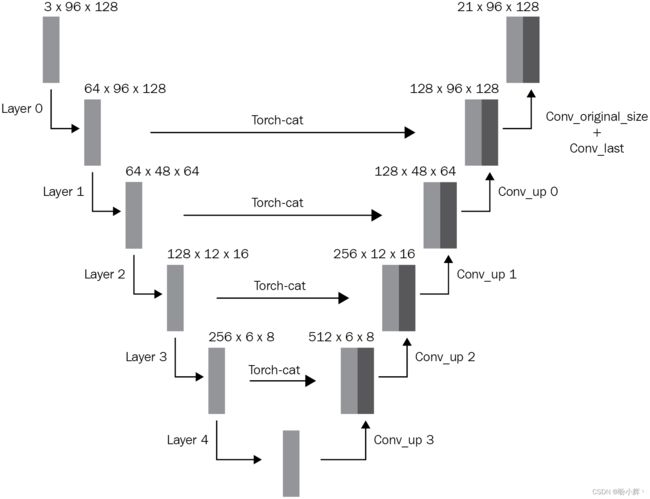
该架构因类似 U 形结构而被称为 U-Net 架构。整个网络分为两条分支,左侧分支实现图像特征的下采样,图像尺寸不断减小,而通道数不断增加;右侧分支负责进行特征的上采样与融合,逐渐将特征图尺寸恢复到原始图像尺寸,但通道数与类别数相同。两条分支都由卷积层、池化层、转置卷积层或上采样组成。其中,下采样的过程可以理解为逐渐把原图降采样为较小的低分辨率特征图,并将其存储在特征金字塔中,而上采样的过程则是对这些特征图进行反卷积或上采样操作,使得它们的分辨率逐渐恢复并与左侧的特征图进行融合,从而预测出每个像素所属的类别。
此外,在上采样过程中,UNet 还加入了跳跃连接 (skip connection),可以将底层网络的信息传递到高层网络中,更好地利用多尺度特征,提高了分割的精确性
U-Net 架构能够保留原始图像的结构与目标对象的形状,同时利用卷积的特征预测每个像素的类别,输出中的通道数与我们需要预测的类别数相同。
1.4 上采样
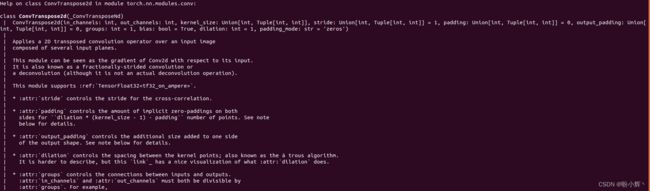
上采样 (upsampling) 是一种将低分辨率图像或特征图放大到高分辨率的过程,常见的上采样方法包括最近邻插值、双线性插值、双三次插值、反卷积(也称转置卷积)等。在 U-Net 架构中,使用 nn.ConvTranspose2d 方法执行上采样,该方法使用接受输入通道数、输出通道数、核大小和步幅作为参数。ConvTranspose2d 示例计算如下:

在以上示例中,使用形状为 3 x 3 的输入数组 (Input Array),将步幅设为 2,调整输入值以适应步幅 (Input Array adjusted for stride),用零填充输入数组 (Input Array adjusted for stride and padding),并将填充后的输入与卷积核 (Kernel) 执行卷积获取输出数组 (Output array)。
通过利用 padding 和 stride 的组合,能够将尺寸从 3 x 3 的输入放大为 6 x 6,训练过程中卷积核的权重和偏置会进行优化,以尽可能地重建原始图像。nn.ConvTranspose2d 中的参数如下:
接下来,使用 nn.ConvTranspose2d 查看反卷积运算结果。
(1) 导入相关库,并使用 nn.ConvTranspose2d 方法初始化网络 m:
import torch
import torch.nn as nn
m = nn.ConvTranspose2d(1, 1, kernel_size=(2,2),
stride=2, padding = 0)
在以上代码中,指定输入通道为 1,输出通道为 1,核大小为 (2,2),步幅为 2,并使用 0 填充。
所需填充是通过 dilation * (kernel_size - 1) - padding 计算得出的,在示例中,1*(2-1)-0 = 1,这表示我们需要在输入数组的周围上均匀的添加 1 个元素(值为 0 )进行填充。
(2) 初始化输入数组并将其传递给模型:
input = torch.ones(1, 1, 3, 3)
output = m(input)
print(output.shape)
以上代码得到的输出形状为 1 x 1 x 6 x 6。
2. 使用 U-Net 实现语义分割
2.1 数据集分析
2.1 数据集分析
为了训练图像分割模型以检测图像中的汽车,我们首先需要对数据集有所了解。我们用于图像分割模型的数据集中包含 367 张图像,并且每张图片都具有相应的包含对象蒙版的图像,此数据集中具有 12 个不同类别的对象,其中汽车蒙版的像素值为 8。如下图所示为原始图像及其对应的汽车带有蒙版的标签图像。
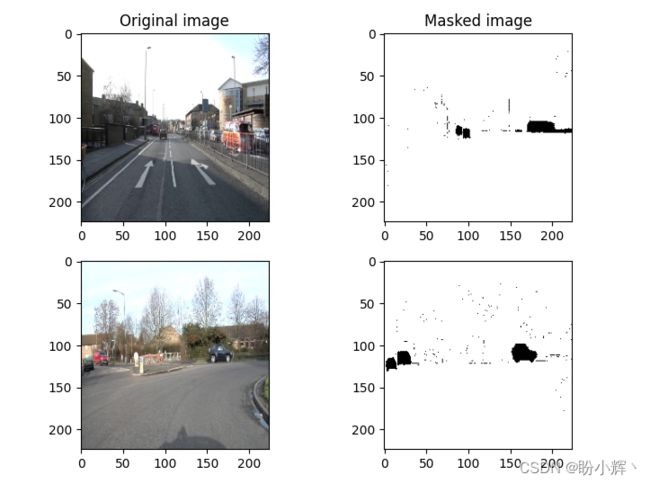
该数据集可从以下链接下载:https://pan.baidu.com/s/18c-5hBjsmLGdRaBUizxeKg,提取码: rh6p。
2.2 使用 PyTorch 实现图像分割模型
在图像分割中,输出图像也称为掩码图像,掩码用于标注图像中的不同区域。使用图像分割模型可以将图像分成不同的区域,然后为每个区域分配一个掩码值,从而可以方便地对这些区域进行后续处理。
掩码可以是二值掩码,每个像素值为 0 或 1,分别表示该像素属于或不属于某个类别;掩码可以是多值掩码,每个像素值对应一个标签,表示该像素属于哪个类别。接下来,我们使用 PyTorch 实现语义分割模型。
(1) 首先下载数据集,导入所需库,并定义设备:
import os
from torchvision import transforms
import torch
from torch import nn
from torch import optim
from torch.utils.data import DataLoader, Dataset
from glob import glob
from matplotlib import pyplot as plt
