技术贴 | 一文带你走进统计信息模型

一、简介
数据库中的“统计信息”是一个描述数据库中表和列信息的数据集合。优化器代价模型 (OptimizerCost Model) 依赖于查询中涉及到的表、列、谓词等对象的统计信息来选取计划,优化器可以利用统计信息来优化计划的选择,所以统计信息是代价模型中选取最优执行计划的关键。
统计信息包含表统计信息(Table Level Statistics)和列统计信息(Column Level Statistics)两种类型。各家数据库不一定会收集全部下列所列的统计信息,但会根据各家的实际情况收集进行收集。
1. 表级统计信息
- 表的基本信息
- 表的统计信息类型(信息级别分为 GLOBAL、PARTITION 和 SUBPARTITION)
- 表的行数
- 表所占用的宏块数
- 表所占用的微块数
- 表的平均行长
- 表的收集统计信息时间
- 表的统计信息是否锁定
2. 列级统计信息
- 列的基本信息(包括 tenant_id、table_id、partition_id、column_id)
- 列的统计信息类型(信息级别分为 GLOBAL、PARTITION 和 SUBPARTITION)
- 列中不同的值的数量 NDV(Number of Distinct Values)
- 列中 NULL 值的数量
- 列的最大值和最小值
- 列的采样数据量大小
- 列的直方图的稠密度
- 列的直方图桶个数
- 直方图类型(频率直方图/等高直方图/TopK 直方图/混合直方图)
在普通的统计信息中,CBO 会默认目标列数据在其最小与最大值间是均匀分布的,并以此为依据预估条件选择率及结果集 cardinality,进而选择执行计划。但在实际中,显然有些数据不是平均分布的,会出现所谓的“数据倾斜”,此时产生的执行计划很可能就不是最佳的,甚至会产生较差的执行计划。
直方图的引入就是用来解决数据倾斜的问题。直方图是一种特殊的列统计信息,它详细描述了列的数据分布情况。直方图收集信息后,CBO 不会再认为列上是均匀分布的,可以根据实际情况预估条件选择率及结果集 cardinality,选择正确的执行计划。
二、常见的统计信息直方图模型
1. 频率直方图
列中有多少 distinct 值,数据字典中就会存储多少条记录。endpoint value 记录这些 distinct 值,endpoint number 则记录到此 distinct 值为止共有多少条记录。此时 endpoint number 是一个累加值,可以用一条记录的 endpoint number 减去前一条记录的 endpoint number 得到这条记录对应的 endpoint value 值的记录数。频率直方图一般适用于 distinct 值比较少的表,直方图桶的个数 >= NDV (Number of Distinct Value),即直方图的桶数大于等于列上的不同值的数量的场景。
2. 等高直方图
对于这类直方图,Oracle 首先根据目标列对目标表的所有记录从小到大排序,然后用总记录数除以需要使用的 Bucket 数,来决定每个 Bucket 中需要描述的已排好序的记录数。此时 endpoint number 记录的是 Bucket 号,Bucket 号从 0 开始一直到 N。0 号 Bucket 对应的 endpoint value 记录目标列最小值,其他 Bucket 对应的 endpoint value 则记录到此 Bucket 为止目标列的最大值。
为节省空间,对于相邻的仅 endpoint number 不同,而 endpoint value 相同的记录,Oracle 会在数据字典中合并存储。假如 endpoint number=2 和 3 的 Bucket 对应 endpoint value 都为 P,数据字典中只会记录 endpoint number=3,endpoint value=P。因此,Height Balanced 类型直方图数据字典中的 endpoint number 可能是不连续的。
这种合并后记录在数据字典的 endpoint value,Oracle 称为 popular value。显然 popular value 记录的 endpoint number 值与上一条记录的 endpoint number 值相差越大,popular value 在目标列中所占比例越大,对应的 cardinality 也就越大,这应该也是将其称为 popular value 的原因。
3. Top-k 直方图
频率直方图的一个变种,针对 k 个直方图覆盖数据占比超过一定阈值的情况。很少出现的 distinct 值在直方图里会被忽略掉。
4. 混合直方图
混合直方图结合了基于高度的直方图和频率直方图的特征,但与频率直方图和 Top-k 直方图的不同的是,一个桶里面可能装多个不同的 value 值,将采集到的数据量按照桶个数分段,将每一分段内的所有数据都放到对应的一个桶中,达到用更少的桶来描述更大数据量的数据分布,其中桶内的最大的 value 值将作为 endpoint_value,同时会多一个 endpoint_repeat_cnt 来记录 endpoint_value 的频次。该方法使优化器能够在某些情况下获得更好的选择性估计。
单纯的等高直方图目前在数据库内使用的很少,很多优化方案都是在等高直方图的基础上加入了对空洞(非连续值超过一定阈值的区间视为空洞),高频值以及第二高频值表示,并确保每一个值只出现在一个区间内的近似等高直方图。
对于频率直方图、Top-k 直方图和混合直方图在不同场景下的使用逻辑如下:

