flume
- flume概述
- flume概念
- flume概念
- flume概念
flume是分布式的,可靠的,高可用的,用于对不同来源的大量的日志数据进行有效收集、聚集和移动,并以集中式的数据存储的系统。
flume目前是apache的一个顶级项目。
-
-
- 系统需求
-
flume需要java运行环境,要求java1.6以上,推荐java1.7.
-
- 下载安装flume
- 下载flume:
- 下载安装flume
可以到apache官网下载flume的安装包。
下载时需要注意,flume具有两个版本:0.9.x和1.x,这两个版本并不兼容,我们学习的是最新的1.x版本,也叫flume-ng版本。
-
-
- 安装flume:
-
将下载好的flume安装包解压到指定目录即可。
tar -zxvf apache-flume-1.6.0-bin.tar.gz
- flume中的概念、模型和特点
- flume中的一些重要概念
- flume Event:
- flume中的一些重要概念
flume 事件,被定义为一个具有有效荷载的字节数据流和可选的字符串属性集。(json格式的字符串,由headers和body两部分组成)
-
-
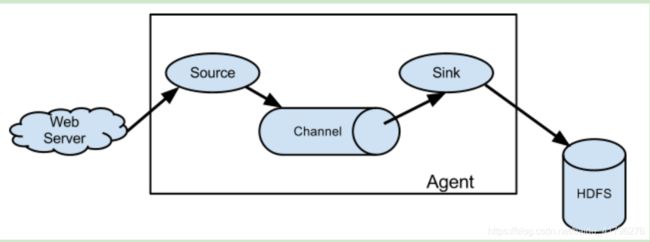
- flume Agent:
-
flume 代理,是一个进程承载从外部源事件流到下一个目的地的过程。包含source channel和sink。
-
-
- Source
-
数据源,消耗外部传递给他的事件,外部源将数据按照flume Source 能识别的格式将Flume 事件发送给flume Source。
-
-
- Channel
-
数据通道,是一个被动的存储,用来保持事件,直到由一个flume Sink消耗。
-
-
- Sink
-
数据汇聚点,代表外部数据存放位置。发送flume event到指定的外部目标。
-
- flume流动模型
- flume流动模型
- flume流动模型
- flume流动模型
-
- flume的特点
- 复杂流动性
- flume的特点
Flume允许用户进行多级流动到最终目的地,也允许扇出流(一到多)、扇入流(多到一)的、故障转移和失败处理。
-
-
- 可靠性
-
事务性的数据传递,保证了数据的可靠性。(flume一次处理一批数据,只要有任意一条失败了,那么flume会重新处理这批数据)
-
-
- 可恢复性
-
通道可以以内存或文件的方式实现,内存更快,但是不可恢复,而文件虽然比较慢但提供了可恢复性。
- 入门案例
- 编写配置文件
- 编写配置文件
- 编写配置文件
首先需要通过一个配置文件来配置Agent。
#example.conf:单节点Flume配置
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:
(1)一个配置文件中可以配置多个Agent,一个Agent中可以包含多个Source、Sink、Channel。
(2)一个Source 可以绑定到多个通道,但一个Sink只能绑定到一个通道。
-
- 通过flume的工具启动agent
- 通过flume的工具启动agent
- 通过flume的工具启动agent
$ bin/flume-ng agent --conf ../conf --conf-file ../conf/example.conf --name a1 -Dflume.root.logger=INFO,console
-
- 发送数据
- 发送数据
- 发送数据
在windows中通过命令连接flume所在机器的44444端口发送数据。
发现,flume确实收集到了该信息。
telnet ip port
#按ctrl+]后回车在界面输入数据,就可以在flume的控制台上显示数据
- Source详解
- Avro Source
- Avro Source 概述
- Avro Source
监听AVRO端口来接受来自外部AVRO客户端的事件流。
利用Avro Source可以实现多级流动、扇出流、扇入流等效果。
另外也可以接受通过flume提供的Avro客户端发送的日志信息。
-
-
- Avro Source属性说明
-
!channels –
!type – 类型名称,"AVRO"
!bind – 需要监听的主机名或IP
!port – 要监听的端口
threads – 工作线程最大线程数
selector.type
selector.*
interceptors – 空格分隔的拦截器列表
interceptors.*
compression-type none 压缩类型,可以是“none”或“default”,这个值必须和AvroSource的压缩格式匹配
ssl false 是否启用ssl加密,如果启用还需要配置一个“keystore”和一个“keystore-password”。
keystore – 为SSL提供的java密钥文件所在路径。
keystore-password – 为SSL提供的java密钥文件 密码。
keystore-type JKS 密钥库类型可以是“JKS”或“PKCS12”。
exclude-protocols SSLv3 空格分隔开的列表,用来指定在SSL / TLS协议中排除。SSLv3将总是被排除除了所指定的协议。
ipFilter false 如果需要为netty开启ip过滤,将此项设置为true
ipFilterRules – 定义netty的ip过滤设置表达式规则
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 33333
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template2.conf --name a1 -Dflume.root.logger=INFO,console
通过flume提供的avro客户端向指定机器指定端口发送日志信息:
./flume-ng avro-client --conf ../conf --host 0.0.0.0 --port 33333 --filename ../mydata/log1.txt
发现确实收集到了日志。
-
- Exec Source
- Exec Source概述
- Exec Source
可以将命令产生的输出作为源。
-
-
- Exec Source属性说明
-
!channels –
!type – 类型名称,需要是"exec"
!command – 要执行的命令
shell – A shell invocation used to run the command. e.g. /bin/sh -c. Required only for commands relying on shell features like wildcards, back ticks, pipes etc.
