【ElasticSearch系列-02】ElasticSearch的概念和基本操作
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
深入理解ElasticSearch概念和基本操作
-
- 1,ES的基本概念
- 2,ES的基本操作
-
- 2.1,索引的创建和删除
- 2.2,文档的增删改查
- 3,mapping
-
- 3.1,静态映射和动态映射
- 3.2,reindex重建索引
- 3.3,常用mapping参数设置
1,ES的基本概念
在上一篇中,讲解了ElasticSearch的搭建以及Kibana的搭建,接下来就可以去了解其内部原理了,从es的官网上可以看到,ElasticSearch主要的一些应用,如做系统日志,大数据分析,搜索引擎,性能监控等等
ElasticSearch同时也支持RestFulf风格,这样就可以通过HTTP来操作ES中的数据,可以达到实时搜索,稳定,可靠等强大性能,同时也支持多种客户端语言,其生态圈也相当友好,版本还在一直迭代更新。
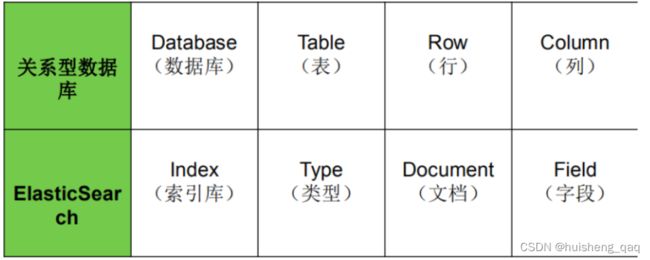
在关系型数据库中,如mysql,内部有库、表、行列等,在ElasticSearch中,也存在着和其一样概念的类型数据,如下图,Index对应的就是数据库,Type类型对应的就是表,Document文档对应的就是行,Field字段对应的就是列。在7.0开始后,一个索引库中只能存在一种类型。
2,ES的基本操作
2.1,索引的创建和删除
索引的创建方式如下,需要注意的是,索引的名称必须全部小写,否则会报错
PUT /zhs_db
接下来查看索引的信息,直接通过GET命令即可
GET /zhs_db
在使用GET命令后,在控制台会出现以下数据,一些别名,创建时间,索引的分片数,副本数据等
{
"zhs_db" : {
"aliases" : { },
"mappings" : { }, //映射关系,每个字段的数据和类型
"settings" : {
"index" : {
"creation_date" : "1695018423771", //创建索引的时间
"number_of_shards" : "1", //分片数
"number_of_replicas" : "1", //副本数
"uuid" : "eHD7DY1eR7Ki4zm1QKXzrg", //uuid
"version" : { //版本号
"created" : "7070099"
},
"provided_name" : "es_db"
}
}
}
}
删除索引库的方式如下,可以直接通过DELETE的方式直接删除
DELETE /zhs_db
2.2,文档的增删改查
在ES中,文档就是相当于mysql表中的一条数据,只不过ES是通过序列化后的JSON的方式保存,JSON数据中支持层层嵌套,接下来举一个例子来说明文档的含义
首先创建一个索引库,并设置分词器为IK分词器,粒度设置为细粒度。
PUT /zhs_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
由于本人使用的是7.7.0的版本,因此type类型可以不需处理。随后往文档中插入几条数据,其数据如下
PUT /zhs_db/_doc/1
{
"name": "zhenghuisheng",
"sex": 1,
"age": 18,
"dept": "团长",
"remark": "tz"
}
PUT /zhs_db/_doc/2
{
"name": "xiaozheng",
"sex": 1,
"age": 19,
"dept": "连长",
"remark": "lz"
}
PUT /zhs_db/_doc/3
{
"name": "郑跟班",
"sex": 0,
"age": 20,
"dept": "班长",
"remark": "bz"
}
添加文档除了使用这个PUT请求之外,还可以使用POST请求。PUT请求需要手动的指定一个id才能操作,而POST请求如果在没指定id的情况下,ES内部会自动的生成一个id,如果指定了,就用指定的id。如下图,ES内部自动的生成了一个id
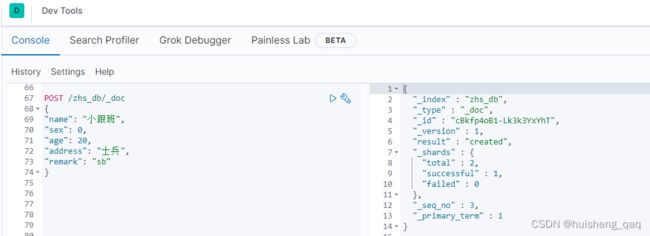
并且无论是PUT请求还是POST请求,在重复进行数据的插入时,会出现数据覆盖的情况,类似于先删除后覆盖。
也存在直接创建完,不需要进行更新和删除操作的,就是需要用到create的语法,如果已经存在这个id对应的文档,那么就会直接抛异常
PUT /zhs_db/_created/1
在通过id获取某条文档数据的时候比较简单,只需要索引库 + _doc + 文档对应的id即可
GET /zhs_db/_doc/1
在获取这个zhs_db索引库的时候,其结果如下。每个字段中可以包含数值、字符串、布尔类型、日期、二进制等
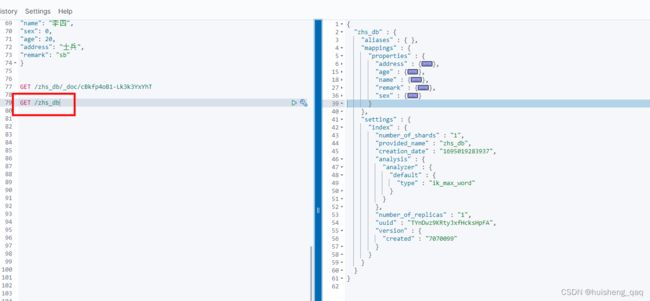
在重复执行查询文档数据时,该条文档的version版本号和seq序列号会跟着改变,并且result的 状态会从创建的 created 状态变成 updated 状态。