直方图信息列上数据分布出现倾斜的情况下,对单表的结果集大小预测提供了相对准确的结果,但是在做关联查询时却不能提供关联结果集大小的准确性判断。
在关联查询的情况下又出现了另外一种判断结果集大小的方法 Count-Min Sketch。它是一种可以处理等值查询,Join 大小估计等的数据结构,并且可以提供很强的准确性保证。自 2003 年文献 An improved data stream summar: The count-min sketch and its applications 中提出以来,由于其创建和使用的简单性获得了广泛的使用。
Count-Min Sketch 维护了一个 d*w 的计数数组,对于每一个值,用 d 个独立的 hash 函数映射到每一行的一列中,并对应修改这 d 个位置的计数值。
这样在查询一个值出现了多少次的时候,依旧用 d 个 hash 函数找到每一行中被映射到的位置,取这 d 个值的最小值作为估计值。
KaiwuDB 提供的列级统计信息包含行数、不同值的数量、NULL 值的数量等。对于列上数据分布不均匀的情况也可以提供直方图统计信息。KaiwuDB 的直方图也是一个近似等高直方图,对于列的不同值小于等于 200 的场景,可以提供类似频率直方图的效果,对于高频值也能表示,但是在处理区间上的不同值的数量上,目前基于 HyperLoglog 的算法不太准确。
![]()
小于等于 200 个 bucket:
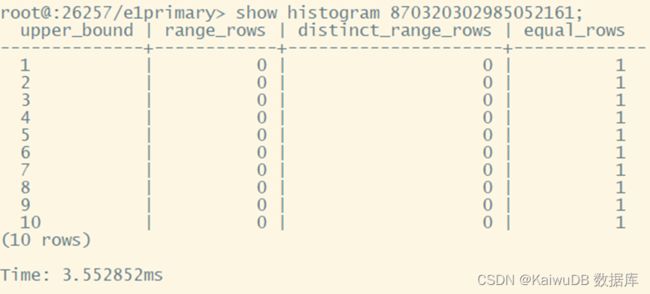
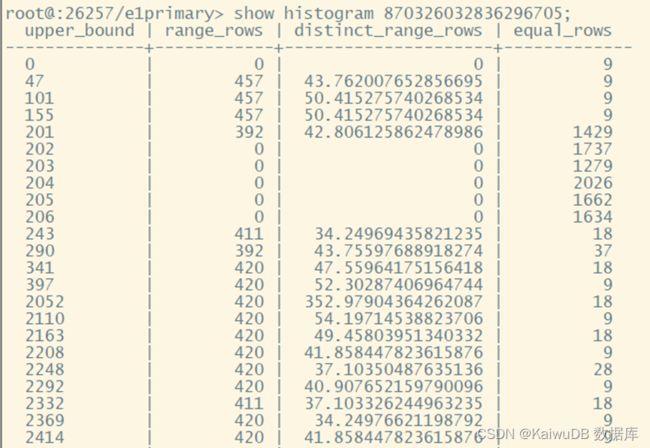
大于 200 个 bucket:
插入 10 万个 1 到 10000 的随机值,201, 202, 203, 204, 205, 206 的重复值都增加到 1000 以上,删除 400 到 2000 之间的值,然后创建统计信息和直方图。


三、总结
基于成本的优化模型(CBO)是目前关系型数据库最主流的优化模型,而统计信息则是 CBO 的基础,一定程度上统计信息的准确性是 CBO 能否产生最优执行计划的关键。统计信息的收集主要以表级统计信息和列级统计信息为主,在列上数据分布不均匀的情况下,直方图信息的准确性就尤为重要,目前主要以等高直方图、频率直方图和相应的变形直方图为主。
另外,统计信息的准确性虽然是影响产生最优执行计划的关键,但是统计信息的计算也会耗费系统资源。一般情况下相同策略下参与计算的数据越多统计信息越能准表描述表上数据的真实分布情况,但代价是耗费的资源越多,计算的时间越长。
通常情况下,会对表上的数据进行采样来收集统计信息,或者通过增量收集统计信息的方式来提高收集统计信息的效率。在参与计算的数据确定的情况下,会通过粗略的估计来决定使用哪种策略来收集统计信息,从而能够更有效的描述数据分布情况。
对于数据频繁变动的表,统计信息的有效性是重点。如何有效判定统计信息的有效性,以及如何通过变动的数据修正统计信息是统计信息研究的难点。另外,对于某些融合型的多模数据库里的某些特殊的表,可以根据表本身的特性,尝试新的统计信息策略。如时序数据表,表上的数据有一定的规律性,有些表甚至是增加了降采样规则的,新的策略可以依据降采样的规则来生成或者替代统计信息。
总之,对于传统的关系型数据库,统计信息的收集是必不可少的部分,统计信息的好坏直接影响执行计划的质量。对于融合型的数据库里的新型的表,可以基于新的策略来统计估算表的数据分布,从而达到统计信息的效果。