restartThrottle 10000 毫秒为单位的时间,用来声明等待多久后尝试重试命令
restart false 如果cmd挂了,是否重启cmd
logStdErr false 无论是否是标准错误都该被记录
batchSize 20 同时发送到通道中的最大行数
batchTimeout 3000 如果缓冲区没有满,经过多长时间发送 数据
selector.type 复制还是多路复用
selector.* Depends on the selector.type value
interceptors – 空格分隔的拦截器列表
interceptors.*
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = exec
a1.sources.r1.command = ping 192.168.242.102
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template2.conf --name a1 -Dflume.root.logger=INFO,console
可以通过tail命令,收集日志文件中后续追加的日志
-
- Spooling Directory Source
- Spooling Directory Source概述
- Spooling Directory Source
这个Source允许你将将要收集的数据放置到"自动搜集"目录中。这个Source将监视该目录,并将解析新文件的出现。事件处理逻辑是可插拔的,当一个文件被完全读入通道,它会被重命名或可选的直接删除。
要注意的是,放置到自动搜集目录下的文件不能修改,如果修改,则flume会报错。另外,也不能产生重名的文件,如果有重名的文件被放置进来,则flume会报错。
-
-
- Spooling Directory Source属性说明
-
!channels –
!type – 类型,需要指定为"spooldir"
!spoolDir – 读取文件的路径,即"搜集目录"
fileSuffix .COMPLETED 对处理完成的文件追加的后缀
deletePolicy never 处理完成后是否删除文件,需是"never"或"immediate"
fileHeader false 是否添加一个存储的绝对路径名的头文件.
fileHeaderKey file Header key to use when appending absolute path filename to event header.
basenameHeader false Whether to add a header storing the basename of the file.
basenameHeaderKey basename Header Key to use when appending basename of file to event header.
ignorePattern ^$ 正则表达式指定哪些文件需要忽略
trackerDir .flumespool Directory to store metadata related to processing of files. If this path is not an absolute path, then it is interpreted as relative to the spoolDir.
consumeOrder 处理文件的策略,oldest, youngest 或 random。
maxBackoff 4000 The maximum time (in millis) to wait between consecutive attempts to write to the channel(s) if the channel is full. The source will start at a low backoff and increase it exponentially each time the channel throws a ChannelException, upto the value specified by this parameter.
batchSize 100 Granularity at which to batch transfer to the channel
inputCharset UTF-8 读取文件时使用的编码。
decodeErrorPolicy FAIL 当在输入文件中发现无法处理的字符编码时如何处理。FAIL:抛出一个异常而无法 解析该文件。REPLACE:用“替换字符”字符,通常是Unicode的U + FFFD更换不可解析角色。 忽略:掉落的不可解析的字符序列。
deserializer LINE 声明用来将文件解析为事件的解析器。默认一行为一个事件。处理类必须实现EventDeserializer.Builder接口。
deserializer.* Varies per event deserializer.
bufferMaxLines – (Obselete) This option is now ignored.
bufferMaxLineLength 5000 (Deprecated) Maximum length of a line in the commit buffer. Use deserializer.maxLineLength instead.
selector.type replicating replicating or multiplexing
selector.* Depends on the selector.type value
interceptors – Space-separated list of interceptors
interceptors.*
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/home/park/work/apache-flume-1.6.0-bin/mydata
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template4.conf --name a1 -Dflume.root.logger=INFO,console
向指定目录中传输文件,发现flume收集到了该文件,将文件中的每一行都作为日志来处理。
-
- NetCat Source
- NetCat Source概述
- NetCat Source
一个NetCat Source用来监听一个指定端口,并将接收到的数据的每一行转换为一个事件。
-
-
- NetCat Source属性说明
-
!channels –
!type – 类型名称,需要被设置为"netcat"
!bind – 指定要绑定到的ip或主机名。
!port – 指定要绑定到的端口号
max-line-length 512 单行最大字节数
ack-every-event true 对于收到的每一个Event是否响应"OK"
selector.type
selector.*
interceptors –
interceptors.*
-
-
- 案例
-
参见入门案例。
-
- Sequence Generator Source
-
-
- Sequence Generator Source概述
-
一个简单的序列发生器,不断的产生事件,值是从0开始每次递增1。
主要用来进行测试。
-
-
- Sequence Generator Source属性说明
-
!channels –
!type – 类型名称,必须为"seq"
selector.type
selector.*
interceptors –
interceptors.*
batchSize
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = seq
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template4.conf --name a1 -Dflume.root.logger=INFO,console
发现打印了日志
-
- HTTP Source
- HTTP Source概述
- HTTP Source
HTTP Source接受HTTP的GET和POST请求作为Flume的事件,其中GET方式应该只用于试验。
该Source需要提供一个可插拔的"处理器"来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口,该处理器接受一个 HttpServletRequest对象,并返回一个Flume Envent对象集合。
从一个HTTP请求中得到的事件将在一个事务中提交到通道中。因此允许像文件通道那样对通道提高效率。
如果处理器抛出一个异常,Source将会返回一个400的HTTP状态码。
如果通道已满,无法再将Event加入Channel,则Source返回503的HTTP状态码,表示暂时不可用。
-
-
- HTTP Source属性说明
-
!type 类型,必须为"HTTP"
!port – 监听的端口
bind 0.0.0.0 监听的主机名或ip
handler org.apache.flume.source.http.JSONHandler处理器类,需要实现HTTPSourceHandler接口
handler.* – 处理器的配置参数
selector.type
selector.*
interceptors –
interceptors.*
enableSSL false 是否开启SSL,如果需要设置为true。注意,HTTP不支持SSLv3。
excludeProtocols SSLv3 空格分隔的要排除的SSL/TLS协议。SSLv3总是被排除的。
keystore 密钥库文件所在位置。
keystorePassword Keystore 密钥库密码
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 66666
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template6.conf --name a1 -Dflume.root.logger=INFO,console
通过命令发送HTTP请求到指定端口:
curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]' http://0.0.0.0:6666
发现flume收集到了日志
-
-
- 常用的Handler
-
JSONHandler
可以处理JSON格式的数据,并支持UTF-8 UTF-16 UTF-32字符集,该handler接受Evnet数组,并根据请求头中指定的编码将其转换为Flume Event。
如果没有指定编码,默认编码为UTF-8.
