python自动化测试学习笔记合集
python自动化测试学习笔记-1
一、什么是自动化
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。直白的就是为了节省人力、时间或硬件资源,提高测试效率,便引入了通过软件或程序自动化执行测试用例进行测试;
二、python简介
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
我们先来看一各种编程语言的类型。
机器语言:是指一台计算机全部的指令集合,计算机所使用的是由"0"和"1"组成的二进制数,二进制是计算 计算机语言机的语言的基础。
编译型语言:将源代码编译生成机器语言,再由机器运行机器码(二进制)。例如:c c++ c#
解释型语言:相对于编译型语言存在的,源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。
代码在运行的时候才进行编译,如 java 、JavaScript、Perl 、Shell、PHP、ruby、python
脚本语言:一个脚本通常是 解释执行而非编译。一开始的时候这种语言只有单一的功能,如shell用户编写linux的脚本,js用于制作网页特效
python的应用:数据挖掘(爬虫)、数据分析、自动化运维、自动化测试、后台服务器接口开发、AI、人工智能、嵌入式开发、web开发等。
python的特点:
1编写的代码质量高:采用缩进的方法,让代码的可读性更好,也很适合团队协作开发。
2提高开发的效率:简单的语法,动态的类型,不过不要认为python仅可以完成简单的任务,其实他只是让复杂的编程任务变的高效和有趣,曾经我一个搞JAVA的朋友,他完成一个任务要写几百行代码,而我只写了10几行代码,的确python这们语言是想把程序员解放出来,腾出一些时间去享受生活。
3程序的可移植性:你编写的代码可以放到几个平台上去运行,比如windows,linux,unix。
4很多标准库和第3方库:等你了解python标准库的时候,你就会觉的它的标准库太多了,而且功能和强大,从字符处理到网络处理无所不能。
5编程思想是大道至简:python希望程序员能够用最简单的方法来解决问题,化繁为简。
好了下面开始我们的python学习之旅~
三、python基础
基本概念
字符集:是一个系统支持的所有抽象字符的集合,计算机中储存的信息都是用二进制数表示的。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
常用的字符集合字符编码
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
有时我们看到页面上的乱码,可能就是字符集不一致导致的。
变量(variable)变量就是代表某个数据(值)的名称。python是一种动态类型语言,在赋值的执行中可以绑定不同类型的值,这个过程叫做变量赋值操作,赋值同时确定了变量类型。
静态类型语言是指在编译时变量的数据类型即可确定的语言,多数静态类型语言要求在使用变量之前必须声明数据类型,某些具有类型推导能力的现代语言可能能够部分减轻这个要求.
动态类型语言是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
python中变量的定义
1、变量名可以包括字母、数字、下划线,但是数字不能做为开头。例如:name1是合法变量名,而1name就不可以。
2、系统关键字不能做变量名使用
3、除了下划线之个,其它符号不能做为变量名使用
4、Python的变量名是区分大小写的,例如:name和Name就是两个变量名,而非相同变量哦。
5、中文也能定义变量名,单实际当中不这样运用
python的数据类型
1)整型——int——数字
python有5种数字类型,最常见的就是整型int,例如:a = 123 或 b = -123 等号左边是变量名,右边是要赋的值
2)布尔型——bool——用符号==表示
布尔型是一种比较特殊的python数字类型,它只有True和False两种值,它主要用来比较和判断,所得结果叫做布尔值。例如:3==3 给出True,3==5给出False
3)字符串——str——用' '或" "表示
例如:URL='www.iplaypy.com'或者name="lijing"
4)列表——list——用[ ]符号表示
例如:num=[1,2,3,4]
5)元组——tuple——用( )符号表示
例如:('d',300)
6)字典——dict——用{ }符号表示
例如:{'name':'coco','country':'china'}
实战演练
安装python,安装pycharm编码软件进行编码。
1、hello world!
python中输出函数print函数,字符串和数值类型的可以直接输出,如下
print('hello world')
print(1)
输出内容:

输出字符串内容可以用‘’,也可以用“”,当输出的字符串中包含‘’时,则字符串用“”;当输出的字符串中包含“”号时,则字符串用‘’;当输出的字符串中‘’和“”都包含时,则字符串用‘’‘ ‘’’来输出;如下
print("你真的很'帅'!")
print('你真的很"帅"!')
print(''''哇!'你真的很"帅"!''')
输出内容:

输出变量类型
x='hello world!' print(x) s=13 print(s) l=[1,2,3,'p'] print(l)
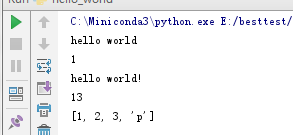
格式化输出
输出的内容中包含定义的参数时,
name=input('请输入你的姓名:')
time='2017年12月19日'
print('%s欢迎光临!'%name)
输出内容
![]()
%字符:标记转换说明符的开始 ,s表示格式转换类型为字符串,f表示十进制浮点数,d表示带符号的十进制整数
当有两个输出参数的使用,在%(参数1,参数2)列出需要传参的参数名
name=input('请输入你的姓名:')
time='2017年12月19日'
print('%s欢迎光临!'%name)
print('%s欢迎光临!时间是:%s'%(name,time))
输出内容:

+的形式进行字符串拼接:
name=input('请输入你的姓名:')
time='2017年12月19日'
print('%s欢迎光临!'%name)
print(name+'欢迎光临!')
输出内容:

可以看到字符串拼接 + 的输出内容与%形式的转换是一样的;
还有一种方式更加简便快捷常用,{}的形式进行传参
name=input('请输入你的姓名:')
time='2017年12月19日'
print('%s欢迎光临!'%name)
print('%s欢迎光临!时间是:%s'%(name,time))
print(name+'欢迎光临!')
print('{}欢迎光临!时间是:{}'.format(name,time))
输出内容:
请输入你的姓名:pei
pei欢迎光临!
pei欢迎光临!时间是:2017年12月19日
pei欢迎光临!
pei欢迎光临!时间是:2017年12月19日
当参数较多时,可能会记忆混乱出现传参错误的情况,此时我们可重新定义一下传参的内容:如下实现方法
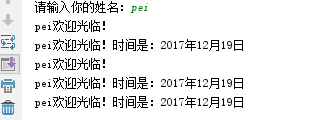
name=input('请输入你的姓名:')
time='2017年12月19日'
print('%s欢迎光临!'%name)
print('%s欢迎光临!时间是:%s'%(name,time))
print(name+'欢迎光临!')
print('{}欢迎光临!时间是:{}'.format(name,time))
print('{username}欢迎光临!时间是:{localtime}'.format(username=name,localtime=time))
输出内容:
2、条件判断基本使用方法
语法:
if 条件表达式:
语句块
例子:
如果成绩达到80分或以上,视为优秀。
成绩达到60分到80分(不包括80分),视为及格。
成绩60分以下,视为不及格。
我们输入一个分数,用if语句判断是否能打印出分数所属阶段:
score =input('请输入分数:')
if score >= 80:
print('优秀')
elif score >=60 and score<80:
print('及格')
else:
print('不及格!')
执行上面的语句,输入分数为89,看执行结果

上述结果我们看到执行报错了,str类型的与int类型不能进行比较;
因为score为一个输入类型的变量,而input函数所有形式的输入按字符串处理,如果想要得到其他类型的数据进行强制类型转化,此处我们需要对输入内容强制进行转化,如下
score =int(input('请输入分数:'))
if score >= 80:
print('优秀')
elif score >=60 and score<80:
print('及格')
else:
print('不及格!')
执行上述代码,输入分数为99,查看输出结果
![]()
输入分数为78,查看输出结果

输入分数为55,查看输出结果
![]()
2、for循环和while循环的基本使用方法
for循环
for something in XXXX:
语句块
即表示对XXXX中的每一个元素,执行某些语句块,XXXX可以是列表,字典,元组,迭代器等等。
如下
for x in range(10):
print('test')
执行查看输出结果,输入了10次test
while循环:
while 条件表达式1:
语句块
while 循环不会迭代 list 或 tuple 的元素,而是根据表达式判断循环是否结束。while循环会每次判断 条件表达式1 是否为true,如果为true,则执行语句块,否则退出循环。
例如:
count=0
while count<3:
print('哈哈哈')
count+=1
执行看一下结果

结果输出了3次‘哈哈哈’,每一次输入,count+1,直到不满足条件count<3时,退出循环。
continue和break
break:
直接退出整个循环体;
continue:
跳出本次循环,执行下一次循环。
例如上边的例子,我们加上break和continue来看一下结果
for x in range(10):
print('test')
break
执行并查看结果

我们看到for循环中添加break之后,执行一次,遇到break就退出循环了,没有继续循环。
在while中添加continue来试试:
count=0
while count<3:
count += 1
username=input('请输入您的姓名:')
if username=='小王':
print('%s,欢迎光临!'%username)
break
else:
print('您好,您重新输入!')
continue
else:
print('您好,输入次数过多!')
执行上述代码,输入姓名为:ww,查看结果

