决策树,信息熵,信息增益计算----机器学习
决策树(decision tree)
- 决策树简单介绍
- 信息量
- 信息熵
- 信息增益
决策树简单介绍
决策树是一种基于树状结构来做决策的。是一种常见的机器学习方法。主要做分类,也可以做回归。一棵决策树含有一个根结点(样本全集),若干个内部结点和若干个叶结点(最终结论)。
简单的一个例子。比如我们相亲的时候,老母亲甩出来一沓照片来让你做选择。这时候我们会问一些问题来做一下筛选,比如对方的年龄,相貌,工作收入,家庭住址等等等,然后最终确定选择两个或三个人去见。
这一系列问题和层层的筛选判断就是在做决策,这些问题为“子决策”。其中那一沓照片是根结点(样本全集),年龄要小于三十的,家要离得近的等判定是内部结点,最终选出来符合所有要求的人就是叶结点。
看图理解,左边是问题描述,右边是该事件的决策树。其中绿色的为内部节点,橙色的为叶结点。
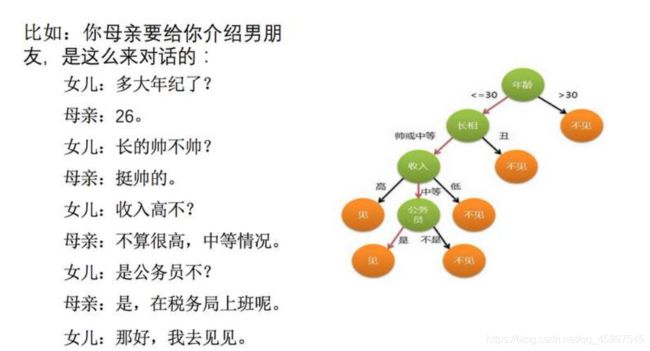
决策树学习目的是要产生一棵泛化能力强的树,通俗地说就是要学习出来一棵决策树,这个树可以很强的处理陌生的示例
在决策树中,每个内部结点的判定问题都是基于上一层的决策结果。比如长相这个结点在做决策时,是基于年龄小于30的人做出的决策;收入这个结点做决策时是基于长相在中等或者帅气时做出的决策。
决策分类的停止条件有三个,当这三个条件其一出现时,决策分类停止。
1.这个结点中的样本都是同一类别,这时就不用再往下一层进行划分了。
比如:相亲照片中所有人的年龄都小于30,就不用再分了。又或者所有的人长的都帅,那这一层也就不用再划分帅或者丑了。
2.这个结点的属性集为空,或者所有样本在所有属性上取值相同,没办法划分。
比如:相亲照片中,所有人的收入都一样,都是一个月100万。那么这个样本中所有人在收入这个属性上的取值就是相同的,没办法划分高低。
这个时候我们就把当前结点,即【收入】这个结点标记为叶结点,并把其类别设定为所含样本最多的类别。反正收入都一样,没办法划分高低那就都见见面。
3.这个结点包含的样本集为空,不能进行划分。
比如:给了一沓照片,知道都是男的,但是每张照片上的脸都被扣掉了,媒人也不说对方各方面条件。那还见个毛线。决策树就终止在"男"这个结点上,当然假设女主如饥似渴,那么此决策树的叶结点就是“见”。
信息量
信息量是求取信息熵的要点,信息熵是求取信息增益的基础,信息增益是来判断哪个样本集合纯度最高的,信息增益最大的属性被选为划分属性。
决策树学习的关键就是如何选择最优属性划分
那信息量是什么东西?顾名思义,它其实就是一个事件所能提供的信息多少。(信息量用 I I I来表示)
比如有人告诉我,太阳是东升西落的,那么这句话的信息量几乎为0,人人都知道的一个自然规律,说出来价值不大,且这个事件发生概率为1。但是如果有人告诉我说,国足踢进了世界杯。这是个几乎不可能的小概率事件,那么这句话的信息量就很大了。我会关注是哪天,哪场,哪个人
从上面的例子就不难得出一个结论:一个事件的信息量( I I I)与该事件所发生的概率( P P P)呈负相关。这是信息量的第一个特点。
信息量的第二个特点是:若两个互不相关的事件X,Y的发生没有相互影响的关系,那么 I ( X , Y ) = I ( X ) + I ( Y ) I(X,Y)=I(X)+I(Y) I(X,Y)=I(X)+I(Y)。也是概率论的一个知识点。
能够同时满足这两个特点的函数必然是一个单调递减函数。这个函数刚好满足: I = − l o g ( P ( x ) ) I=-log(P(x)) I=−log(P(x))。把负号去掉就是我们熟悉的对数函数,不过不加负号的图像是一个单调递增的正相关函数, 要变成负相关,加个负号就正好满足。
