ccf历年第二题满分python代码及知识点总结(2013-2022)
201312-2ISBN号码
思路:
就是简单的字符串处理,没有什么好说的。
代码:
str_input = input()
s = str_input.replace("-", "")
sum_value = 0
start = 1
for i in range(len(s)-1):
sum_value += int(s[i]) * start
start += 1
last = sum_value % 11
if (last != 0 and s[-1] == str(last)) or (last == 10 and s[-1] == 'X'):
print("Right")
else:
print(str_input[:-1] + str(last) if last != 10 else str_input[:-1] + 'X')
知识点
就是字符串处理吧,一些替换啊,切片啊,拼接啊,很基础的知识点。
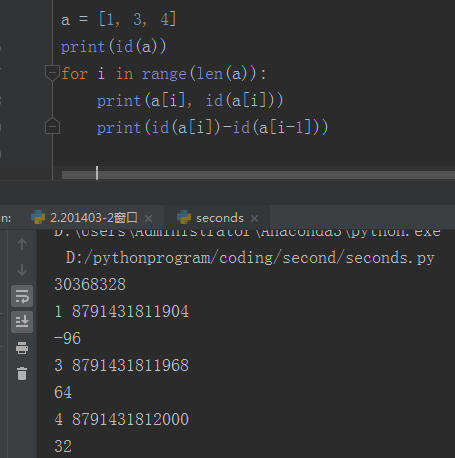
201403-2窗口*
思路
我这思路很清晰,完全没有问题啊,为啥时隔那么久再刷竟然是70分!
就是在每个窗口前面加上两个数,第一个数change_order表示这个窗口现在的顺序,第二个数order表示窗口本来的序号,整个过程不变。
在对每个点遍历的时候,先对窗口排序,逆序判断当前点在不在这个窗口,因为是逆序,所以在的话肯定是上面的窗口,跳出循环,把窗口的本来的序号order加到结果集中,并保存当前窗口first的change_order。如果点不在所有的窗口中,就把"IGNORED"加到结果集中。
遍历窗口,为了让点击所在窗口first为顶层窗口,其他窗口相对顺序不变,如果当前窗口的change_order大于本来first窗口的change_order,那么就-1,本来就比其小的不改变。最后把first窗口的change_order改为最大的值,即N,变成了顶层窗口。
再对下一个点进行循环判断。
这哪里有问题?测试几个样例完全没问题啊。
也许是时间复杂度的问题?因为这样的思路在外层for循环下每次都要排序,时间复杂度是O(n2logn)。
于是就改变一下思路,用一个字典,key是窗口坐标,value是序号。然后对每个点判断的时候,把遇到的窗口加到所有窗口后面,然后把这个窗口出现在第一个的给删掉。
代码:
N, M = map(int, input().split())
windows = []
windows_order = {}
points = []
for i in range(N):
bounds = list(map(int, input().split()))
windows.append(bounds)
windows_order[tuple(bounds)] = i + 1
for j in range(M):
points.append(list(map(int, input().split())))
# 对每次点击存放一次结果
for i in range(M):
x, y = points[i][0], points[i][1]
order = 0
flag = 1
for j in range(N-1, -1, -1):
left_x, left_y = windows[j][0], windows[j][1]
right_x, right_y = windows[j][2], windows[j][3]
if left_x <= x <= right_x and left_y <= y <= right_y:
print(windows_order[tuple(windows[j])])
windows.append(windows[j])
windows.remove(windows[j])
flag = 0
break
if flag:
print("IGNORED")
知识点
这题考察的就是逻辑思维和字典(学霸用的链表),其中列表是不可哈希对象,因为列表是可变的数据类型,所以在创建字典的时候key值用的是元组。怎么去模拟窗口的位置变换,就是把新的顶部窗口加到列表最后面,然后把之前的删除就行。
在和学霸讨论这题的时候,涉及到一些知识点,顺便巩固一下。查看对象的内存地址用id(),顺序列表中的存储空间是连续的。列表的每个元素都有自己的内存地址空间,但是这个列表的内存地址空间和列表第一个元素的地址空间是不一样的。
201409-2画图
思路1
因为1<=n<=100,0<=横坐标、纵坐标<=100。就先创建一个100*100的列表,然后遍历每个矩形坐标,遍历到的就把其赋值为1,最后判断列表中有多少个1即可。
代码1
n = int(input())
rec = []
for i in range(n):
rec.append(list(map(int, input().split())))
paper = [[0] * 100 for _ in range(100)]
for i in range(n):
leftx, lefty, rightx, righty = rec[i][0], rec[i][1], rec[i][2], rec[i][3]
for x in range(leftx, rightx):
for y in range(lefty, righty):
paper[x][y] = 1
rec_cur = sum(paper, [])
print(rec_cur.count(1))
思路2
直接用集合,遍历矩阵,因为集合自动去重,所以最后返回集合的长度即可。
代码2
n = int(input())
rec = []
for i in range(n):
rec.append(list(map(int, input().split())))
ans = set()
for i in range(n):
leftx, lefty, rightx, righty = rec[i][0], rec[i][1], rec[i][2], rec[i][3]
for x in range(leftx, rightx):
for y in range(lefty, righty):
ans.add((x, y))
print(len(ans))
知识点
纯逻辑吧,没什么知识点。第一个代码中用到sum(paper,[])是把二维列表转为一维列表,代码2中用到的是集合的自动去重。
201412-2 Z字形扫描