JSON格式如下:
--
[{
"headers" : {
"timestamp" : "434324343",
"host" : "random_host.example.com"
},
"body" : "random_body"
},
{
"headers" : {
"namenode" : "namenode.example.com",
"datanode" : "random_datanode.example.com"
},
"body" : "really_random_body"
}]
--
设置字符集时,请求必须包含content type 并设置为application/json;charset=UTF-8。
To set the charset, the request must have content type specified as application/json;charset=UTF-8 (replace UTF-8 with UTF-16 or UTF-32 as required).
One way to create an event in the format expected by this handler is to use JSONEvent provided in the Flume SDK and use Google Gson to create the JSON string using the Gson#fromJson(Object, Type) method.
Typetype=newTypeToken
BlobHandler
BlobHandler是一种将请求中上传文件信息转化为event的处理器。
参数说明,加!为必须属性:
!handler – The FQCN of this class: org.apache.flume.sink.solr.morphline.BlobHandler
handler.maxBlobLength 100000000 The maximum number of bytes to read and buffer for a given request
-
- Custom source
- Custom source概述
- Custom source
自定义源是自己实现源接口得到的,自定义源的类和其依赖包必须在开始时就放置到Flume的类加载目录下。
-
-
- Custom source属性说明
-
!channels –
!type – 类型,必须设置为自己的自定义处理类的全路径名
selector.type
elector.*
interceptors –
interceptors.*
- Sink详解
- Logger Sink
- Logger Sink概述
- Logger Sink
记录INFO级别的日志,通常用于调试。
-
-
- Logger Sink属性说明
-
!channel –
!type – The component type name, needs to be logger
maxBytesToLog 16 Maximum number of bytes of the Event body to log
要求必须在 --conf 参数指定的目录下有 log4j的配置文件
也可以通过-Dflume.root.logger=INFO,console在命令启动时手动指定log4j参数
-
-
- 案例
-
参见入门案例。
-
- File Roll Sink
- File Roll Sink概述
- File Roll Sink
在本地文件系统中存储事件,每隔指定时长生成文件保存这段时间内收集到的日志信息。
-
-
- File Roll Sink属性说明
-
!channel –
!type – 类型,必须是"file_roll"
!sink.directory – 文件被存储的目录
sink.rollInterval 30 滚动文件每隔30秒(应该是每隔30秒钟单独切割数据到一个文件的意思)。如果设置为0,则禁止滚动,从而导致所有数据被写入到一个文件中。
sink.serializer TEXT Other possible options include avro_event or the FQCN of an implementation of EventSerializer.Builder interface.
batchSize 100
-
-
- 案例
-
编写配置文件:
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 6666
#描述Sink
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory=/home/park/work/apache-flume-1.6.0-bin/mysink(修改:之前是a1.sinks.k1.dirctory,出不来结果)
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template7.conf --name a1 -Dflume.root.logger=INFO,console
-
- Avro Sink
- Avro Sink概述
- Avro Sink
Avro Sink是实现多级流动、扇出流(1到多) 和 扇入流(多到1) 的基础。
-
-
- Avro Sink属性说明
-
!channel –
!type – The component type name, needs to be avro.
!hostname – The hostname or IP address to bind to.
!port – The port # to listen on.
batch-size 100 number of event to batch together for send.
connect-timeout 20000 Amount of time (ms) to allow for the first (handshake) request.
request-timeout 20000 Amount of time (ms) to allow for requests after the first.
reset-connection-interval none Amount of time (s) before the connection to the next hop is reset. This will force the Avro Sink to reconnect to the next hop. This will allow the sink to connect to hosts behind a hardware load-balancer when news hosts are added without having to restart the agent.
compression-type none This can be “none” or “deflate”. The compression-type must match the compression-type of matching AvroSource
compression-level 6 The level of compression to compress event. 0 = no compression and 1-9 is compression. The higher the number the more compression
ssl false Set to true to enable SSL for this AvroSink. When configuring SSL, you can optionally set a “truststore”, “truststore-password”, “truststore-type”, and specify whether to “trust-all-certs”.
