关于MVP的项目经验心得以及对Jetpack Compose的思考
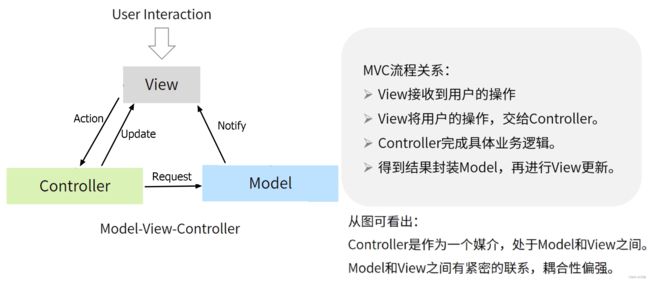
MVC(既当爹又当妈的痛苦)
MVC的缺点就不啰嗦了,来张图总结一下,你看着图上画的挺好挺清楚,实际上它们都在一个Activity类里面呢,互相纠缠在一起,就问你怕不怕。(说出来你可能不信,我在项目中曾经有幸见过超过2000行业务代码的Adapter类,你猜里面都干了啥)
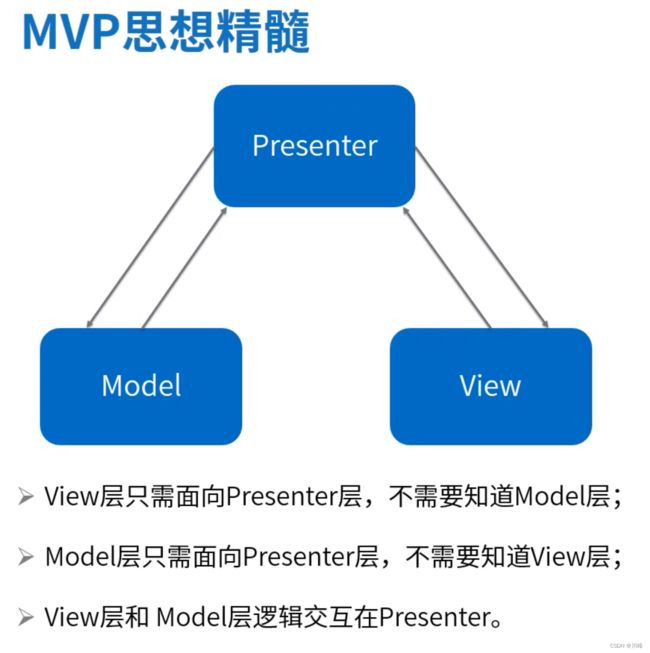
关于MVP架构的心得总结 (过去式)

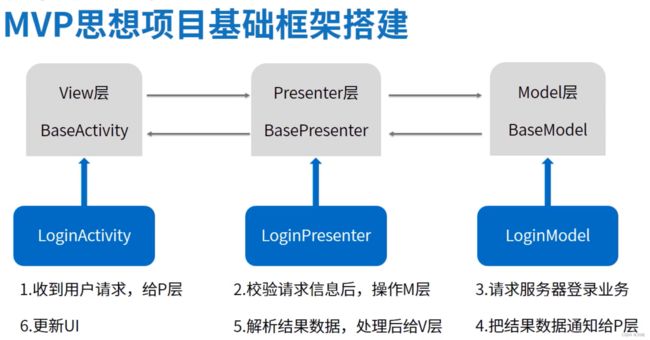
V层和P层交互:
-
V层持有P层的接口,P层持有V层的接口,
-
V层调用iPresenter.requestLogin()之类, P层调用V层的iLoginView.onLoginSuccess()之类
-
P层调用M层的接口,iUserInfo.login(callback), 在回调接口中,P层调用V层接口处理,其中iUserInfo.login()中调用HttpClient.get()/post()方法
-
P层直接调用M层的统一数据管理类DataManager.getData()这种是同步请求本地数据(当然直接同步IO读取是不可取的,但是有时我们会因为耗时任务太短而忽略这一点,比如主线程读取一个sp中的值)
-
1) V --> P: 通过统一的方法 iLoginPresenter.getData(AppConstant.LOG_IN)请求, 其中iLoginPresenter要继承 IBasePresenter, getData()来自 IBasePresenter,iLoginPresenter中有自己的业务接口
- 2) P --> V: 通过统一的方法iLoginView.setDataToView(AppConstant.LOG_IN,Object data)回调UI层处理,其中iLoginView要继承IBaseView,而所有的页面Activity基类、Fragment基类等都实现IBaseView接口。
-
3) P --> V:P层回调V层通过 全局Handler发消息处理,或 EventBus之类的通信框架,这是因为某些业务情况下,发起Presenter请求的页面可能并不一定是要处理回调数据的页面,比如在A页面调用P层方法做一些接口请求或者提交数据,不用等接口返回,用户A页面紧接着就跳到了B页面,P层可以将M层处理完成的数据直接发送到B页面处理,或者,B页面的P层数据又要通知A页面中的View刷新。