思路
这题也不涉及什么算法,就是找规律。也是想了一会调试了一会才通过的。
在上半个走位(包括对角线),添加的值的坐标有这样的规律:
如果坐标x、y之和为偶数,如2,就(2,0)(1,1)(0,2),x一直在减小,y一直在增大。如果是奇数,如3,就(0,3)(1,2)(2,1)(3,0),x一直在增大,y一直在减少。
在下半个走位,添加的值的坐标有这样的规律:
如果坐标x、y之和为偶数,如4,就(3,1)(2,2)(1,3),x一直在减小,y一直在增大。如果是奇数,如5,就(2,3)(3,2),x一直在增大,y一直在减少。注意一下x、y的边界。
代码:
n = int(input())
nums = []
for i in range(n):
nums.append(list(map(int, input().split())))
res = []
for i in range(n):
if i % 2:
for j in range(i+1):
res.append(nums[j][i-j])
else:
for j in range(i+1):
res.append(nums[i-j][j])
for i in range(n, (n-1)*2+1):
if i % 2:
for j in range(i-n+1, n):
res.append(nums[j][i-j])
else:
for j in range(i-n+1, n):
res.append(nums[i-j][j])
for k in res:
print(k, end=" ")
201503-2数字排序
思路
用字典得到每个数出现的次数,key是这个数,value是出现次数,然后排序。先value从大到小,然后key从小到大。
代码:
import collections
n = int(input())
nums = list(map(int, input().split()))
dic = collections.Counter(nums)
dic = sorted(dic.items(), key=lambda x: (-x[1], x[0]))
for k in dic:
print(k[0], k[1])
知识点:
字典。这里面用到了字典的排序,这个写法还是蛮有趣的。
201509-2日期计算
思路:
好像没什么好说的。上代码。
代码:
y = int(input())
d = int(input())
month = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
if y % 400 == 0 or (y % 4 == 0 and y % 100 != 0):
month[1] = 29
cur_day = 0
for i in range(12):
cur_day += month[i]
if cur_day >= d:
print(i+1)
print(d-(cur_day-month[i]))
break
201512-2消除类游戏
思路:
先对每一行判断,把符合要求的坐标加到集合中;再对每一列判断,把符合要求的坐标加到集合中。然后把集合中所有的坐标上的元素赋值为0。
代码:
n, m = map(int, input().split())
games = []
for i in range(n):
games.append(list(map(int, input().split())))
zeros = set()
# 判断每行
for i in range(n):
for j in range(m-2):
if games[i][j] == games[i][j+1] == games[i][j+2]:
zeros.update([(i, j), (i, j + 1), (i, j + 2)])
# 判断每列
for j in range(m):
for i in range(n-2):
if games[i][j] == games[i+1][j] == games[i+2][j]:
zeros.update([(i, j), (i + 1, j), (i + 2, j)])
for k in zeros:
x, y = k[0], k[1]
games[x][y] = 0
for i in range(n):
for j in range(m):
print(games[i][j], end=" ")
print()
知识点:
这里我用到了前两天刚学的集合的相关知识,如添加多个元素用update函数,通过for … in …的方式遍历集合中的元素,不能通过索引访问以及集合自动去重的特点。
201604-2俄罗斯方块
思路:
这个这个快乐无以言表,这题我之前刷了很久都不曾满分过,今天满分通过。思路其实蛮简单,就是判断当前新版块的下一个位置是否是1,如果是的话就停止,以这样的方式找到新版块最后应该停在的位置。再把方格图上对应的位置赋值为1即可。上代码更清楚。
代码:
start = []
for i in range(15):
start.append(list(map(int, input().split())))
# 新加入版块
new = []
for i in range(4):
new.append(list(map(int, input().split())))
# 新版块在初始图案位置 最左边所在列
col = int(input())
change_new = []
# 图案上出现新版块为1的位置 为了方便找到最终停止的位置
for i in range(4):
for j in range(col-1, col + 3):
if new[i][j-col+1] == 1:
change_new.append([i, j])
flag = 1
for i in range(15):
judge = []
for k in change_new:
x, y = k[0], k[1]
if [x+1, y] not in change_new and x+1 < 15:
judge.append([x+1, y])
if len(judge) == 0:
flag = 0
else:
for v in judge:
vx, vy = v[0], v[1]
if start[vx][vy] == 1:
flag = 0
if flag:
for j in range(len(change_new)):