信息熵
信息熵用Ent来表示。信息熵可以理解为平均信息量,就是信息量的期望值。信息是个很抽象的概念,我们平时说信息多,信息少,但是不知道信息到底是有多少,比如我说一句话,这句话中到底有多少信息量。信息熵从另一方面理解也可以说是对信息的一种量化。
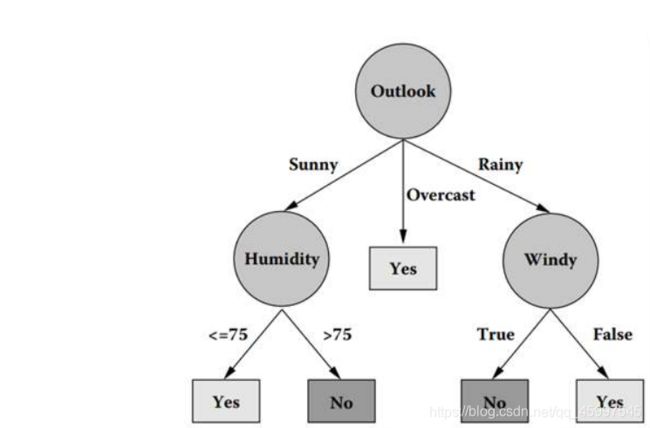
信息熵是度量样本集合纯度时最常用的一种指标。关于纯度的概念,可以理解为当前样本集合中的某类别占比最大时最好是不用进行分类时,它就越纯。看个图帮助理解。
这个图是一个根据天气判断要不要去打球的决策树。看看,overcast阴天的时候,也不下雨,没有大太阳,还有点儿小凉风,打球最爽,果断去。其他的就是分晴天的空气湿度啊,雨天的风力如何等等等。这里面的overcast就是这棵决策树中最纯的一个集合。
我们假设一个样本集合D中第 k k k类样本所占比例为 p ( k ) p(k) p(k)(k=1,2,3… ∣ y ∣ \lvert y \rvert ∣y∣),则D的信息熵可定义为:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ ( p k ∗ l o g 2 p k ) Ent(D)=-\sum\limits_{k=1}^{\lvert y \rvert}(p_{k}*log_{2}p_{k}) Ent(D)=−k=1∑∣y∣(pk∗log2pk)
此为信息熵的计算公式,信息熵越小,数据就越纯。
看个信息熵的计算例子:左右两个集合,左边集合中有两类,右边集合就一类,这样看是右边的集合纯度最纯。那来计算一下信息熵,看看是不是数据越纯的信息熵就越小。

根据信息熵计算公式先来计算左边的信息熵:一共两类,叉叉和圈圈各占一半,则他们的概率都一样: p ( k ) = 1 2 p(k)=\dfrac{1}{2} p(k)=21
带入公式中:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ ( p k ∗ l o g 2 p k ) Ent(D)=-\sum\limits_{k=1}^{\lvert y \rvert}(p_{k}*log_{2}p_{k}) Ent(D)=−k=1∑∣y∣(pk∗log2pk)
= − ( 1 2 ∗ l o g 2 1 2 ) − ( 1 2 ∗ l o g 2 1 2 ) =-(\dfrac{1}{2}*log_{2}\dfrac{1}{2})-(\dfrac{1}{2}*log_{2}\dfrac{1}{2}) =−(21∗log221)−(21∗log221)
= 1 =1 =1
右边的信息熵,共一个类别,叉叉占比 p ( k ) = 1 p(k)=1 p(k)=1,代入公式:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ ( p k ∗ l o g 2 p k ) Ent(D)=-\sum\limits_{k=1}^{\lvert y \rvert}(p_{k}*log_{2}p_{k}) Ent(D)=−k=1∑∣y∣(pk∗log2pk)
= − ( 1 ∗ l o g 2 1 ) =-(1*log_{2}1) =−(1∗log21)
= 0 =0 =0
可以得到,信息熵越小,数据就越纯。信息熵的最小值为0,最大值为 l o g 2 ∣ y ∣ log_{2}\lvert y \rvert log2∣y∣
