技术解析|Doris Connector 结合 Flink CDC 实现 MySQL 分库分表 Exactly Once精准接入
本篇文档将演示如何使用 Apache Doris Flink Connector 结合 Flink CDC 以及 Doris Stream Load 的两阶段提交,实现 MySQL 数据库分库分表实时高效接入,并实现 Exactly Once。
一、概述
在实际业务系统中为了解决单表数据量大带来的各种问题,我们通常采用分库分表的方式对库表进行拆分,以达到提高系统的吞吐量。
但是这样给后面数据分析带来了麻烦,这个时候我们通常试将业务数据库的分库分表同步到数据仓库时,将这些分库分表的数据合并成一个库、一个表,便于我们后面的数据分析。
本篇文档我们将演示如何基于 Flink CDC 结合 Apache Doris Flink Connector 及 Doris Stream Load 的两阶段提交,实现 MySQL 数据库分库分表实时高效的接入到 Doris 数据仓库中进行分析。
1.1 什么是 CDC
CDC 是 Change Data Capture 变更数据获取的简称。
核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入 INSERT、更新 UPDATE、删除 DELETE 等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC 技术应用场景也非常广泛,包括:
- 数据分发:将一个数据源分发给多个下游,常用于业务解耦、微服务。
- 数据集成:将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析。
- 数据迁移:常用于数据库备份、容灾等。
1.2 为什么选择 Flink CDC
Flink CDC 基于数据库日志的 Change Data Capture 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
目前,Flink CDC 的上游已经支持了 MySQL、MariaDB、PG、Oracle、MongoDB 、Oceanbase、TiDB、SQLServer 等数据库。
Flink CDC 的下游则更加丰富,支持写入 Kafka、Pulsar 消息队列,也支持写入 Hudi、Iceberg 、Doris 等,支持写入各种数据仓库及数据湖中。
同时,通过 Flink SQL 原生支持的 Changelog 机制,可以让 CDC 数据的加工变得非常简单。用户通过 SQL 便能实现数据库全量和增量数据的清洗、打宽、聚合等操作,极大地降低了用户门槛。此外, Flink DataStream API 支持用户编写代码实现自定义逻辑,给用户提供了深度定制业务的自由度。
Flink CDC 技术的核心是支持将表中的全量数据和增量数据做实时一致性的同步与加工,让用户可以方便地获每张表的实时一致性快照。比如一张表中有历史的全量业务数据,也有增量的业务数据在源源不断写入、更新。Flink CDC 会实时抓取增量的更新记录,实时提供与数据库中一致性的快照,如果是更新记录,会更新已有数据;如果是插入记录,则会追加到已有数据,整个过程中,Flink CDC 提供了一致性保障,即不重不丢。
Flink CDC 具有如下优势:
- Flink 的算子和 SQL 模块更为成熟和易用;
- Flink 作业可以通过调整算子并行度的方式轻松扩展处理能力;
- Flink 支持高级的状态后端(State Backends),允许存取海量的状态数据;
- Flink 提供更多的 Source 和 Sink 等生态支持;
- Flink 有更大的用户基数和活跃的支持社群,问题更容易解决。
而且 Flink Table / SQL 模块将数据库表和变动记录流(例如 CDC 的数据流)看做是同一事物的两面,因此内部提供的 Upsert 消息结构(+I表示新增、-U表示记录更新前的值、+U表示记录更新后的值,-D表示删除)可以与 Debezium 等生成的变动记录一一对应。
1.3 什么是 Apache Doris
Apache Doris 是一个现代化的 MPP 分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。可以使数据分析工作更加简单高效!