change_new[j][0] += 1
# 改变其值
for k in change_new:
x, y = k[0], k[1]
start[x][y] = 1
# 输出最后的结果
for i in range(15):
for j in range(10):
print(start[i][j], end=" ")
print()
知识点
纯纯纯逻辑。
201609-2火车购票
思路
这题也是纯逻辑题,前几年的ccf第二题真的鲜少用到算法。
用了一个数组存放座位的标好,另一个数组初始都存放0,然后如果已经被订了,这个位置就变成1。
对每次购票数进行遍历,先遍历行,如果某一行的空座位大于购票数就安排上。否则,就从头开始遍历,有空位就订上。
突然发现设置一个flag还是蛮好用的。
代码
n = int(input())
tickets = list(map(int, input().split()))
sits = [[0]*5 for i in range(20)]
zero = [[0]*5 for i in range(20)]
for i in range(20):
for j in range(5):
sits[i][j] = 5*i + j + 1
for i in range(n):
num = tickets[i]
ans = []
flag = 1
for j in range(20):
if zero[j].count(0) >= num:
flag = 0
for k in range(5):
if zero[j][k] == 0 and len(ans) < num:
ans.append(sits[j][k])
zero[j][k] = 1
break
if flag:
for ii in range(20):
for jj in range(5):
if zero[ii][jj] == 0 and len(ans) < num:
ans.append(sits[ii][jj])
zero[ii][jj] = 1
for v in ans:
print(v, end=" ")
print()
201612-2工资计算
思路
我愿意将其称之为ccf第二题出的最有猫病的一题,这不纯玩数字呢嘛!根据题目给的几个情况倒推公式。注意结果要向上取整。
代码
import math
after = int(input())
two_high = 5000 - 1500*0.03
three_high = 8000 - 1500*0.03 - 3000*0.1
four_high = 12500 - 1500*0.03 - 3000*0.1 - 4500*0.2
five_high = 38500 - 1500*0.03 - 3000*0.1 - 4500*0.2 - 26000*0.25
six_high = 58500 - 1500*0.03 - 3000*0.1 - 4500*0.2 - 26000*0.25 - 20000*0.3
seven_high = 83500 - 1500*0.03 - 3000*0.1 - 4500*0.2 - 26000*0.25 - 20000*0.3 - 25000*0.35
if after <= 3500:
before = after
elif after <= two_high:
before = (after - 3500*0.03)/(1-0.03)
elif after <= three_high:
before = (after + 1500*0.03 - 5000*0.1) / (1 - 0.1)
elif after <= four_high:
before = (after + 1500*0.03 + 3000*0.1 - 8000*0.2) / (1-0.2)
elif after <= five_high:
before = (after + 1500 * 0.03 + 3000 * 0.1 + 4500*0.2 - 12500 * 0.25) / (1 - 0.25)
elif after <= six_high:
before = (after + 1500 * 0.03 + 3000 * 0.1 + 4500*0.2 + 26000*0.25 - 38500 * 0.3) / (1 - 0.3)
elif after <= seven_high:
before = (after + 1500 * 0.03 + 3000 * 0.1 + 4500*0.2 + 26000*0.25 + 20000*0.3 - 58500 * 0.35) / (1 - 0.35)
else:
before = (after + 1500 * 0.03 + 3000 * 0.1 + 4500 * 0.2 + 26000 * 0.25 + 20000 * 0.3 + 25000*0.35 - 83500 * 0.45) / (1 - 0.45)
print(math.ceil(before))
201703-2学生排队
思路:
上代码上代码,就是列表的删除和插入。
代码:
n = int(input())
m = int(input())
students = [i+1 for i in range(n)]
change = []
for i in range(m):
student, move = map(int, input().split())
ind = students.index(student)
students.pop(ind)
students.insert(ind+move, student)
for k in students:
print(k, end=" ")
201709-2公共钥匙盒
思路
我怎么那么厉害啊,感受到了刷题的乐趣!这题写的蛮快,虽然调试了一会,但思路很清晰。重点在于排序吧。对于每一次的取出(0)和放回(1),拆成两个列表,一个是[钥匙编号,开始时间,0],另一个是[钥匙编号,结束时间,1]。
排序的时候先对时间从小到大排序,因为同一时刻有放回有取出,所以再对1,0排序,最后因为同一时刻多个钥匙按编号从小到大放回所以再对钥匙编号排序。这些排序就依赖于一个sort函数。teachers.sort(key=lambda x: (x[1], -x[2], x[0]))
代码
n, k = map(int, input().split())
teachers = []
keys = [i+1 for i in range(n)]
