clickhouse聚合之内存不足怎么办?那就提升聚合性能

大家好,我是奇想派,可以叫我奇奇。
当你遇到clickhouse内存溢出,内存不足报错,如包含Exception: Memory limit (for query)、Exception: Memory limit (total) exceeded等,这样的错误时候,是不是手足无措,不知如何下手,那么你就应该认真看看这篇文章啦,本文教你如何解决clickhouse内存溢出问题。
上一篇文章《clickhouse聚合之探索聚合内部机制》里主要介绍了clickhouse聚合时的内部机制,在本篇文章中,主要是讲解如何提升聚合性能。主要步骤是:
- 1、先带大家对clickhouse实际查询进行性能测试,这样我们可以先充分理解当前性能的耗时和资源使用情况。
- 2、根据实际情况,我们再进行一系列实用技巧,给聚合性能提高一个档次。让聚合更快、更有效益。
探索聚合性能
让我们详细看一下聚合,并使用示例查询测试性能。我们将改变三个不同的方面:GROUP BY 键、聚合函数的复杂性以及扫描中使用的线程数。通过保持示例相对简单,我们可以更轻松地理解围绕聚合的权衡。
分组依据中值的影响
我们最初的示例查询有几十个 GROUP BY 值。回过头来参考用于保存扫描结果的哈希表,这意味着此类哈希表具有少量键。如果我们使用不同的 GROUP BY 运行相同的查询,从而生成更多的值,该怎么办?较大的密钥数量是否会对聚合的资源或速度产生影响?
这很容易测试。首先,让我们重新运行示例查询,然后重新运行另一个具有不同 GROUP BY 的查询。
SET max_untracked_memory = 1
-- #1
SELECT Carrier, avg(DepDelay) AS Delay
FROM ontime
GROUP BY Carrier
ORDER BY Delay DESC LIMIT 3
;
-- #2
SELECT Carrier, FlightDate, avg(DepDelay) AS Delay
FROM ontime
GROUP BY Carrier, FlightDate
ORDER BY Delay DESC LIMIT 314
如果我们现在检查system.query_log查询速度和内存,我们会看到以下内容。
┌──────────event_time─┬──secs─┬─memory────┬─threads─┬─query───────────────┐
│ 2022-03-15 11:09:34 │ 0.725 │ 33.96 MiB │ 4 │ -- #2SELECT Carrier │
│ 2022-03-15 11:09:33 │ 0.831 │ 10.46 MiB │ 4 │ -- #1SELECT Carrier │
└─────────────────────┴───────┴───────────┴─────────┴─────────────────────┘
第二个查询使用的内存量存在很大差异。拥有更多密钥会占用更多 RAM,至少在这种情况下是这样。导致这种情况的密钥数量有什么区别?我们可以使用以下查询找出答案。方便的 uniqExact() 聚合计算行中值的唯一出现次数。
SELECT
uniqExact(Carrier),
uniqExact(Carrier, FlightDate)
FROM ontime
FORMAT Vertical
Row 1:
──────
uniqExact(Carrier): 35
uniqExact(Carrier, FlightDate): 169368
我们的第一个查询有 35 个 GROUP BY 键。我们的第二个查询必须处理 169,368 个密钥。
在离开此示例之前,值得注意的是,第二个查询始终比第一个查询快约 15%。这是令人惊讶的,因为您可能会认为更多的GROUP BY键意味着更多的工作。正如我们在其他地方所解释的那样,ClickHouse根据GROUP BY键的数量和类型选择不同的聚合方法以及不同的哈希表配置。反过来,它们的效率会有所不同。
如何知道?
我们可以使用 clickhouse-client –send_logs_message=‘trace’ 选项启用跟踪日志记录,然后仔细查看消息。(有关如何执行此操作的说明,请参阅之前文章《clickhouse聚合之探索聚合内部机制》。它显示扫描线程完成的时间,还指示聚合方法。下面是第二个查询中来自其中一个线程的几个典型消息。
[chi-clickhouse101-clickhouse101-0-0-0] 2022.03.28 14:23:15.311284 [ 1887 ] {92d8506c-ae7c-4d01-84b6-3c927ed1d6a5} <Trace> Aggregator: Aggregation method: keys32
…
[chi-clickhouse101-clickhouse101-0-0-0] 2022.03.28 14:23:16.007341 [ 1887 ] {92d8506c-ae7c-4d01-84b6-3c927ed1d6a5} <Debug> AggregatingTransform: Aggregated. 48020348 to 42056 rows (from 366.37 MiB) in 0.698374248 sec. (68760192.887 rows/sec., 524.61 MiB/sec.)
