dmfldr工具学习笔记-达梦数据库
目录
一.概述... 2
二.dmfldr入门... 3
三.工具使用... 5
1.指定数据文件... 5
2.数据转换与错误数据文件... 7
3.服务器端错误数据处理... 8
4.大字段数据处理... 9
5.日志文件与日志信息... 11
6.自增列装载... 12
7.数据排序... 14
8.空值处理... 15
10.条件过滤... 18
11.多表装载... 19
12.个性化设置... 20
13. 主备切换时的数据继续载入... 21
14.MPP本地分发... 21
15.提升dmfldr性能... 21
16.dmfldr使用限制... 22
一.概述
1.功能简介
Dmfldr(DM FAST LOADER)是DM提供的快速数据装载命令行工具。能够快速将文件写入数据库,也可以快速将数据库的数据写入文件
2.系统结构

当进行数据载入时,dmfldr客户端接收用户提交的命令和参数,分析控制文件和数据文件,将数据文件发送给服务器,服务器去做真正的载入工作,之后分析服务器返回的信息,必要时根据用户指定的参数生成日志文件和错误文件。
当进行数据导出时,dmfldr客户端接收用户提交的命令和参数,分析控制文件,将相应信息发送给服务器,服务器进行信息解析,并在完成导出工作后,将导出的数据打包发送给客户端,客户端将数据写入指定的数据文件,并根据指定参数生成日志文件和错误文件。
二.dmfldr入门
1.启动dmfldr
在安装目录的bin目录下启动程序,格式如下:
dmfldr keyword=value [keyword=value ...]
例如:
dmfldr USERID=SYSDBA/SYSDBA CONTROL='c:\fldr.ctl'
如例子所示,USERID 和 CONTROL 是启动 dmfldr 必须要指定的参数,且 USERID 必 须是第一个参数,CONTROL 必须是第二个参数。
2.dmfldr参数
dmfldr help




3.dmfldr参数简介(参考DM8_dmfldr使用手册.pdf)
注:USERID必须是第一个参数,CONTROL必须是第二个参数,这两个参数都
不能省略;其余参数均为可选参数,可以不指定,指定时也无顺序要求
三.工具使用
1.指定数据文件
执行语句:
- 数据库中建表CREATE TABLE TEST(C1 INT,C2 INT,C3 DATE);

- 编辑数据文件 test.txt

- 编辑控制文件 test.ctl

- 使用 dmfldr 进行数据载入

- 数据库中查看

其中指定数据文件还可以用data参数的方式,这种方式需要在控制文件中写入INFILE ‘*’,而不是具体路径,具体路径在执行语句中写入,例如:
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@DM01:5236 control=\'/dm8/data/test.ctl\' data=\’/dm8/data/test.txt\’
2.数据转换与错误数据文件
dmfldr 使用的数据文件都是文本格式的,其中的列值都是以字符串的方式保存在数据 文件中。要想将这些数据载入数据库表中,需要将字符串转换成数据库表各列对应的数据类 型。dmfldr 支持所有 DM 数据库支持的列定义类型,包括字符串、数值、时间日期、时间 日期间隔、大字段类型等。
若数据文件的编码方式与 DM 数据库服务器的编码方式不一样,dmfldr 还需要进行字 符编码的转换。dmfldr 支持 UTF8、GBK 和 GB18030 编码之间的相互转换。
数据类型和编码转换工作由 dmfldr 客户端进行,在这个过程中如果出现错误, dmfldr 会跳过该行继续后面的工作,并记录错误行到 BADFILE 指定的文件。常见的出错 的情况有以下几种:
- 编码转换失败
- 目标列为字符串类型时,数据长度大于列定义长度
- 目标列为数值类型时,数据包含非法字符或者转换后超出该数值的范围
- 目标列为日期类型时,dmfldr 默认按 yyyy-mm-dd hh:mi:ss 的格式解析,如 果数据不是这样的格式,需要指定对应列的时间日期 fmt 格式而未指定
dmfldr 错误数据的文件路径由 BADFILE 参数设置,默认的错误文件名为 fldr.bad。 用户也可以通过设置控制文件中的 OPTIONS 选项来指定错误数据文件的路径,同时也可以 在控制文件的 LOAD 节点中指定错误数据文件的路径。错误数据文件路径最终值的优先选择 顺序为 LOAD 节点选项,OPTIONS 选项,参数选项。用户可以同时对三种设置方式中的一 个或多个设置,但最终的值只取一个。BADFILE 仅作用于 dmfldr 的工作 MODE 为 IN 的 情况下,MODE 为 OUT 时无效。
当数据类型和编码转换中存在错误数据,而错误数在允许的最大错误数范围内时, dmfldr 会将出错的数据记录到错误数据文件中。文件记录的信息为执行程序、时间、目标 表、数据文件中存在格式错误的行数据以及转换出错的行数据。
允许的最大容错个数由 ERRORS 选项设置,取值范围为[0,4294967295]之间的整数, 默认为 100。当 dmfldr 客户端在数据类型和编码转换过程中出现的错误个数超过了 ERRORS 所设置的数目,dmfldr 会停止载入,当前时间点的所有正确数据将会被提交到服 务器端。如果载入过程中不允许出现错误则可以将 ERRORS 设置为 0;如果允许所有的错 误出现,则可以将 ERRORS 设置为一个非常大的数。
实例:
- 建表
DROP TABLE TEST;
CREATE TABLE TEST(C1 INT,C2 INT,C3 DATE);
- 编辑数据文件
1 1|2015-11-06
2 2|2015-11-05
3 3|2015-11_04
44|aaaa-bbb-ccc
- 编辑控制文件
LOAD DATA
INFILE '/opt/data/test.txt'
INTO TABLE test
FIELDS '|'
(
C1 TERMINATED BY ' ',
C2,
C3 DATE FORMAT 'yyyy-mm-dd'
)
- 使用dmfldr进行数据载入
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' badfile=\'/dm8/data/test.bad\'