-
1)在P层调用统一方法 iBaseView.setDataToView(int code,Object data)回调UI层处理时,这里的数据data并没有使用泛型,因为是所有人共用的方法,如果使用泛型就得分开接口类设计,不同的页面实现不同的接口类,在不同的接口类上持有的泛型不同,这样其实又绕回去了。这一步可以改成泛型实现,如果传泛型data,使用时不用强转,但是在同一个页面中请求返回的可能是不同的实体类,在使用一个统一方法的前提下,是无法区分不同的业务实体类的,这也算是一种细节上的妥协和牺牲,但是问题不大。
-
2)P层持有的V层接口成员如iLoginView应该是弱引用 WeakReference
,防止P层持有View层实例导致 内存泄漏 -
3) 关于P层与M层的交互,个人更倾向于在M层向外暴露回调callback,P层中实现这个callback处理,而不是在M层自己的内部去调用P层的接口,这是两种不同的实现模式,前者可以保证M层是干净的,因为它不会依赖任何P层的类,这样就很方便的做成一个独立的Module或插件,甚至可以在MVC的页面中也可以调用,而后者会依赖P层的接口,也就是说它的处理接口只会交给P层接口,这样专门为P而生为P而死,无法独立存在和复用。


MVVM(被抛弃的人)
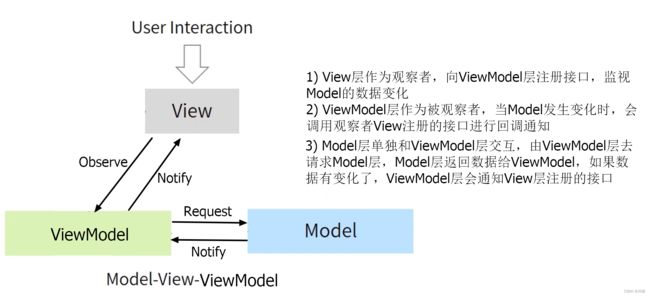
MVI ? ??
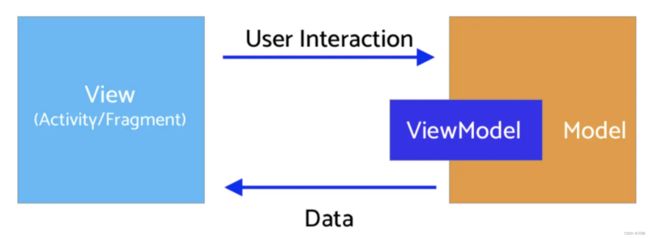
- Model: 与MVVM中的Model不同的是,MVI的Model主要指UI状态(State)。例如页面加载状态、控件位置等都是一种UI状态
- View: 与其他MVX中的View一致,可能是一个Activity或者任意UI承载单元。MVI中的View通过订阅Model的变化实现界面刷新
- Intent: 此Intent不是Activity的Intent,用户的任何操作都被包装成Intent后发送给Model层进行数据请求
-
用户操作以Intent的形式通知Model
-
Model基于Intent更新State
-
View接收到State变化刷新UI。
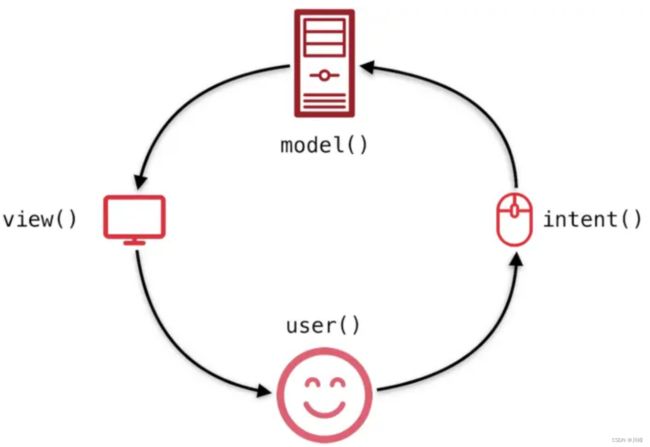