for i in range(k):
w, s, c = map(int, input().split())
teachers.append([w, s, 0])
teachers.append([w, s+c, 1])
teachers.sort(key=lambda x: (x[1], -x[2], x[0]))
for k in teachers:
if k[2] == 0:
ind = keys.index(k[0])
keys[ind] = 0
else:
for i in range(n):
if keys[i] == 0:
keys[i] = k[0]
break
for v in keys:
print(v, end=" ")
看了之前写的代码(应该不是自己写出来的),思路是一样的,但是代码更加简洁好看。注意添加列表的改变,这样写直接sort就行了(牛哇牛哇)。
N, K = map(int,input().split())
ks = [i+1 for i in range(N)]
A = []
for i in range(K):
w, s, c = list(map(int, input().split()))
A.append([s, 1, w])
A.append([s+c, 0, w])
A.sort()
for s, f, w in A:
if f:
ks[ks.index(w)] = 0
else:
ks[ks.index(0)] = w
for k in ks:
print(k, end=' ')
知识点
sort()函数的花样功能。
201712-2游戏*
思路:
这题竟然给我难住了(肯定是我状态不好)!写了一个小时,先用列表后用循环链表都没调试出来,60分是什么鬼啊!明明感觉很简单嘛!先缓一下。
调试了很久终于知道60分的原因。测试用例16 3,因为12 13是紧挨在一起的,所以在删除的时候链表删的有问题。故只有测试样例中出现连续两个数删除的就会报错。
调试了快两个小时,通过了,但没有快乐可言。关于上面连续两个数都要删除的话,也是用了flag判断了一下。
垃圾代码:
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
n, k = map(int, input().split())
kinds = [i for i in range(n, 0, -1)]
num = 1
i = 0
dummy = ListNode(-1)
cur = dummy
while kinds:
node = ListNode(kinds.pop())
cur.next = node
cur = cur.next
cur.next = dummy.next
# 循环单链表
head = dummy.next
curr = head
num = 1
pre = ListNode(-1)
kinds = [i+1 for i in range(n)]
while len(kinds) > 1:
flag = 1
if num % k == 0 or int(str(num)[-1]) == k:
flag = 0
pre.next = curr.next
kinds.remove(curr.val)
if flag:
pre = curr
curr = curr.next
else:
curr = pre
curr = curr.next
num += 1
print(kinds[0])
另外,我看了之前刷的代码(貌似不是我自己写出来的,但自己写出来的代码也比今晚写的好啊,用的是字典),很优秀,很简单。
优秀代码:
n, k = map(int, input().split())
a = [i+1 for i in range(n)]
numb = 0
# 当前数的数
count = 1
while len(a) != 1:
if numb + 1 > len(a):
numb = 0
if count % k == 0 or count % 10 == k:
a.pop(numb)
else:
numb += 1
count += 1
print(a[0])
201803-2碰撞的小球
思路:
今天同学约了10点打羽毛球,早上来图书馆把这题刷出来,就是很开心嘛(我怎么那么勤奋啊!)。
用1和-1表示球的方向,当两个球碰撞的时候或者在0和L的时候就改变其方向,又因为最后需要按序号输出,所以又加了一个序号便与输出。
再刷通过的代码还是没有之前在网上看到的带有优美,水平还不够啊。
代码:
n, L, t = map(int, input().split())
start = list(map(int, input().split()))
move = []
for i in range(n):
# 1表示向右 -1表示向左
move.append([start[i], 1, i])
# 处理每一时刻球的位置变动
for time in range(t):
move.sort(key=lambda x: x[0])
for j in range(n-1):
if move[j][0] == move[j+1][0]:
move[j][1] = - move[j][1]
move[j+1][1] = -move[j+1][1]
if move[j][0] == 0 or move[j][0] == L:
move[j][1] = -move[j][1]
move[j][0] += move[j][1]
# 为防止越界 最后一个球单独处理
if move[j+1][0] == 0 or move[j+1][0] == L:
move[j+1][1] = - move[j+1][1]
move[j+1][0] += move[j+1][1]
move.sort(key=lambda x: x[2])
for k in move:
print(k[0], end=" ")
之前的优秀代码(网上参考):
n, L, t = map(int, input().split())
a = list(map(int, input().split()))
dir = [1]*n
for i in range(t):
for j in range(n):
if a[j] == L or a[j] == 0:
dir[j] = -dir[j]
if a.count(a[j]) != 1:
dir[j] = -dir[j]