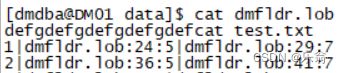
- 查看错误数据文件
cat /dm8/data/test.bad
![]()
3.服务器端错误数据处理
dmfldr 客户端将载入的数据进行数据转换和编码转换后,将转换正确的数据发往 DM 服务器的 dmfldr 模块,也就是 dmfldr 的服务器端,由其进行真正的数据载入工作。
dmfldr 客户端每次向服务器端发送一批数据,在服务器端插入数据的过程中,由于目 的表上可能存在约束等原因,导致某些数据无法插入成功,此时服务器端会将这一批数据全 部回滚,并将这批数据全部记为错误数据,但服务器端插入时的错误数据并不会记录到 BADFILE 中。
ERRORS 所统计的错误包含在数据转换和数据插入过程中所产生的数据错误,因此当服 务器端插入数据记录的错误数据数加上客户端数据转换时的错误数据数超过 ERRORS 参数 的指定值时,dmfldr 服务器会停止插入数据。
4.大字段数据处理
dmfldr 支持对 DM 数据库的大字段类型数据的载入和导出,DM 数据库支持的大字段 数据类型有 TEXT、LONGVARCHAR、IMAGE、LONGVARBINARY、BLOB 以及 CLOB。
- 大字段数据的导出
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 BLOB,C3 CLOB);
- 插入数据
INSERT INTO TEST VALUES(1,0XAB121032DE,'abcdefg');
INSERT INTO TEST VALUES(2,0XAB121032DE,'abcdefg');
COMMIT
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2, C3 )
- 使用dmfldr进行导出数据
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' LOB_DIRECTORY=\'/dm8/data/\' mode=\'out\'

这个导出看不太懂
- DIRECT 为 TRUE 时大字段数据的载入
当 MODE 为 IN 且 DIRECT 为 TRUE 时,此时数据载入若涉及到大字段对象,需要用户 指定大字段数据文件。若 CLIENT_LOB 为 TRUE,LOB_DIRECTORY 应指定大字段数据文 件所在的客户端本地目录,且此时待载入的大字段长度不得超过 2G,否则无法成功载入大 字段;若 CLIENT_LOB 为 FALSE,用户必须先把相关文件传送到 DM 服务器所在主库,然 后使用 LOB_DIRECTORY 指明存放目录。
大字段数据文件在数据文件中指定,可以是任意格式的文件。在数据文件中,大字段以 “文件名:起始偏移:长度”的形式记录在数据文件中。指定的文件名无效时,dmfldr 会 报错,装载失败。对于 CLOB 类型字段,当指定的偏移、长度范围内带有不完整字符时, dmfldr 将装载失败。
实例:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 BLOB,C3 CLOB);
- 编辑数据文件
1|testblob.txt:0:10|testclob.txt:0:10
2|testblob.txt:10:20|testclob.txt:10:20
3|testblob.txt:20:30|testclob.txt:20:30
其中,testblob.txt、testclob.txt 为文本文件,长度大于 30 字节,存放路径 为/dm8/data。
- 编辑控制文件
LOAD DATA INFILE '/opt/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2, C3 )
- 使用dmfldr进行导入数据
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' direct=false blob_type=\'hex_char\'
其中数据文件没有提供,自己输入的文件,提示数据错误。
如下图,求指导


