单词拼写检查笔记
序
最近在看自然语言处理方面的书籍,也写写相关的读书笔记吧
英语单词拼写是文字录入,编辑,出版等工作中的一项重要任务。实现单词拼写检测的方法很多,我这里就暂时写2个,第一个是在《统计自然语言处理》书中的 K.Oflazer用有限自动机写的,第二个是在网上看见的一个20几行python代码写的《How to Write a Spelling Corrector》
自动机法
基于优先自动机的识别器,可以看成由所有正确的单词构成的一个有向图:
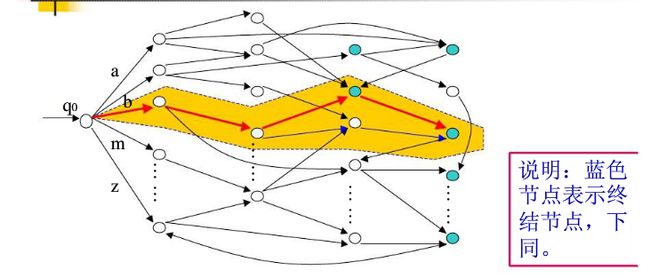
每个正确的单词都是一条由起始位置(q0)到一个蓝色节点的一条路径,路径上的所有弧组合起来就是该单词。
现在,我们需要作的是:对于一个输入的单词,找出编辑距离(网上这方面的文章很多)小于t的所有路径。如果使用穷举法,是可以做到的。但是为了提高搜索速度,我们必须要尽早的把那些编辑距离超过给定阀值的路劲剪枝。
剪除距离
设Y是一个候选的字符串(拼写正确),长度为n
设X是出错的字符串,长度为m
我们确定2个边界,一个是n-t,一个是n+t
为什么确定这2个边界呢?对于长度小于n-t的X子串,至少需要大于t次插入操作,对于长度大于n+t的X的子串,需要大于t次的删除操作,以上2种情况都不符合要求。
考虑2个字符串的长度,把边界定义为 l=max(1,n−t),u=min(m,n+t)
所以,我们得出剪除距离为: cuted(X,Y)=min(ed(X[i],Y)),l≤i≤u
其中 ed(X[i],Y) 表示X前i个字符组合的子字符串与x的编辑距离
拿书上的例子说明下:

因此,可以通过稍微修改图的深度优先搜索算法来实现Y的生成过程,算法描述如下:
伪代码
/*将一个空字符串和初始结点压栈*/
push((ε,q_0));
while stack!=NULL{
/*从栈顶弹出一个部分字符串Y'和状态节点,第一次执行的时候,弹出的初始节点q_0*/
pop((Y',q_i));
/*找出该节点的下一条弧,弧上的字母记为a*/
for q_j,δ(q_i,a)=q_j{
/*扩展候选串,把字符a连接到Y'*/
Y=concat(Y',a);
/*保证满足剪除距离*/
if(cuted(X,Y)<=t)
push((Y,q_j));
/*找到一个候选字符串*/
if(ed(X,Y)<=t and q_j=Final)
output(Y)
}
}
该算法的还有一个关键的地方,因为每次扩展候选字符串的时候,都要计算剪除距离,所以,通过构造一个mxn的H矩阵,从而可以快速的计算出剪除距离。H矩阵的元素 hij=ed(X[i],Y[j]) ,我们在计算编辑距离的时候,也是构造一个矩阵,并且 hi+1,j+1 的计算,只依赖于 hi,j,hi,j+1,hi+1,j 三项,所以,在深度优先搜索过程中,只有候选字符串长度达到n的时候,H矩阵的第n列才会被重新计算,在回溯过程中,最后一列的项也会丢弃,但是前面列中的数据任然有效。这样,在计算 hi+1,j+1 的时候,只用计算 hi,j+1
How to Write a Spelling Corrector
原文地址http://www.norvig.com/spell-correct.html
先贴代码感受一下
import re, collections
def words(text): return re.findall('[a-z]+', text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(file('big.txt').read()))
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [a + b[1:] for a, b in splits if b]
transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b)>1]
replaces = [a + c + b[1:] for a, b in splits for c in alphabet if b]
inserts = [a + c + b for a, b in splits for c in alphabet]
return set(deletes + transposes + replaces + inserts)
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words): return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)分析
NWORDS = train(words(file(‘big.txt’).read()))
big.txt 类似于语料库,统计每个单词出现的数量,通过这个数量来判断某个单词是否是常用单词,并生成一个字典NWORDS
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [a + b[1:] for a, b in splits if b]
transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b)>1]
replaces = [a + c + b[1:] for a, b in splits for c in alphabet if b]
inserts = [a + c + b for a, b in splits for c in alphabet]
return set(deletes + transposes + replaces + inserts)
给定一个单词,找出所有编辑距离为1的单词。
如果一个单词的长度为n,那么通过删除一个字符生成n-1个单词,通过改变相邻位置,生成n-1个单词,通过改变一个字符,生成26n个单词,通过插入有26(n+1)个单词,所有总共有生成54n+25
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
找出一个单词的编辑距离为2的单词,并且这个单词在字典NWORDS出现过。
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)
判断的一个单词的正确性,如果这个单词在字典中出现过,那么认为是正确的,
如果不是正确的,则返回编辑距离最短,如果编辑距离一样,则返回在字典中出现次数最多的
原理
如果我们用c表示在字典中出现过的正确单词,用w表示待检测的单词
那么目标为
根据贝叶斯公式,则变换为
由于P(w)对于每个c都是一样的,所以可以忽略掉这一项,原式等价于:
按照作者的意思,P(c)可以理解为一个单词出现的频率,可以用字典中,c出现的次数来等价表示
P(w|c) 是一个人写w的时候,他本来是打算是写c的概率(he probability that w would be typed in a text when the author meant c),通过这个 程序来看,也就是编辑距离
然后作者也说明了,为什么计算到编辑距离2就可以了,因为他通过实验得出,当只计算编辑距离为1的时候,只有 76% 的正确率,当编辑距离为2的时候,提升到 98.9%。