"_version" : 23, // 版本号
"_seq_no" : 22, // 序列号
或者直接通过 _search 的方式将数据查出,这里面也可以写一些SDL语法进行匹配模式
GET /zhs_db/_search
更新可以直接使用POST的方式进行更新操作,只需要通过 _update 就可以实现更新操作。
POST /zhs_db/_update/1
也可以只更新某个文档中的部分数据,如只更新文档中的某一个字段
POST /zhs_db/_update/1
{
"name":"王五"
}
除了这两种方式是属于更新操作之外,上面的重复插入操作也会有更新的效果,如修改序列号等等。
通过id删除文档也比较简单,只需要通过DELETE关键字即可
DELETE /zhs_db/_doc/2
在7.x版本之前,为了保证多线程场景下的线程安全,采用通过version版本号来实现乐观锁,但是在7.x开始,是通过**_seq_no** 和 _primary_term 字段来保证乐观锁的
POST /zhs_db/_update/3?if_seq_no=21&if_primary_term=6
{
"name": "赵六"
}
3,mapping
3.1,静态映射和动态映射
动态映射指的是Es在插入数据时,不需要手动的指定插入字段的数据类型,es内部会自动的根据对应的数据类型转成相应的数据类型,内部有自动识别机制
PUT /zhs_db/_doc/1
{
"age":10,
"name":"zhenghuisheng"
}
GET /zhs_db
其结果如下,可以看到在mapping中的属性age和name给了对应的属性。text类型则表示是可以全文检索的数据类型
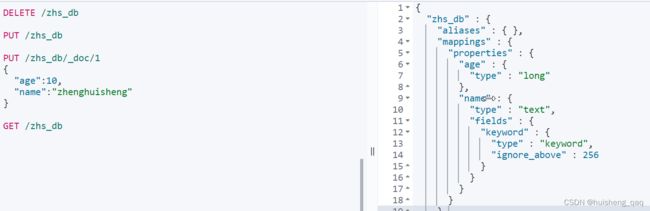
静态映射指的是在创建索引时,同时将文档中字段的数据类型也设置好
DELETE /zhs_db
PUT /zhs_db
{
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
在es的动态映射中,其对应的数据类型如下,有这些对应的字符串类型,布尔类型,浮点型,整型,对象,数组等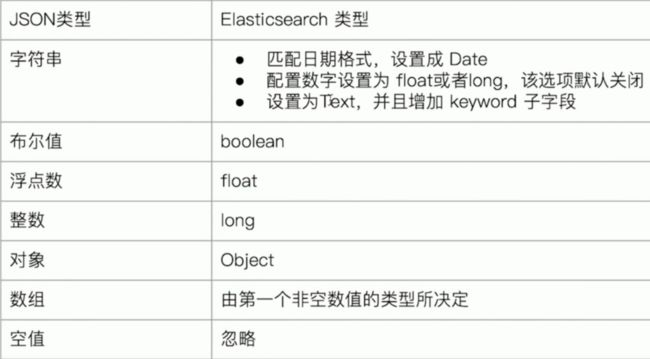
在mapping建立好之后,可能会遇到新增或者删除字段的情况,因此可以直接通过这个dynamic这个属性控制
- 当该属性为true时,一旦有新的文档写入,mapping也会自动更新
- 当该属性为false时,mapping不会被更新,新增的字段内容无法被索引查询
- 当该属性为strict时,文档直接写入失败,并且同时抛出异常
PUT /zhs_db/_mapping
{
"dynamic":true
}
3.2,reindex重建索引
如果是索引的文档中已经有了数据,那么就不支持修改操作,只能重新的建立索引,然后将原索引的数据迁移到新的索引中。那么就需要通过这个 _reindex 这个命令,source设置为需要修改的索引,dest设置为新建的索引
POST _reindex
{
"source": { //原索引
"index": "zhs_db"
},
"dest": {
"index": "zhs_db2"
}
}
并且为了解决接口调用的问题,因为此时索引已经从zhs_db变成了zhs_db2,所以可以通过修改别名的方式,减少上层代码的变动,需要先将原索引删除,随后将新索引的别名设置成原索引的名称
DELETE /zhs_db
PUT /zhs_db2/_alias/zhs_db
在查这个新的索引 zhs_db2 时,只需要查询原来的 zhs_db,就能将原数据全部查询出
GET /zhs_db
3.3,常用mapping参数设置
如果不想被索引,可以直接在对应的字段加上index这个属性,并且设置value为false
{
"mappings" : {
"properties" : {
"name":{
"type": "text",
"index": false
}
}
}
}
如果需要在有索引的字段中将为null的值查询出,那么可以设置一个 null_value的属性,并将值设置成null
{
"mappings" : {
"properties" : {
"name":{
"type": "text",
"null_value": "NULL"
}
}
}
}
如果是需要字段合并的场景,如省市区等的合并等,那就需要借助于这个 copy_to 这个属性,可以将这个值全部添加到这个full_address这个属性中,后续可以直接通过查询这个 full_address 这个属性将需要匹配的值查询出
{
"mappings" : {
"properties" : {
"province" : {
"type" : "keyword",
"copy_to": "full_address"
},
"city" : {
"type" : "text",
"copy_to": "full_address"
}
}
}
}