MySQL数据库入门级基础宝藏干货!!!
目录
关于个人笔记归纳
官网下载并安装MySQL
SQL通用语法
SQL分类
DDL--数据库-操作
DDL- 表操作-创建
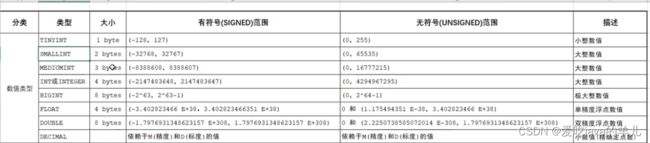
DDL-表操作-数据类型(参考《MySQL数据类型》)
DDL-表操作-修改
DML-介绍
DML-添加数据
DML-修改数据
DML-删除数据
DQL-介绍
DQL语法
DQL-基本查询
DQL-条件查询
DQL-聚合函数
DQL-分组查询
DQL-排序查询
DQL-分页查询
DQL-总结
DCL-管理用户
DCL-权限控制(常用)
关于个人笔记归纳
官网下载并安装MySQL
安装完毕(两种方式打开MySQL数据库)
方式一:win+R--->输入services.msc回车(找到MySQL80打开即可)
方式二:命令行(win+R--->输入cmd回车)---->直接输入net start mysql80(启动)
//net stop mysql80(停止)
客户端的连接
方法一:MySQL提供的客户端命令行工具

方法二:系统自带的命令行工具执行命令
mysql[-h 127.0.0.1][-p 3306] -u root -p(使用这种方式时需要配置PATH环境变量---->高级系统设置--->环境变量--->添加系统变量PATH(将MySQL目录下的bin文件的路径复制粘贴)
关系型数据库(RDBMS)
建立在关系型模型基础上,由多张相互连接的二维码组成的数据库
特点:1、使用表存储数据,格式统一,便于维护
2、使用SQL语言操作,标准统一,使用方便
SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾
2、SQL语句可以使用空格/缩进来增强语句的可读性
3、MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
4、注释:单行用 -- or # 多行用/* */
SQL分类
| DDL |
数据定义语言,用来定义数据库对象(数据库、表、字段) |
| DML | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | 数据查询语言,用来查询数据库中表的记录 |
| DCL | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 |
DDL--数据库-操作
查询所有数据库show databases;
查询当前数据库show database();
创建create database[if not exists]数据库名[default charset字符集][collate排序规则]
删除drop database[if exists]数据库名
使用use数据库名
DDL-表操作-查询
| 查询当前数据库所有表 | show tables; |
| 查询表结构 | desc 表名; |
| 查询指定表的建表结构语句 | show create table表名; |
DDL- 表操作-创建
create table 表名(
字段1 字段1类型[comment 字段1注释],
字段2字段2类型[comment 字段2注释],
.......
字段n字段n类型[comment 字段n注释]
)[comment 表注释];
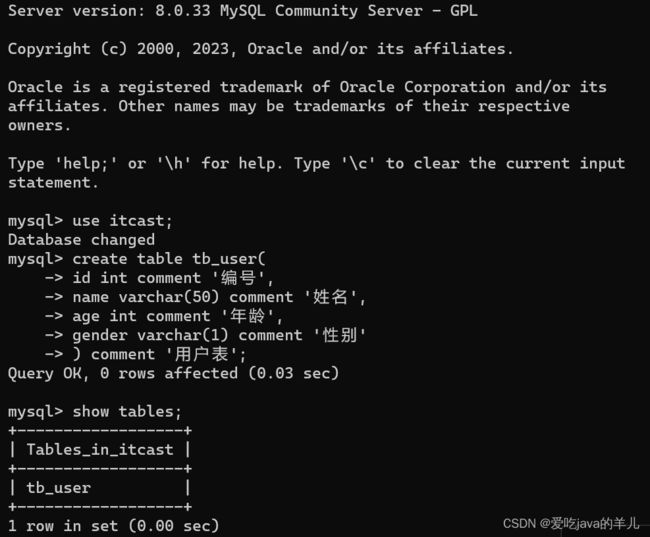
DDL-表操作-数据类型(参考《MySQL数据类型》)

char---性能好(用户名usename varchar(50))性别 gender char(1)
varchar---性能较差

eg1:根据需求创建表(设计合理的数据类型、长度)
编号(纯数字id int )员工工号(字符串类型,长度不超过10位workno varchar)
员工姓名(字符串类型,长度不超过10位name varchar)
性别(男/女,存储员工汉字gender char)
年龄(正常人年龄,不可能存在负数age tinyint unsigned )
身份证号(二代身份证号均为18位,身份证中有X这样的字符idcard char)
入职时间(取值年月日即可entrydate date)

DDL-表操作-修改
添加字段
alter table表名add字段名 类型(长度)[comment注释] [约束];
修改数据类型
alter table 表名modify字段名 新数据类型(长度);
修改字段名和字段类型
alter table表名change旧字段名 新字段名 类型(长度)[comment注释] [约束];
删除字段
alter table 表名drop字段名;
修改表名
alter table表名rename to 新表名;
删除表
drop table[if exists]表名;