1.4 Two-phase commit
什么是 Two-phase commit(2PC)
在分布式系统中,为了让每个节点都能够感知到其他节点的事务执行状况,需要引入一个中心节点来统一处理所有节点的执行逻辑,这个中心节点叫做协调者(Coordinator),被中心节点调度的其他业务节点叫做参与者(Participant)。
2PC 将分布式事务分成了两个阶段,两个阶段分别为提交请求(投票)和提交(执行)。协调者根据参与者的响应来决定是否需要真正地执行事务,具体流程如下:
提交请求(投票)阶段
- 协调者向所有参与者发送 prepare 请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
- 参与者执行事务中包含的操作,并记录 undo 日志(用于回滚)和 redo 日志(用于重放),但不真正提交。
- 参与者向协调者返回事务操作的执行结果,执行成功返回 yes,否则返回 no。
提交(执行)阶段
分为成功与失败两种情况。
-
若所有参与者都返回 yes,说明事务可以提交:
- 协调者向所有参与者发送 Commit 请求。
- 参与者收到 Commit 请求后,将事务真正地提交上去,并释放占用的事务资源,并向协调者返回 Ack。
- 协调者收到所有参与者的 Ack 消息,事务成功完成。
-
若有参与者返回 no 或者超时未返回,说明事务中断,需要回滚:
- 协调者向所有参与者发送 Rollback 请求。
- 参与者收到 Rollback 请求后,根据 undo 日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回 Ack。
- 协调者收到所有参与者的 Ack 消息,事务回滚完成。
1.5 Flink 2PC
Flink 作为流式处理引擎,自然也提供了对 Exactly Once 语义的保证。端到端的 Exactly Once 语义,是输入、处理逻辑、输出三部分协同作用的结果。Flink 内部依托检查点机制和轻量级分布式快照算法 ABS 保证 Exactly Once。而要实现精确一次的输出逻辑,则需要施加以下两种限制之一:幂等性写入(idempotent write)、事务性写入(transactional write)。
预提交阶段的流程
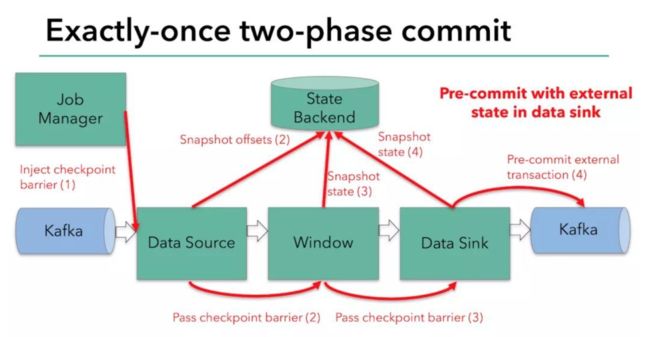
每当需要做 Checkpoint 时,JobManager 就在数据流中打入一个屏障(barrier),作为检查点的界限。屏障随着算子链向下游传递,每到达一个算子都会触发将状态快照写入状态后端的动作。当屏障到达 Kafka sink 后,通过 KafkaProducer.flush() 方法刷写消息数据,但还未真正提交。接下来还是需要通过检查点来触发提交阶段:
提交阶段流程
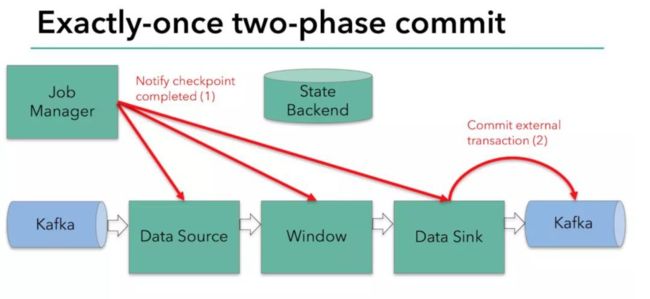
只有在所有检查点都成功完成这个前提下,写入才会成功。这符合前文所述 2PC 的流程,其中 JobManager 为协调者,各个算子为参与者(不过只有 Sink 一个参与者会执行提交)。一旦有检查点失败,notifyCheckpointComplete() 方法就不会执行。如果重试也不成功的话,最终会调用 abort() 方法回滚事务。
1.6 Doris Stream Load 2PC
1.6.1 Stream Load
Stream Load 是 Apache Doris 提供的一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream Load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。
Stream Load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
使用方法:
用户通过Http Client 进行操作,也可以使用 Curl 命令进行
curl --location-trusted -u user:passwd [-H ""...] -T data.file -H "label:label" -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load这里为了是防止用户重复导入相同的数据,使用了导入任务标识 Label。强烈推荐用户同一批次数据使用相同的 Label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once。
1.6.2 Stream Load 2PC
Aapche Doris 最早的 Stream Load 是没有两阶段提交的,导入数据的时候直接通过 Stream Load 的 HTTP 接口完成数据导入,只有成功和失败。
- 这种在正常情况下是没有问题的,在分布式环境下可能为因为某一个导入任务是失败导致两端数据不一致的情况,特别是在 Doris Flink Connector 里,之前的 Doris Flink Connector 数据导入失败需要用户自己控制,做异常处理,如果导入失败之后,将数据保存到指定的地方(例如 Kafka),然后手动处理。
- 如果 Flink Job 因为其他问题突然挂掉,这样会造成部分数据成功、部分数据失败,而且失败的数据因为没有 Checkpoint,重新启动 Job 也没办法重新消费失败的数据,造成两端数据不一致。
为了解决上面的这些问题,保证两端数据一致性,我们实现了 Doris Stream Load 2PC,原理如下:
- 提交分成两个阶段