trust-all-certs false If this is set to true, SSL server certificates for remote servers (Avro Sources) will not be checked. This should NOT be used in production because it makes it easier for an attacker to execute a man-in-the-middle attack and “listen in” on the encrypted connection.
truststore – The path to a custom Java truststore file. Flume uses the certificate authority information in this file to determine whether the remote Avro Source’s SSL authentication credentials should be trusted. If not specified, the default Java JSSE certificate authority files (typically “jssecacerts” or “cacerts” in the Oracle JRE) will be used.
truststore-password – The password for the specified truststore.
truststore-type JKS The type of the Java truststore. This can be “JKS” or other supported Java truststore type.
exclude-protocols SSLv3 Space-separated list of SSL/TLS protocols to exclude. SSLv3 will always be excluded in addition to the protocols specified.
maxIoWorkers 2 * the number of available processors in the machine The maximum number of I/O w
-
-
- 案例1-多级流动
-
我们用三台机器h1、h2、h3来进行实验:
h3:
配置配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
h2:
配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port=9988
#描述Sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.242.139
a1.sinks.k1.port=9988
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
h1:
配置配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#描述Sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.242.138
a1.sinks.k1.port=9988
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
发送http请求到h1:
curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]' http://192.168.242.133:8888
稍等几秒后,发现h2最终收到了这条消息
-
-
- 案例2-扇出流-复制
-
h2 h3:
配置配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
h1:
配置配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1 c2
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#描述Sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.242.138
a1.sinks.k1.port=9988
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.242.135
a1.sinks.k2.port=9988
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
-
-
- 案例3-扇出流-多路复用(路由)
-
h2 h3:
配置配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9988
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
h1:
配置配置文件
#配置Agent组件
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1 c2
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=8888
a1.sources.r1.selector.type=multiplexing
a1.sources.r1.selector.header=gender
a1.sources.r1.selector.mapping.male=c1
a1.sources.r1.selector.mapping.female=c2
a1.sources.r1.selector.default=c1
#描述Sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.242.138
a1.sinks.k1.port=9988
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.242.135
a1.sinks.k2.port=9988
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template8.conf --name a1 -Dflume.root.logger=INFO,console
发送http请求进行测试。发现可以实现路由效果
-
-
- 案例4-扇入流
-
m3:
编写配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=4141
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template.conf --name a1 -Dflume.root.logger=INFO,console
m1、m2:
编写配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#描述Sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.242.135
a1.sinks.k1.port=4141
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template9.conf --name a1 -Dflume.root.logger=INFO,console
m1通过curl发送一条http请求,由于默认使用的是jsonHandler,数据格式必须是指定的json格式:
[root@localhost conf]# curl -XPOST -d '[{ "headers" :{"flag" : "c"},"body" : "idoall.org_body"}]' http://0.0.0.0:8888
m2通过curl发送一条http请求,由于默认使用的是jsonHandler,数据格式必须是指定的json格式:
[root@localhost conf]# curl -XPOST -d '[{ "headers" :{"flag" : "c"},"body" : "idoall.org_body"}]' http://0.0.0.0:8888
发现m3均能正确收到消息
-
- HDFS Sink
- HDFS Sink概述
- HDFS Sink
HDFS Sink将事件写入到Hadoop分布式文件系统HDFS中,目前支持创建文本文件和序列化文件。并且对这两种格式都支持压缩。这些文件可以按照指定的时间或数据量或事件的数量为基础进行分卷。
它还通过类似时间戳或机器属性对数据进行 buckets/partitions 操作。 HDFS的目录路径可以包含将要由HDFS替换格式的转移序列用以生成存储事件的目录/文件名。
使用HDFS Sink要求hadoop必须已经安装好,以便Flume可以通过hadoop提供的jar包与HDFS进行通信。
注意,此版本hadoop必须支持sync()调用。
-
-
- HDFS Sink属性说明
-
!channel –
!type – 类型名称,必须是“HDFS”
!hdfs.path – HDFS 目录路径 (eg hdfs://namenode/flume/webdata/)
hdfs.filePrefix FlumeData Flume在目录下创建文件的名称前缀
hdfs.fileSuffix – 追加到文件的名称后缀 (eg .avro - 注: 日期时间不会自动添加)
hdfs.inUsePrefix – Flume正在处理的文件所加的前缀
hdfs.inUseSuffix .tmp Flume正在处理的文件所加的后缀
hdfs.rollInterval 30 Number of seconds to wait before rolling current file (0 = never roll based on time interval)
hdfs.rollSize 1024 File size to trigger roll, in bytes (0: never roll based on file size)
hdfs.rollCount 10 Number of events written to file before it rolled (0 = never roll based on number of events)
hdfs.idleTimeout 0 Timeout after which inactive files get closed (0 = disable automatic closing of idle files)
hdfs.batchSize 100 number of events written to file before it is flushed to HDFS
hdfs.codeC – Compression codec. one of following : gzip, bzip2, lzo, lzop, snappy
hdfs.fileType SequenceFile File format: currently SequenceFile, DataStream or CompressedStream (1)DataStream will not compress output file and please don’t set codeC (2)CompressedStream requires set hdfs.codeC with an available codeC
hdfs.maxOpenFiles 5000 Allow only this number of open files. If this number is exceeded, the oldest file is closed.
