Java中的I/O通信机制模型(BIO/NIO/AIO)
文章目录
-
- 一、什么是I/O?
- 二、什么是流?
- 三、阻塞/非阻塞(相对数据而言)
- 四、同步/异步
- 五、Linux中的五种IO模型
- 六、BIO(Blocking I/O 同步并阻塞)
- 七、NIO(Non-Blocking I/O 同步非阻塞)
- 八、AIO(Asynchronous I/O 异步非阻塞)
一、什么是I/O?
I/O为input(输入)/ output(输出)的简称。
Java中I/O是以流为基础进行数据的输入输出的,所有数据被串行化(所谓串行化就是数据要按顺序进行输入输出)写入输出流。简单来说就是java通过io流方式和外部设备进行交互。
二、什么是流?
流是一个很形象的概念,当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
1、Java流的分类
(1)按流向分:
输入流: 程序可以从中读取数据的流。
输出流: 程序能向其中写入数据的流。
(2)按数据传输单位分:
字节流: 以字节为单位传输数据的流
字符流: 以字符为单位传输数据的流
(3)按功能分:
节点流: 用于直接操作目标设备的流
过滤流: 是对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能。
2、java.io常用类
JDK所提供的所有流类位于java.io包中,都分别继承自以下四种抽象流类。
(1)InputStream:
继承自InputStream的流都是用于向程序中输入数据的,且数据单位都是字节(8位)。
(2)OutputStream:
继承自OutputStream的流都是程序用于向外输出数据的,且数据单位都是字节(8位)。
(3)Reader:
继承自Reader的流都是用于向程序中输入数据的,且数据单位都是字符(16位)。
(4)Writer:
继承自Writer的流都是程序用于向外输出数据的,且数据单位都是字符(16位)。
三、阻塞/非阻塞(相对数据而言)
1、概念:
程序等待调用结果时的状态。进程访问数据的时候,数据是否就绪的一种处理状态。
2、解释:
涉及到CPU线程调度;
所谓阻塞,就是调用结果返回之前,该执行线程会被挂起,不释放CPU执行权,线程不能做其它事情,只能等待,只有等到调用结果返回了,才能接着往下执行;
所谓非阻塞,就是在没有获取调用结果时,不是一直等待,而是不间断的循环重试。
四、同步/异步
1、概念:
消息的通知机制
2、解释:
涉及到IO通知机制;
所谓同步,就是发起调用后,被调用者处理消息,必须等处理完才直接返回结果,没处理完之前是不返回的,调用者主动等待结果;
所谓异步,就是发起调用后,被调用者直接返回,但是并没有返回结果,等处理完消息后,通过状态、通知或者回调函数来通知调用者,调用者被动接收结果。
五、Linux中的五种IO模型
这里引用来自https://blog.csdn.net/weixin_45692705/article/details/118958625中的描述,以“钓鱼”为例,这位博主很有才。
这部分内容其实可以深入学习,后续会另起文章进行描述。
1、阻塞BIO(blocking I/O)
A拿着一支鱼竿在河边钓鱼,并且一直在鱼竿前等,在等的时候不做其他的事情,十分专心。只有鱼上钩的时,才结束掉等的动作,把鱼钓上来。
在内核将数据准备好之前,系统调用会一直等待所有的套接字,默认的是阻塞方式。
2、非阻塞NIO(noblocking I/O)
B也在河边钓鱼,但是B不想将自己的所有时间都花费在钓鱼上,在等鱼上钩这个时间段中,B也在做其他的事情(一会看看书,一会读读报纸,一会又去看其他人的钓鱼等),但B在做这些事情的时候,每隔一个固定的时间检查鱼是否上钩。一旦检查到有鱼上钩,就停下手中的事情,把鱼钓上来。 B在检查鱼竿是否有鱼,是一个轮询的过程。
3、异步AIO(asynchronous I/O)
C也想钓鱼,但C有事情,于是他雇来了D、E、F,让他们帮他等待鱼上钩,一旦有鱼上钩,就打电话给C,C就会将鱼钓上去。
当应用程序请求数据时,内核一方面去取数据报内容返回,另一方面将程序控制权还给应用进程,应用进程继续处理其他事情,是一种非阻塞的状态。
4.、信号驱动IO(signal blocking I/O)
G也在河边钓鱼,但与A、B、C不同的是,G比较聪明,他给鱼竿上挂一个铃铛,当有鱼上钩的时候,这个铃铛就会被碰响,G就会将鱼钓上来。