- 第一阶段,提交数据写入任务,这个时候数据写入成功后,数据状态是不可见的,事务状态是 PRECOMMITTED
- 数据写入成功之后,用户触发 Commit 操作,将事务状态变成 VISIBLE,这个时候数据可以查询到
- 如果用户要方式这一批数据只需要通过事务 ID,对事务触发 Abort 操作,这批数据将会被自动删除掉
1.6.3 Stream Load 2PC 使用方式
- 在 be.conf 中配置
disable_stream_load_2pc=false(重启生效) - 并且 在 HEADER 中声明 two_phase_commit=true
发起预提交:
curl --location-trusted -u user:passwd -H "two_phase_commit:true" -T test.txt http://fe_host:http_port/api/{db}/{table}/_stream_load触发事务 Commit 操作:
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18036" -H "txn_operation:commit" http://fe_host:http_port/api/{db}/_stream_load_2pc对事物触发 abort 操作:
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18037" -H "txn_operation:abort" http://fe_host:http_port/api/{db}/_stream_load_2pc1.7 Doris Flink Connector 2PC
我们之前提供了 Doris Flink Connector ,支持对 Doris 表数据的读,Upsert、Delete(Unique key 模型),但是存在可能因为 Job 失败或者其他异常情况导致两端数据不一致的问题。
为了解决这些问题,我们基于 FLink 2PC 和 Doris Stream Load 2PC 对 Doris Connector 进行了改造升级,保证两端 Exactly Once。
- 我们会在内存中维护读写的 Buffer,在启动的时候,开启写入,并异步的提交,期间通过 HTTP Chunked 的方式持续的将数据写入到 BE,直到 Checkpoint 的时候,停止写入,这样做的好处是避免用户频繁提交 HTTP 带来的开销,Checkpoint 完成后会开启下一阶段的写入。
- 在这个 Checkpoint 期间,可能是多个 Task 任务同时在写一张表的数据,这些我们都会在这个 Checkpoint 期间对应一个全局的 Label,在 Checkpoint 的时候将这个 Label 对应的写入数据的事务进行统一的一次提交,将数据状态变成可见。
- 如果失败 Flink 在重启的时候会对这些数据通过 Checkpoint 进行回放。
- 这样就可以保证 Doris 两端数据的一致。
二、系统架构
下面我们通过一个完整示例来看怎么去通过 Doris Flink Connector 最新版本(支持两阶段提交),来完成整合 Flink CDC 实现 MySQL 分库分表实时采集入库。

- 这里通过 Flink CDC 完成 MySQL 分库分表数据采集。
- 然后通过 Doris Flink Connector 来完成数据的入库。
- 最后利用 Doris 的高并发、高性能的OLAP分析计算能力对外提供数据服务。
三、MySQL 安装配置
3.1 安装 MySQL
快速使用 Docker 安装配置 MySQL,具体参照下面的连接:
Docker 安装 MySQL8.0 - SegmentFault 思否
3.2 开启 MySQL Binlog
进入 Docker 容器修改 /etc/my.cnf 文件,在 [mysqld] 下面添加以下内容:
log_bin=mysql_bin
binlog-format=Row
server-id=1然后重启 MySQL
systemctl restart mysqld3.3 准备数据
这里演示我们准备了两个库 emp_1和emp_2, 每个库下面主备了两张表 employees_1,employees_2。并给出了一下初始化数据:
CREATE DATABASE emp_1;
USE emp_1;
CREATE TABLE employees_1 (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
INSERT INTO `employees_1` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26'),
(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21'),
(10003,'1959-12-03','Parto','Bamford','M','1986-08-28'),
(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01'),
(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12'),
(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02'),
(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10'),
(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15'),