执行代码,输入姓名为:小王,查看结果

其中,字符串的比较
相等:==
不等于 :=!
小于等于 :<=
大于等于:>=
我们再来试一个猜数字的例子
Python中的random模块用于生成随机数。下面介绍一下random模块中最常用的几个函数。
random.random
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
random.uniform
random.uniform的函数原型为:random.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a random.randint random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b random.randrange random.randrange的函数原型为:random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数。random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。 random.choice random.choice从序列中获取一个随机元素。其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。 random.shuffle random.shuffle的函数原型为:random.shuffle(x[, random]),用于将一个列表中的元素打乱。 random.sample random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。 首先需要导入random模块 执行查看结果为 736 ,取了一个随机数。 下面来写猜数字的例子:如果7次之内猜出数字,则结束,如果错误,输入超过7次后结束。 执行输入相应的数字,查看结果、 python的数据类型-列表 列表是最常用的python数据类型,每一个元素都配有一个位置(角标或索引),从0开始依次类推。可以进行的操作包括索引,切片,追加,检查等。 1、定义一个列表 只要使用方括号括起来,并用逗号分隔不同数据项,就定义好一个列表了。例如: 那我们怎么打印出列表中的值呢,刚刚我们说了,列表有角标,我们可以通过角标找到想要的数据,如下: 角标是3,从0开始的话那就是第四个数据,我们执行看一下结果: 角标可以从正向计数,也可以从逆向计数,例如最后一个元素的角标为-1,依次类推,例如: 我们执行一下,可以看到打印的效果是一样的: 如果定义一个空的列表 stus=[] 上面我们列举的都是一维数组,python中还存在多维数组,例如: 我们打印来看一下 可以看到多维数组中字符串类型和int类型是可以同时存在的。 2、增加元素 append方法,在末尾增加一个元素,一次只能增加一个。我们来实验一下 查看打印结果: insert方法,将对象插入列表指定的位置,如: stus=['xiaoli','xiaowang','xiaotu','xiaozhao'] stus.insert(2,'www') 当输入的下标不存在的场合,就会把数据添加到末尾,来实验一下: 打印看一下结果: extend方法,在列表的末尾一次性追加另一个序列中的多个值(把两个列表合并): 查看执行结果 我们可以看到,打印出来的num1,是合并之后的列表,列表num2是不受影响的。 3、更新元素 可以直接给列表中的某一个元素进行赋值,如下: 看一下执行结果: 可以看到角标为2的第三个元素,已经被修改为11; 4、删除元素 del 语句:删除操作可以使用del语句来操作,例如 我们来打印一下,看一下结果: 可以看到删除了填写的下标元素,此处需要注意的是,下标是必须填写的,不填写就会报错,如果想要删除整个列表,可以用clear方法,如下: clear方法: 执行看一下结果,可以看到清空了整个list pop方法,移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。 我们可以看到删除操作中,我们指定了角标,则删除了对应角标位置的数据,没有指定角标的删除了最后一个数据。 删除操作还有一种方法,remove方法,直接删除需要删除的元素;如下: 看一下执行结果: 我们看到上述列表中有两个[5],我们使用remove方法删除5的时候,只会删除其中的一个元素,删除第一个匹配的元素,不会全部删除。 pop和remove的区别还在于pop会返回删除元素的值,而remove不会返回。 我们看一下执行结果,remove返回的是none,pop返回了删除的数据3: 5、反转排序 reverse方法,使列表中的元素反向排列,例如 执行结果: sort 方法,对列表进行排序,但只能是同类型的元素进行排序,不同类型的元素会报错,看一下: 执行结果: 错误提示信息显示str类型和int类型不能进行排序。我们来看一下同类型的排序: 查看结果: 排序默认的话为升序排序,如果需要倒叙排序我们可以借助reverse方法,对排序进行反转,如下: 查看执行结果: index方法,从列表中找出某个元素第一个匹配项的索引位置,使用方法如下: 查看执行结果: 6、循环 list的一个重要特性就是可循环的,python可以对list进行解析,对list的元素进行遍历,我们看一下直接应用for循环的结果: 看一下执行结果,可以看到循环一个列表,取出了列表中的每一个元素: 在其他语言中想要遍历出列表的每一个元素就没有这么容易了, 7、切片 由于list可循环可遍历的特性,我们就可以对list进行切片操作,取出我们想要的元素。 切片是list取值的一种方式。 切片的语法格式: list[start:stop:step] star:表示取值的开始 stop:表示取值的结束 step:表示步长 我们来实验一下: num=['haha','hehe','heihei','hengheng'] 差看执行结果: 我们看到上述的结果,当我们结束值为3时,实际取到的值为下标为2的值,所以想取到一个列表中全部的值时,结束取值应为末尾下标+1。 执行结果: #如果切片的开始值不写的话,默认从0开始;如下: 查看打印结果: #如果切片的结束值不写的话,则默认到最后,例如: 查看打印结果,num4我们步长设置的2,所以是隔一个取一个数值: #如果步长不写的话默认是1,如下: num=['haha','hehe','heihei','hengheng'] 查看执行结果: #如果都不填写的话默认就是列表所有,步长为1,如下 查看执行结果: 当步长为负数的场合,相当于从右往左取,如下: 差看执行结果: 当步数是步数的时候,开始值和结束值也应该是负数,如下: 查看执行结果,负数的时候,结束标志同样需要+1: 总结:切片操作的开始结束值是顾头不顾尾,结束值为末尾角标+1。 