相信有的人还是很难理解,这是因为你还是按照三个角色去理解它,不要被网友创造的单词MVI给迷惑了,MVI中的 I 在这里其实并不能算是一直角色,它是一种动作,一种意图,更直白的说就是View控件上的事件触发,如点击事件啊,文本框的onTextChanged啊。也就是说,实际上这种单向数据流的架构只有2层,非常简单。看一下官方的介绍你就明白了。
以下是摘自官方的部分介绍
-
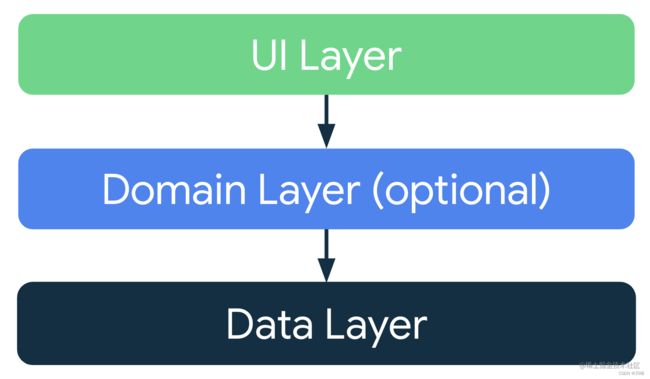
在屏幕上呈现数据的界面元素。您可以使用 View 或 Jetpack Compose 函数构建这些元素。
-
用于存储数据、向界面提供数据以及处理逻辑的状态容器(如 ViewModel 类)。
-
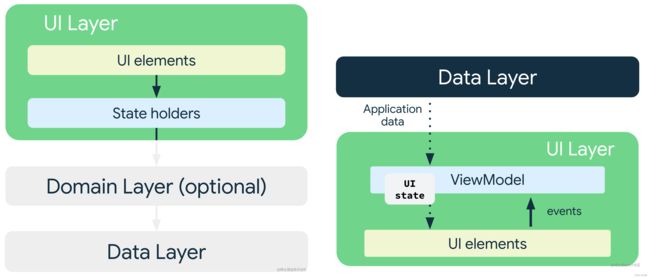
获取应用数据,并将其转换为UI可以轻松呈现的UI State。
-
订阅UI State,当页面状态发生改变时刷新UI
-
接收用户的输入事件,并根据相应的事件进行处理,从而刷新UI State
-
根据需要重复第 1-3 步。

- 不要将数据存储在应用组件中。请避免将应用的入口点(如 Activity、Service 和广播接收器)指定为数据源。相反,您应只将其与其他组件协调,以检索与该入口点相关的数据子集。每个应用组件存在的时间都很短暂,具体取决于用户与其设备的交互情况以及系统当前的整体运行状况。
- 减少对 Android 类的依赖。您的应用组件应该是唯一依赖于 Android 框架 SDK API (例如 Context 或 Toast)的类。将应用中的其他类与这些类分离开来有助于改善可测试性,并减少应用中的耦合。
- 在应用的各个模块之间设定明确定义的职责界限。例如,请勿在代码库中将从网络加载数据的代码散布到多个类或软件包中。同样,也不要将不相关的职责(如数据缓存和数据绑定)定义到同一个类中。遵循推荐的应用架构可以帮助您解决此问题。
- 尽量少公开每个模块中的代码。例如,请勿试图创建从模块提供内部实现细节的快捷方式。短期内,您可能会省点时间,但随着代码库的不断发展,您可能会反复陷入技术上的麻烦。
- 专注于应用的独特核心,以使其从其他应用中脱颖而出。不要一次又一次地编写相同的样板代码,这是在做无用功。 相反,您应将时间和精力集中放在能让应用与众不同的方面上,并让 Jetpack 库以及建议的其他库处理重复的样板。