(10009,'1952-04-19','Sumant','Peac','F','1985-02-18'),
(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
CREATE TABLE employees_2 (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
INSERT INTO `employees_2` VALUES (10037,'1963-07-22','Pradeep','Makrucki','M','1990-12-05'),
(10038,'1960-07-20','Huan','Lortz','M','1989-09-20'),
(10039,'1959-10-01','Alejandro','Brender','M','1988-01-19'),
(10040,'1959-09-13','Weiyi','Meriste','F','1993-02-14'),
(10041,'1959-08-27','Uri','Lenart','F','1989-11-12'),
(10042,'1956-02-26','Magy','Stamatiou','F','1993-03-21'),
(10043,'1960-09-19','Yishay','Tzvieli','M','1990-10-20'),
(10044,'1961-09-21','Mingsen','Casley','F','1994-05-21'),
(10045,'1957-08-14','Moss','Shanbhogue','M','1989-09-02'),
(10046,'1960-07-23','Lucien','Rosenbaum','M','1992-06-20');
CREATE DATABASE emp_2;
USE emp_2;
CREATE TABLE employees_1 (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
INSERT INTO `employees_1` VALUES (10055,'1956-06-06','Georgy','Dredge','M','1992-04-27'),
(10056,'1961-09-01','Brendon','Bernini','F','1990-02-01'),
(10057,'1954-05-30','Ebbe','Callaway','F','1992-01-15'),
(10058,'1954-10-01','Berhard','McFarlin','M','1987-04-13'),
(10059,'1953-09-19','Alejandro','McAlpine','F','1991-06-26'),
(10060,'1961-10-15','Breannda','Billingsley','M','1987-11-02'),
(10061,'1962-10-19','Tse','Herber','M','1985-09-17'),
(10062,'1961-11-02','Anoosh','Peyn','M','1991-08-30'),
(10063,'1952-08-06','Gino','Leonhardt','F','1989-04-08'),
(10064,'1959-04-07','Udi','Jansch','M','1985-11-20');
CREATE TABLE employees_2(
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
INSERT INTO `employees_1` VALUES (10085,'1962-11-07','Kenroku','Malabarba','M','1994-04-09'),
(10086,'1962-11-19','Somnath','Foote','M','1990-02-16'),
(10087,'1959-07-23','Xinglin','Eugenio','F','1986-09-08'),
(10088,'1954-02-25','Jungsoon','Syrzycki','F','1988-09-02'),
(10089,'1963-03-21','Sudharsan','Flasterstein','F','1986-08-12'),
(10090,'1961-05-30','Kendra','Hofting','M','1986-03-14'),
(10091,'1955-10-04','Amabile','Gomatam','M','1992-11-18'),
(10092,'1964-10-18','Valdiodio','Niizuma','F','1989-09-22'),
(10093,'1964-06-11','Sailaja','Desikan','M','1996-11-05'),
(10094,'1957-05-25','Arumugam','Ossenbruggen','F','1987-04-18');四、Doris 安装配置
这里我们以单机版为例:
首先下载 Doris 1.1 release版本:
https://doris.apache.org/downloads/downloads.html
解压到指定目录:
tar zxvf apache-doris-1.1.0-bin.tar.gz -C doris-1.1解压到目录结构是这样的:
.