删除指定表,并重新创建该表(删除该表时,数据也会全部删除)
truncate table表名;
MySQL图形化界面---DataGrip
下载并安装(不做详细介绍)
DML-介绍
添加数据(insert)
修改数据(update)
删除数据(delete)
DML-添加数据
1、给指定字段添加数据
insert into表名(字段名1,字段名2,...)values(值1,值2,...);
2、给全部字段添加数据
insert into 表名values(值1,值,...);
3、批量添加数据
insert into 表名(字段名1,字段名2,...)values(值1,值2,...),(值1,值2,...),(值1,值2,...);
insert into表名values(值1,值2,...),(值1,值2,...);
*注意:
·插入数据时,指定的字段顺序需要于值的顺序是一一对应的。
·字符串和日期数据应该包含在引号中。
·插入的数据大小,应该在字段的规定范围内。
DML-修改数据
update表名set 字段名1=值1,字段名2=值2,...[where 条件];
注意:修改语句的条件可以有,也可以没有,如果没用条件则会修改整张表是所有数据
DML-删除数据
delete from表名[where 条件]
注意:·delete语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
·delete语句不能删除某一个字段的值(可以使用update)
DQL-介绍
查询关键字:select
DQL语法

DQL-基本查询
1、查询多个字段
select 字段1,字段2,字段3,...from 表名;
select * from 表名;
2、设置别名
select 字段1[as 别名1],字段2[as 别名2]...from 表名;
3、去除重复记录
select distinct 字段列表 from 表名;
DQL-条件查询
1、语法
select 字段列表 from 表名 where 条件列表;
2、条件
| 比较运算符 | 功能 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| between...and... | 在某个范围之内(含最小、最大值) |
| in(...) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(匹配单个字符,%匹配任意个字符) |
| is null | 是null |
| 逻辑运算符 | 功能 |
| and 或 && | 并且(多个条件同时成立) |
| or 或 || | 或者(多个条件任意一个成立) |
| NOT或 ! | 非,不是 |
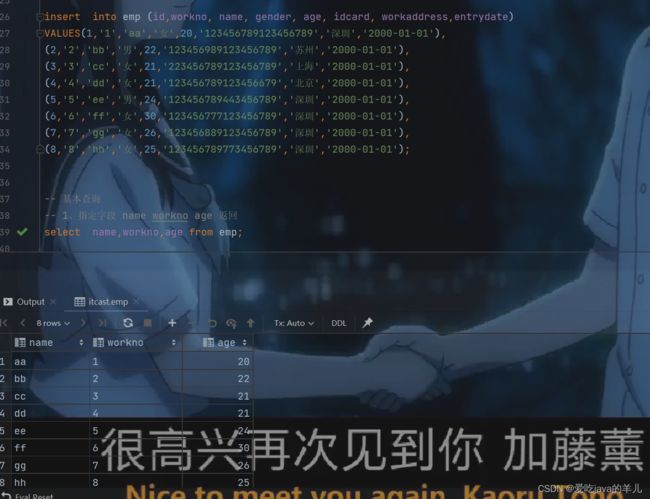
-- 基本查询
-- 1、指定字段 name workno age 返回
select name,workno,age from emp;
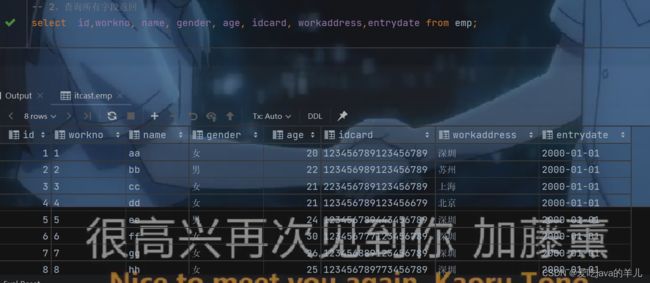
-- 2、查询所有字段返回
select id,workno, name, gender, age, idcard, workaddress,entrydate from emp;
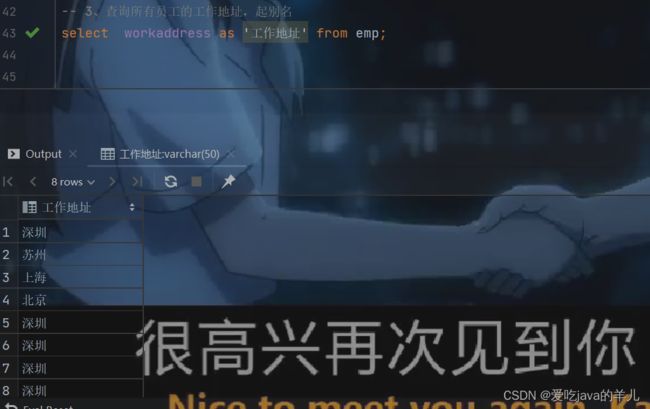
-- 3、查询所有员工的工作地址,起别名
select workaddress as '工作地址' from emp;
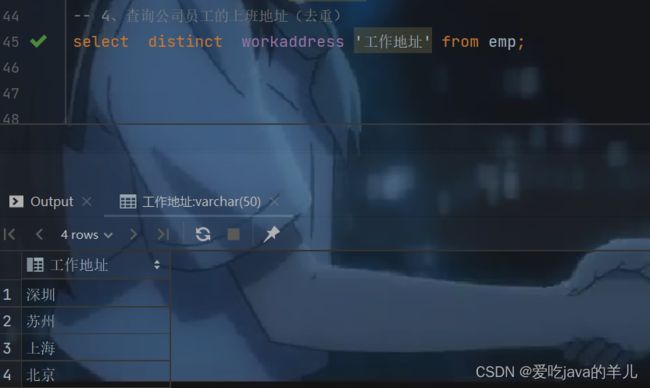
-- 4、查询公司员工的上班地址(去重)
select distinct workaddress '工作地址' from emp;
-- 条件查询
-- 1、查询年龄等于24的员工
select * from emp where age =24;
-- 2、 查询年龄小于26的员工信息
select * from emp where age < 26;
-- 3、查询年龄小于等于23的员工信息
select * from emp where age <= 23;
-- 4、查询有身份证号的员工信息
select * from emp where idcard is not null;
-- 5、 查询年龄不等于23的员工信息
select * from emp where age != 23;
select * from emp where age <> 23;
-- 6、查询年龄在20岁(包含)到28岁(包含)之间额员工信息
select * from emp where age >=20 && emp.age <= 28;
select * from emp where age >=20 and emp.age <= 28;