hdfs.minBlockReplicas – Specify minimum number of replicas per HDFS block. If not specified, it comes from the default Hadoop config in the classpath.
hdfs.writeFormat – Format for sequence file records. One of “Text” or “Writable” (the default).
hdfs.callTimeout 10000 Number of milliseconds allowed for HDFS operations, such as open, write, flush, close. This number should be increased if many HDFS timeout operations are occurring.
hdfs.threadsPoolSize 10 Number of threads per HDFS sink for HDFS IO ops (open, write, etc.)
hdfs.rollTimerPoolSize 1 Number of threads per HDFS sink for scheduling timed file rolling
hdfs.kerberosPrincipal – Kerberos user principal for accessing secure HDFS
hdfs.kerberosKeytab – Kerberos keytab for accessing secure HDFS
hdfs.proxyUser
hdfs.round false 时间戳是否向下取整(如果是true,会影响所有基于时间的转移序列,除了%T)
hdfs.roundValue 1 舍值的边界值
hdfs.roundUnit 向下舍值的单位 - second, minute , hour
hdfs.timeZone Local Time Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles.
hdfs.useLocalTimeStamp false Use the local time (instead of the timestamp from the event header) while replacing the escape sequences.
hdfs.closeTries 0 Number of times the sink must try renaming a file, after initiating a close attempt. If set to 1, this sink will not re-try a failed rename (due to, for example, NameNode or DataNode failure), and may leave the file in an open state with a .tmp extension. If set to 0, the sink will try to rename the file until the file is eventually renamed (there is no limit on the number of times it would try). The file may still remain open if the close call fails but the data will be intact and in this case, the file will be closed only after a Flume restart.
hdfs.retryInterval 180 Time in seconds between consecutive attempts to close a file. Each close call costs multiple RPC round-trips to the Namenode, so setting this too low can cause a lot of load on the name node. If set to 0 or less, the sink will not attempt to close the file if the first attempt fails, and may leave the file open or with a ”.tmp” extension.
serializer TEXT Other possible options include avro_event or the fully-qualified class name of an implementation of the EventSerializer.Builder interface.
-
-
- 案例
-
编写配置文件:
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=8888
#描述Sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://0.0.0.0:9000/ppp
#文本格式,默认是序列化的格式
a1.sinks.k1.hdfs.fileType=DataStream
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume:
./flume-ng agent --conf ../conf --conf-file ../conf/template9.conf --name a1 -Dflume.root.logger=INFO,console
-
- Hive Sink
- Hive Sink概述
- Hive Sink
这个Sink可以将含分隔符的文本或JSON数据事件直接导入Hive的表或分区。
事件Event是使用Hive transactions编写的,当一组Event被提交到Hive中,它们立即可以通过Hive被查询出来。
Flume要写入数据的分区即可以预先创建好,也可以在缺失时由Flume来创建。
Flume收到的数据字段将映射到Hive表的列上。
此功能是一个预览功能,不推荐在生产环境下使用。
-
-
- Hive Sink属性说明
-
!channel –
!type – 类型,必须设置为“hive”
!hive.metastore – Hive metastore URI (eg thrift://a.b.com:9083 )
!hive.database – hive库名称
!hive.table – hive表名称
hive.partition – 逗号分开的分区值确定写入分区的列表。可以包含转义序列。
hive.txnsPerBatchAsk 100 Hive grants a batch of transactions instead of single transactions to streaming clients like Flume. This setting configures the number of desired transactions per Transaction Batch. Data from all transactions in a single batch end up in a single file. Flume will write a maximum of batchSize events in each transaction in the batch. This setting in conjunction with batchSize provides control over the size of each file. Note that eventually Hive will transparently compact these files into larger files.
heartBeatInterval 240 (In seconds) Interval between consecutive heartbeats sent to Hive to keep unused transactions from expiring. Set this value to 0 to disable heartbeats.
autoCreatePartitions true Flume will automatically create the necessary Hive partitions to stream to
batchSize 15000 Max number of events written to Hive in a single Hive transaction
maxOpenConnections 500 Allow only this number of open connections. If this number is exceeded, the least recently used connection is closed.
callTimeout 10000 (In milliseconds) Timeout for Hive & HDFS I/O operations, such as openTxn, write, commit, abort.
serializer Serializer is responsible for parsing out field from the event and mapping them to columns in the hive table. Choice of serializer depends upon the format of the data in the event. Supported serializers: DELIMITED and JSON
roundUnit minute The unit of the round down value - second, minute or hour.
roundValue 1 Rounded down to the highest multiple of this (in the unit configured using hive.roundUnit), less than current time
timeZone Local Time Name of the timezone that should be used for resolving the escape sequences in partition, e.g. America/Los_Angeles.
useLocalTimeStamp false Use the local time (instead of the timestamp from the event header) while replacing the escape sequences.
-
- Custom Sink
- Custom Sink概述
- Custom Sink
自定义接收器,是自己实现的接收器接口Sink来实现的。
自定义接收器的类及其依赖类须在Flume启动前放置到Flume类加载目录下。
-
-
- Custom Sink属性说明
-
type – 类型,需要指定为自己实现的Sink类的全路径名。
- Selector
- Selector概述
- Selector概述
- Selector概述
Selector(选择器)可以工作在复制或多路复用(路由) 模式下 。
-
- 复制模式
- Selector复制模式-属性说明
- 复制模式
selector.type replicating 类型名称,默认是 replicating
selector.optional – 标志通道为可选
-
-
- Selector复制模式-案例
-
参看5.3.4avro sink案例.