├── apache_hdfs_broker
│ ├── bin
│ ├── conf
│ └── lib
├── be
│ ├── bin
│ ├── conf
│ ├── lib
│ ├── log
│ ├── minidump
│ ├── storage
│ └── www
├── derby.log
├── fe
│ ├── bin
│ ├── conf
│ ├── doris-meta
│ ├── lib
│ ├── log
│ ├── plugins
│ ├── spark-dpp
│ ├── temp_dir
│ └── webroot
└── udf
├── include
└── lib配置 FE 和 BE:
cd doris-1.0
# 配置 fe.conf 和 be.conf,这两个文件分别在fe和be的conf目录下
打开这个 priority_networks
修改成自己的IP地址,注意这里是CIDR方式配置IP地址
例如我本地的IP是172.19.0.12,我的配置如下:
priority_networks = 172.19.0.0/24
######
在be.conf配置文件最后加上下面这个配置
disable_stream_load_2pc=false- 注意这里默认只需要修改 fe.conf 和 be.conf 同样的上面配置就可以。
- 默认 FE 元数据的目录在 fe/doris-meta 目录下。
- BE 的数据存储在 be/storage 目录下。
启动 FE:
sh fe/bin/start_fe.sh --daemon启动 BE:
sh be/bin/start_be.sh --daemonMySQL 命令行连接 FE,这里新安装的 Doris 集群默认用户是 Root 和 Admin,密码是空:
mysql -uroot -P9030 -h127.0.0.1
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 41
Server version: 5.7.37 Doris version trunk-440ad03
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show frontends;
+--------------------------------+-------------+-------------+----------+-----------+---------+----------+----------+------------+------+-------+-------------------+---------------------+----------+--------+---------------+------------------+
| Name | IP | EditLogPort | HttpPort | QueryPort | RpcPort | Role | IsMaster | ClusterId | Join | Alive | ReplayedJournalId | LastHeartbeat | IsHelper | ErrMsg | Version | CurrentConnected |
+--------------------------------+-------------+-------------+----------+-----------+---------+----------+----------+------------+------+-------+-------------------+---------------------+----------+--------+---------------+------------------+
| 172.19.0.12_9010_1654681464955 | 172.19.0.12 | 9010 | 8030 | 9030 | 9020 | FOLLOWER | true | 1690644599 | true | true | 381106 | 2022-06-22 18:13:34 | true | | trunk-440ad03 | Yes |
+--------------------------------+-------------+-------------+----------+-----------+---------+----------+----------+------------+------+-------+-------------------+---------------------+----------+--------+---------------+------------------+
1 row in set (0.01 sec)将BE节点加入到集群中:
mysql>alter system add backend "172.19.0.12:9050";这里是你自己的IP地址
查看BE:
mysql> show backends;
+-----------+-----------------+-------------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------------------+-----------+------------------+---------------+---------------+---------+----------------+--------------------------+--------+---------------+-------------------------------------------------------------------------------------------------------------------------------+
| BackendId | Cluster | IP | HeartbeatPort | BePort | HttpPort | BrpcPort | LastStartTime | LastHeartbeat | Alive | SystemDecommissioned | ClusterDecommissioned | TabletNum | DataUsedCapacity | AvailCapacity | TotalCapacity | UsedPct | MaxDiskUsedPct | Tag | ErrMsg | Version | Status |
+-----------+-----------------+-------------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------------------+-----------+------------------+---------------+---------------+---------+----------------+--------------------------+--------+---------------+-------------------------------------------------------------------------------------------------------------------------------+
| 10002 | default_cluster | 172.19.0.12 | 9050 | 9060 | 8040 | 8060 | 2022-06-22 12:51:58 | 2022-06-22 18:15:34 | true | false | false | 4369 | 328.686 MB | 144.083 GB | 196.735 GB | 26.76 % | 26.76 % | {"location" : "default"} | | trunk-440ad03 | {"lastSuccessReportTabletsTime":"2022-06-22 18:15:05","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false} |
+-----------+-----------------+-------------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------------------+-----------+------------------+---------------+---------------+---------+----------------+--------------------------+--------+---------------+-------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Doris 单机版安装完成。