a = [i+j for i, j in zip(a, dir)]
for i in a:
print(i, end=' ')
知识点:
我的代码又是用到了sort函数,优秀代码里用到了zip()函数。a = [i+j for i, j in zip(a, dir)]
201809-2买菜
思路:
建一个最长的列表note,元素都是0。然后遍历两个人的时间列表,假如时间段是[1,3],就把列表note[1]、note[2]都加一,以此类推。最后输出这个列表中2的个数。
代码:
n = int(input())
H = [list(map(int, input().split())) for _ in range(n)]
W = [list(map(int, input().split())) for _ in range(n)]
max_time = max(H[-1][1], W[-1][1])
note = [0]*max_time
for i in range(n):
x1, y1 = H[i][0], H[i][1]
for j in range(x1, y1):
note[j] += 1
x2, y2 = W[i][0], W[i][1]
for j in range(x2, y2):
note[j] += 1
print(note.count(2))
201812-2小明放学*
思路
我觉得代码特别正确,为什么只有30分!就很不开心啊!看了之前我刷出来的代码,前后做了一下对比。就是每种情况要考虑四种情况,最后一种我开始漏了。(直接看代码注释)卡在逻辑上(调了两个小时左右吧),很难受!
代码
r, y, g = map(int, input().split())
n = int(input())
times = [list(map(int, input().split())) for _ in range(n)]
ans = 0
period = r + y + g
# 红-> 绿 -> 黄
for i in range(n):
period_time = ans % period
if times[i][0] == 0:
ans += times[i][1]
# 出发时是红灯
elif times[i][0] == 1:
red = times[i][1]
# 当前还是红灯 +剩余等红灯时间
if period_time < red:
ans += (red - period_time)
# 当前是绿灯 直接通过
elif period_time < (red + g):
continue
# 当前是黄灯 +剩余的黄灯+红灯
elif period_time < red + g + y:
# (period_time - red - g)是黄灯已经走过了这些s 还要等y - (period_time - red - g)s
ans += (y - (period_time - red - g) + r)
elif period_time < red + period:
ans += r - (period_time - red - g - y)
# 出发时是黄灯
elif times[i][0] == 2:
yellow = times[i][1]
# 当前还是黄灯 + 剩余的黄灯 + 红灯
if period_time < yellow:
ans += (yellow - period_time + r)
# 当前是红灯 + 剩余的红灯
elif period_time < (yellow + r):
ans += r - (period_time - yellow)
# 当前是绿灯
elif period_time < yellow + r + g:
continue
elif period_time < yellow + period:
ans += y - (period_time - yellow - r - g) + r
else:
green = times[i][1]
# 当前是绿灯 直接走
if period_time < green:
continue
# 当前是黄灯 + 剩余黄灯+r
elif period_time < (green + y):
ans += y - (period_time - green) + r
# 当前是红灯 +剩余红灯
elif period_time < green + y + r:
ans += r - (period_time - green - y)
elif period_time < green + period:
continue
print(ans)
啊哈,看了学霸的代码,纯纯属于是每一行都能看懂,放在一起看不懂。写的很简洁漂亮。这个图画的太好了。

学霸的代码:
r, y, g = map(int, input().split())
n = int(input())
times = []
ans = 0
for i in range(n):
state, time = map(int, input().split())
if state == 3:
time = g - time
elif state == 2:
time = g + y - time
elif state == 1:
time = g + y + r - time
if state == 0:
ans += time
else:
time = (time + ans) % (r + y + g)
if time > g:
ans += (r + y + g) - time
print(ans)
201903-2二十四点
思路:
直接把字符串中的“x”替换成“*”,把“/”替换成“//”。知识点的话一个是字符串的替换replace函数一个是eval()会自动把里面的操作转换成一个整数。
代码:
n = int(input())
res = []
for i in range(n):
string = input()
string = string.replace("x", "*").replace("/","//")
res.append(eval(string))
for k in res:
if k == 24:
print("Yes")
else:
print("No")
201909-2小明种苹果(续)
思路:
目前遇到的第二题还都是纯逻辑的,没有涉及到什么算法。直接上代码吧。
n = int(input())