在第二种情况下,扫描线程的运行速度更快,这可能意味着所选的聚合方法和/或哈希表实现更快。为了找出为什么我们需要从src/Interpreters/Aggregator.h开始深入研究代码。在那里,我们可以了解keys32和其他聚合方法。这项调查将不得不等待另一篇博客文章。
不同聚合函数的影响
avg() 函数非常简单,使用的内存相对较少 - 基本上它创建的每个部分聚合都有几个整数。如果我们使用更复杂的函数会发生什么?
uniqExact() 函数是一个很好的尝试。此聚合存储一个哈希表,其中包含它在块中看到的值,然后合并它们以获得最终答案。我们可以假设哈希表将需要更多的RAM来存储,并且速度也会更慢。让我们来看看!我们将使用少量和大量 GROUP BY 键运行以下查询。
SET max_untracked_memory = 1
SELECT Carrier, avg(DepDelay) AS Delay, uniqExact(TailNum) AS Aircraft
FROM ontime
GROUP BY Carrier ORDER BY Delay DESC
LIMIT 3
-- #2
SELECT Carrier, FlightDate, avg(DepDelay) AS Delay,
uniqExact(TailNum) AS Aircraft
FROM ontime
GROUP BY Carrier, FlightDate ORDER BY Delay DESC
LIMIT 3
当我们检查system.query_log中的查询性能时,我们会看到以下结果。
┌──────────event_time─┬──secs─┬─memory────┬─threads─┬─query────────────────┐
│ 2022-03-15 12:19:08 │ 3.324 │ 2.41 GiB │ 4 │ -- #2SELECT Carrier │
│ 2022-03-15 12:19:04 │ 2.657 │ 21.57 MiB │ 4 │ -- #1SELECT Carrier │
. . .
添加此新聚合的执行时间肯定存在差异,但这并不奇怪。更有趣的是RAM的增加。对于少量的密钥,它不是很多:21.57MiB,而我们原始示例查询中的10.46Mib。
但是,RAM 使用量会随着更多的 GROUP BY 键而爆炸式增长。如果您考虑查询,这是有道理的,该查询要求在每个组中进行航班的航空公司尾号(即飞机)的确切计数。将FlightDate添加到GROUP BY意味着同一架飞机被计数更多次,这意味着它们必须保留在哈希表中,直到ClickHouse可以合并并进行最终计数。
由于我们看到的是爆炸式增长,让我们再尝试一个查询。groupArray() 函数是 ClickHouse 独有的强大聚合,它将组中的列值收集到数组中。我们假设它将使用比uniqExact更多的内存。那是因为它将包含所有值,而不仅仅是我们计算的值。
下面是查询,后跟查询日志统计信息。
SELECT Carrier, FlightDate, avg(DepDelay) AS Delay,
length(groupArray(TailNum)) AS TailArrayLen
FROM ontime
GROUP BY Carrier, FlightDate ORDER BY Delay DESC
LIMIT 3
┌──────────event_time─┬──secs─┬─memory───┬─threads─┬─query───────────────┐
│ 2022-03-15 21:28:51 │ 2.957 │ 5.66 GiB │ 4 │ -- #3SELECT Carrier │
└─────────────────────┴───────┴──────────┴─────────┴─────────────────────┘
正如预期的那样,这比uniqExact占用更多的内存:5.66GiB。默认情况下,ClickHouse 将终止使用超过 10GiB 的查询,因此这接近一个有问题的级别。但是,请注意,鉴于我们正在扫描近200M行,所有这些仍然非常快。与以前一样,由于 ClickHouse 在每种情况下选择不同的聚合方法和哈希表实现,因此性能也存在差异。
执行线程数的影响
对于我们的最后一项调查,我们将研究线程的影响。我们可以使用max_threads来控制扫描阶段的线程数。我们将运行相同的查询三次,如下所示:
SET max_untracked_memory = 1
SET max_threads = 1
SELECT Origin, FlightDate, avg(DepDelay) AS Delay,
uniqExact(TailNum) AS Aircraft
FROM ontime
WHERE Carrier='WN'
GROUP BY Origin, FlightDate ORDER BY Delay DESC
LIMIT 3
SET max_threads = 2
(same query)
SET max_threads = 4
(same query)
好吧,让我们看一下生成的内存使用情况。我添加了注释,以便更容易分辨哪个查询是哪个查询。
┌──────────event_time─┬──secs─┬─memory───┬─threads─┬─query───────────────┐
│ 2022-03-15 22:12:02 │ 0.86 │ 1.71 GiB │ 8 │ -- #8SELECT Origin, │
│ 2022-03-15 22:12:01 │ 1.285 │ 1.72 GiB │ 4 │ -- #4SELECT Origin, │
│ 2022-03-15 22:11:59 │ 2.325 │ 1.75 GiB │ 2 │ -- #2SELECT Origin, │
│ 2022-03-15 22:11:56 │ 4.408 │ 1.91 GiB │ 1 │ -- #1SELECT Origin, │
. . .