五、Flink 安装配置
5.1 下载安装 Flink 1.14.4
wget https://dlcdn.apache.org/flink/flink-1.14.4/flink-1.14.5-bin-scala_2.12.tgz
tar zxvf flink-1.14.4-bin-scala_2.12.tgz需要将下面的依赖拷贝到 Flink 安装目录下的 lib 目录下,具体的依赖的 lib 文件如下:
wget https://jiafeng-1308700295.cos.ap-hongkong.myqcloud.com/flink-doris-connector-1.14_2.12-1.0.0-SNAPSHOT.jar
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar启动 Flink:
bin/start-cluster.sh启动后的界面如下:

六、开始同步数据到 Doris
6.1 创建 Doris 数据库及表
create database demo;
use demo;
CREATE TABLE all_employees_info (
emp_no int NOT NULL,
birth_date date,
first_name varchar(20),
last_name varchar(20),
gender char(2),
hire_date date,
database_name varchar(50),
table_name varchar(200)
)
UNIQUE KEY(`emp_no`, `birth_date`)
DISTRIBUTED BY HASH(`birth_date`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);6.2 进入 Flink SQL Client
bin/sql-client.sh embedded 
开启 Checkpoint,每隔 10 秒做一次 Checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 提交事务。
Source 在启动时会扫描全表,将表按照主键分成多个 Chunk。并使用增量快照算法逐个读取每个 Chunk 的数据。作业会周期性执行 Checkpoint,记录下已经完成的 Chunk。当发生 Failover 时,只需要继续读取未完成的 Chunk。当 Chunk 全部读取完后,会从之前获取的 Binlog 位点读取增量的变更记录。Flink 作业会继续周期性执行 Checkpoint,记录下 Binlog 位点,当作业发生 Failover,便会从之前记录的 Binlog 位点继续处理,从而实现 Exactly Once 语义。
SET execution.checkpointing.interval = 10s;注意:这里是演示,生产环境建议 Checkpoint 间隔 60 秒。
6.3 创建 MySQL CDC 表
在 Flink SQL Client 下执行下面的 SQL
CREATE TABLE employees_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
emp_no int NOT NULL,
birth_date date,
first_name STRING,
last_name STRING,
gender STRING,
hire_date date,
PRIMARY KEY (`emp_no`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'MyNewPass4!',
'database-name' = 'emp_[0-9]+',
'table-name' = 'employees_[0-9]+'
);- 'database-name' = 'emp_[0-9]+':这里是使用了正则表达式,同时连接多个库
- 'table-name' = 'employees_[0-9]+':这里是使用了正则表达式,同时连接多个表
查询 CDC 表,我们可以看到下面的数据,标识一切正常
select * from employees_source limit 10;
6.4 创建 Doris Sink 表
CREATE TABLE cdc_doris_sink (
emp_no int ,
birth_date STRING,
first_name STRING,
last_name STRING,
gender STRING,
hire_date STRING,
database_name STRING,
table_name STRING
)
WITH (
'connector' = 'doris',
'fenodes' = '172.19.0.12:8030',
'table.identifier' = 'demo.all_employees_info',
'username' = 'root',
'password' = '',
'sink.properties.two_phase_commit'='true',
'sink.label-prefix'='doris_demo_emp_001'
);参数说明:
- connector :指定连接器是 Doris
- fenodes:Doris FE 节点 IP 地址及 HTTP Port
- table.identifier :Doris 对应的数据库及表名
- username:Doris 用户名
- password:Doris 用户密码
- sink.properties.two_phase_commit:指定使用两阶段提交,这样在 Stream load 的时候,会在 Http header 里加上 two_phase_commit:true ,不然会失败
- sink.label-prefix :这个是在两阶段提交的时候必须要加的一个参数,才能保证两端数据一致性,否则会失败
- 其他参数参考官方文档:
- https://doris.apache.org/zh-CN/docs/ecosystem/flink-doris-connector.html
这个时候查询 Doris sink 表是没有数据的
select * from cdc_doris_sink;
6.5 将数据插入到 Doris 表里
执行下面的 SQL:
insert into cdc_doris_sink (emp_no,birth_date,first_name,last_name,gender,hire_date,database_name,table_name)
select emp_no,cast(birth_date as string) as birth_date ,first_name,last_name,gender,cast(hire_date as string) as hire_date ,database_name,table_name from employees_source;然后我们可以看到 Flink WEB UI 上的任务运行信息

这里我们可以看看 TaskManager 的日志信息,会发现这里是使用两阶段提交的,而且数据是通过 Http chunked 方式不断朝 BE 端进行传输的,直到 Checkpoint,才会停止。
Checkpoint 完成后会继续下一个任务的提交。
2022-06-22 19:04:08,321 INFO org.apache.doris.flink.sink.writer.DorisStreamLoad [] - load Result {
"TxnId": 6963,
"Label": "doris_demo_001_0_1",
"TwoPhaseCommit": "true",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 40,
"NumberLoadedRows": 40,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 35721,
"LoadTimeMs": 9046,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 0,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 9041,
"CommitAndPublishTimeMs": 0
}
....