- 考虑如何使应用的每个部分可独立测试。例如,如果使用明确定义的 API 从网络获取数据,将会更容易测试在本地数据库中保留该数据的模块。如果您将这两个模块的逻辑混放在一处,或将网络代码分散在整个代码库中,那么即便能够进行有效测试,难度也会大很多。
- 保留尽可能多的相关数据和最新数据。这样,即使用户的设备处于离线模式,他们也可以使用您应用的功能。请记住,并非所有用户都能享受到稳定的高速连接 - 即使有时可以使用,在比较拥挤的地方网络信号也可能不佳。
从官网的介绍中可以得知,这种单向数据流的设计,主要是为了实现分离关注点的架构设计原则。如果只从分层上看,它足够简单,在层次划分上,几乎抹平了以前的所有角色,只分为两层:UI层和数据层(回归到本质了有木有),由ViewModel来承担数据业务的管理。但是对状态的抽象和管理才是这种架构中最难的部分。
JetpackCompose :摒弃过去,面向未来
- 因为View控件要修改啊,文本框中输入了文字后要让它(数据)变化啊。
为什么是可被观察的?
- 如果不可被观察,我(View)怎么知道你(数据)变了呢?要知道,我(View)可是一个观察者。(观察者模式)
只有变成了mutableState这样之后,UI产生的事件对数据造成的变化会反馈到承载数据的状态容器中(这点需要我们写代码时去遵循),而状态容器中对状态(数据)的修改也会自动反馈的UI上(这点是Compose框架为我们完成的),如此循环往复,形成一个环型单向流。
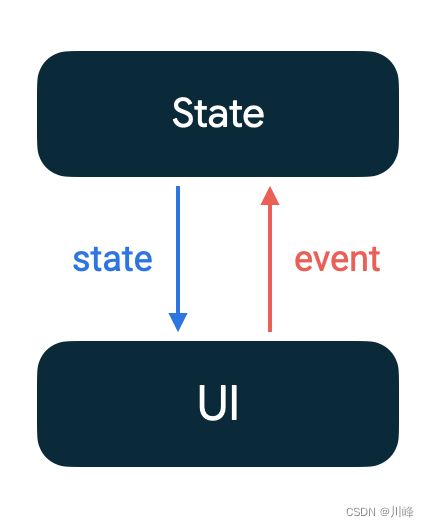
(其实这背后的本质还是观察者模式的应用,但不管怎样,在声明式的UI框架中,如React、Flutter等,都是由状态驱动UI界面更新,这种思想大家是统一的)
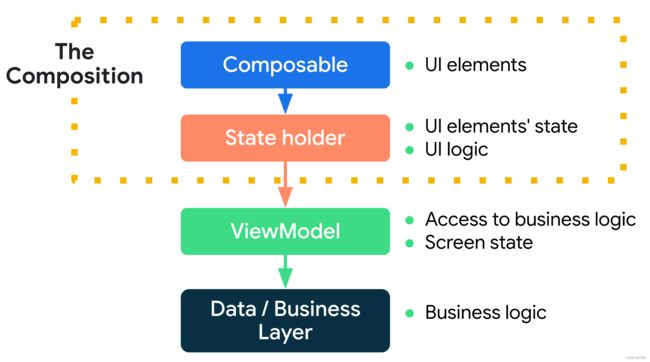
参考文章:
Google 推荐使用 MVI 架构?卷起来了~
一文了解MVI架构,学起来吧~
MVVM 进阶版:MVI 架构了解一下~
应用架构指南
Compose 编程思想
状态和 Jetpack Compose
如果有正在学习Compose的道友找不到资料的,推荐一个书籍《Jetpack Compose 从入门到实战》这个是今年8月出版,目前找到的最新的了,作者都是大佬,内容质量应该不会差。不喜欢看书的可以看官网或者这个网站学习都行。如果你不喜欢看书也不喜欢看文章,而更喜欢看视频?那么你可以去B站搜索输入"Jetpack Compose"试试,会得到惊人的发现。