医学图像分割UNet
UNet图像分割
- pytorch-gpu环境配置
-
- 安装pytorch-gpu
- 验证安装是否成功
- 数据预处理
- 训练模型
- 测试并显示结果
- 完整代码
pytorch-gpu环境配置
安装pytorch-gpu
1、在线安装
(已配置CUDA11.3,Cudnn8.0,Anaconda新建环境Python=3.9)
进入官网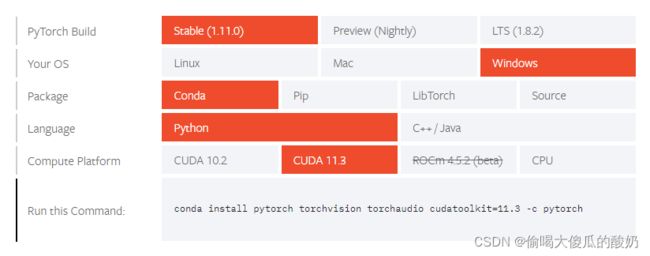
//配置清华源
http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud//pytorch/win-64
http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64
http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64
//去掉-c pytorch,使用清华源进行下载安装
conda install pytorch torchvision torchaudio cudatoolkit=11.3
2、离线安装
首先查询需要安装的各版本对应情况
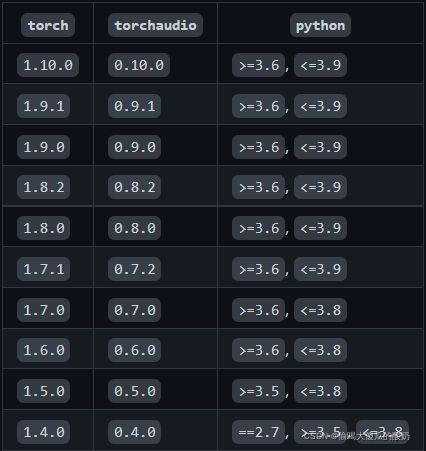
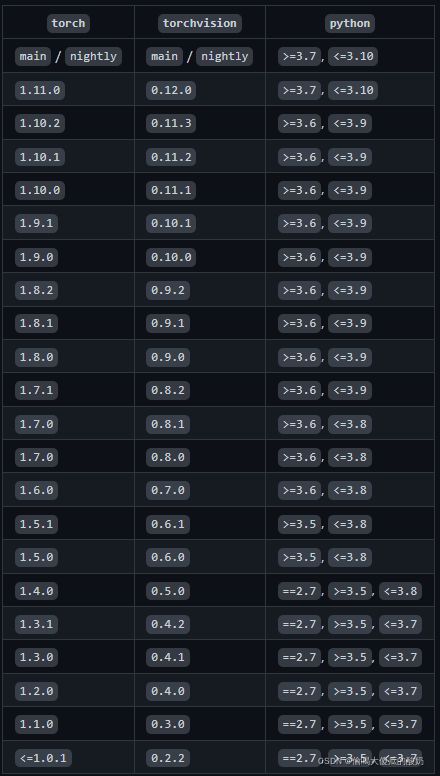
我安装的是torch = 1.10.0,torchvision= 0.11.1, torchaudio = 0.10.0
下载对应的文件(注意如果要安装gpu版本的pytorch,请选择标注了cuda版本的文件并保证cuda与torch的版本对应)下载地址
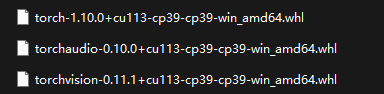
其中cu113表示对应的是cuda11.3版本
下载完成后将文件放在对应的 lib/site-packages文件夹下,开始安装:

验证安装是否成功
//进入Python3.9环境
import torch
torch.__version__ # 查看torch版本
torch.cuda.is_available() # 查看gpu是否可用(返回true表示pytorch-gpu安装成功)
若输出结果如下,则安装成功:

数据预处理
下载BraTS19数据集
将三维数据转换为二维数据(自行选择如何切分训练集和测试集),并保存至文件夹中
def read_img(img_path):
return sitk.GetArrayFromImage(sitk.ReadImage(img_path))
if __name__ == '__main__':
flair_train = glob.glob(r'F:/MICCAI_BraTS_2019_Data_Training/MICCAI_BraTS_2019_Data_Training/HGG/*/*flair.nii.gz')
seg_train = glob.glob(r'F:/MICCAI_BraTS_2019_Data_Training/MICCAI_BraTS_2019_Data_Training/HGG/*/*seg.nii.gz')
flair_test = glob.glob(r'F:/MICCAI_BraTS_2019_Data_Training/MICCAI_BraTS_2019_Data_Training/*/*flair.nii.gz')
seg_test = glob.glob(r'F:/MICCAI_BraTS_2019_Data_Training/MICCAI_BraTS_2019_Data_Training/*/*seg.nii.gz')
print('begin')
for i in range(len(flair_train)):
print(i)
img1 = (read_img(flair_train[i])[100]).astype(np.uint8)
img2 = (read_img(seg_train[i])[100]).astype(np.uint8)
dir = 'data/train/'
filename1 = dir + format(str(i), '0>3s') + '.png'
plt.imshow(img1)
plt.axis('off')
plt.savefig(filename1, bbox_inches='tight',pad_inches=0)
filename2 = dir + format(str(i), '0>3s') + '_mask.png'
plt.imshow(img2)
plt.axis('off')
plt.savefig(filename2, bbox_inches='tight',pad_inches=0)
print('over')
训练模型
def train_model(model, criterion, optimizer, dataload, num_epochs=20):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
dt_size = len(dataload.dataset)
epoch_loss = 0
step = 0
for x, y in dataload:
step += 1
inputs = x.to(device)
labels = y.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
labels = labels[:,0,:,:]
print(labels.shape)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print("%d/%d,train_loss:%0.3f" % (step, (dt_size - 1) // dataload.batch_size + 1, loss.item()))
# # 可视化
# writer = SummaryWriter(log_dir='logs', flush_secs=60)
# writer.add_scalar('Train_loss', loss, epoch)
torch.save(model.state_dict(), 'weights_%d.pth' % epoch)
return model
# 训练模型
def train():
model = Unet(3, 1).to(device)
batch_size = args.batch_size
criterion = torch.nn.BCELoss()
optimizer = optim.Adam(model.parameters())
liver_dataset = LiverDataset("data/train", transform=x_transforms, target_transform=y_transforms)
dataloaders = DataLoader(liver_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# print(dataloaders)
train_model(model, criterion, optimizer, dataloaders)
测试并显示结果
def test():
model = Unet(3, 1)
model.load_state_dict(torch.load(args.ckp, map_location='cpu'))
liver_dataset = LiverDataset("data/val", transform=x_transforms, target_transform=y_transforms)
dataloaders = DataLoader(liver_dataset, batch_size=1)
model.eval()
# plt.ion()
with torch.no_grad():
for x, true_y in dataloaders:
y = model(x)
img_y = torch.squeeze(y).numpy()
x = tensor_to_PIL(x)
true_y = tensor_to_PIL(true_y)
plt.figure()
plt.subplot(1, 3, 1)
plt.imshow(x)
plt.subplot(1, 3, 2)
plt.imshow(img_y)
plt.subplot(1, 3, 3)
plt.imshow(true_y)
plt.pause(0.1)
plt.show()
完整代码
链接:https://pan.baidu.com/s/15odtjD6HGdBcPl7YBPiw2Q
提取码:ky78