select * from emp where age between 20 and 28;
-- 7、查询性别为女且小于27岁的员工信息
select * from emp where gender ='女'and age <27;
-- 8、查询年龄等于20或30或40的员工信息
select * from emp where age =20 or age =30 or age =40;
select * from emp where age in (20,30,40);
-- 9、查询姓名为两个字的员工信息
select * from emp where name like '__';
-- 10、查询身份证号最后一位是9的员工信息
select * from emp where idcard like '%9';
select * from emp where idcard like '_________________9';
DQL-聚合函数
1、介绍
将一列数据作为一个整体,进行纵向计算
2、常见聚合函数
| 函数 | 功能 |
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
3、语法
select 聚合函数(字段列表)from 表名;
*所有的null值不参与所有聚合函数运算
-- 1、统计员工数量
select count(*) from emp;
-- 2、统计员工平均年龄
select avg(age)from emp;
-- 3、统计员工的最大年龄
select max(age)from emp;
-- 4、统计员工最小年龄
select min(age)from emp;
-- 5、统计深圳员工的年龄之和
select sum(age)from emp where workaddress='深圳';
DQL-分组查询
1、语法
select 字段列表 from 表名[where 条件]group by分组字段名[having分组后过滤条件];
2、where 与having区别
·执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤
·判断条件不同:where不能对聚合函数进行判断,而having可以
注意:*执行顺序:where>聚合函数>having
*分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
DQL-排序查询
1、语法
select 字段列表from表名order by 字段1 排序方式1,字段2 排序方式2;
2、排序方式
asc:升序(默认值)
desc:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
-- 排序查询
-- 1、根据年龄对员工进行升序
select * from emp order by age asc ;
-- 2、根据id,对员工进行降序
select * from emp order by id desc ;
-- 3、根据年龄对员工进行升序,年龄相同再根据id进行排序
select *from emp order by age asc ,id desc ;DQL-分页查询
1、语法
select 字段列表 from表名limit 起始索引,查询记录数;
注意:
*起始索引从0开始,起始索引 =(查询页码-1)*每页显示记录数。
*分页查询是数据库的发言,不同的数据库有不同的实现,MySQL中是limit
*如果查询的是第1页数据,起始索引可以省略,直接简写为limit 5(一页展示5条记录)
-- 分页查询
-- 1、查询第一页员工数据,每页展示5条记录
select * from emp limit 0,5;
select * from emp limit 5;
-- 2、 查询第二页员工数据,每页展示3条记录
select * from emp limit 1,3-- (页码-1)+页展示记录数DQL-总结
-- 1、查询年龄为21、23、24的女性员工信息
select * from emp where gender ='女' and age in (21,23,24);
-- 2、查询性别为男,并且年龄在20-30(包含)以内的姓名为两个字的员工
select * from emp where gender ='男' and (age between 20 and 30)and name like '__';
-- 3、统计员工表中,年龄小于30岁的,男性员工和女性员工的人数
select gender,count(*)from emp where age <30 group by gender;
-- 4、查询性别为女,且年龄在20-30(包含)以内的3个员工信息,对查询的结果按年龄升序排序,年龄相同按id升序排序