- DIRECT 为 FALSE 时大字段数据的载入
当 MODE 为 IN 且 DIRECT 为 FALSE 时,数据文件中大字段列数据即字段内容。 BLOB_TYPE 参数指定 BLOB 列内容为十六进制或者字符串:
- BLOB_TYPE 为 HEX_CHAR 时,数据文件中 BLOB 列当作为十六进制内容;
- BLOB_TYPE 为 HEX 时,数据文件中 BLOB 列为字符串形式内容,导入后会转换 为十六进制.
BLOB_TYPE 参数只对 DIRECT 为 FALSE 时有效,默认为 HEX_CHAR。
实例:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 BLOB,C3 CLOB);
- 编辑数据文件
1|0x12d3c8a7|abcdefg
2|0x12a4cbac|hijlkmn
3|0x22d3c8b3|adefhjd
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2, C3 )
- 使用 dmfldr 进行导入数据,BLOB_TYPE 为 HEX_CHAR
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' direct=false blob_type=\'hex_char\'

- 查询表数据

步骤 a)、b)、c)同上
d.使用 dmfldr 进行导入数据,BLOB_TYPE 为 HEX
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' direct=false blob_type=\'hex\'
e.查询表数据

5.日志文件与日志信息
dmfldr 的日志文件路径由 LOG 参数设置,默认日志文件名为 fldr.log。文件记录 了装载过程中的装载信息和错误信息以及统计信息。用户也可以通过设置控制文件中的 OPTIONS 选项来指定日志路径。如果参数及 OPTION 中同时指定了日志路径则其将以 OPTION 中指定的路径为最终路径。
实例:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 INT,C3 DATE);
- 编辑数据文件
1|1 2018-11-06
2|2 2018-11-05
3|3 2018-11_04
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 TERMINATED BY ' ', C3 DATE FORMAT 'yyyy-mm-dd' )
- 使用 dmfldr 进行数据载入
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' log=\'/dm8/data/test.log\'
- 查看日志文件test.log
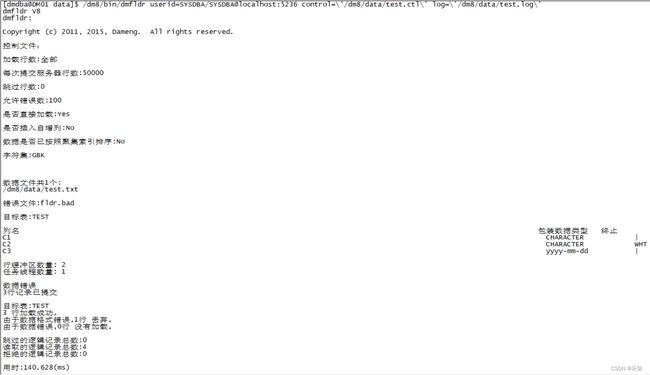
6.自增列装载
自增列是比较特殊的列,为了保证数据库中自增列列值的正确性,用户在进行数据载入 时需要特别注意。
当 DIRECT 参数为 FALSE 时,dmfldr 将把从数据文件中读取的自增列值作为目标值 插入数据库表中,用户应当保证每一行的自增列的值符合自增列的规则,否则将造成数据混 乱。
当 DIRECT 参数为 TRUE 时,dmfldr 提供了 SET_IDENTITY 参数(默认为 FALSE) 对数据载入时自增列的处理进行设置:
如果指定 SET_IDENTITY 选项值为 TRUE,则 dmfldr 将把从数据文件中读取的 自增列值作为目标值插入数据库表中,用户应当保证每一行的自增列的值符合自增 列的规则,否则将造成数据混乱;
如果 SET_IDENTITY 选项值设置为 FALSE,则 dmfldr 将忽略数据文件中对应 自增列的值,服务器将根据自增列定义和表中已有数据自动生成自增列的值插入每 一行的对应列。
实例1:
- 建表并插入数据
DROP TABLE TEST;
CREATE TABLE TEST(C1 INT IDENTITY(1,1),C2 VARCHAR); INSERT INTO TEST(C2) VALUES('AAA'); INSERT INTO TEST(C2) VALUES('BBB'); COMMIT;
此时表中数据为