apples = [list(map(int, input().split())) for _ in range(n)]
applenums = 0
drop = [0]*n
for i in range(n):
applenum = 0
m = apples[i][0]
for j in range(1, m+1):
if apples[i][j] > 0:
if applenum > apples[i][j]:
drop[i] = 1
applenum = apples[i][j]
else:
applenum += apples[i][j]
applenums += applenum
E = 0
for i in range(n-1):
if drop[i-1] == drop[i] == drop[i+1] == 1:
E += 1
if drop[-2] == drop[-1] == drop[0] == 1:
E += 1
print(applenums, sum(drop), E)
201912-2回收站选址
思路:
用字典存放0-4分各自的点位数。用集合存放坐标,为了方便查找。遍历每个点,先判断其上下左右四个点是否在集合里,然后再判段四个角与原来集合的交集的长度即为该点的分数。
代码:
n = int(input())
axis = {tuple(map(int, input().split())) for _ in range(n)}
dic = {0: 0, 1: 0, 2: 0, 3: 0, 4: 0}
for k in axis:
x, y = k[0], k[1]
if (x+1, y) in axis and (x-1, y) in axis and (x, y+1) in axis and (x, y-1) in axis:
cur_set = {(x-1, y-1), (x-1, y+1), (x+1, y-1), (x+1, y+1)}
score = len(axis.intersection(cur_set))
dic[score] += 1
for i in range(5):
print(dic[i])
202006-2稀疏向量
思路:
直接用字典,没有什么套路可言。不过话说回来,我研一的时候刷这题刷了好久都没写出来,记得当时在吃黄焖鸡的时候问同问小吴,那时候是有多菜啊(虽然现在也没有多厉害)。
代码:
n, a, b = map(int, input().split())
ans = 0
dica = {}
for i in range(a):
index, value = map(int, input().split())
dica[index] = value
for j in range(b):
index, value = map(int, input().split())
if index in dica:
ans += dica[index] * value
print(ans)
202009-2风险人群筛查
思路:
time表示当前这个人连续停留在危险区域的时间,因为判断的时候是判断当前时刻和上一时刻都在危险区域,所以初始值设置为1。(一开始我设置为0提交0分)
代码:
n, k, t, xl, yd, xr, yu = map(int, input().split())
through = 0
stay = [0]*n
for i in range(n):
flag = 0
time = 1
time_note = [0]*t
axis = list(map(int, input().split()))
for j in range(0, 2*t, 2):
x, y = axis[j], axis[j+1]
if xl <= x <= xr and yd <= y <= yu:
flag = 1
time_note[j//2] = 1
if time_note[j//2-1] == 1 and (j//2 - 1) != -1:
time += 1
if time >= k:
stay[i] = 1
else:
time = 1
if flag:
through += 1
print(through)
print(sum(stay))
202012-2期末预测之最佳阈值***(前缀和)
思路:
这个开始涉及算法了,因为直接写,即使使用哈希也只能70分。又是写了几个小时没写出来,最后还是看了之前写的代码。
用一个字典,key是候选值,value是一个列表[候选值0的个数,候选值1的个数]。对候选值列表从大到小排序,正序遍历计算前缀和,得到大于等于该候选值且值为1的个数。倒序遍历计算前缀和(-当前候选值0的个数),得到小于该候选且值为0的个数。大于等于的和小于的对应数相加就得到当前候选值的分数。
感觉就是前缀和和差分的题目还要多刷。
代码:
m = int(input())
dic = {}
candidates = []
for i in range(m):
y, result = map(int, input().split())
if y not in dic:
dic[y] = [0, 0]
if result == 0:
dic[y][0] += 1
else:
dic[y][1] += 1
candidates += [y]
else:
if result == 0:
dic[y][0] += 1
else:
dic[y][1] += 1
candidates.sort(reverse=True)
bigger = []
big = 0
for i in range(len(candidates)):
big += dic[candidates[i]][1]
bigger += [big]
smaller = []
small = 0
for i in range(len(candidates)-1, -1, -1):
small += dic[candidates[i]][0]
smaller += [small - dic[candidates[i]][0]]
res = [0] * len(candidates)
for i in range(len(candidates)):
res[i] = bigger[i] + smaller[len(candidates)-i-1]
print(candidates[res.index(max(res))])
202104-2邻域均值
思路:
快乐快乐就是如此简单!提交一次通过!(我太棒啦!)
