Python使用AI photo2cartoon制作属于你的漫画头像
Python使用AI photo2cartoon制作属于你的漫画头像
-
- 1. 效果图
- 2. 原理
- 3. 源码
- 参考
git clone https://github.com/minivision-ai/photo2cartoon.git
cd ./photo2cartoon
python test.py --photo_path images/photo_test.jpg --save_path images/cartoon_result.png
1. 效果图
官方效果图如下:

效果图1如下:

效果图2如下:

效果图3如下:

2. 原理
人像卡通风格渲染的目标是,在保持原图像 ID 信息和纹理细节的同时,将真实照片转换为卡通风格的非真实感图像。
但是图像卡通化任务面临着一些难题:
- 卡通图像往往有清晰的边缘,平滑的色块和经过简化的纹理,与其他艺术风格有很大区别。使用传统图像处理技术生成的卡通图无法自适应地处理复杂的光照和纹理,效果较差;基于风格迁移的方法无法对细节进行准确地勾勒。
- 数据获取难度大。绘制风格精美且统一的卡通画耗时较多、成本较高,且转换后的卡通画和原照片的脸型及五官形状有差异,因此不构成像素级的成对数据,难以采用基于成对数据的图像翻译(Paired Image Translation)方法。
- 照片卡通化后容易丢失身份信息。基于非成对数据的图像翻译(Unpaired Image Translation)方法中的循环一致性损失(Cycle Loss)无法对输入输出的 id 进行有效约束。
小视科技的研究团队提出了一种基于生成对抗网络的卡通化模型,只需少量非成对训练数据,就能获得漂亮的结果。卡通风格渲染网络是该解决方案的核心,它主要由特征提取、特征融合和特征重建三部分组成。
3. 源码
源码及示例文件模型等见资源:https://download.csdn.net/download/qq_40985985/87739184
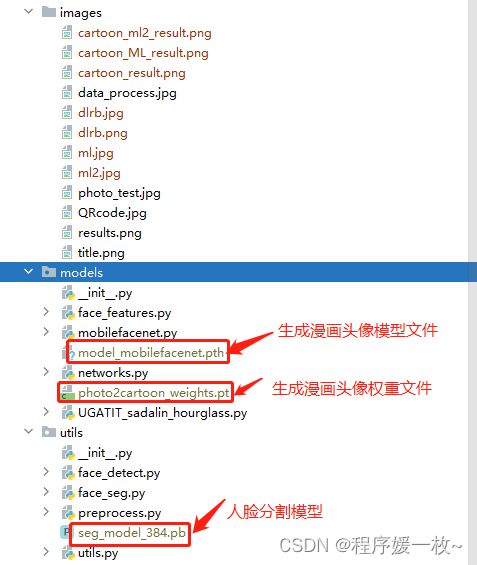
代码下载 https://github.com/minivision-ai/photo2cartoon
模型下载 https://drive.google.com/uc?id=1eDNGZT3jszHLXQ9XGIUPtcu72HdBmHuX&export=download
人像卡通化预训练模型:photo2cartoon_weights.pt,存放在 models 路径下。
头像分割模型:seg_model_384.pb,存放在 utils 路径下。
人脸识别预训练模型:model_mobilefacenet.pth,存放在 models 路径下。
卡通画开源数据:cartoon_data,包含 trainB 和 testB
# 使用预训练的模型生成漫画头像
# python test.py --photo_path images/ml.jpg --save_path images/cartoon_ml_result.png
import argparse
import os
import cv2
import numpy as np
import torch
from models import ResnetGenerator
from utils import Preprocess
parser = argparse.ArgumentParser()
parser.add_argument('--photo_path', type=str, default='images/photo_test.jpg', help='input photo path')
parser.add_argument('--save_path', type=str, default='images/photo_test_cartoon.jpg', help='cartoon save path')
args = parser.parse_args()
os.makedirs(os.path.dirname(args.save_path), exist_ok=True)
class Photo2Cartoon:
def __init__(self):
self.pre = Preprocess()
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.net = ResnetGenerator(ngf=32, img_size=256, light=True).to(self.device)
assert os.path.exists(
'./models/photo2cartoon_weights.pt'), "[Step1: load weights] Can not find 'photo2cartoon_weights.pt' in folder 'models!!!'"
params = torch.load('./models/photo2cartoon_weights.pt', map_location=self.device)
self.net.load_state_dict(params['genA2B'])
print('[Step1: load weights] success!')
def inference(self, img):
# face alignment and segmentation
face_rgba = self.pre.process(img)
if face_rgba is None:
print('[Step2: face detect] can not detect face!!!')
return None
print('[Step2: face detect] success!')
face_rgba = cv2.resize(face_rgba, (256, 256), interpolation=cv2.INTER_AREA)
face = face_rgba[:, :, :3].copy()
mask = face_rgba[:, :, 3][:, :, np.newaxis].copy() / 255.
face = (face * mask + (1 - mask) * 255) / 127.5 - 1
face = np.transpose(face[np.newaxis, :, :, :], (0, 3, 1, 2)).astype(np.float32)
face = torch.from_numpy(face).to(self.device)
# inference
with torch.no_grad():
cartoon = self.net(face)[0][0]
# post-process
cartoon = np.transpose(cartoon.cpu().numpy(), (1, 2, 0))
cartoon = (cartoon + 1) * 127.5
cartoon = (cartoon * mask + 255 * (1 - mask)).astype(np.uint8)
cartoon = cv2.cvtColor(cartoon, cv2.COLOR_RGB2BGR)
print('[Step3: photo to cartoon] success!')
return cartoon
if __name__ == '__main__':
img = cv2.cvtColor(cv2.imread(args.photo_path), cv2.COLOR_BGR2RGB)
c2p = Photo2Cartoon()
cartoon = c2p.inference(img)
if cartoon is not None:
cv2.imwrite(args.save_path, cartoon)
print('Cartoon portrait has been saved successfully!')
origin = cv2.resize(cv2.imread(args.photo_path), (256, 256))
res = cv2.imread(args.save_path)
print(origin.shape, res.shape)
cv2.imshow("origin VS cartoon", np.hstack([origin, res]))
cv2.waitKey(0)
参考
- https://blog.csdn.net/weixin_47196664/article/details/106542463
- 代码下载 https://github.com/minivision-ai/photo2cartoon
- 模型下载 https://drive.google.com/uc?id=1eDNGZT3jszHLXQ9XGIUPtcu72HdBmHuX&export=download
- https://blog.csdn.net/kexuanxiu1163/article/details/105858528