select * from emp where gender='女' and age between 20 and 30 order by age asc ,id asc limit 3;DCL-管理用户
1、查询用户
use mysql;
select * from user;
2、创建用户
create user '用户名'@‘主机名’ identified with mysql_native_password by '新密码';
3、修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by'新密码';
4、删除用户
drop user '用户名'@'主机名';
-- 创建用户zzq,只能够在当前主机localhost访问,密码229815;(并未分配权限)
create user 'zzq'@'localhost' identified by '229815';
-- 创建用户abc,可以在任意主机访问该数据库,密码123456;
create user 'abc'@'%' identified by '123456';
-- 修改用户abc的访问密码为12345;
alter user 'abc'@'%' identified with mysql_native_password by '12345';
-- 删除zzq@localhost用户
drop user 'zzq'@'localhost';注意:主机名可以使用%通配
这类SQL开发人员操作的比较少,主要是DBA(Database Administrator 数据库管理员)使用
DCL-权限控制(常用)
| 权限 | 说明 |
| all , all privileges | 所有权限 |
| select | 查询数据 |
| insert | 插入数据 |
| update | 修改数据 |
| delete | 删除数据 |
| alter | 修改表 |
| drop | 删除数据库/表/视图 |
| create | 创建数据库/表 |
1、查询权限
show grants for '用户名'@'主机名 ';
2、授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
3、撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
-- 查询权限
show grants for 'abc'@'%';
-- 授予权限
grant all on itcast.*to 'abc'@'%';
-- 撤销权限
revoke all on itcast.*from 'abc'@'%';函数是指一段可以直接被另一段程序调用的程序或代码
常用字符串函数
| 函数 | 功能 |
| concatenate(S1,S2...Sn) | 字符串拼接,将S1,S2,...Sn拼接成一个字符串 |
| lower(str) | 将字符串str全部转为小写 |
| upper(str) | 将字符串str全部转为大写 |
| lpad(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| rpad(str,n,pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| trim(str) | 去掉字符串头部和尾部的空格 |
| substring(str,start,len) | 返回从字符串str从start位置起的len个长度的字符串 |
-- concat拼接
select concat('Hello','MySQL');
-- lower全部转为小写
select lower('Hello');
-- upper全部转为大写
select upper('Hello');
-- lpad左填充
select lpad('01',5,'-');
-- rpad右填充
select rpad('01',5,'-');
-- trim去头尾空格
select trim(' Hello MySQL');
-- substring返回从字符串str从start位置起的len个长度的字符串
select substring('Hello MySQL',1,5);
常见数值函数
| 函数 | 功能 |
| ceil(x) | 向上取整 |
| floor(x) | 向下取整 |
| mod(x,y) | 返回x/y的模 |
| rand() | 返回0~1内的随机数 |
| round(x,y) | 求参数x的四舍五入的值,保留y位小数 |
-- 数值函数
-- ceil向上取整
select ceil(1.5);
-- floor向下取整
select floor(7,4);
-- mod求模运算
select mod(5,4);
