基于LSTM神经网络的股票预测(Python+pytorch)
个人主页:研学社的博客
欢迎来到本博客❤️❤️a
博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
本文目录如下:
目录
1 概述
2 运行结果
3 参考文献
4 Python代码实现
1 概述
为了解决循环神经网络存在的梯度消失等问题,专家学者经过研究提出了长短期记忆(Long-Short Term Memory , LSTM )神经网络。 LSTM 神经网络从本质上来说是一种特殊的循环神经网络,能够用来处理长期依赖问题。经过大量的研究结论证明 LSTM 神经网络已经解决了循环神经网络无法解决的许多问题,在时间序列预测问题上获得了更进一步的成功 [54] 。 LSTM 神经网络增加了一个信息存储记忆单元,可以维持一个持续信息流,使得梯度不会消失或爆炸。同时构造了遗忘门(Forget Gate ),输入门( Input Gate ),输出门( Output Gate )分别对该记忆单元进行控制。这三个门就像滤波器一样,遗忘门控制记忆单元状态信息的舍弃与保留,输入门更新记忆单元状态,输出门控制 LSTM 单元输出。 LSTM 神经网络拥有着与循环神经网络相似的结构,不同之处在于它是通过内部的各个模块协同工作的[55] 。 LSTM 神经网络结构图如下。
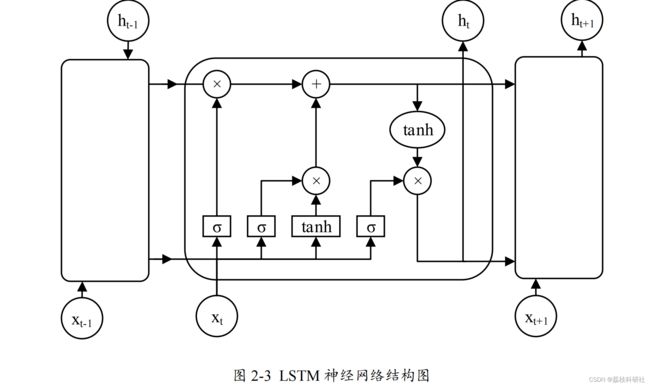
LSTM 神经网络的优点主要表现在以下三方面:
(1 )解决了循环神经网络存在的长期依赖问题,能够处理时间滞后很长的数据序列。如果在某个时刻下信息较为重要,那么它对应的遗忘门位置会一直保留在接近于 1 的数值。这样就可以让这个时刻的信息一直往下传递下去而不被丢失,这就是 LSTM 神经网络能够处理长序列的原因之一。
(2)收敛性好。遗忘门对上一时刻的记忆进行控制,再加上当前输入产生当前时刻的新记忆。“门”结构的加入,提供了控制网络中信息传递的工具,让 LSTM神经网络能够记忆较为长期的信息。因此,通过遗忘门便可以对先前记忆进行处理进而对网络的输出产生影响[56] 。
(3)不易发生梯度消失或爆炸。循环神经网络在基于时间的反向传播中存在激活函数导数的乘数,与之相比 LSTM 神经网络其相应导数不是以乘积的形式存在,而是通过累加的方式进行计算。这一改变使得梯度消失和爆炸问题获得解决,同时不易陷入局部最优。
2 运行结果
# 归一化,便与训练 train_data_numpy = np.array(train_data) train_mean = np.mean(train_data_numpy) train_std = np.std(train_data_numpy) train_data_numpy = (train_data_numpy - train_mean) / train_std train_data_tensor = torch.Tensor(train_data_numpy) # 创建 dataloader train_set = TrainSet(train_data_tensor) train_loader = DataLoader(train_set, batch_size=10, shuffle=True)
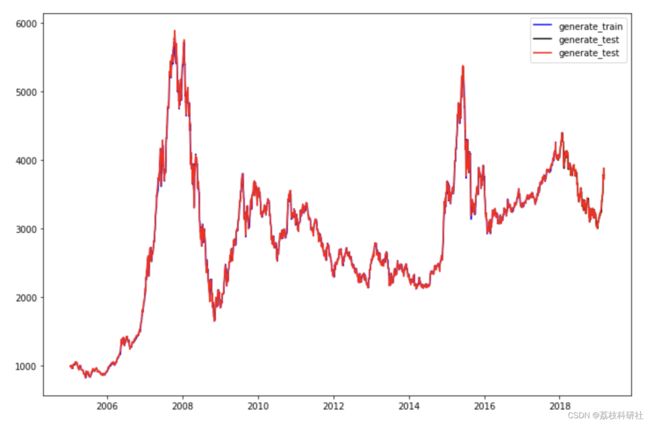
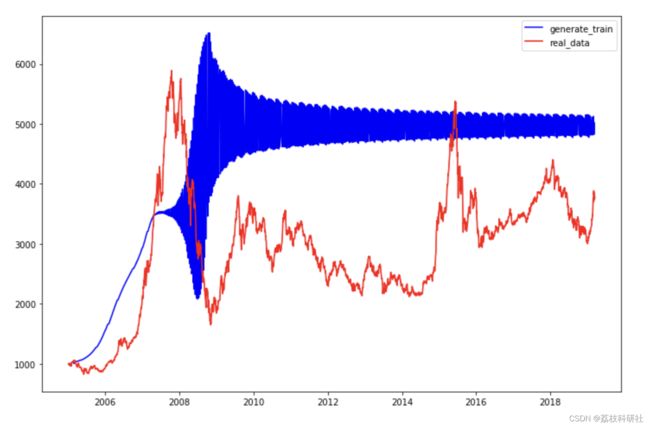
for i in range(DAYS_BEFORE, len(all_series)): x = all_series[i - DAYS_BEFORE:i] # 将 x 填充到 (bs, ts, is) 中的 timesteps x = torch.unsqueeze(torch.unsqueeze(x, dim=0), dim=2) if torch.cuda.is_available(): x = x.cuda() y = rnn(x) if i < test_start: generate_data_train.append(torch.squeeze(y.cpu()).detach().numpy() * train_std + train_mean) else: generate_data_test.append(torch.squeeze(y.cpu()).detach().numpy() * train_std + train_mean) plt.figure(figsize=(12,8)) plt.plot(df_index[DAYS_BEFORE: TRAIN_END], generate_data_train, 'b', label='generate_train', ) plt.plot(df_index[TRAIN_END:], generate_data_test, 'k', label='generate_test') plt.plot(df_index, all_series.clone().numpy()* train_std + train_mean, 'r', label='real_data') plt.legend() plt.show()
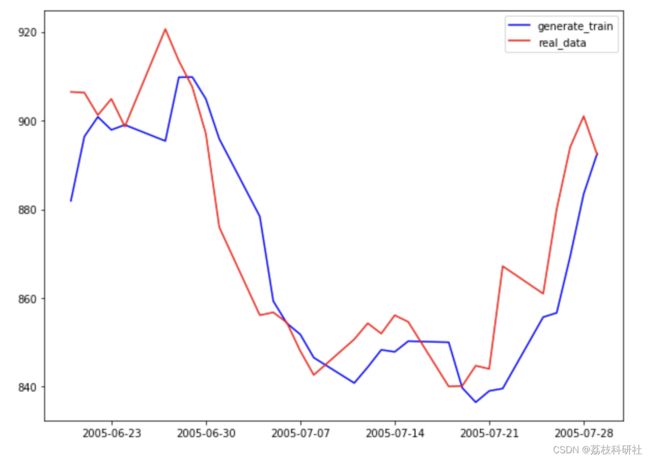
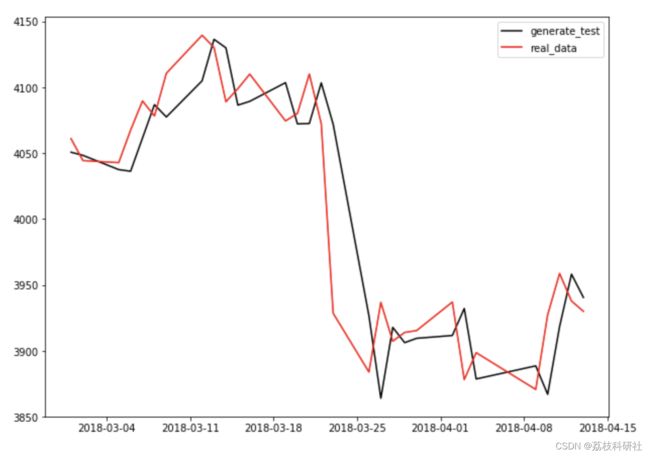
plt.figure(figsize=(10,16)) plt.subplot(2,1,1) plt.plot(df_index[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], generate_data_train[100: 130], 'b', label='generate_train') plt.plot(df_index[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], (all_series.clone().numpy()* train_std + train_mean)[100 + DAYS_BEFORE: 130 + DAYS_BEFORE], 'r', label='real_data') plt.legend() plt.subplot(2,1,2) plt.plot(df_index[TRAIN_END + 50: TRAIN_END + 80], generate_data_test[50:80], 'k', label='generate_test') plt.plot(df_index[TRAIN_END + 50: TRAIN_END + 80], (all_series.clone().numpy()* train_std + train_mean)[TRAIN_END + 50: TRAIN_END + 80], 'r', label='real_data') plt.legend() plt.show()
print(len(all_series_test2)) print(len(df_index)) print(len(iter_series)) plt.figure(figsize=(12,8)) plt.plot(df_index[ : len(iter_series)], iter_series, 'b', label='generate_train') plt.plot(df_index, all_series_test2.clone().numpy() * train_std + train_mean, 'r', label='real_data') plt.legend() plt.show()
3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]曹彦彦. LSTM模型优化及其在股指预测中的应用研究[D].东北财经大学,2022.DOI:10.27006/d.cnki.gdbcu.2022.000020.
[2]张杰. 基于LSTM的股票预测实证分析[D].山东大学,2020.DOI:10.27272/d.cnki.gshdu.2020.002958.
[3]隋金城. 基于LSTM神经网络的股票预测研究[D].青岛科技大学,2020.DOI:10.27264/d.cnki.gqdhc.2020.000423.