Spacy的依存分析

# Spacy 架构


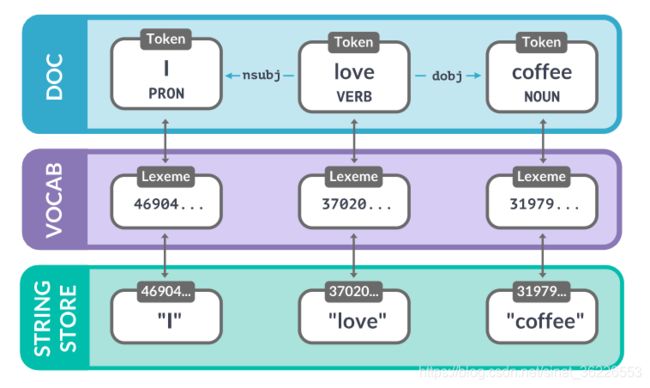
spaCy模块有4个非常重要的类:
- Doc:Doc对象由Tokenizer构造,然后由管道的组件进行适当的修改。doc对象是token的序列
- Span:Span对象是Doc对象的一个切片。
- Token:在自然语言处理中,把一个单词,一个标点符号,一个空格等叫做一个token。
- Vocab:存储词汇表和语言共享的数据。词汇表使用Lexeme对象和StringStore对象来表示。
Lexeme对象是词汇表Vocab中的一个词条(entry),可以通过similarity()函数计算两个词条的相似性;
StringStore类是一个string-to-int的对象,通过64位的哈希值来查找词汇,或者把词汇映射到64位的哈希值
 spaCy 101: Everything you need to know · spaCy Usage Documentation
spaCy 101: Everything you need to know · spaCy Usage Documentation
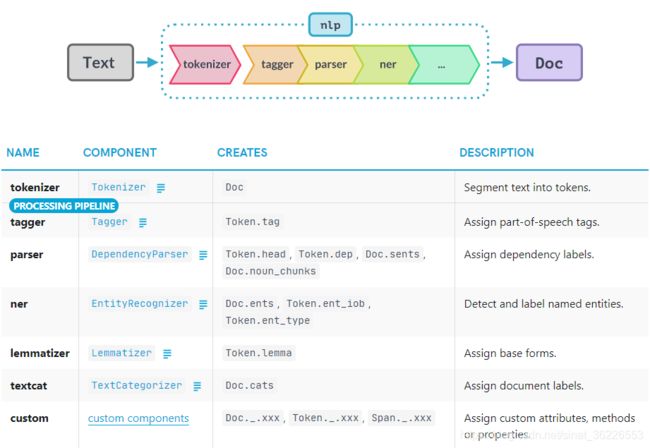
# Pipeline
当你在一个文本上调用nlp时,spaCy首先将文本分词,生成一个Doc对象。然后,Doc会经过几个不同的步骤进行处理。Pipeline通常包括一个标记器(tagger)、一个词法器(lemmatizer)、一个解析器(parser)和一个实体识别器(entity recognizer)。每个流水线组件都会返回经过处理的Doc,然后将其传递给下一个组件。
 spaCy 101: Everything you need to know · spaCy Usage Documentation
spaCy 101: Everything you need to know · spaCy Usage Documentation
找出活动的管道组件:
nlp.pipe_names禁用/添加管道组件:
nlp.disable_pipes('tagger', 'parser') # 禁用
nlp.add_pipe("parser") # 添加
- Pipeline组件列表 [链接]
- Pipeline组件的顺序重要吗?[链接]
- 分词器(tokenizer)为什么特殊?[链接]
tokenizer 是一个 "特殊 "组件,并不是常规管道的一部分。它也不会出现在 nlp.pipe_names 中。原因是实际上只能有一个 tokenizer,而且其他管道组件都会接收一个 Doc 并返回它,而 tokenizer 会接收一串文本并将其变成一个 Doc。nlp.tokenizer 是可写的,所以你可以从头开始创建自己的 Tokenizer 类,甚至可以用一个完全自定义的函数来替换它。
# 模型
上次使用spacy时,官网提供的中文模型有zh_core_web_sm、zh_core_web_md 和 zh_core_web_lg,现在发现又提供了一种 zh_core_web_trf [下载链接]
根据说明解释 trf 是larger and slower pipeline, but more accurate,而其余的是faster and smaller pipeline, but less accurate [来源]
注:模型和Spacy有版本对应要求,详情可以看Github下载链接里的说明
中文模型中,sm、md 和 lg 有2.3.0、2.3.1(要求spaCy >=2.3.0,<2.4.0)和 3.0.0版本(要求spaCy >=3.0.0,<3.1.0);trf 目前仅有3.0.0版本(要求spaCy >=3.0.0,<3.1.0)
- 导入方式
# 方式一
import spacy
nlp = spacy.load("zh_core_web_sm")
# 方式二
import zh_core_web_sm
nlp = zh_core_web_sm.load()- 模型的选用
根据自己的需求进行分析、比较,比如我发现使用zh_core_web_sm有时候会出现同一句式分析出的结果不一致,而zh_core_web_md、zh_core_web_trf出来的结果一致:


- 模型安装问题
zh_core_web_trf 导入时报错:
Config validation error: batch_size field required找到C:\Anaconda3\Lib\site-packages\zh_core_web_trf\zh_core_web_trf-3.0.0a0下的config.cfg 添加
[nlp]
lang = "zh"
pipeline = ["transformer","tagger","parser","ner","attribute_ruler"]
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
batch_size = 64导入时又报错(这个问题后来卸载重新安装zh_core_web_trf 就解决了
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Anaconda3\\lib\\site-packages\\zh_core_web_trf-3.0.0a0-py3.7.egg\\zh_core_web_trf\\zh_core_web_trf-3.0.0a0\\tokenizer\\pkuseg_model\\unigram_word.txt'pip install zh_core_web_trf-3.0.0a0.tar.gz# 分词器
In v3.0, the default word segmenter has switched from Jieba to character segmentation
在v3.0中,默认的分词器已从Jieba切换到char。[来源]
打开python虚拟环境下的模型包 spacy\data\zh_core_web_sm\zh_core_web_sm-2.3.0\tokenizer 下的 cfg,里面的配置如下:
{
"use_jieba":false,
"use_pkuseg":true,
"require_pkuseg":true
}当我修改成使用jieba后,发现确实分词不同了。奇怪的是,之前默认使用的pkuseg为什么会在控制台显示加载jieba词表
# 标注附录
- ① POS 附录、POS扩展附录 [翻译](pos_属性公开基于Google Universal POS Tag set,spaCy扩展了列表
从spaCy的parts of speech模块中看到,它扩展了这个模式,增加了三个额外的POS常量,EOL、NO_TAG(错误代码,如:未安装该语言模型)和SPACE,它们不是Universal POS Tag集的一部分 [来源]
DET(冠词)、ADJ(形容词)、NOUN(名词)、VERB(动词)、PUNCT(标点)...
- ② TAG 附录
- ③ DEP 附录 [翻译] [Universal Dependency Relations]
det (限定词) 、amod (形容词修饰) 、nsubj(名词主语)、ROOT(根节点)、attr(属性) 、punct(标点) ...
依存标记ROOT表示句子中的主要动词或动作。其他词与句子的词根有直接或间接的联系
- pos和tag有什么区别?
.pos_和.tag_方法访问粗粒度和细粒度POS标签,tag是更细分的pos [来源]。在官网上只找到说pos属性基于Google Universal POS Tag set,但没有给出tag的标注介绍,从网上找到的是这个spacy TAG 附录
 Data formats · spaCy API Documentation
Data formats · spaCy API Documentation
在模型的说明中,介绍了该模型含哪些词性、依存标注
 Chinese · spaCy Models Documentation
Chinese · spaCy Models Documentation
标注的解释可以使用 spacy.explain() ,但我发现很多都返回None
doc = nlp('猴子喜欢香蕉')
for token in doc:
print(token.dep_, spacy.explain(token.dep_)) # 解释标注# 操作
相比之前学习的其他依存分析工具,Spacy接口调用的API更为丰富、方便
# -*- coding:utf8 -*-
import spacy
nlp = spacy.load('zh_core_web_sm')
doc = nlp('猴子喜欢香蕉')
for token in doc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
>>> 猴子/NN <--nsubj-- 喜欢/VV
>>> 喜欢/VV <--ROOT-- 喜欢/VV
>>> 香蕉/NN <--dobj-- 喜欢/VV
token 的 属性查询:Token · spaCy API Documentation
可以获取token相邻的词:Token · spaCy API Documentation
token的children节点:Token · spaCy API Documentation (可以找到以该token为head的dependent词
# 可视化
1)依存树
- 网址
displaCy Dependency Visualizer · Explosion
- 代码
from spacy import displacy
txt = '''In particle physics, a magnetic monopole is a hypothetical elementary particle.'''
displacy.render(nlp(txt), style='dep', jupyter=True, options = {'distance': 90})2)命名实体识别
- 网址
displaCy Named Entity Visualizer · Explosion
- 代码
from spacy import displacy
displacy.render(doc, style='ent', jupyter=True)# 工具学习系列
- 哈工大LTP的依存分析
- 百度DDParser的依存分析
- HanLP的依存分析
-
Spacy的依存分析
| 词性标注集pos/tag | 依存句法分析标注集dep | 语义依存分析标注集sdp | |
| LTP | 863词性标注集 | BH-DEP | BH-SDP |
| SpaCy | 基于Google Universal POS Tag set扩展 | 采用了 ClearNLP 的依存分析标签 | - |
| DDParser | 百度构建的标注集 | DuCTB | - |
| HanLP | CTB、PKU、863、UD | SD、UD | SemEval16、DM、PAS、PSD |
| stanford corenlp | Penn Chinese Treebank Tag Set(CTB) | 没找到说明采用的标注集 [链接] | - |
| jieba | 和 ictclas 兼容的标记法 | 不支持 | 不支持 |
# 案例
⭐基于 SpaCy 和 Networkx 的依存树和最短依存路径分析
Python NLP教程:使用Python和SpaCy构建知识图
python从零开始构建知识图谱
python从零开始构建知识图谱笔记
从头搭建问答(QA)系统
# 参考
spaCy教程学习(① spaCy的统计模型和处理管道 ② 基于规则的spaCy匹配
NLP:spaCy笔记 (① spacy原理 ② WordNet
python spacy(①$. 和 }.中的句点不能被正确识别为句子的结尾 ② 知识提取(有点像阅读理解) ③ 提取名词短语(中文不行?)
英文文本处理与spaCy (① 断句 ② POS词性标注编码和含义 ③ 词向量使用和文本相似度
自然语言处理的基本概念--结合spacy软件的学习(① spacy.explain("对应属性名称")来查找对应的属性含义 ② 模板匹配(例子比较多)
自然语言处理就这么简单有趣(spacy功能
