正则表达式引擎比较(翻译自:A comparison of regex engines)
原文: A comparison of regex engines – Rust Leipzig
引言
正则表达式(或简称regex)通常用于模式搜索算法。 有许多不同的正则表达式引擎提供不同的表达式支持、性能约束和语言绑定。 基于 John Maddock 之前的工作 (regex comparison)和 sljit 项目( regex comparison),这里概述下几个活跃开发的引擎的性能。
搭建测试
硬件
这里的性能仅在我的戴尔笔记本上测试。它并不是最新的,但这并不重要,因为我对所有引擎使用相同的硬件,并且我对不同引擎性能比较的结果感兴趣。 这里是硬件信息:
- Chassis: Dell Latitude E7450
- CPU: Intel® Core™ i5-5300U
- RAM: 16GB
- SSD: Samsung PM85 256GB
软件
这里并非使用最新的软件,但也比 Ubuntu 16.04 系统默认的软件包更新了
- GCC 6.2.0
- Rustc 1.16.0 and 1.17.0-nightly
我想知道用不同引擎匹配以下每一项的执行时间:
Twain(?i)Twain[a-z]shingHuck[a-zA-Z]+|Saw[a-zA-Z]+\b\w+nn\b[a-q][^u-z]{13}xTom|Sawyer|Huckleberry|Finn(?i)Tom|Sawyer|Huckleberry|Finn.{0,2}(Tom|Sawyer|Huckleberry|Finn).{2,4}(Tom|Sawyer|Huckleberry|Finn)Tom.{10,25}river|river.{10,25}Tom[a-zA-Z]+ing\s[a-zA-Z]{0,12}ing\s([A-Za-z]awyer|[A-Za-z]inn)\s["'][^"']{0,30}[?!\.][\"']\u221E|\u2713\p{Sm}
也许以上表达式集合不够代表性,但也足以提供一个参考.
为了测量性能,我修改了 sljit 项目现有的基准测试工具。 该工具可在 github 上找到: regex-performance. sljit 项目的基础工具已经支持以下正则表达式引擎:
- Oniguruma, v6.1.3
- RE2
- Tre
- PCRE2, v10.23
这里我多加2种引擎:
- Hyperscan, v4.4.1
- Rust regex crate, v0.2.1
PCRE2
Perl 兼容正则表达式 (PCRE) 是一个正则表达式 C 库,其灵感来自于 Perl 编程语言中的正则表达式功能。 PCRE2 是 PCRE 库修订后的 API 的名称。
除了标准匹配算法之外,PCRE2 还附带了一种基于确定性有限自动机 (DFA) 的替代算法,该算法运行方式不同且不与 Perl 兼容。 手册页中提供了详细的描述。
此外PCRE2还提供了重量级优化:即时(JIT)编译可以大大加快模式匹配速度。
为了获得可比较的结果,必须使用配置选项 --enable-unicode 启用 Unicode 支持。 JIT 功能是可选的,必须配合选项 --enable-jit 启用。
Hyperscan
Hyperscan 是 01.org 开源项目:
Hyperscan 是一个高性能的多正则表达式匹配库。 它遵循常用的 libpcre 库的正则表达式语法,但作为一个独立的库且用 C 编写了 API。Hyperscan利用混合自动机技术,可以同时匹配大量的正则表达式,以及在数据流中匹配正则表达式。
Hyperscan是经过10多年开发的成熟的库。Hyperscan着重的是x86平台,并且该库使用硬件加速器(如AVX)来优化吞吐量。
默认情况下,Hyperscan不考虑匹配的起始位置。要获取匹配的起始位置,需要在编译模式时设置标志HS_FLAG_SOM_LEFTMOST。这个标志会带来一些性能损失,但是在需要可比较结果时是必需的。
Rust 正则表达式箱
Rust 箱是“库”或“包”的同义词。Rust 正则表达式箱提供了解析、编译和执行正则表达式的函数:
它的语法类似于 Perl 风格的正则表达式,但缺少一些功能,例如环视和反向引用。 但带来的好处是,所有搜索的时间复杂度都与正则表达式和搜索文本的长度成线性关系。
