(转)关于样本标准差(SD)与样本标准误差(SE)
许多paper里经常能看到Mean±SD(SE)这样的表达方式,或者在图表里用SD或者SE来表示error bar,用SD的居多,但是也有不少用SE的。初学者很容易混淆SD(standard deviation)和SE(standard error)。
SD
SD我们都很清楚,是表达数据的离散程度,然后实际应用中很多数据具有近似正态分布的概率分布,有了SD,我们就可以大致估计数据的范围,譬如经典的"68-95-99.7法则",即约 68% 数值分布在距离平均值有 1 个标准差之内的范围,约 95% 数值分布在距离平均值有 2 个标准差之内的范围,以及约 99.7% 数值分布在距离平均值有 3 个标准差之内的范围。如下图:

SE
SE是什么呢,一般来说,自然界里很难获得总体数据,我们只能用样本(无论是各种实验还是社会调查抽样)去近似估计总体,这样问题就来了,估计的准不准(平均值)?
我们可以理论上这样做,既然不能获得总体,我们可以尽可能多(无限)的从标准差为σ的总体数据里抽取大小为 n 的样本,每个样本各有一个平均值,所有样本平均值的标准差就可以用"68-95-99.7法则"评估准不准了(这就是所谓的置信区间),样本平均值的标准差可以被证明如下公式表达:
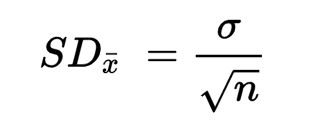
但由于通常σ为未知,此时可以用研究中取得样本的标准差 (S) 来估计:
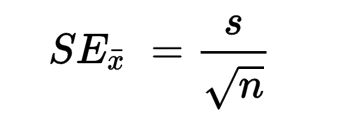
这就是SE的来源,即 样本平均值的SD,我们用MATLAB编程演示下。
MATLAB演示
以掷硬币为例,掷100次,统计正面(1)的次数,共统计1000次作为一个sample,然后我们这样采1000个sample(程序不怕累的)。
先贴结果,代码放后面。结果如下,我们能看到样本平均值的SD基本等于样本的SE!

完整代码如下:
-
%1000个样本(sample)
-
sample_mean = []
-
-
for m=1:1000
-
-
%掷硬币100次,统计正面的次数,共统计1000次作为一个sample
-
sample = []
-
for i = 1:1000
-
box = randi([0,1],100,1);
-
sample = [sample length(box(box==1))];
-
end
-
sample_mean = [sample_mean mean(
sample)];
-
end
-
-
%
sample的标准差和标准误
-
SD_sample =
std(
sample)
-
SE_sample = SD_sample/
sqrt(
1000)
-
%
sample平均值的标准差
-
SD_sample_mean =
std(sample_mean)
结论
1、标准差(SD)更能反应离散程度。
paper里需要Mean±SD这个信息,就是便于读者进行判断数据的离散性,e.g.,一般我们把偏离平均值2或3个SD的值作为outlier(i.e., 异常值)。
2、标准误则比较适合用于评估精确性或准确性的问题。
paper里根据需要也可以提供Mean±SE这个信息,就是便于读者进行判断数据的不确定性,e.g.,95%置信区间是用的Mean ± 2*SE。
无论用哪种表达方式,一定要注意标明,特别是error bar,好的paper都会说明这是什么的。