-
- 多路复用(路由)模式
- Selector多路复用(路由)模式-属性说明
- 多路复用(路由)模式
selector.type 类型,必须是"multiplexing"
selector.header 指定要监测的头的名称
selector.default –
selector.mapping.* –
举例:
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
-
-
- Selector多路复用(路由)模式-案例
-
参看 5.3.5 avro sink案例
- Interceptors
- Interceptors概述
- Interceptors概述
- Interceptors概述
Flume有能力在运行阶段修改/删除Event,这是通过拦截器(Interceptors)来实现的。
拦截器需要实现org.apache.flume.interceptor.Interceptor接口。
拦截器可以修改或删除事件基于开发者在选择器中选择的任何条件。
拦截器采用了责任链模式,多个拦截器可以按指定顺序拦截。
一个拦截器返回的事件列表被传递给链中的下一个拦截器。
如果一个拦截器需要删除事件,它只需要在返回的事件集中不包含要删除的事件即可。
如果要删除所有事件,只需返回一个空列表。
-
- Timestamp Interceptor
- Timestamp Interceptor概述
- Timestamp Interceptor
这个拦截器在事件头中插入以毫秒为单位的当前处理时间。
头的名字为timestamp,值为当前处理的时间戳。
如果在之前已经有这个时间戳,则保留原有的时间戳。
-
-
- Timestamp Interceptor属性说明
-
!interceptors.type – 类型名称,必须是timestamp或自定义类的全路径名
preserveExisting false 如果时间戳已经存在是否保留
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
-
- Host Interceptor
- Host Interceptor概述
- Host Interceptor
这个拦截器插入当前处理Agent的主机名或ip
头的名字为host或配置的名称
值是主机名或ip地址,基于配置。
-
-
- Host Interceptor属性说明
-
!type – 类型名称,必须是host
preserveExisting false 如果主机名已经存在是否保留
useIP true 如果配置为true则用IP,配置为false则用主机名
hostHeader host 加入头时使用的名称
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = timestamp
#ip是拦截者所在机器的ip
a1.sources.r1.interceptors.i2.type = host
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
-
- Static Interceptor
- Static Interceptor概述
- Static Interceptor
此拦截器允许用户增加静态头信息使用静态的值到所有事件。
目前的实现中不允许一次指定多个头。
如果需要增加多个静态头可以指定多个Static interceptors
-
-
- Static Interceptor属性说明
-
!type – 类型,必须是static
preserveExisting true 如果配置头已经存在是否应该保留
key key 要增加的透明
value value 要增加的头值
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1 i2 i3
a1.sources.r1.interceptors.i1.type = timestamp
#ip是拦截者所在机器的ip
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = country
a1.sources.r1.interceptors.i3.value = China
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
在Event的headers中有多了country=China信息
-
- UUID Interceptor
- UUID Interceptor概述
- UUID Interceptor
这个拦截器在所有事件头中增加一个全局一致性标志,其实就是UUID。
-
-
- UUID Interceptor属性说明
-
!type – 类型名称,必须是org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
headerName id 头名称
preserveExisting true 如果头已经存在,是否保留
prefix “” 在UUID前拼接的字符串前缀
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1 i2 i3 i4
a1.sources.r1.interceptors.i1.type = timestamp
#ip是拦截者所在机器的ip
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = country
a1.sources.r1.interceptors.i3.value = China
a1.sources.r1.interceptors.i4.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
作用:标识一条日志
-
- Search and Replace Interceptor
- Search and Replace Interceptor概述
- Search and Replace Interceptor
这个拦截器提供了简单的基于字符串的正则搜索和替换功能。可以修改body部分的内容
-
-
- Search and Replace Interceptor属性说明
-
type – 类型名称,必须是"search_replace"
searchPattern – 要搜索和替换的正则表达式
replaceString – 要替换为的字符串
charset UTF-8 字符集编码,默认utf-8
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1 i2 i3 i4 i5
a1.sources.r1.interceptors.i1.type = timestamp
#ip是拦截者所在机器的ip
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = country
a1.sources.r1.interceptors.i3.value = China
a1.sources.r1.interceptors.i4.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.r1.interceptors.i5.type = search_replace
#将所有的数字替换成*
a1.sources.r1.interceptors.i5.searchPattern = [0-9]
a1.sources.r1.interceptors.i5.replaceString = *
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
-
- Regex Filtering Interceptor
- Regex Filtering Interceptor概述
- Regex Filtering Interceptor
此拦截器通过解析事件体去匹配给定正则表达式来筛选事件,所提供的正则表达式即可以用来包含或刨除事件。
-
-
- Regex Filtering Interceptor属性说明
-
!type – 类型,必须设定为regex_filter
regex ”.*” 所要匹配的正则表达式
excludeEvents false 如果是true则排除匹配的事件,false则包含匹配的事件。
-
-
- 案例
-
配置文件
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1 i2 i3 i4 i5 i6
a1.sources.r1.interceptors.i1.type = timestamp
#ip是拦截者所在机器的ip
a1.sources.r1.interceptors.i2.type = host
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = country
a1.sources.r1.interceptors.i3.value = China
a1.sources.r1.interceptors.i4.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.r1.interceptors.i5.type = search_replace
#将所有的数字替换成*
a1.sources.r1.interceptors.i5.searchPattern = [0-9]
a1.sources.r1.interceptors.i5.replaceString = *
a1.sources.r1.interceptors.i6.type = regex_filter
#只要是a开头的抛弃
a1.sources.r1.interceptors.i6.regex = ^a.*
a1.sources.r1.interceptors.i6.excludeEvents = true
#描述Sink
a1.sinks.k1.type = logger
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume4.conf --name a1 -Dflume.root.logger=INFO,console
-
- Regex Extractor Interceptor
- Regex Extractor Interceptor概述
- Regex Extractor Interceptor
使用指定正则表达式匹配事件,并将匹配到的组作为头加入到事件中,它也支持插件化的序列化器用来格式化匹配到的组在加入他们作为头之前。
-
-
- Regex Extractor Interceptor属性说明
-
!type – 类型,必须是regex_extractor
!regex – 要匹配的正则表达式
!serializers – Space-separated list of serializers for mapping matches to header names and serializing their values. (See example below) Flume provides built-in support for the following serializers: org.apache.flume.interceptor.RegexExtractorInterceptorPassThroughSerializer org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer
serializers.