除了Rust crate之外,所有引擎都是使用C或C++编写的,包括测试工具。使用的引擎必须有C绑定,因此需要一个接口来调用Rust函数。该解决方案利用Rust的FFI(外部函数接口)构建一个静态库,该库只会计算给定表达式的匹配次数。完整的库包含3个函数,总共不到50行代码。获取匹配项的主要Rust函数是::
#[no_mangle]
pub extern fn regex_matches(raw_exp: *mut Regex, p: *const u8, len: u64) -> u64 {
let exp = unsafe { Box::from_raw(raw_exp) };
let s = unsafe { slice::from_raw_parts(p, len as usize) };
let findings = exp.find_iter(s).count();
Box::into_raw(exp);
findings as u64
}
该函数接受一个先前编译的表达式的原始指针(raw_exp)、一个输入C字符串的原始指针(p)以及输入字符串的长度(len)。首先,函数从相应的原始指针中获取编译后的表达式和输入字符串。将原始指针转换为类型是不安全的操作,因此代码部分必须用unsafe{}包装起来。然后,通过调用exp.find_iter(s).count()来获取匹配项的数量。为了在后续函数调用中使用编译后的表达式,再次获取表达式的原始指针。这样做的结果是,在返回后,表达式的生命周期仍然存在。最后,该函数将匹配项的数量作为64位值返回给调用者。
对应的C函数原型是:
struct Regex; // anonymous declaration
extern uint64_t regex_matches(struct Regex const * const exp, uint8_t * const str, uint64_t str_len);
结果
在工具构建路径执行以下命令以获取测试结果:
./src/regex_perf -f ../3200.txt -o results.csv
工具将细节打印如下,每个引擎的结果保存到 results.csv. 最后还打印了结果的简要总结:
Total Results:
[ pcre] time: 12626.7 ms, score: 8 points,
[ pcre-dfa] time: 14135.2 ms, score: 0 points,
[ pcre-jit] time: 1050.6 ms, score: 47 points,
[ re2] time: 946.1 ms, score: 26 points,
[ onig] time: 2475.8 ms, score: 4 points,
[ tre] time: 10508.4 ms, score: 0 points,
[ hscan] time: 299.7 ms, score: 72 points,
[rust_regex] time: 3681.5 ms, score: 47 points,
Timings
根据CSV文件我做了一些分析。首先我计算了每个引擎的总体执行时间。详见下图:
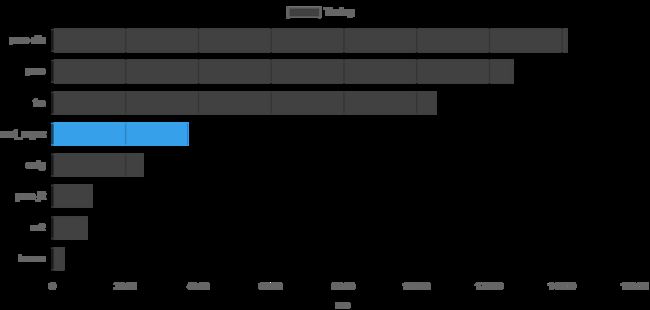
Hyperscan是最快的引擎,总执行时间约为300毫秒(比第二名少约3倍),而Rust的正则表达式库在排名中位列第5,总执行时间约为3700毫秒。看来Rust的正则表达式库并不是最快的解决方案。
但是,如果一个表达式非常慢会发生什么呢?这个测试会扭曲引擎的整体结果。因此,我实现了一个简单的结果评分系统。对于每个测试,最快的引擎可以得到5分,第二名得到4分,依此类推。这限制了单个慢表达式的影响。以下图表显示了每个引擎的得分点数:
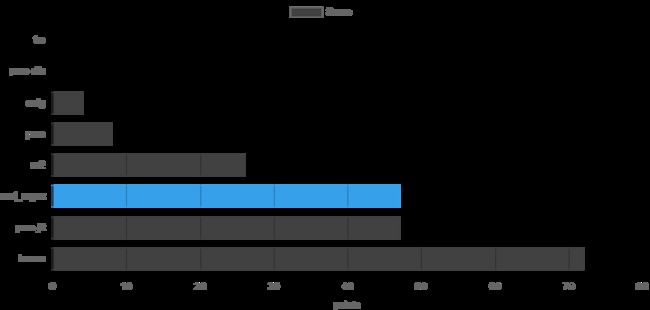
Hyperscan仍然是第一名,但Rust的正则表达式库与PCRE2-JIT并列第二。结果比绝对时间看起来更好,但似乎有一个或多个表达式的执行时间很慢。
因此,现在是时候查看每个表达式的结果了。以下图表将所有引擎每个表达式的平均时间与Rust的测量值进行了比较。次要的y轴显示了Rust值与平均值的比例,以百分比表示。
.