信息增益
一般来说,一个属性的信息增益越大,就意味着使用该属性来进行划分所得到的“纯度提升”越大。因此,我们可以使用信息增益来进行决策树的第一个结点划分属性选择。(选出决策树的第一个顶头划分的属性,再继续往下划分)
信息熵越小,数据就越纯,信息增益就越大。
假定一个数据集D,其中一个属性a有V个可能的取值{ a 1 , a 2 . . . a V a^{1},a^{2}...a^{V} a1,a2...aV},如果选定a为划分属性,那么会产生V个分支结点,其中第 v v v个分支结点包含了D中所有在属性a上取值为 a v a^{v} av的样本,记为 D v D^{v} Dv。
直接通过一个实例的计算过程来理解信息增益的算法。
信息增益的计算公式:
G a i n ( D , a ) = E n t ( D ) − ∑ k = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum\limits_{k=1}^{V}\dfrac{\lvert D^{v} \rvert}{\lvert D \rvert}Ent(D^{v}) Gain(D,a)=Ent(D)−k=1∑V∣D∣∣Dv∣Ent(Dv)
计算下图西瓜数据集中各个属性的信息增益,选取值最大的一个属性作为划分属性。
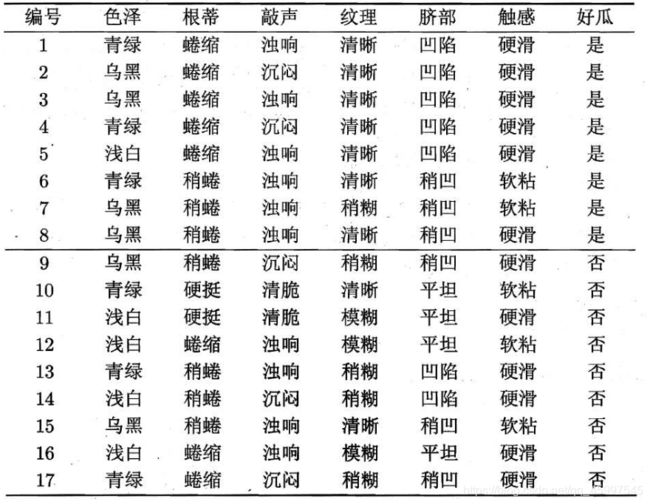
以色泽为例:
共17个数据。首先色泽一栏,它有三个可能的(V)取值:青绿( D 1 D^{1} D1),乌黑( D 2 D^{2} D2),浅白( D 3 D^{3} D3)。
青绿有6个,占总样本的比 6 17 \dfrac{6}{17} 176,其中好瓜有3个,占比 1 2 \dfrac{1}{2} 21,坏瓜有3个,占比也是 1 2 \dfrac{1}{2} 21。
乌黑有6个,占总比 6 17 \dfrac{6}{17} 176,其中好瓜有4个,占比 2 3 \dfrac{2}{3} 32,坏瓜有2个,占比也是 1 3 \dfrac{1}{3} 31。
浅白有5个,占总比 5 17 \dfrac{5}{17} 175,其中好瓜有1个,占比 1 5 \dfrac{1}{5} 51,坏瓜有4个,占比也是 4 5 \dfrac{4}{5} 54。
如下结构图清晰明了:
总的信息熵计算,可以看到共两大类:是好瓜,是坏瓜。所以 ∣ y ∣ = 2 \lvert y \rvert=2 ∣y∣=2,其中好瓜有8个,坏瓜有9个。占比分别为 8 17 , 9 17 \dfrac{8}{17},\dfrac{9}{17} 178,179
E n t ( D ) = − ( 8 17 ∗ l o g 2 8 17 ) − ( 9 17 ∗ l o g 2 9 17 ) = 0.998 Ent(D)=-(\dfrac{8}{17}*log_{2}\dfrac{8}{17})-(\dfrac{9}{17}*log_{2}\dfrac{9}{17})=0.998 Ent(D)=−(178∗log2178)−(179∗log2179)=0.998
而 D 1 , D 2 , D 3 D^{1},D^{2},D^{3} D1,D2,D3这三个分支结点的信息熵如下:
E n t ( D 1 ) = − ( 1 2 ∗ l o g 2 1 2 ) − ( 1 2 ∗ l o g 2 1 2 ) = 1.000 Ent(D^{1})=-(\dfrac{1}{2}*log_{2}\dfrac{1}{2})-(\dfrac{1}{2}*log_{2}\dfrac{1}{2})=1.000 Ent(D1)=−(21∗log221)−(21∗log221)=1.000