serializers.
serializers.* – Serializer-specific properties
-
-
- 案例
-
项目时在讲
- Processor
- 概述
- 概述
- 概述
Sink Group允许用户将多个Sink组合成一个实体。
Flume Sink Processor 可以通过切换组内Sink用来实现负载均衡的效果,或在一个Sink故障时切换到另一个Sink。
sinks – 用空格分隔的Sink集合
processor.type default 类型名称,必须是 default、failover 或 load_balance
-
- Default Sink Processor
- Default Sink Processor
- Default Sink Processor
Default Sink Processor 只接受一个 Sink。
不要求用户为单一Sink创建processor
-
- Failover Sink Processor
- Failover Sink Processor
- Failover Sink Processor
Failover Sink Processor 维护一个sink们的优先表。确保只要一个是可用的事件就可以被处理。
失败处理原理是,为失效的sink指定一个冷却时间,在冷却时间到达后再重新使用。
sink们可以被配置一个优先级,数字越大优先级越高。
如果sink发送事件失败,则下一个最高优先级的sink将会尝试接着发送事件。
如果没有指定优先级,则优先级顺序取决于sink们的配置顺序,先配置的默认优先级高于后配置的。
在配置的过程中,设置一个group processor ,并且为每个sink都指定一个优先级。
优先级必须是唯一的。
另外可以设置maxpenalty属性指定限定失败时间。
-
-
- 属性说明
-
sinks – Space-separated list of sinks that are participating in the group
processor.type default The component type name, needs to be failover
processor.priority.
processor.maxpenalty 30000 The maximum backoff period for the failed Sink (in millis)
-
-
- 案例
-
h1配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=44444
#描述Sink
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1=5
a1.sinkgroups.g1.processor.priority.k2=10
a1.sinks.k1.type =avro
a1.sinks.k1.hostname =hadoop02
a1.sinks.k1.port =44444
a1.sinks.k2.type =avro
a1.sinks.k2.hostname =hadoop03
a1.sinks.k2.port =44444
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c1
h2、h3配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port=44444
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume5.conf --name a1 -Dflume.root.logger=INFO,console
h1发送数据
curl -XPOST -d '[{ "headers" :{"flag" : "c"},"body" : "idoall.org_body"}]' http://0.0.0.0:44444
-
- Load balancing Sink Processor
- Load balancing Sink Processor
- Load balancing Sink Processor
Load balancing Sink processor 提供了在多个sink之间实现负载均衡的能力。
它维护了一个活动sink的索引列表。
它支持轮询 或 随机方式的负载均衡,默认值是轮询方式,可以通过配置指定。
也可以通过实现AbstractSinkSelector接口实现自定义的选择机制。
-
-
- 属性说明
-
!processor.sinks – Space-separated list of sinks that are participating in the group
!processor.type default The component type name, needs to be load_balance
processor.backoff false Should failed sinks be backed off exponentially.
processor.selector round_robin Selection mechanism. Must be either round_robin, random or FQCN of custom class that inherits from AbstractSinkSelector
processor.selector.maxTimeOut 30000 Used by backoff selectors to limit exponential backoff (in milliseconds)
-
-
- 案例
-
h1配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=http
a1.sources.r1.port=44444
#描述Sink 负载均衡方式
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.selector = random
a1.sinks.k1.type =avro
a1.sinks.k1.hostname =hadoop02
a1.sinks.k1.port =44444
a1.sinks.k2.type =avro
a1.sinks.k2.hostname =hadoop03
a1.sinks.k2.port =44444
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c1
h2、h3配置文件
#命名Agent组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述/配置Source
a1.sources.r1.type=avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port=44444
#描述Sink
a1.sinks.k1.type=logger
#描述内存Channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
#为Channel绑定Source和Sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume
./flume-ng agent --conf ../conf --conf-file ../conf/flume6.conf --name a1 -Dflume.root.logger=INFO,console
h1发送数据
curl -XPOST -d '[{ "headers" :{"flag" : "c"},"body" : "idoall.org_body"}]' http://0.0.0.0:44444
- Channel
- Memory Channel
- Memory Channel概述
- Memory Channel
Memory Channel,内存通道;事件将被存储在内存中的具有指定大小的队列中。
非常适合那些需要高吞吐量但是失败时会丢失数据的场景下。
-
-
- Memory Channel属性说明
-
!type – 类型,必须是“memory”
capacity 100 事件存储在信道中的最大数量
transactionCapacity 100 每个事务中的最大事件数
keep-alive 3 添加或删除操作的超时时间
byteCapacityBufferPercentage 20 Defines the percent of buffer between byteCapacity and the estimated total size of all events in the channel, to account for data in headers. See below.