-- rand 返回0~1内的随机数
select rand();
-- round四舍五入值,保留2位小数
select round(2.344,2);日期函数
| 函数 | 功能 |
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| now() | 返回当前日期和时间 |
| year(date) | 获取指定date的年份 |
| month(date) | 获取指定date的月份 |
| day(date) | 获取指定date的日期 |
| date_add(date,interval expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| datediff(date1,date2) | 返回起始时间date1和结束时间date2之间的天数 |
-- 日期函数
-- curdate()返回当前日期
select curdate();
-- curtime()返回当前时间
select curtime();
-- now()返回当前日期和时间
select now();
-- YEAR,MONTH,DAY获取指定的年月日
select year(now());
select MONTH(now());
select DAY(now());
-- date_add现在时间+70年
select date_add(now(),INTERVAL 70 YEAR );
-- datediff相差时间(第一个时间-第二个时间)
select datediff('2023-12-23','2023-5-23');流程函数
| 函数 | 功能 |
| if(value,t,f) | 如果value为true,则返回t,否则返回f |
| ifnull(value1, value2) | 如果value不为空;返回value1,否则返回value2 |
| case when[val1] then[res1]...else[default] end | 如果val1为true,返回res1,...否则返回default默认值 |
| case[expr]when[val1]then[res1]...else[default] end | 如果expr的值等于val1,返回res1,...否则返回default默认值 |
create table score(
id int comment 'ID',
name varchar(20)comment '姓名',
math int comment '数学',
english int comment '英语',
chinese int comment '语文'
)comment '学员成绩表';
insert into score(id, name, math, english, chinese) VALUES
(1,'Tom',67,88,95),(2,'Rose',23,66,98),(3,'Bob',56,98,77);
-- 案例:统计班级各个学员的成绩,展示的规则如下:
-- >=85,展示优秀
-- >=60,展示及格
-- 否则,展示不及格
select
id,
name,
(case when math >= 85 then '优秀' when math >=60 then '及格' else '不及格' end ) '数学',
(case when english >= 85 then '优秀' when english >=60 then '及格' else '不及格' end ) '英语',
(case when chinese >= 85 then '优秀' when chinese >=60 then '及格' else '不及格' end ) '语文'
from score;约束
1、概念:约束是作用于表中字段上的规则,用于限制在表中的数据
2、目的:保证数据库中数据的正确、有效性和完整性
3、分类:
| 约束 | 描述 | 关键字 |
| 非空约束 | 限制该字段的数据不能为null | not null |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | default |
| 检查约束 | 保证字段值满足某一个条件 | check |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | foreign key |
*约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束
外键约束:外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性
语法:添加外键
方法1:
create table 表名(
字段名 数据类型
...