2022-06-22 19:04:18,310 INFO org.apache.doris.flink.sink.writer.DorisStreamLoad [] - load Result {
"TxnId": 6964,
"Label": "doris_demo_001_0_2",
"TwoPhaseCommit": "true",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 0,
"NumberLoadedRows": 0,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 0,
"LoadTimeMs": 9988,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 0,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 9983,
"CommitAndPublishTimeMs": 0
}
2022-06-22 19:04:18,310 INFO org.apache.doris.flink.sink.writer.RecordBuffer [] - start buffer data, read queue size 0, write queue size 36.6 查询 Doris 数据
这里插入了 636 条数
mysql> select count(1) from all_employees_info ;
+----------+
| count(1) |
+----------+
| 634 |
+----------+
1 row in set (0.01 sec)
mysql> select * from all_employees_info limit 20;
+--------+------------+------------+-------------+--------+------------+---------------+-------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | database_name | table_name |
+--------+------------+------------+-------------+--------+------------+---------------+-------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | emp_1 | employees_1 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | emp_1 | employees_1 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | emp_1 | employees_1 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | emp_1 | employees_1 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | emp_1 | employees_1 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | emp_1 | employees_1 |
| 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 | emp_1 | employees_1 |
| 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 | emp_1 | employees_1 |
| 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 | emp_1 | employees_1 |
| 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 | emp_1 | employees_1 |
| 10011 | 1953-11-07 | Mary | Sluis | F | 1990-01-22 | emp_1 | employees_1 |
| 10012 | 1960-10-04 | Patricio | Bridgland | M | 1992-12-18 | emp_1 | employees_1 |
| 10013 | 1963-06-07 | Eberhardt | Terkki | M | 1985-10-20 | emp_1 | employees_1 |
| 10014 | 1956-02-12 | Berni | Genin | M | 1987-03-11 | emp_1 | employees_1 |
| 10015 | 1959-08-19 | Guoxiang | Nooteboom | M | 1987-07-02 | emp_1 | employees_1 |
| 10016 | 1961-05-02 | Kazuhito | Cappelletti | M | 1995-01-27 | emp_1 | employees_1 |
| 10017 | 1958-07-06 | Cristinel | Bouloucos | F | 1993-08-03 | emp_1 | employees_1 |
| 10018 | 1954-06-19 | Kazuhide | Peha | F | 1987-04-03 | emp_1 | employees_1 |
| 10019 | 1953-01-23 | Lillian | Haddadi | M | 1999-04-30 | emp_1 | employees_1 |
| 10020 | 1952-12-24 | Mayuko | Warwick | M | 1991-01-26 | emp_1 | employees_1 |
+--------+------------+------------+-------------+--------+------------+---------------+-------------+
20 rows in set (0.00 sec)6.7 测试删除
mysql> use emp_2;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------+
| Tables_in_emp_2 |
+-----------------+
| employees_1 |
| employees_2 |
+-----------------+
2 rows in set (0.00 sec)
mysql> delete from employees_2 where emp_no in (12013,12014,12015);
Query OK, 3 rows affected (0.01 sec)验证 Doris 数据删除
mysql> select count(1) from all_employees_info ;
+----------+
| count(1) |
+----------+
| 631 |
+----------+
1 row in set (0.01 sec)七、总结
本文主要介绍了 Flink CDC 分库分表怎么实时同步,以及其结合 Apache Doris Flink Connector 最新版本整合的 Flink 2PC 和 Doris Stream Load 2PC 的机制及整合原理、使用方法等。希望能给大家带来一点帮助。
转载|SelectDB 公众号作者|张家锋