信号驱动IO模型,应用进程告诉内核:当数据报准备好的时候,给我发送一个信号,对SIGIO信号进行捕捉,并且调用我的信号处理函数来获取数据报。
5.、IO多路转接(I/O multiplexing)
H同样也在河边钓鱼,但是H生活水平比较好,H拿了很多的鱼竿,一次性有很多鱼竿在等,H不断的查看每个鱼竿是否有鱼上钩。增加了效率,减少了等待的时间。
IO多路转接是多了一个select函数,select函数有一个参数是文件描述符集合,对这些文件描述符进行循环 监听,当某个文件描述符就绪时,就对这个文件描述符进行处理。
IO多路转接是属于阻塞IO,但可以对多个文件描述符进行阻塞监听,所以效率较阻塞IO的高。
内核空间:
我们的应用程序是不能直接访问硬盘的,我们程序没有权限直接访问,但是操作系统(Windows、Linux…)会给我们一部分权限较高的内存空间,他叫内核空间,和我们的实际硬盘空间是有区别的。
下面介绍的BIO、NIO、AIO中采用的图片是引用自:《10.BIO、NIO、AIO、多路复用IO的区别(图解)》
博主图画的简单易懂,我就没有花时间去画了。
六、BIO(Blocking I/O 同步并阻塞)
1、图解

2、详解
服务器实现一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,没处理完之前此线程不能做其他操作,当然可以通过线程池机制改善。
3、适用场景
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
七、NIO(Non-Blocking I/O 同步非阻塞)
1、图解
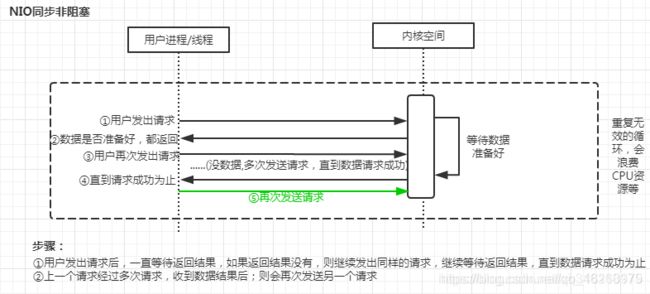
2、详解
服务器实现一个连接一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
3、适用场景
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4之后开始支持。
4、核心组件介绍
(1)通道(Channel)
Channel是一个对象,可以通过它读取和写入数据。 通常我们都是将数据写入包含一个或者多个字节的缓冲区,然后再将缓存区的数据写入到通道中,将数据从通道读入缓冲区,再从缓冲区获取数据。
Channel 类似于原I/O中的流(Stream),但有所区别:流是单向的,通道是双向的,可读可写。流读写是阻塞的,通道可以异步读写。
(2)缓冲区(Buffer)
Buffer 是一个缓冲数据的对象, 它包含一些要写入或者刚读出的数据。
在普通的面向流的 I/O 中,一般将数据直接写入或直接读到 Stream 对象中。当是有了Buffer(缓冲区)后,数据第一步到达的是Buffer(缓冲区)中。
缓冲区实质上是一个数组( 底层完全是数组实现的,感兴趣可以去看一下 )。通常它是一个字节数组,内部维护几个状态变量,可以实现在同一块缓冲区上反复读写(不用清空数据再写)。
(3)选择器(Selector)
Selector可以称他为通道的集合,每次客户端来了之后我们会把Channel注册到Selector中并且我们给他一个状态,在用死循环来判断( 判断是否做完某个操作,完成某个操作后改变不一样的状态 )状态是否发生变化,直到IO操作完成后在退出死循环。
5、对比归纳
区别对比文中已经很详细,这里就不阐述,有空再来补充,可当复习。
(1)NIO与IO区别
(2)NIO与BIO区别
6、应用
Netty是一个基于NIO的客户、服务器端编程框架,使用Netty可以确保你快速和简单的开发出一个网络应用。(Netty内容很多,后续另起文章详细介绍Netty。)
八、AIO(Asynchronous I/O 异步非阻塞)
1、图解

2、详解
服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由操作系统先完成了再通知服务器应用去启动线程进行处理。
AIO属于NIO包中的类实现,其实IO主要分为BIO和NIO,AIO只是附加品,解决IO不能异步的实现在以前很少有Linux系统支持AIO,Windows的IOCP就是该AIO模型。但是现在的服务器一般都是支持AIO操作。
3、适用场景
AIO方式适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用操作系统参与并发操作,编程比较复杂,JDK1.7之后开始支持。
梧高凤必至,花香蝶自来。