- 编辑数据文件
2|aaa
3|bbb
4|ccc
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 )
- 使用dmfldr进行数据载入
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' direct=true set_identity=false
- 查看表数据

在这个例子中,表 TEST 中已有两行数据,由于 SET_IDENTITY 置为 FALSE,因此 在数据载入时 dmfldr 根据 C1 列的定义和表中已有数据,为 C1 列重新插入合适的值。
实例2:
重复实例1 的a、b、c 步骤
d.使用dmfldr进行数据载入
/dm8/bin/dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' direct=true set_identity=true
f.查看表数据
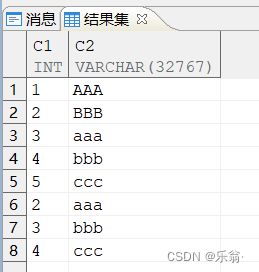
7.数据排序
SORTED 参数用来设置数据是否已经按照聚集索引排序,默认为 FALSE。
如果设置为 TRUE,则用户必须保证数据已按照聚集索引排序完成,并且如果表中存在 数据,需要插入的数据索引值要比表中数据的索引值大,服务器在做插入操作时顺序进行插 入。若数据并未按照索引排序,则 dmfldr 会报错,装载失败。
如果设置为 FALSE,则服务器对于每条记录进行定位插入。
用户也可以通过设置控制文件中的 OPTIONS 选项来设置 SORTED 的值。SORTED 参数值的优先选择顺序为 OPTIONS 选项,参数选项。此参数为可选参数,作用于 MODE 为 IN且DIRECT 为 TRUE 的情况下,对于其他情况此参数无效。
在数据量大,并且确定数据已按照聚集索引排序完成的情况下,将 SORTED 参数设置 为 TRUE,可以提升装载性能。
例如:
- 建表
DROP TABLE TEST;
CREATE TABLE TEST(C1 INT CLUSTER PRIMARY KEY,C2 VARCHAR);
- 编辑数据文件
2|aaa
3|bbb
4|ccc
5|ddd
1|zzz
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 )
- 使用dmfldr进行数据载入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' sorted=true

上图为sorted为true时执行图;
数据若无序,会报错(不能使用 NOSORT 选项,数据非有序)

上图为sorted为false时执行图
8.空值处理
dmfldr 通过设置 NULL_MODE 参数来处理空值。
设置为 TRUE,载入时 NULL 字符串处理为 NULL,载出时空值处理为 NULL 字符串;
设置为 FALSE,载入时 NULL 字符串处理为字符串,载出时空值处理为空串
例如:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 VARCHAR);
- 编辑数据文件
1|aaa
2|NULL
3|null
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 )
- 使用dmfldr进行数据载入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' null_mode=true