8、切片同样适用于字符串 切片: str='今天真开心!明天星期五' 查看执行结果: 字符串用于循环: 查看结果: 如果需要同时打印下标和文字,用enumerate: str='今天真开心!明天星期五' 查看执行结果: 布尔类型 布尔类型只有True和False两种值,简单地说是非空即真,非0即真;如下: 执行结果: 综上我们来做一个小程序温习一下: 要求:写一个死循环, 注册用户,提示用户注册成功,如果已经存在则提示用户已经存在。 查看执行结果: 上面我们判断用户名是否存在,用了 in 进行判断,还可以用计数的方法判断,判断输入的用户名在列表中的个数,如果个数为0则说明输入的用户名不存在,可以注册成功。例如: 查看执行结果: 一、字典 Python字典是另一种可变容器模型,且可存储任意类型对象,如字符串、数字、元组等其他容器模型。 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示: f = {key1 : value1, key2 : value2 } 键必须是唯一的,但值则不必。 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。 查看打印结果:可以看到字典里面的排序是无序的。 1、查看元素 如果我们要查看某个键值的值,把相应的键放入方括弧,字典没有下标,直接取key,例如: 执行查看结果: 还可以用get方法获取键值,例如: 差看执行结果: 当get的键值不存在的时候会返回默认值: 查看执行结果: None 2、增加元素 如果需要增加元素就直接在方括号中写入key名,然后写入相应的值,例如: 查看执行结果,加入了phone: setdefault()方法和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default值,我们看一下和get的区别: 查看执行结果: 120 可以看到,get的key不存在的时候,只会返回默认值,不会添加到字典中,setdefault的可以不存在的场合,会返回默认值,并把key 添加到字典中,并默认值赋值; 3、修改元素 如果需要修改字典中的键值,同样也是在方括号中写入已有的key值,然后写入相应的值,例如: 查看执行结果: 4、删除字典元素 如果只需删除一个元素,可以用del命令: 查看执行结果: {'addr': '昌平', 'money': 19000, 'sex': '女', 'age': 12} 如果需要清空字典表,用clear方法,例如: 查看执行结果: {} 如果需要删除字典表,可以用del,例如: 查看执行结果: 我们可以看到,d这个字典已经不存在了 和列表一样,还可以用pop()方法删除一个元素 查看执行结果: {'sex': '女', 'addr': '昌平', 'age': 12, 'money': 19000} popitem()方法也可以用来删除,由于字典是无序的,所以popitem方法会随机删除字典中的一个元素,例如 查看执行结果: {'name': 'pei', 'age': 12, 'addr': '昌平', 'sex': '女'} 5、字典的其他方法 keys以列表形式返回一个字典所有的键; 执行结果: dict_keys(['addr', 'name', 'sex', 'age', 'money']) values,以列表返回字典中的所有值; 查看执行结果: dict_values(['女', '昌平', 12, 'pei', 19000]) 6、循环 我们对字典进行循环操作,看一下得到的结果: 练习: 下面我们看一下列表与字典的实际应用,通常情况下,两者都是结合使用的。例如: 以上, 1.我们要取到‘pei’的招商卡的金额: print(stus['pei']['jinku']['招商卡']) 2.我们要取到‘li’的化妆品种类 3.我们查看‘wang’的bag的种类: 查看执行结果:dict_keys(['lv', '鳄鱼']) 4.如果我们查‘wang’的bag的总数量呢: 我们可以直接使用内置的函数sum(),如下: 查看执行结果:100 还可以用相加的方法: 查看执行结果:100 再来做一个小实验: ##################################################### #用户注册:存入字典表中,注册时进行非空验证,,验证密码和确认密码是否一致,已经存在的不能重复注册 大家执行一下看一下结果吧~ 元组 Python的元组与列表类似,不同之处在于元组的元素不能修改。 元组使用小括号,列表使用方括号。元组与字符串类似,下标索引从0开始,可以进行截取,组合等。 1、创建 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。 如下: 执行查看结果: 1 2、修改元组 元组中的元素值是不允许修改的: 我们执行看一下,看到执行的结果报错了。 TypeError: 'tuple' object does not support item assignment #可变变量:创建后可以修改 查看执行结果: 0 元组的切片与列表切片类似,用:进行分割 查看执行结果: ('111', '333') 我们来做个小程序: 如果列表中的数除2取余数不为0的,则从列表中删除: 运行以上程序,查看结果: [1, 2, 4, 6, 8] 我们看到以上程序【1】没有被删除,那是因为我们直接修改了列表,进行了删除操作,当遇到第一个1时,进行了删除,列表变为[1,2,3,4,5,6,7,8,9],此时循环的角标变为1,取到的是2,略过了[1]; 所以循环list的时候不能删除列表中的数据,角标会进行变化; 这个时候我们就需要拷贝一份新的列表进行循环: 查看执行结果: 我们看到了,通过切片拷贝的内容和直接赋值的内容是一样的,但地址是不一样的。 我们叫做深拷贝和浅拷贝,深拷贝的时候删除原有列表的数据,不影响拷贝的列表。 字符串方法 下面列举字符串常用的方法 文件操作 上次学习到文件的读写,为了高效的读写文件,我们可以用循环的方式,一行一行的进行读写操作,打开文件的方法是open的方法,打开文件执行完后还要进行关闭操作。 一般的文件流操作都包含缓冲机制,write方法并不直接将数据写入文件,而是先写入内存中特定的缓冲区。 