基于随机森林的房价预测(boston住房数据集)
目录
一、随机森林的简单介绍
二、数据集
boston住房数据集下载链接:
三、数据预处理
1)加载住房数据集
2)绘制散点图
3)绘制关联矩阵
4)划分训练集和测试集
四、随机森林回归模型建立
1)建立随机森林回归模型
2)模型预测
五、结果及分析
1)模型性能评估
2)绘制残差图
六、全部代码
一、随机森林的简单介绍
随机森林是多个回归决策树的集合。相对于回归决策树,随机森林有以下几个优点:
(1)由于建立了多个决策树,因此随机森林可以降低单个决策树异常值带来的影响,预测结果更准确。
(2)回归决策树采用了训练集的所有特征和样本,而随机森林采用训练集的部分特征构建多个决策树,相对于决策树回归降低了过拟合的可能性。
相对于回归决策树,随机森林存在以下缺点:
(1)随机森林的计算量相对于决策树更大。
(2)由于采用训练集的部分特征构建多个决策树,随机森林可能存在部分数据没有被训练到的问题。
二、数据集
boston住房数据集下载链接:
链接:https://pan.baidu.com/s/1I4Ko-o0J-rX4hlacPP1VsA?pwd=oqdj
提取码:oqdj
如果要查看住房数据集的所有内容,可以去下面这个网站:
UCI Machine Learning Repository: Data SetsUCI Machine Learning Repository: Data SetsUCI Machine Learning Repository: Data Sets
住房数据集包含了由哈里斯和鲁宾菲尔德于1978年收集的关于波士顿郊区住房的信息。数据集中包含506个房屋样本的价格信息以及14个相关特征。这些特征如下:
- CRIM:城镇人均犯罪率
- ZN:住宅用地超过25000平方英尺的比例
- INDUS:城镇非零售营业面积占比
- CHAS:查尔斯河亚变量(如果临河有大片土地则为1;否则为0)
- NOX:一氧化氮浓度(千万分之一)
- RM:平均每户的房间数
- AGE:1940年以前建成的自用住房比例
- DIS:到五个波士顿就业中心的加权距离
- RAD:辐射可达的公路的指数
- TAX:每10,000美元的全额财产的税率
- PTRATIO:城镇师生比例
- B:1000人种非裔美国人的比例
- LSTAT:地位较低人口的百分比
- MEDV:自住房中位价(以千美元为单位)
在这里,将把MEDV(自住房中位价)作为目标变量,从剩余的特征中选取一个或多个特征作为解释变量,分析解释变量与目标变量之间的关系并建立回归模型。
三、数据预处理
1)加载住房数据集
# 数据预处理
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
df = pd.read_csv('.\housing.data', header=None, sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
2)绘制散点图
在建立模型之前,需要对数据进行分析,分析数据中可能与房价存在相关关系的特征。使用比较普遍的主要是采用数据可视化的方法,绘制散点图矩阵和关联矩阵。数据集有13个特征,由于空间的限制,此处选择5个特征绘制散点图,读者可自行绘制包含13个特征的散点图,采用Seaborn图形可视化Python包绘制散点图。
import seaborn as sns
import matplotlib.pyplot as plt
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
sns.pairplot(df[cols], height=2.5) # 绘制 df 数据框对象中的 'LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV' 这几个变量的两两关系的散点图
plt.tight_layout()
plt.show()
3)绘制关联矩阵
根据散点图可以可视化LSTAT、INDUS、NOX、RM和MEDV五个特征之间的关系,例如MEDV与RM之间可能存在一种线性关系、MEDV与LSTAT之间可能存在一种非线性关系。
为了更准确地分析特征间的相关性,接下来进一步绘制关联矩阵,关联矩阵的取值范围为-1到1,越接近1代表特征特征间正相关关系越强,越接近-1代表特征间负相关关系越强。采用Seaborn图形可视化Python包绘制关联矩阵。
# 绘制关联矩阵
import numpy as np
# 将相关系数矩阵以热力图的形式可视化
cm = np.corrcoef(df[cols].values.T)
# cbar=True 表示显示颜色条,square=True 表示将热力图的宽高设置为相等,annot_kws={'size':15} 表示热力图上的数值字体大小为15
hm = sns.heatmap(cm, cbar=True, square=True, fmt='.2f', annot=True, annot_kws={'size':15}, yticklabels=cols, xticklabels=cols)
plt.show()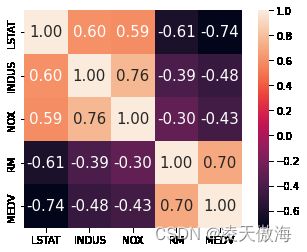
根据关联矩阵的信息,可知LSTAT与MEDV之间存在最强的负相关关系,RM与MEDV存在最强的正相关关系。因此,可以选择相关性较强的特征,探索其与MEDV(房价)间的关系。
4)划分训练集和测试集
这里选择RM与MEDV两个特征建立随机森林回归模型。
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X = df['RM'].values.reshape(-1, 1)
y = df['MEDV'].values