用二维前缀和,先求出二维前缀和矩阵,然后对于每个区域利用加减得到该区域的和,再计算该区域元素个数,注意边界问题。
代码:
n, L, r, t = map(int, input().split())
pixels = [list(map(int, input().split())) for _ in range(n)]
pre_pixels = [[0]*n for _ in range(n)]
pre_pixels[0][0] = pixels[0][0]
for i in range(1, n):
pre_pixels[i][0] += pre_pixels[i-1][0] + pixels[i][0]
pre_pixels[0][i] += pre_pixels[0][i-1] + pixels[0][i]
for i in range(1, n):
for j in range(1, n):
pre_pixels[i][j] = pre_pixels[i-1][j] + pre_pixels[i][j-1] - pre_pixels[i-1][j-1] + pixels[i][j]
res = 0
for i in range(n):
for j in range(n):
rowup = max(0, i - r)
rowdown = min(i + r, n-1)
colleft = max(0, j - r)
colright = min(j + r, n-1)
left = pre_pixels[rowdown][colleft-1] if j-r > 0 else 0
up = pre_pixels[rowup-1][colright] if i - r > 0 else 0
again = pre_pixels[rowup-1][colleft-1] if (j-r-1 >= 0 and i-r-1 >= 0) else 0
cur_sum = pre_pixels[rowdown][colright]
area = cur_sum - left - up + again
num = (rowdown - rowup + 1) * (colright - colleft + 1)
value = area / num
if value <= t:
res += 1
print(res)
202109-2非零段划分
思路:
吐了,又70分。(看了之前代码)
时间超时,就要想一想字典和集合!因为哈希的增删改查的时间复杂度是O(1)!期末预测的那题也是用字典,要考虑怎么存键值对!
太美了,真的是太美了!
首先为了方便处理头尾,在头尾各插入一个0。
然后字典中key是出现的值,value是出现的值的下标的列表。
遍历的时候先对p集合排序,然后对每个值的下标判断,该值前后都大于0,则段+1,都等于0,则段数-1。
代码:
n = int(input())
a = [0]+list(map(int, input().split()))+[0]
seta = sorted(set(a))
dic = {}
# dic 中存放的是每个值 和其出现的下标
for i in range(1, n+1):
if a[i] in dic:
dic[a[i]].append(i)
else:
dic[a[i]] = [i]
pri = 0
num = 0
for i in range(n):
if a[i] == 0 and a[i+1] != 0:
num += 1
for key in seta:
if key == 0:
continue
for index in dic[key]:
a[index] = 0
if a[index-1] > 0 and a[index+1] > 0:
num += 1
elif a[index-1] == 0 and a[index+1] == 0:
num -= 1
pri = max(pri, num)
print(pri)
202112-2序列查询新解
思路:
就是分段求解,ans += a*abs(fi - gi),a是前面的系数,是当前fx段和gx段的较小值。
如果在fx段,那系数a就是gx的剩余段长,此时fx要减去gx的当前段,gx的值加一,gx段重新变成r。
如果在gx段,那么系数就是fx的剩余段长,此时那遍历fx的下一段。
代码:
n, N = map(int, input().split())
A = list(map(int, input().split()))
fsteps = [A[0]]
for i in range(1, n):
fsteps.append(A[i] - A[i-1])
fsteps.append(N - A[-1])
r = N // (n+1)
ans = 0
gstep = r
value = 0
i = 0
while i <= n:
# 当前段在fx gx可能会到一个新的段
if fsteps[i] >= gstep:
ans += gstep * abs(i - value)
fsteps[i] -= gstep
value += 1
gstep = r
# 当前段在gx fx可能对到一个新的段
else:
ans += fsteps[i] * abs(i-value)
gstep -= fsteps[i]
i += 1
print(ans)
202203-2出行计划*****
思路:
写出来倒是快,一提交又是70分。完全想不到其他思路。