import numpy as np
from torchvision import transforms
import cv2
import random
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(2) 定义用于转换图像的函数 (tfms):
tfms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
denormalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.255],
std=[1/0.229, 1/0.224, 1/0.255]
)
def preprocess_image(img):
img = torch.tensor(img).permute(2,0,1)[None].float()
img = normalize(img)
return img.to(device)
def stems(split):
items = list(glob(f'dataset1/images_prepped_{split}/*.png'))
items_new = [item.split('/')[-1] for item in items]
items = [item.split('.')[0] for item in items_new]
return items
def get_segmentation_arr(img, n_classes):
seg_labels = np.zeros((224, 224, n_classes))
for c in range(n_classes):
seg_labels[:, :, c] = (img == c).astype(int)
return seg_labels
(3) 定义数据集类 SegData。
在 __init__ 方法中指定包含图像文件夹:
class SegData(Dataset):
def __init__(self, split):
self.items = stems(split)
# print(self.items)
self.split = split
定义 __len__ 方法:
def __len__(self):
return len(self.items)
定义 __getitem__ 方法:
def __getitem__(self, ix):
image = cv2.imread(f'dataset1/images_prepped_{self.split}/{self.items[ix]}.png', 1)
image = cv2.resize(image, (224,224))
mask = cv2.imread(f'dataset1/annotations_prepped_{self.split}/{self.items[ix]}.png', 0)
mask = cv2.resize(mask, (224,224))
return image, mask
在 __getitem__ 方法中,将输入 (image) 和输出 (mask) 图像调整为相同尺寸,掩码图像的像素值取值范围为 [0,11] 之间的整数,表示有 12 个不同的类别。
定义函数 (choose) 用于随机选择图像索引:
def choose(self):
return self[random.randint(len(self))]
定义 collate_fn 方法对批数据图像进行预处理:
def collate_fn(self, batch):
ims, ce_masks = [], []
for item in batch:
img, mask = item
img = preprocess_image(img)
ims.append(img)
ce_masks.append(torch.tensor(mask)[None].long().to(device))
images = torch.cat(ims).to(device)
ce_masks = torch.cat(ce_masks).to(device)
return images, ce_masks
在以上代码中,对所有输入图像进行预处理,ce_masks 是类似于交叉熵目标函数的长整型张量。
(4) 定义训练和验证数据集,以及数据加载器:
trn_ds = SegData('train')
val_ds = SegData('test')
trn_dl = DataLoader(trn_ds, batch_size=4, shuffle=True, collate_fn=trn_ds.collate_fn)
val_dl = DataLoader(val_ds, batch_size=1, shuffle=True, collate_fn=val_ds.collate_fn)
plt.imshow(cv2.cvtColor(trn_ds[11][0], cv2.COLOR_BGR2RGB))