正常情况下缓冲区满时,操作系统会自动将缓冲数据写入到文件中。 至于close方法,原理是内部先调用flush方法来刷新缓冲区,再执行关闭操作,这样即使缓冲区数据未满也能保证数据的完整性。 如果进程意外退出或正常退出时而未执行文件的close方法,缓冲区中的内容将会丢失。 所以我们通常用flush方法刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区。如下: 还有一种打开文件的方式,可以自动关闭文件,防止open方式忘记手动关闭文件。 在 “with” 打开的代码块内,文件是打开的,而且可以自由读取。 然而,一旦Python代码从 “with” 负责的代码段退出,文件会自动关闭。 用with打开文件的时候可以打开多个,用逗号分开就好: 打开多个文件时,我们就可以对多个文件同时进行操作了。 在文件操作时可能会遇到需要下载图片或视频的内容,如果我们要下载一个网站的图片,进行保存,由于图片地址时http协议的,所以我们需要用到request处理HTTP的功能。 wb模式时文件的一种操作模式,wb代表以二进制的格式写文件,还有以下几种方式: "rb" 以二进制读方式打开,只能读文件 , 如果文件不存在,会发生异常 "wb" 以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件 如果文件已存在,先清空,再打开文件 "rt" 以文本读方式打开,只能读文件 , 如果文件不存在,会发生异常 "wt" 以文本写方式打开,只能写文件, 如果文件不存在,创建该文件 如果文件已存在,先清空,再打开文件 "rb+" 以二进制读方式打开,可以读、写文件 , 如果文件不存在,会发生异常 "wb+" 以二进制写方式打开,可以读、写文件, 如果文件不存在,创建该文件 如果文件已存在,先清空,再打开文件 实战练习: 用学过的知识完成下面的小程序: 将文件中的内容个别文字进行批量替换。 上述方法我们直接取出所有内容,然后进行替换,清空源文件后再写入所有内容,这样的效率时不高的,文件小的时候还好,当文件有大量数据的时候,这种方法的效率就太低了。 我还可以用for循环的方式,进行逐行读取,逐行修改的方式,但在文件中我们没办法在原文件中取读完每一行就立马进行修改 所以可以分为以下几个步骤进行: 1、逐行高效读取文件,进行修改 2、将修改后的内容写入一个新的文件中 3、修改完成后删除原有文件 4、将新文件的名称修改为目标文件的名称 集合 在Python中集合set是基本数据类型的一种,它有可变集合(set)和不可变集合(frozenset)两种。创建集合set、集合set添加、集合删除、交集、并集、差集的操作都是非常实用的方法。 集合的一个特点是天生去重 创建集合: 查看执行结果: [1, 2, 3, 4, 5, 5, 5, 5, 5, 5] 取集合的数据: 查看执行结果: 添加元素: s2={'1','2','3','3','3'} 查看执行结果: {'5', '2', '1', '3'} 如果想添加多个元素的话,可以用update s2={'1','2','3','3','3'} 执行查看结果: {7, '2', 8, 9, '1', '3'} 删除元素: 删除元素可以用pop()随机删除一个元素: 查看执行结果: 2 集合的运算操作: 交集、并集、差集、子集、包含 s2={'1','2','3','5'} 查看执行结果: {'1', '3', '2'} 查看执行结果: {'8', '3', '5', '2', '1', '4', '9'} {'5'} 子集、包含关系: 查看执行结果 True 函数 函数是把一堆代码合到一起,变成一个整体,是一个方法或者功能的代码段,可以重复使用。 定义一个函数的规则: 定义一个函数,并调用:hello world! 查看执行结果: hello world! 再来看一个实例: 查看执行结果:SSS文件中写入了www 参数传递 在 python 中,类型属于对象,变量是没有类型的 以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象。 定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。 局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。 如下实例: 判断对象的数据类型方法,可以用type()方法,如: 执行查看结果: dict 模块 在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。 如果需要调用模块中的函数的话,需要用 模块名.函数名 进行调用。 例如上面的校验是否是小数的函数,存放在check.py文件中,如果需要直接调用函数,则需要导入这个模块,如下: 执行的话就会直接调用check中的check_float 函数。 实战演练: 需求:access.log日志 60S内同一个IP地址访问超过200次,IP加入黑名单 感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走: ① 2000多本软件测试电子书(主流和经典的书籍应该都有了) ② 软件测试/自动化测试标准库资料(最全中文版) ③ 项目源码(四五十个有趣且经典的练手项目及源码) ④ Python编程语言、API接口自动化测试、web自动化测试、App自动化测试(适合小白学习) ⑤ Python学习路线图(告别不入流的学习) 在我的QQ技术交流群里(技术交流和资源共享,广告进来腿给你打断) 可以自助拿走,群号550412533(备注“csdn999”)550412533(备注“csdn999”)群里的免费资料都是笔者十多年测试生涯的精华。还有同行大神一起交流技术哦。 import random
random_num=random.randint(1,1999)
print(random_num)
import random # 导入random模块
random_num = random.randint(1, 500)
count = 0
while count < 7:
count += 1
num = int(input('请输入你猜的数字:'))
if num > random_num:
print('你猜的太大了')
continue
elif num < random_num:
print('你猜的太小了')
continue
else:
print('恭喜你猜对了,答案是:%s'%num)
break