E n t ( D 2 ) = − ( 2 3 ∗ l o g 2 2 3 ) − ( 1 3 ∗ l o g 2 1 3 ) = 0.918 Ent(D^{2})=-(\dfrac{2}{3}*log_{2}\dfrac{2}{3})-(\dfrac{1}{3}*log_{2}\dfrac{1}{3})=0.918 Ent(D2)=−(32∗log232)−(31∗log231)=0.918
E n t ( D 3 ) = − ( 1 5 ∗ l o g 2 1 5 ) − ( 4 5 ∗ l o g 2 4 5 ) = 0.722 Ent(D^{3})=-(\dfrac{1}{5}*log_{2}\dfrac{1}{5})-(\dfrac{4}{5}*log_{2}\dfrac{4}{5})=0.722 Ent(D3)=−(51∗log251)−(54∗log254)=0.722
所以,色泽的信息增益为:
G a i n ( D , a ) = E n t ( D ) − ∑ k = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum\limits_{k=1}^{V}\dfrac{\lvert D^{v} \rvert}{\lvert D \rvert}Ent(D^{v}) Gain(D,a)=Ent(D)−k=1∑V∣D∣∣Dv∣Ent(Dv)
= 0.998 − ( 6 17 ∗ 1 + 6 17 ∗ 0.918 + 5 17 ∗ 0.722 ) =0.998-(\dfrac{6}{17}*1+\dfrac{6}{17}*0.918+\dfrac{5}{17}*0.722) =0.998−(176∗1+176∗0.918+175∗0.722)
= 0.109 =0.109 =0.109
其他属性的计算过程都是一样的,此处不一 一展示。最终得到的各个属性信息增益值是:
G a i n ( D , 色 泽 ) = 0.109 Gain(D,色泽)=0.109 Gain(D,色泽)=0.109
G a i n ( D , 根 蒂 ) = 0.143 Gain(D,根蒂)=0.143 Gain(D,根蒂)=0.143
G a i n ( D , 敲 声 ) = 0.141 Gain(D,敲声)=0.141 Gain(D,敲声)=0.141
G a i n ( D , 纹 理 ) = 0.381 Gain(D,纹理)=0.381 Gain(D,纹理)=0.381
G a i n ( D , 脐 部 ) = 0.289 Gain(D,脐部)=0.289 Gain(D,脐部)=0.289
G a i n ( D , 触 感 ) = 0.006 Gain(D,触感)=0.006 Gain(D,触感)=0.006
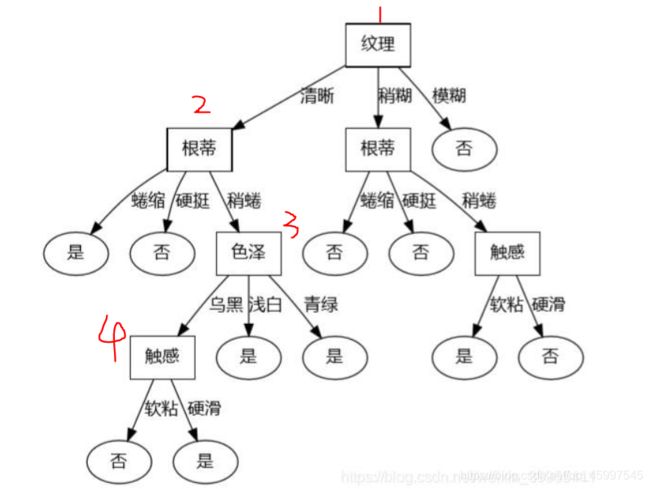
对比得出【纹理】的信息增益最大,所以它被选为划分属性。
基于纹理属性对根结点划分如下图:

然后,对每个分支结点再做进一步划分。
比如上图中的【清晰】这个分支结点,该结点包含9个样例集合( D 1 D^{1} D1),把这些样例根据编号投选出来,然后根据{色泽,根蒂,敲声,脐部,触感}这些属性再算出各属性的信息增益。选出最大的作为【清晰】下面的一个划分属性。以此类推,最终得到如下决策树:
结束,完美撒花~