plt.show()
(5) 定义神经网络模型。
定义卷积构建块 (conv):
def conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
在 conv 定义中,依次执行 Conv2d、BatchNorm2d 和 ReLU 操作。
定义 up_conv 构建块:
def up_conv(in_channels, out_channels):
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2),
nn.ReLU(inplace=True)
)
ConvTranspose2d 用于放大图像,与 Conv2d 操作不同,Conv2d 用于减少图像尺寸 ConvTranspose2d 接收具有 in_channels 个通道的图像作为输入,并生成具有 out_channels 个输出通道的图像。
定义网络类 UNet:
from torchvision.models import vgg16_bn
class UNet(nn.Module):
def __init__(self, pretrained=True, out_channels=12):
super().__init__()
self.encoder = vgg16_bn(pretrained=pretrained).features
self.block1 = nn.Sequential(*self.encoder[:6])
self.block2 = nn.Sequential(*self.encoder[6:13])
self.block3 = nn.Sequential(*self.encoder[13:20])
self.block4 = nn.Sequential(*self.encoder[20:27])
self.block5 = nn.Sequential(*self.encoder[27:34])
self.bottleneck = nn.Sequential(*self.encoder[34:])
self.conv_bottleneck = conv(512, 1024)
self.up_conv6 = up_conv(1024, 512)
self.conv6 = conv(512 + 512, 512)
self.up_conv7 = up_conv(512, 256)
self.conv7 = conv(256 + 512, 256)
self.up_conv8 = up_conv(256, 128)
self.conv8 = conv(128 + 256, 128)
self.up_conv9 = up_conv(128, 64)
self.conv9 = conv(64 + 128, 64)
self.up_conv10 = up_conv(64, 32)
self.conv10 = conv(32 + 64, 32)
self.conv11 = nn.Conv2d(32, out_channels, kernel_size=1)
在 __init__ 方法中,定义了用于 forward 方法的所有网络层。
定义前向传播方法 forward:
def forward(self, x):
block1 = self.block1(x)
block2 = self.block2(block1)
block3 = self.block3(block2)
block4 = self.block4(block3)
block5 = self.block5(block4)
bottleneck = self.bottleneck(block5)
x = self.conv_bottleneck(bottleneck)
x = self.up_conv6(x)
x = torch.cat([x, block5], dim=1)
x = self.conv6(x)
x = self.up_conv7(x)
x = torch.cat([x, block4], dim=1)
x = self.conv7(x)
x = self.up_conv8(x)
x = torch.cat([x, block3], dim=1)
x = self.conv8(x)
x = self.up_conv9(x)
x = torch.cat([x, block2], dim=1)
x = self.conv9(x)
x = self.up_conv10(x)
x = torch.cat([x, block1], dim=1)
x = self.conv10(x)
x = self.conv11(x)
return x
在以上代码中,通过在对应的张量对上使用 torch.cat 来连接下采样和上采样卷积特征,实现 U 型连接。
定义函数 UNetLoss 计算损失和准确率值:
ce = nn.CrossEntropyLoss()
def UnetLoss(preds, targets):
ce_loss = ce(preds, targets)