上图为执行过一次true,一次false后的表中数据
首先执行true,前三行表示对控制进行了处理,后三行为false的执行结果,表示未进行处理,原样载入了
9.类类型装载
dmfldr 支持对 CLASS 类型数据的装载。CLASS 类型装载和 LOB 类型一样,载入时 需要指定 LOB_DIRECTORY,另外需要指定 ENABLE_CLASS_TYPE 为 TRUE;导出时,默 认导出目录和数据文件所在目录一致,导出类类型形成的大字段文件默认为 dmfldr.lob, 导出目录和大字段文件可通过 LOB_DIRECTORY 和 LOB_FILE_NAME 参数设置。
CLASS 类型大字段数据文件无法通过手动创建,只有从表中导出到大字段文 件中,并使用数据文件 CLASS 字段对应的偏移、字长进行导入。
例如:
- 建表
数据准备,创建类 mycls 的类头与类体,之后创建表 TEST,其 C2 列类型为 mycls 类类型,并向 TEST 中插入两行数据。
--类头创建
CREATE CLASS mycls
AS
TYPE rec_type IS RECORD (c1 INT, c2 INT); --类型声明
id INT; --成员变量
r rec_type; --成员变量
FUNCTION f1(a INT, b INT) RETURN rec_type; --成员函数
FUNCTION mycls(id INT , r_c1 INT, r_c2 INT) RETURN mycls;--用户自定义构造函数
END;
/
--类体创建
CREATE OR REPLACE CLASS BODY mycls
AS
FUNCTION f1(a INT, b INT) RETURN rec_type
AS
BEGIN
r.c1 = a;
r.c2 = b;
RETURN r;
END;
FUNCTION mycls(id INT, r_c1 INT, r_c2 INT) RETURN mycls
AS
BEGIN
this.id = id; --可以使用 this.来访问自身的成员
r.c1 = r_c1; --this 也可以省略
r.c2 = r_c2;
RETURN this; --使用 return this 返回本对象
END;
END;
/
--建表 TEST
DROP TABLE TEST;
CREATE TABLE TEST(C1 INT,C2 mycls);
--插入数据:
INSERT INTO TEST VALUES(1,mycls(1,1,1));
INSERT INTO TEST VALUES(2,mycls(2,2,2));
COMMIT;
注:此处定义类,不是很了解
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 )
- 使用dmfldr进行数据导出
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' mode=\'out\' lob_directory=\'/dm8/data\'
- 在指定的 LOB_DIRECTORY 目录会生成大字段文件 dmfldr.lob,在指定的数据 文件路径生成的数据文件内容如下:
![]()
- 创建一张新表 TEST2,表的两列都为 mycls 类类型
CREATE TABLE TEST2(C1 MYCLS,C2 MYCLS);
- 编辑数据文件test2.txt
dmfldr.lob:70:70|dmfldr.lob:0:70
dmfldr.lob:0:70|dmfldr.lob:70:70
- 编辑控制文件test2.ctl
LOAD DATA INFILE '/dm8/data/test2.txt' INTO TABLE test2 FIELDS '|' ( C1, C2 )
- 使用 dmfldr 进行数据导入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test2.ctl\' lob_directory=\'/dm8/data/\' enable_class_type=true
- 查看表 TEST2 的数据

10.条件过滤
通过在控制文件中指定 WHEN 子句,可以在装载过程中对数 据进行过滤,符合 field_conditions 条件的数据才会被装载。
对于条件过滤的使用需注意以下几点:
- 判断条件中的操作符仅支持比较相等和不相等,即=、!=和<>这三个比较操作符;
- 目前仅支持使用 AND 连接多个过滤条件;
- BLANKS 和 WHITESPACE 表示若干个空格;
- 判断条件若使用(p1:p2)作为比较表达式,其意义与在 POSTION 子句中的意义相 同,表示从该行指定位置获取数据进行比较,起始位置和结束位置表示的都是字节 位置,包含边界 p1,p2;
- 如果判断条件中使用 colid 作为比较表达式,该列必须在 INTO 表的 coldef_option 中进行说明;
- 如果判断条件中使用 colid 作为比较表达式,判断条件中使用的列仅用于过滤, 并没有对应表中的某个实际列,应在 col_def 中指明 FILLER 属性表示装载时跳 过该列;
- 如果判断条件中比较数据是字符常量值,其长度小于比较表达式长度,则在其之后 补充空格;如果判断条件中比较数据是二进制串常量,其长度小于比较表达式长度, 则在之后补充 0。
例如:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 INT);
- 编辑数据文件
12
23
32
48
91
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test WHEN C1 != '2' ( C1 position (1:1), C2 position (2:2) )
- 使用dmfldr进行数据载入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\'