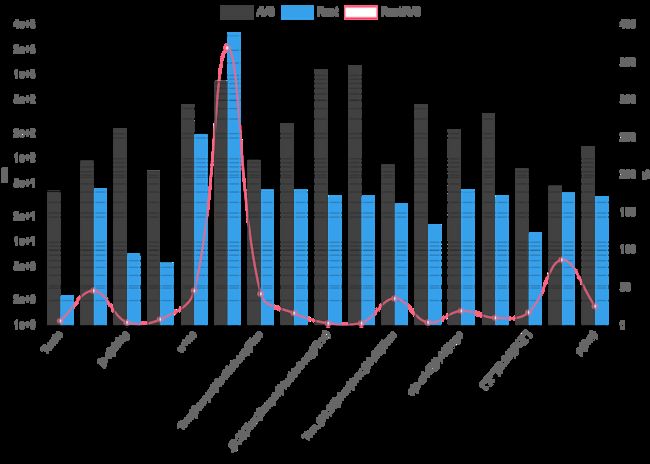
红色曲线有3个主要的峰值,即正则表达式库性能不佳的表达式。这些表达式是:
[a-q][^u-z]{13}x∞|✓(?i)Twain
特别是这三个表达式中的第一个执行非常缓慢。
改进
根据基准测试的初步结果,我开了一个投票 rust-lang/regex/350 来汇报我的发现以获得些反馈。Andrew Gallant(化名BurntSushi)给了我很好的反馈和一些改进建议。
其中一项改进是使用正则表达式库的SIMD功能。这个功能目前在Rust Nightly构建中可用,因此我需要安装Nightly工具链。我调整了项目的CMake脚本,以检测是否使用了Nightly编译器并支持SIMD功能。因此,可以使用rustup default nightly-x86_64-unknown-linux-gnu切换Rust工具链,并重新配置和构建工具以获取新的结果。
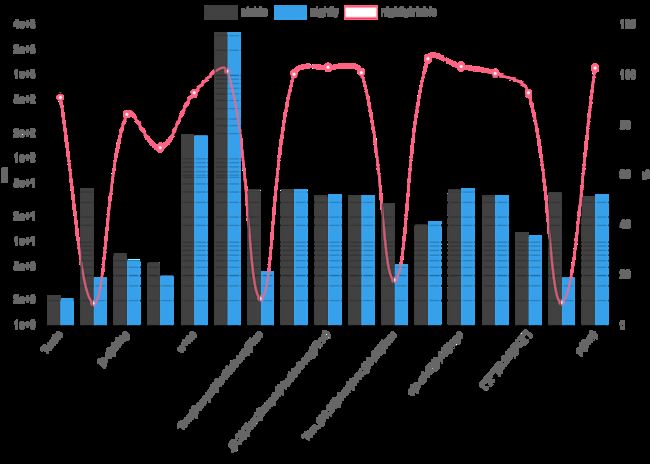
图表显示,表达式∞|✓和(?i)Twain通过使用SIMD功能受益,但表达式[a-q][^u-z]{13}x则不受益。这个表达式需要回溯。Rust的正则表达式库使用基于有限状态机(DFA)的算法,缺乏反向引用和回溯功能。.
匹配
Regarding the found matches I found some deviations. At first, the libraries oniguruma and tre do not support Unicode category expressions like \p{Sm}. This expression matches all mathematical symbols like = or |. The Rust regex crate matches additionally the symbol ∞.
Hyperscan returns more matches than other engines, e.g. 977 for the expression Huck[a-zA-Z]+|Saw[a-zA-Z]+ whereas all other engines are finding 262 matches. Hyperscan reports all matches. The expression Saw[a-zA-Z]+ returns the following matches for input Sawyer:
从找到的匹配项中我发现了一些差异。首先,oniguruma和tre库不支持Unicode类别表达式,如\p{Sm}。这个表达式匹配所有的数学符号,比如=或|。而Rust的正则表达式库还额外匹配了符号∞。
Hyperscan返回的匹配项比其他引擎多,例如对于表达式Huck[a-zA-Z]+|Saw[a-zA-Z]+,Hyperscan返回了977个匹配项,而其他引擎只找到了262个匹配项。Hyperscan报告了所有的匹配项。对于输入"Sawyer",表达式Saw[a-zA-Z]+返回了以下匹配项:
- Sawy
- Sawye
- Sawyer
其他所有引擎只报告了一个匹配项:Sawy(非贪婪语义)或Sawyer(贪婪语义)。
结论
Rust正则表达式库已经推出约2年了,但它趋向于超越像PCRE2和Hyperscan这样成熟的引擎。根据使用的表达式,Rust正则表达式库是进行模式匹配的好选择。感谢正则表达式库的所有贡献者以及他们令人惊叹的工作。.
相关工作
regex crate包含自己的基准测试框架,其中包含许多表达式,并支持以下功能:
- PCRE
- PCRE2
- RE2
- Oniguruma
- TCL
这个基准测试可以用来从另一个角度评估引擎的性能。请查看crates存储库中的bench子目录。