网上看了一个代码写的蛮漂亮,用的差分思想,按着自己的理解改了一点点。
这题不能对每个查询再对每项出行计划遍历。先对每项出行计划算出其能进入的最早核酸证明时间和最晚核算证明时间。
然后创建一个列表,注意其长度应该是最大值+2。差分的思想在于进入这个区间+1,出去这个区间-1,最后进行前缀和计算。
再返回结果的时候如果下标超了应该返回0。
代码变现出来的就是这些个意思,但是其实我还不是非常懂这个这个差分。
代码:
n, m, k = map(int, input().split())
spots = [list(map(int, input().split())) for _ in range(n)]
num = 0
for i in range(n):
# 变成 [能进入的最早核酸报告, 能进入的最晚核酸报告]
# 例如[11, 24] 你最晚核酸得11出来,你12出来就赶不上了
# 例如[35, 24] 你最早核酸12出来 你11出来 到35 你已经过了24h 失效了
spots[i][0], spots[i][1] = max(1, spots[i][0]-spots[i][1]+1), spots[i][0]
times = []
for i in range(m):
point = int(input())
times.append(point+k)
# 长度num是最大值+2 因为最大值如例子中的35 要在temp[36]-1 所以num为37
num = spots[-1][1] + 2
temp = [0 for i in range(num)]
for spot in spots:
# 进入该区间 满足条件的结果+1
temp[spot[0]] += 1
# 过了该区间 满足条件的结果-1
temp[spot[1]+1] -= 1
# 前缀和
for i in range(1, num):
temp[i] += temp[i-1]
for time in times:
print(temp[time] if time <= num else 0)
202206-2寻宝!大冒险!
思路:
用哈希!前几天刚刷过。
把每棵树的坐标(x,y)作为藏宝图的(0,0)位置,然后判断这棵树的位置满不满足条件。怎么判断呢?
先把藏宝图reverse一下,然后藏宝图中的每个坐标都加分别加上x,y。如果是1则判断绿化图中树的坐标中有没有它,没有就说明这个点不对,跳出循环。如果是0,但树中有它说明也对不上,跳出循环。另外一点就是,如果越界的话也不行,跳出循环。
那怎么查找?哈希表的查找时间复杂度是O(1)啊!
python里集合也是哈希表!(集合不能通过索引访问)
感觉近几年其实算法涉及的也不是很多,第二题偏向考察哈希表,此外涉及到就是一维二维前缀和。
代码:
n, L, S = map(int, input().split())
trees = {tuple(map(int, input().split())) for _ in range(n)}
graph = [list(map(int, input().split())) for _ in range(S+1)]
graph.reverse()
ans = 0
for k in trees:
flag = 1
x, y = k[0], k[1]
for j in range(S+1):
for k in range(S+1):
newx, newy = x + j, y + k
if newx > L or newy > L:
flag = 0
break
elif graph[j][k] == 1 and (newx, newy) not in trees:
flag = 0
break
elif graph[j][k] == 0 and (newx, newy) in trees:
flag = 0
break
if flag:
ans += 1
print(ans)
202209-2 何以包邮?
思路:
笑死人,上次考试的时候用的回溯,回溯本质也就是暴力,最多剪剪枝,但还是不够,70分。想到背包问题,但是背包问题是求小于等于某个容量,就这,就转换不过来了。
学霸说了一下思路,啊哈,背包的容量是书的总价格-邮费的价格,背包里放价值最大的书,剩下的就是最小的。
经典的01背包问题啊!
代码:
n, x = map(int, input().split())
prices = []
for i in range(n):
prices.append(int(input()))
sum_prices = sum(prices)
bagsize = sum_prices - x
dp = [0] * (bagsize + 1)
for i in range(n):
for j in range(bagsize, prices[i]-1, -1):
dp[j] = max(dp[j], dp[j-prices[i]] + prices[i])
print(sum_prices - max(dp))
至此5天左右时间把ccf共28道第二题重刷一遍结束。有感觉到自己的进步,但不多。
其中最开心的莫过于通过之前没有通过的俄罗斯方块和大冒险,而窗口、游戏、小明放学、非零段划分、出行计划这几题刷的还不是很顺畅。前三题是逻辑,后两题是哈希和差分。
总体感觉第二题用哈希降低复杂度的比较多,其他考察的主要是逻辑思考能力,此外也就近几年涉及到几个算法,一维二维前缀和、差分、背包问题。