acc = (torch.max(preds, 1)[1] == targets).float().mean()
return ce_loss, acc
(6) 定义函数 train_batch 在批数据上训练模型,并在验证数据集上计算模型性能指标 (validate_batch):
def train_batch(model, data, optimizer, criterion):
model.train()
ims, ce_masks = data
_masks = model(ims)
optimizer.zero_grad()
loss, acc = criterion(_masks, ce_masks)
loss.backward()
optimizer.step()
return loss.item(), acc.item()
@torch.no_grad()
def validate_batch(model, data, criterion):
model.eval()
ims, masks = data
_masks = model(ims)
loss, acc = criterion(_masks, masks)
return loss.item(), acc.item()
(7) 定义模型、优化器、损失函数和 epoch 数:
model = UNet().to(device)
criterion = UnetLoss
optimizer = optim.Adam(model.parameters(), lr=1e-3)
n_epochs = 30
(8) 训练模型:
train_loss_epochs = []
val_loss_epochs = []
# log = Report(n_epochs)
for epoch in range(n_epochs):
N = len(trn_dl)
trn_loss = []
val_loss = []
for ix, data in enumerate(trn_dl):
loss, acc = train_batch(model, data, optimizer, criterion)
pos = (epoch + (ix+1)/N)
trn_loss.append(loss)
train_loss_epochs.append(np.average(trn_loss))
N = len(val_dl)
for bx, data in enumerate(val_dl):
loss, acc = validate_batch(model, data, criterion)
pos = (epoch + (ix+1)/N)
val_loss.append(loss)
val_loss_epochs.append(np.average(val_loss))
(9) 绘制训练期间的训练、验证损失和准确率变化情况:
epochs = np.arange(n_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()
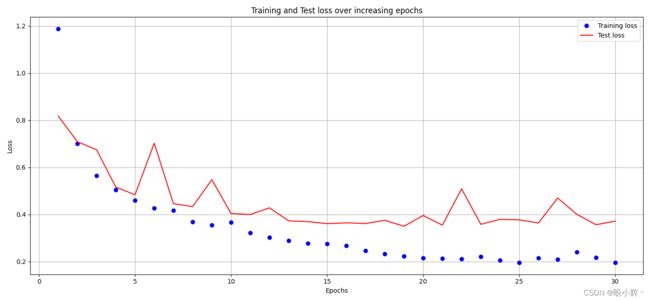
(10) 计算测试图像上的预测输出。
使用测试图像获取模型预测结果:
im, mask = next(iter(val_dl))
_mask = model(im)
获取概率最高的通道:
_, _mask = torch.max(_mask, dim=1)
显示原始图像、预测图像和真实分割图像:
plt.subplot(131)
plt.imshow(im[0].permute(1,2,0).detach().cpu()[:,:,0], cmap='gray')
plt.title('Original image')
plt.subplot(132)
plt.imshow(mask.permute(1,2,0).detach().cpu()[:,:,0], cmap='gray')
plt.title('Original mask')
plt.subplot(133)
plt.imshow(_mask.permute(1,2,0).detach().cpu()[:,:,0], cmap='gray')
plt.title('Predicted mask')
plt.show()

从上图中可以看出,使用 U-Net 架构能够成功生成分割图像。但是,同一类别的所有实例都具有相同的预测像素值。如果我们想在图像中分离同一类别的不同实例,则需要使用实例分割模型,以便区分不同实例。
小结
图像分割旨在将图像分割成具有语义或结构意义的不同区域,在许多应用中都有广泛的应用,包括医学图像分析、自动驾驶、机器人视觉、智能视频监控等领域。通过准确地将图像分割为不同的区域和对象,可以为后续的视觉分析和理解提供更丰富的信息。本文首先介绍了图像分割模型的核心思想与算法流程,然后使用 PyTorch 从零开始实现了一个基于 UNet 的图像分割模型。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测