如果我们把它们放在一个图表中,就更容易理解结果。
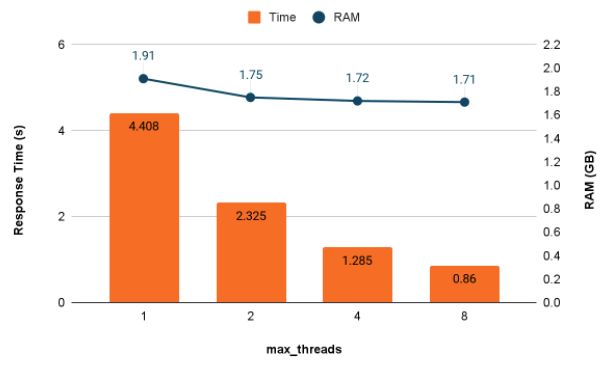
添加线程可显著提高聚合查询速度,最高可达一个点,在本例中为 4 个线程。在某些时候,扫描会随着线程的增加而停止加速 - 这里的情况是4到8个线程之间。有趣的是,ClickHouse在扫描运行后并行化合并操作。如果仔细检查调试级别的消息,则会看到这部分查询执行速度也会加快。
添加更多线程会影响内存使用量,但可能不会像您想象的那样。在这种情况下,当线程较多时,我们使用较少的 RAM 来处理查询。
提高聚合性能的实用技巧
我们已经详细研究了聚合响应时间和内存使用情况,这是生产 ClickHous 实现中的两大考虑因素。在最后一节中,我们将总结改进两者的实用方法。
加快聚合速度
有多种方法可以使具有聚合的查询速度更快。以下是主要建议。
删除或交换复杂的聚合函数
使用 uniqExact 来计算发生次数?请尝试uniq。它的速度更快,但代价是答案的精度较低。ClickHouse还具有特定的功能,可以用更具体的实现来取代昂贵的聚合。如果您正在处理网站访问者的数据以计算转化率,请尝试使用windowFunnel。
减少“分组依据”中的值
处理大量 GROUP BY 键可能会增加聚合时间。如果可能,按较少的项目分组。
使用max_threads提高并行度
增加max_threads可以导致接近线性响应时间的改进,尽管最终添加新线程不再增加吞吐量。此时,您正在添加的内核将被浪费。
推迟连接
如果要针对数据进行连接,则最好将关联查询推迟到聚合完成后,这样能减少初始扫描中的处理。下面是一个示例。ClickHouse 将首先运行子查询,然后将结果与表左连接。
SELECT Dest, airports.Name Name, c Flights, ad Delay
FROM
(
SELECT Dest, count(*) c, avg(ArrDelayMinutes) ad
FROM ontime
GROUP BY Dest HAVING c > 100000
ORDER BY ad DESC LIMIT 10
) a
LEFT JOIN airports ON IATA = Dest
如果我们直接连接表,ClickHouse将在主扫描期间连接行,这需要额外的CPU。相反,我们只是在子查询完成后的末尾加入 10 行。它大大减少了所需的处理时间。
这种方法还可以节省内存,但除非您向结果中添加大量列,否则效果可能不明显。该示例为每个 GROUP BY 键添加一个值,这在事物的宏伟方案中根本不是很大。
过滤不必要的数据
继上一点之后,如果处理的数据较少,则任何查询的运行速度都会更快。过滤掉不需要的行,完全删除不需要的列,以及所有这些好东西。
使用实例化视图
具体化视图预先聚合数据以服务于常见用例。在最好的情况下,他们只需减少需要扫描的数据量,就可以将查询响应时间缩短 1000 倍或更多。
更高效地使用内存
使用实例化视图(再次)
我们提到过它们是否节省了内存?例如,将基于秒的测量值预先聚合为小时的具体化视图可以大大减少 ClickHouse 在初始扫描期间拖动的部分聚合的大小和数量。实例化视图通常也会在外部存储中使用更少的空间。
删除或交换占用大量内存的聚合函数
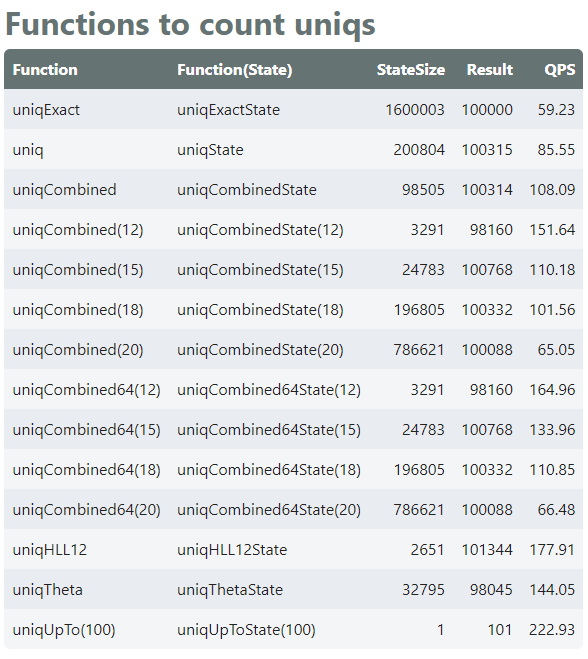
像 max、min 和 avg 这样的函数对内存非常简洁。相比之下,像uniqExact这样的函数是记忆猪。要了解跨函数的内存使用情况以计算唯一发生次数,请查看此计数唯一发生次数的函数的表,如下表。
减少“分组”里的字段数
GROUP BY 的聚合可能会出现一个情况,那就是随着字段数的增加,内存会爆炸式增长。如果无法减少 GROUP BY 中的字段数,则另一个方式是使用实例化视图对特定的 GROUP BY 组合进行预聚合。