python自动化测试学习笔记-2-列表
stus=['xiaoli','xiaowang','xiaotu','xiaozhao']
stus=['xiaoli','xiaowang','xiaotu','xiaozhao']
print(stus[3])

stus=['xiaoli','xiaowang','xiaotu','xiaozhao']
print(stus[3])
print(stus[-1])
![]()
stus=['一年级','二年级','三年级','四年级',['一班','二班','三班','四班','五班',[1,2,3,4,5,6,7,8]]]
print(stus)
![]()
stus=['xiaoli','xiaowang','xiaotu','xiaozhao']
stus.append('wangzhi')
print(stus)
![]()
print(stus)stus=['xiaoli','xiaowang','xiaotu','xiaozhao']
stus.insert(9,333)
print(stus)
![]()
num1=[1,2,3,4,5]
num2=[6,7,8,9,10]
num1.extend(num2)
print(num1)
print(num2)

num1=[1,2,3,4,5]
num1[2]=11
print(num1)
![]()
num1=[1,2,3,4,5]
del num1[0]
print(num1)
![]()
num1=[1,2,3,4,5]
num1.clear()
print(num1)
![]()
num1=[1,2,3,4,5]
num2=[6,7,8,9,10]
num1.pop(1)
num2.pop()
print(num1)
print(num2)
看一下执行结果:

num1=[1,2,3,5,4,5]
num1.remove(5)
print(num1)
![]()
num1=[1,2,3,5,4,5]
print(num1.remove(5))
print(num1.pop(2))
![]()
num1=[1,2,3,5,4,5]
num1.reverse()
print(num1)
![]()
num1=[1,2,5,3,4,'a','z','l','t']
num1.sort()
print(num1)
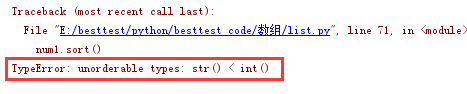
num1=['a','z','l','t']
num1.sort()
print(num1)
![]()
num1=[45,23,67,111,1,9,100]
num1.sort(reverse=True)
print(num1)
![]()
num1=[45,23,67,111,1,9,100]
print('111的索引位置是:%s'%num1.index(111))
![]()
num=['haha','hehe','heihei','hengheng']
for i in num:
print(i)

num2=num[0:3:1]
print(num2)![]()
num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
print(num2)
![]()
num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
num3=num[:3:1]
print(num2)
print(num3)

num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
num3=num[:3:1]
num4=num[1::2]
print(num2)
print(num3)
print(num4)

num2=num[0:4:1]
num3=num[:3:1]
num4=num[1::]
print(num2)
print(num3)
print(num4)
num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
num3=num[:3:1]
num4=num[:]
print(num2)
print(num3)
print(num4)

num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
num3=num[:3:1]
num4=num[:]
num5=num[::-1]
print(num2)
print(num3)
print(num4)
print(num5)

num=['haha','hehe','heihei','hengheng']
num2=num[0:4:1]
num3=num[:3:1]
num4=num[:]
num5=num[::-1]
num6=num[-1:-5:-1]
print(num2)
print(num3)
print(num4)
print(num5)
print(num6)

str1=str[1:10:1]
print(str1)![]()
str='今天真开心!明天星期五'
for i in str:
print(i)
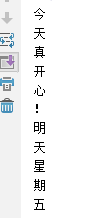
for i,j in enumerate(str):
print('%s的下标是%s'%(j,i))
a=''
b=0
c=' '
if a:
print('zhen')
else:
print('jia')
if b:
print('zhen')
else:
print('jia')
if c:
print('zhen')
else:
print('jia')

user=[] #d定义一个空列表
while True:
username=input('请输入用户名:')#输入用户名
passwd=input('请输入密码:') #输入密码
if username in user: #判断输入的用户名是否存在在列表中
print('用户已经存在,请重新输入!')
else:
print('恭喜你,注册成功') #注册成功
user.append(username) #用户名添加到列表中

username=[]
while True:
name=input('请输入用户名:')
passwd=input('请输入密码:')
if username.count(name)==0:
print('恭喜你注册成功!')
username.append(name)
else:
print('用户已经存在,请重新输入!')

python自动化测试学习笔记-2-字典、元组、字符串方法
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d)
![]()
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d)
print(d['name'])
![]()
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d)
print(d['name'])
print(d.get('name'))

d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d.get('weight'))
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
d['phone']='13102011111111'
print(d)
![]()
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d.get('weight',120))
print(d)
t={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(t.setdefault('weight',130))
print(t)
{'age': 12, 'name': 'pei', 'money': 19000, 'sex': '女', 'addr': '昌平'}
130
{'age': 12, 'name': 'pei', 'sex': '女', 'addr': '昌平', 'money': 19000, 'weight': 130}d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
d['name']='yingfei'
print(d)
![]()
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
del d['name']
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
d.clear()
print(d)
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
del d
print(d)