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.4, random_state=1)
四、随机森林回归模型建立
数据预处理完成后就可以开始建立随机森林回归模型了。
1)建立随机森林回归模型
# 建立随机森林回归模型
forest = RandomForestRegressor(n_estimators=1000, criterion='squared_error', random_state=1, n_jobs=-1)
forest.fit(X_train,y_train)2)模型预测
# 模型预测
y_test_pred = forest.predict(X_test)五、结果及分析
在建立模型之后,需要对模型进行客观的性能评估。需要注意的是,性能评估是评估模型在未见过的数据上的性能即在测试集上的性能,训练集上评估的性能不能代表模型的性能。
评估模型性能采用计算均方误差和报告决定系数。
1)模型性能评估
# 模型性能评估
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mse_test = mean_squared_error(y_test, y_test_pred)
r2_test = r2_score(y_test, y_test_pred)
print("mse_test={:.2f} r2_test={:.2f}".format(mse_test, r2_test))
运行效果:
mse_test=50.92 r2_test=0.44
2)绘制残差图
由于特征变量有两个,无法在平面中绘制出模型图像,因此选择绘制残差图来进一步观察模型的性能是一个比较好的选择。
# 绘制残差图
import matplotlib.pyplot as plt
plt.scatter(y_test_pred, y_test_pred-y_test, c='steelblue', edgecolor='white', marker='s', s=35, alpha=0.9,label='test data')
plt.xlabel = ('Predicted values')
plt.ylabel = ('Residuals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-10, xmax=50, lw=2, color='black')
plt.xlim([10,48])
plt.tight_layout()
plt.show()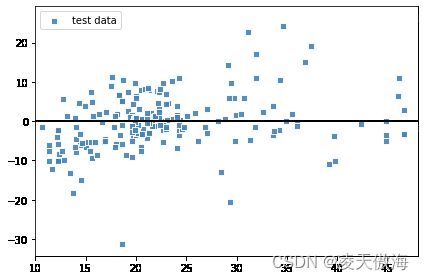
残差图显示残差大体分布在中心线附近,离群值较少。
六、全部代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
# Load data
df = pd.read_csv('.\housing.data', header=None, sep='\s+')
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
# Visualize data
cols = ['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
sns.pairplot(df[cols], height=2.5)
plt.tight_layout()
plt.show()
# Visualize correlation matrix
cm = np.corrcoef(df[cols].values.T)
hm = sns.heatmap(cm, cbar=True, square=True, fmt='.2f', annot=True, annot_kws={'size':15}, yticklabels=cols, xticklabels=cols)
plt.show()
# Prepare data for model
X = df['RM'].values.reshape(-1, 1)
y = df['MEDV'].values
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# Train model
forest = RandomForestRegressor(n_estimators=1000, criterion='squared_error', random_state=1, n_jobs=-1)
forest.fit(X_train,y_train)
# 模型预测
y_test_pred = forest.predict(X_test)
# 模型性能评估
mse_test = mean_squared_error(y_test, y_test_pred)
r2_test = r2_score(y_test, y_test_pred)
print("mse_test={:.2f} r2_test={:.2f}".format(mse_test, r2_test))
# 绘制残差图
plt.scatter(y_test_pred, y_test_pred-y_test, c='steelblue', edgecolor='white', marker='s', s=35, alpha=0.9,label='test data')
plt.xlabel = ('Predicted values')
plt.ylabel = ('Residuals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-10, xmax=50, lw=2, color='black')
plt.xlim([10,48])
plt.tight_layout()
plt.show()