[constraint] [外键名称]foreign key(外键字段名) refrences 主表(主表列名)
);
方法2:
| alter table 表名 add constraint 外键名称 foreign key(外键字段名)references主表(主表列名); |
删除外键:alter table 表名 drop foreing key外键名称;
*删除/更新行为
| 行为 | 说明 |
| no action | 当在父表中删除/更新对应的记录时,首先该记录是否有对应外键,如果有则不允许删除/更新(与restrict一致) |
| restrict | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新(与no action一致) |
| cascade | 当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有,则也删除/更新外键在子表中的记录 |
| set null | 当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许去null) |
| set default | 父表有变更时,子表将外键列设置成一个默认的值(lnnodb不支持) |
alter table 表名add constraint外键名称foreign key(外键字段)references主表名(主表字段名)
on update cascade on delete cascade;
多表关系
*一对多(多对一)
eg:部门与员工关系(一个部门对应多个员工,一个员工对应一个部门)
实现:在多的一方建立外键,指向一的方面的主键
*多对多
eg:学生与课程关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
连接查询--内连接
隐式内连接
select字段列表 from表1,表2where 条件...;
显式内连接
select 字段列表 from 表1[ inner] join 表2on 连接条件...;
内连接查询的是两张表交集的部分
连接查询--外连接
左外连接
select 字段列表from 表1 left[ outer] join 表2 on 条件...;
相当于查询表1(左表)的所有数据包含表与表2交集部分的数据
右外连接
select 字段列表from 表1right[ outer] join 表2on条件...;
相当于查询表2(右表)的所有数据 包含 表1和表2交集部分的数据
连接查询--自连接
select 字段列表 from表A 别名A join 表A 别买B on 条件...;
自连接查询,可以是内连接查询,也可以是外连接查询
联合查询-union,union all(并集)
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
select 字段列表 from 表A...
union [all]
select字段列表from表B...;
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致
union all会将全部数据直接合并在一起,union会对合并之后的数据去重
子查询
概念:SQL语句在嵌套select语句,称为嵌套查询,又称子查询
select * from t1 where column 1=(select column1 from t2);
子查询外部的语句可以是insert/update/delete/select的任何一个
根据子查询结果不同分为:
标量子查询(子查询结果为单个值):子查询返回的结果是单个值(数字、字符串、日期等),最近的是形式。常用的操作符:= <> > >= < <=
列子查询(子查询结果为一列(可以是多行))
| 操作符 | 描述 |
| in | 在指定的集合范围之内,多选一 |
| not in | 不在指定的集合范围之内 |
| any | 子查询返回列表中,有一个任意满足即可 |
| some | 与any等同,使用some的地方都可以用any |
| all | 子查询返回列表的所有值都必须满足 |
行子查询(子查询结果为一行(可以是多列))
常用操作符:= <> in 、not in
表子查询(子查询结果为多行多列)
常用操作符:in
*根据子查询位置,分为:where之后、from之后、select之后
事务简介:是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么会同时成功
,要么会同时失败
默认mysql的事务是自动提交的,也就是是,当执行一条DML语句,MySQL会立即隐式的提交事务
-- 数据准备
create table account(
id int auto_increment primary key comment'主键ID',
name varchar(10) comment'姓名',
money int comment'余额'
)comment '账户表';
insert into account(id,name,money)values(null,'张三',2000),(null,'李四',2000);
-- 恢复数据
update account set money =2000 where name ='张三' or name ='李四';
-- 转账操作
--查询张三账户余额
select * from account where name ='张三';
-- 将张三账户余额-1000
update account set money =money - 1000 where name ='张三';
-- 将李四账户余额+1000
update account set money =money + 1000 where name ='李四';事务操作
查看/设置事务提交方式
select @@autocommit;
set @@autocommit=0;
提交事务
commit;
回滚事务
rollback;
开启事务
start transaction或begin;
提交事务
commit;
回滚事务
rollback;
事务的4大特性
| 原子性(Atomicity) | 事务是不可分割的最小操作单元,要么全部成功,要么全部失败 |
| 一致性(Consistency) | 事务完成时,必须使所有的数据都保持一致状态 |
| 隔离性(Isolation) | 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行 |
| 持久性(Durability) | 事务一旦提交或回滚,它对数据库中的数据的改变就是永久的并发事务问题 |
| 问题 | 描述 |
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了幻影 |

-- 查看事务隔离级别
select@@transaction_isolation;
-- 设置事务隔离级别
set[session|global]transaction isolation level{read uncommitted|read committed|repeatable read}
注意:事物隔离级别越高,数据越安全,但是性能越低