可以看到数据文件中的行 2,3 被过滤掉了。
11.多表装载
通过在控制文件中指定多个 INTO TABLE 子句,可以将一批数据同时向多个表进行装 载。每个 INTO TABLE 子句中都可以指定 WHEN 过滤条件、FIELDS 子句和列定义子句。
对于多表装载的使用需注意以下几点:
- 对于第二个及其之后的 INTO TABLE 子句,在其 coldef_option 中,必须为所 有列指定 POSITION 选项;
- 在 INTO TABLE 子句的目标表中,如果目标表各不相同,则一个批次就可以完成 装载(不管含有多少表,只需扫描一次数据文件即可);如果含有重复的目标 表,则相同的表需要分批次导入(每当遇到相同的表时,就需要再扫描一遍源文件。 N 个重复的表,就需要扫描 N 次源文件)。
例如:
- 建表TEST1,TEST2
DROP TABLE TEST1;
DROP TABLE TEST2;
CREATE TABLE TEST1(C1 INT,C2 INT);
CREATE TABLE TEST2(C1 INT,C2 INT);
- 编辑数据文件
1,2
2,3
3,2
4,8
9,1
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test1 WHEN C1 != '1' FIELDS ',' ( c1 position (1:1), c2 position (3:3) ) INTO TABLE test2 WHEN (3:3) = '2' AND c1 != '3' FIELDS ',' ( c1 position (1:1), c2 position (3:3) )
- 使用dmfldr进行数据载入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\'

12.个性化设置
用户通过设置 dmfldr 的 SKIP、LOAD、ROWS 参数,可以根据自己的需求调整装载的 起始行、装载最大行数以及每次提交的行数。
SKIP 参数用来设置跳过数据文件起始的逻辑行数,整形数值。默认的跳过起始行数为 0 行。如果用户指定了多个文件,且起始文件中的行数不足 SKIP 所指定的行数,则 dmfldr 工具会扫描下一个文件直至累加的行数等于 SKIP 所设置的行数或者所有文件都已 扫描结束。
LOAD参数用来设置装载的最大行数,整形数值。默认的最大装载行数为数据文件中的所有行数。LOAD 指定的值不包括 SKIP 指定的跳过的行数。
ROWS 参数用来设置每次提交的行数,整形数值。默认的提交行数为 50000 行。提交 行数的值表示提交到服务器的行数,并不一定代表按照数据文件中的数据顺序的行数。用户 可以根据实际情况调整每次提交的行数,以达到性能的最佳点。ROWS 参数作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
例如:
- 建表
DROP TABLE TEST; CREATE TABLE TEST(C1 INT,C2 VARCHAR);
- 编辑数据文件
1|aaa
2|bbb
3|ccc
4|ddd
5|eee
6|fff
7|ggg
8|hhh
9|iii
10|jjj
- 编辑控制文件
LOAD DATA INFILE '/dm8/data/test.txt' INTO TABLE test FIELDS '|' ( C1, C2 )
- 使用dmfldr进行数据载入
./dmfldr userid=SYSDBA/SYSDBA@localhost:5236 control=\'/dm8/data/test.ctl\' skip=3 load=5