调整内存参数
如果查询内存占用必不可免,那就修改参数,提高限制,让查询可以正常运行。ClickHouse 内存限制由以下参数控制,您可以在系统级别或在用户配置文件中更改这些参数(具体取决于设置)。
常见错误
User class threw exception: ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 241, host: 10.121.8.8, port: 8123; Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded: would use 9.31 GiB (attempt to allocate chunk of 1048591 bytes), maximum: 9.31 GiB (version 19.9.5.36)
解决涉及的参数
-
max_memory_usage – 单个查询的最大内存字节数。默认值为10GiB,这对于大多数目的来说已经足够了,但可能不是你的。
-
max_memory_usage_for_user – 单个用户在单个时间点的所有查询的最大字节数。默认值为无限制。
-
max_server_memory_usage – 整个 ClickHouse 服务器的最大内存。默认值为可用 RAM 的 90%。
解决方案
配置文件一般修改用户列表文件/etc/clickhouse-server/users.xml (默认路径,具体根据自己文件目录来定)
#这里假设clickhouse所在服务器最大RAM内存:128G
<yandex>
<profiles>
<default>
<max_memory_usage>123000000000max_memory_usage>
<max_server_memory_usage>123000000000max_server_memory_usage>
...
default>
profiles>
<users>
...
users>
yandex>
调整聚合参数
如果所有其他方法都失败,则可以将部分聚合转储到外部存储。使用max_bytes_before_external_group_by设置。标准建议将其设置为max_memory_usage的50%。这可以确保您不会在合并阶段用完。
配置文件一般修改用户列表文件/etc/clickhouse-server/users.xml (默认路径,具体根据自己文件目录来定)
#这里假设clickhouse所在服务器最大RAM内存:128G
<yandex>
<profiles>
<default>
<max_memory_usage>123000000000max_memory_usage>
<max_server_memory_usage>123000000000max_server_memory_usage>
<max_bytes_before_external_group_by>61500000000max_bytes_before_external_group_by>
...
default>
profiles>
<users>
...
users>
yandex>
结论
聚合是数据仓库中从大数据中提取意义的基本操作。ClickHouse聚合就像一辆高性能的赛车。它非常快,但你需要训练才能赢得比赛。做对了,你会在几分之一秒内得到结果;但做错了,你的查询会很慢或内存不足。
在这个由两部分组成的系列文章中,我们介绍了聚合的工作原理,展示了用于检查性能的简单工具,并探讨了聚合性能。
更多内容请关注微信公众号【编程达人】,分享优质好文章,编程黑科技,助你成为编程达人!