删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
d.pop('name')
print(d)
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
d.popitem()
print(d)
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d.keys())
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
print(d.values())
d={'name':'pei','age':12,'sex':'女','addr':'昌平','money':19000}
for k in d:
print(k)
for k in d:
print(k,d.get(k))
for k in d:
print(k,d[k])
for k,v in d.items():
print(k,v)
查看执行结果:
money
name
addr
sex
age
我直接对列表循环,我们得到的只有key;
要想得到key的value值,需要单独取获取;
money 19000
name pei
addr 昌平
sex 女
age 12
money 19000
name pei
addr 昌平
sex 女
age 12
item方法,以列表返回可遍历的(键, 值) 元组数组,
money 19000
name pei
addr 昌平
sex 女
age 12
stus = {
'pei': {
'age': 18,
'sex': '男',
'addr': '昌平区',
'money': 10000000,
'jinku': {
'建行卡': 80000,
'工商卡': 800000,
'招商卡': 8000000
}
},
'li': {
'age': 19,
'sex': '女',
'addr': '昌平区',
'money': 10000000,
'huazhuangpin': ['chanle','haha']
},
'wang': {
'age': 19,
'sex': '女',
'addr': '昌平区',
'money': 10000000,
"bag": {
'lv': '一车',
'鳄鱼':10
}
},
}
查看执行结果:8000000print(stus['li']['huazhuangpin'])
查看执行结果:['chanle', 'haha']
print(stus['wang']['bag'].keys())
print(sum(stus['wang']['bag'].values()))
ls=stus['wang']['bag'].values()
sum=0
for i in ls:
sum=sum+i
print(sum)
user={}
while True:
username=input('请输入您的账号:').strip()
passwd=input('请输入您的密码:').strip()
cpasswd=input('请确认您的密码:').strip()
if username and passwd:
if username in user:
print('用户已经存在,请重新输入!')
else:
if passwd==cpasswd:
print('恭喜您,注册成功!')
user[username]=passwd
break
else:
print('两次密码不一致,请重新输入!')
else:
print('用户名或密码不能为空!请重新输入。')
while True:
usr=input('请输入您的账号:').strip()
pwd=input('请输入您的密码:').strip()
if usr and pwd :
if usr in user:
if pwd==user[usr]:
print('恭喜您登陆成功!')
break
else:
print('密码不正确,请重新登陆!')
else:
print('用户名密码不存在,请重新登陆!')
else:
print('用户名或密码不能为空,请重新登陆')
a=(1)
b=('111','222','333')#元祖也是list,只不过不能变
print(a)
print(b)
('111', '222', '333')b=('111','222','333')
print(b)
b[0]=12
print(b[0])
#不可变变量:一旦创建后,不能修改,如果修改只能重新定义,例如元祖和字符串mysql2=('182.168.55.14',8080,'pei','123456')#不可变,防止被修改
print(mysql2.count('m'))#统计次数
print(mysql2.index('pei'))#下标位置
2
3、切片b=('111','222','333','444')
print(b[0:5:2])
li=[1,1,2,3,4,5,6,7,8,9]
for i in li:
if i%2!=0:
li.remove(i)
print(li)
li=[1,1,2,3,4,5,6,7,8,9]
li2=li[:]#深拷贝,内存地址会变
li3=li#浅拷贝,内存地址不变
print(li2)
print(li3)
print(id(li))
print(id(li2))
print(id(li3))
for i in li2:
if i%2!=0:
li.remove(i)
print(li)
[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]
13995656
13967944
13995656
[2, 4, 6, 8]name=' {a} besttest best '
name1='a besttest best'
name2=' a besttest best\n'
name3='a.txt'
name4=' A B C D, E F G '
name5='1234567677'
print(name.strip())#默认去掉首尾的空格和换行
print(name)
print(name1.rstrip('best'))#去掉右边指定的字符
print(name1.rstrip('t'))#去掉右边指定的字符
print(name1.lstrip('a'))#去掉左边指定的字符
print(name2.rstrip())#去掉右边的空格和换行
print(name2)
print(name.count('e'))#计数
print(name.index('a'))#查找角标
print(name.replace('e','E'))#替换
print(name.format(a='test'))#格式化
print(name1.capitalize())#首字母大写
print(name1.center(30,'$'))#居中
print(name3.endswith('t'))#判断是以什么结尾的
print(name3.startswith('e'))#判断是以什么开头的
print(name1.expandtabs(16))
print(name1.find('w'))#找不到的时候会返回-1
print(name1.index('b'))#找不到的时候会报错
print(name1.upper())#把所有的小写字母变大写
print(name4.lower())#把所有的大写字母变小写
f={'name':'wang','age':13}
d='{name}欢迎,his age is {age}'
print(d.format_map(f))#字符串格式化,传进去的是字典
print(name.isdigit())#判断是否是数字
print(name.islower())#判断是否全是小写
print(name.isupper())#判断是否全是大写
print(name5.isalnum())#判断是否全是数字
print(name5.isalpha())#判断是否全是字母
print(name4.split())#分个字符串,默认以空格进行分割
print(name4.split(','))#以指定符号分割字符串
list=['a','b','c','d','e']
print('$'.join(list))#以指定字符链接列表中的字符串
s='asdasd asdasd asd asd asdasd a'
print('0'.join(s))#链接字符串的的元素
list2=['a','b','c','d',1,2,3,4,5]
#print('*'.join(list2))#int类型的不能进行拼接
大家可以自己试一下~
文件读写
##################################################
#文件读写
#读 r 打开文件没有指定模式,那么默认是读;r权限不能进行写文件操作,r+模式是读写模式,会追加写入的内容;r,r+文件不存在的时候会报错
#写 w w模式会清空原文件,w只能写,不能读; w+ 写读模式,会清空文件内容
#追加 a a+追加读写都可以,文件不存在的时候,会创建文件
file=open('test3','a+')#报GDK的错误,添加utf-8,打开文件
# file.write('hehe呵呵\n')
# print(file.readlines())#读取文件的所有内容,并把内容写成list格式
# file.seek(0)#读操作以后,指针位置在末尾,再读就不会读出来
# print(file.readline())#读一行
st=['a','b','c','d']
#file.write(st)#write不能写入list,只能写入字符串
file.writelines(st)#写入一个可迭代的元素
file.seek(0)
#print(file.readlines())#
print(file.read())#已经读过一次,会自动识别已经读过的数据
# for i in file:
# print(i)
file.close()#关闭文件
#####################################################3
#高效读文件的方法
#
fw=open('test2',encoding='utf-8')
count=1
for f in fw:
f=f.strip()
stu_lst=f.split(',')
print(stu_lst)
#直接循环文件对象的话,循环文件里面的每一行
# fw.close()
python自动化学习笔记3-集合、函数、模块
f=open('www','a+',encoding='utf-8')
f.
f.write('hahah\n')
f.flush()
f.close()
with open('aaa','a+',encoding='utf-8') as f:
f.seek(0)
f.write('haha\n')
f.flush()
with open('aaa','a+',encoding='utf-8') as f,open('www','w',encoding='utf-8')as w:
f.seek(0)
f.write('haha\n')
f.flush()
w.write('再见你好!')
import requests
url='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1515432257731&di=feaf94121db96dc3e315f6c170e0d5a0&imgtype=0&src=http%3A%2F%2Fh.hiphotos.baidu.com%2Fzhidao%2Fpic%2Fitem%2F1e30e924b899a901934d50551d950a7b0208f55d.jpg'
img=requests.get(url).content
f=open('ooo.jpg','wb')
f.write(img)
with open('ttt','a+',encoding='utf-8')as f:
f.seek(0)
content=f.read()
new_content=content.replace('终于','还好')
f.seek(0)
f.truncate()
f.write(new_content)
f.flush()
import os#导入文件操作模块
with open('ttt','r',encoding='utf-8')as f,open('new','a+',encoding='utf-8')as newf:#打开要修改的文件和一个新文件
for content in f:#遍历文件内容
new_content=content.replace('还好','终于')#替换文字
newf.write(new_content)#写入新文件
newf.flush()#立即刷新
os.remove('ttt')#删除原有文件
os.rename('new','ttt')#重命名文件
s=set()#空集合
s2={'1','2','3','3','3'}
list=[1,2,3,4,5,5,5,5,5,5]
s3=set(list)
#list 去重的话,需要循环取出比较
print(list)
print(s2)
print(s3)
{'2', '3', '1'}
{1, 2, 3, 4, 5}s2={'1','2','3','3','3'}
#集合是无序的,没有办法通过下标来取数据
print(s2[2])