13. 主备切换时的数据继续载入
在 DM 数据守护主备环境下,如果 dmfldr 数据载入中发生主备切换,dmfldr 支持主 备切换完成后自动继续装载数据,并且能保持数据正确。
要使用此项功能,USERID 参数需要使用主备服务名方式进行配置,如:
dmfldr USERID=SYSDBA/SYSDBA@DM01 CONTROL='c:\fldr.ctl'
同时在 dm_svc.conf 配置文件中配置主备服务名,如:
DM=(192.168.0.101:5236, 192.168.0.102:5236)
目前主备切换时的数据继续载入功能还存在以下功能限制:
- 目前仅支持单机的主备,不支持 MPP 主备。
但是,若在 MPP 主备环境中使用 MPP_CLIENT=FALSE,等同于单机,也是支持的。
- 目前不支持分区表装载
14.MPP本地分发
MPP_CLIENT 参数用来设置在 DM MPP 环境下使用 dmfldr 进行数据装载时的数据分 发方式。
当 DM 数据库服务器环境为单站点时此参数无效。当服务器环境为 MPP 环境时,若 MPP_CLIENT 为 TRUE,dmfldr 采用客户端分发模式;若 MPP_CLIENT 为 FALSE,则采 用本地分发模式。
客户端分发模式下,数据在 dmfldr 客户端分发好后直接往指定站点发送数据。
本地分发模式下,导入时,dmfldr 直接将数据发送到连接的站点,数据最终在连接的 站点;导出时,dmfldr 只导出连接站点的数据。
MPP 环境下要配置 dmmal.ini 文件中的 MAL_INST_HOST 和 MAL_INST_PORT 参数。
15.提升dmfldr性能
用户在使用 dmfldr 时根据系统和数据的具体情况对一些参数进行调整,可以获得更 好的性能,这些参数包括:
BUFFER_NODE_SIZE 设置读取文件缓冲区页大小,值越大,缓冲区的页越大,每次读 取的数据就越多,每次发送到服务器的数据也就越多,效率越高。但其大小受 dmfldr 客 户端内存大小限制。
在某些情况下,BUFFER_NODE_SIZE 读入的数据行数很大,而后续操作处理不了这么 大的行数,此时可以用 READ_ROWS 来限制处理的行数。dmfldr 取 READ_ROWS 和 BUFFER_NODE_SIZE 中较小的值作为一次处理的行数。
指定 dmfldr 在数据载入时发送节点的个数,默认由系统计算一个初始值。若在数据 载入时发现发送节点不够用,系统会动态增加分配。在系统内存足够的情况下,可以适当设大 SEND_NODE_NUMBER 值,提升 dmfldr 载入性能。
指定 dmfldr 在数据载入时处理用户数据的线程数目。默认情况下,dmfldr 将该参 数值设为系统 CPU 的个数,但当 CPU 个数大于 8 时,默认值都被置为 8。在 dmfldr 客户 端所在机器 CPU 大于 8 环境中,提高 TASK_THREAD_NUMBER 值可以提升 dmfldr 装载 性能。
水平分区表装载时,指定服务器 BLDR 的最大个数,默认为 64。 服务器的 BLDR 保存水平分区子表相关信息,BLDR_NUM 的设置也就指定了服务器能 同时载入的水平分区子表的个数。若 BLDR_NUM 设置太大,当水平分区子表数过多时,可能会导致服务器内存不足。当载入时实际需要的 BLDR 个数超出 BLDR_NUM 设置时,会淘 汰指定子表的 BLDR,并替换为新的子表 BLDR。
BDTA(Batch Data)的大小,默认为 5000。 BDTA 代表 DM 数据库批量数据处理机制中一个批量,在内存、CPU 允许的条件下,增 大 BDTA_SIZE 能加快装载速度;在网络是装载性能瓶颈时,增大 BDTA_SIZE 影响不大。
索引的设置选项,默认为 1。INDEX_OPTION 的可选项有 1、2 和 3。 1 代表服务器装载数据时先不刷新二级索引,而是将新数据按照索引预先排序,在装载完成后,再将排好序的数据插入索引。如果在数据载入前,目标表中已有较多数据,建议 INDEX_OPTION 置为 1。 2 代表服务器在快速装载过程中不刷新二级索引数据,只在装载完成时重建所有二级索 引。如果在数据载入前,目标表中没有数据或数据量较小,建议 INDEX_OPTION 置为 2。 3 代表服务器使用追加模式来进行二级索引的插入, 在数据装载的过程中, 同时进行 二级索引的插入, 当原有数据量远大于插入数据量时, 建议 INDEX_OPTION 置为 3。
16.dmfldr使用限制
dmfldr 的使用存在以下一些限制:
- 不支持向临时表、外部表装载数据
- 不支持向系统表装载数据
- 不支持向带有位图索引的表装载数据
- 不支持向带有函数索引的表装载数据
- 不支持向带有全文索引的表装载数据
- 不支持向 DCP 代理装载数据
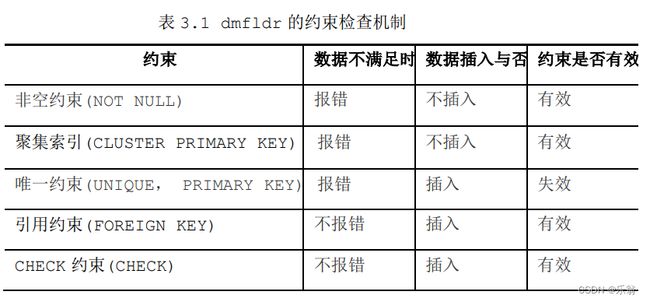
- dmfldr 装载时,对约束进行检查,对各种约束的处理机制如下表所示
点击下方链接,可进入达梦技术交流社区
达梦数据库 - 新一代大型通用关系型数据库 | 达梦云适配中心