byteCapacity see description Maximum total bytes of memory allowed as a sum of all events in this channel. The implementation only counts the Event body, which is the reason for providing the byteCapacityBufferPercentage configuration parameter as well. Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line). Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events (i.e. if you are using a replicating channel selector from a single source) then those event sizes may be double-counted for channel byteCapacity purposes. Setting this value to 0 will cause this value to fall back to a hard internal limit of about 200 GB.
-
-
- 案例
-
参见入门案例。
-
- JDBC Channel
- JDBC Channel概述
- JDBC Channel
事件被持久存储在可靠的数据库中。目前支持嵌入式的Derby数据库。如果可恢复性非常的重要可以使用这种方式。
-
- File Channel
- File Channel概述
- File Channel
性能会比较低下,但是即使程序出错数据不会丢失
-
-
- File Channel属性说明
-
!type – 类型,必须是“file”
checkpointDir ~/.flume/file-channel/checkpoint 检查点文件存放的位置
useDualCheckpoints false Backup the checkpoint. If this is set to true, backupCheckpointDir must be set
backupCheckpointDir – The directory where the checkpoint is backed up to. This directory must not be the same as the data directories or the checkpoint directory
dataDirs ~/.flume/file-channel/data 逗号分隔的目录列表,用以存放日志文件。使用单独的磁盘上的多个目录可以提高文件通道效率。
transactionCapacity 10000 The maximum size of transaction supported by the channel
checkpointInterval 30000 Amount of time (in millis) between checkpoints
maxFileSize 2146435071 一个日志文件的最大尺寸
minimumRequiredSpace 524288000 Minimum Required free space (in bytes). To avoid data corruption, File Channel stops accepting take/put requests when free space drops below this value
capacity 1000000 Maximum capacity of the channel
keep-alive 3 Amount of time (in sec) to wait for a put operation
use-log-replay-v1 false Expert: Use old replay logic
use-fast-replay false Expert: Replay without using queue
checkpointOnClose true Controls if a checkpoint is created when the channel is closed. Creating a checkpoint on close speeds up subsequent startup of the file channel by avoiding replay.
encryption.activeKey – Key name used to encrypt new data
encryption.cipherProvider – Cipher provider type, supported types: AESCTRNOPADDING
encryption.keyProvider – Key provider type, supported types: JCEKSFILE
encryption.keyProvider.keyStoreFile – Path to the keystore file
encrpytion.keyProvider.keyStorePasswordFile – Path to the keystore password file
encryption.keyProvider.keys – List of all keys (e.g. history of the activeKey setting)
encyption.keyProvider.keys.*.passwordFile – Path to the optional key password file
-
- Spillable Memory Channel
- Spillable Memory Channel概述
- Spillable Memory Channel
Spillable Memory Channel:内存溢出通道。
事件被存储在内存队列和磁盘中,内存队列作为主存储,而磁盘作为溢出内容的存储。
内存存储通过embedded File channel来进行管理,当内存队列已满时,后续的事件将被存储在文件通道中,这个通道适用于正常操作期间适用内存通道已期实现高效吞吐,而在高峰期间适用文件通道实现高耐受性。通过降低吞吐效率提高系统可耐受性。
如果Agent崩溃,则只有存储在文件系统中的事件可以被恢复;此通道处于试验阶段,不建议在生产环境中使用。
-
-
- Spillable Memory Channel属性说明
-
!type – 类型,必须是"SPILLABLEMEMORY"
memoryCapacity 10000 内存中存储事件的最大值,如果想要禁用内存缓冲区将此值设置为0。
overflowCapacity 100000000 可以存储在磁盘中的事件数量最大值。设置为0可以禁用磁盘存储。
overflowTimeout 3 在内存填充磁盘溢出之前等待的秒数。
byteCapacityBufferPercentage 20 Defines the percent of buffer between byteCapacity and the estimated total size of all events in the channel, to account for data in headers. See below.
byteCapacity see description Maximum bytes of memory allowed as a sum of all events in the memory queue. The implementation only counts the Event body, which is the reason for providing the byteCapacityBufferPercentage configuration parameter as well. Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line). Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events (i.e. if you are using a replicating channel selector from a single source) then those event sizes may be double-counted for channel byteCapacity purposes. Setting this value to 0 will cause this value to fall back to a hard internal limit of about 200 GB.
avgEventSize 500 Estimated average size of events, in bytes, going into the channel
-
- 自定义通道
- 自定义通道概述
- 自定义通道
自定义通道需要自己实现Channel接口。
自定义Channle类及其依赖类必须在Flume启动前放置到类加载的目录下。
-
-
- 自定义通道属性说明
-
type - 自己实现的Channle类的全路径名称