s2.add('5')#add方法可以添加一个元素
print(s2)
s2.update([7,8,9]) # 添加多个元素
print(s2)s2={'1','2','3','4','8','9'}
print(s2.pop())
print(s2)
{'9', '1', '8', '4', '3'}
s3={'1','2','3','4','8','9'}
#交集
print(s2.intersection(s3))#intersection
print(s2&s3)#&f符号是取交集
{'1', '3', '2'}
#并集
print(s2.union(s3))#union取并集
print(s2|s3)#|取并集
{'8', '3', '5', '2', '1', '4', '9'}# #差集
print(s2.difference(s3))#S2中有,但是S3中没有的
print(s3.difference(s2))#s3中有,但是s2中没有的
print(s2-s3)#-代表差集,S2中有,但是S3中没有的
查看执行结果:
{'4', '8', '9'}
{'5'}s2={'1','2','3'}
s3={'1','2','3','4','8','9'}
print(s2.issubset(s3)) #S2是S3的子集
print(s3.issuperset(s2))#S3包含S2
True
def hello():
print('hello world!')
hello() #函数的调用
def hello():
f=open('sss','a+')
f.seek(0)
f.write('www')
f.close()
hello()
a=[1,2,3]
a="Runoob"
实例:def hello(filename,content=''):#形参,形式参数
f = open(filename, 'a+',encoding='utf-8')
#return #函数中添加return时,结束后边的代码
if content:
f.seek(0)
f.write(content)
res=''
else:
f.seek(0)
res=f.read()
#return res return以后文件就不会被关闭了,所以要把return写到后边
f.close()
return res
print(hello('www','乒乒乓乓乒乒乓乓乒乒乓乓'))#实参,实际的参数
users=hello('aaa')
print(users)
上述代码我们可以看到,当content为空或不为空的时候会有一个判断,一个用来读文件,一个用来写文件
形参,实参
#形参,位置参数也叫必填参数
#默认参数,定义是有一个默认值
#默认值参数是不必填的
#函数里边的变量只能在函数里边用,出了函数里边就不能用了,如果想获取到函数的处理结果,必须return
#没有return的话,返回的是none,return是非必填的,需要返回值的时候再写
#函数中遇到return,函数运行结束
#所以return的两个作用:1、返回函数值,2、结束运行
可变参数,默认参数,扩展参数(不定长参数)
def test(a,b=1,*args):#b=1为默认参数,默认参数为非必填
print('a',a)
print('b',b)
print('args',args)
test('hhh')
test('aaa','222','22233','44444','5555')#位置调用,根据参数的位置指定
test(b=5,a=10)#关键字参数,关键字调用,与位置调用不能混用
查看执行结果:
a hhh
b 1
args ()
a aaa
b 222
args ('22233', '44444', '5555')
a 10
b 5
args ()
*args是可扩展参数,可扩展参数为非必填参数,会把多传的参数放到一个元祖中,可以自己定义名字。
参数为字典表的时候:
def test2(**kwargs):#keargs 字典
print(kwargs)
test2(name='222',sex='eee')#kwargs方式必须用关键字调用的方法
def test3(a,**kwargs):
print(a)
print(kwargs)
test3(a=10000,s='sss',d='ssss3')
查看执行结果:
{'sex': 'eee', 'name': '222'}
10000
{'d': 'ssss3', 's': 'sss'}
全局变量和局部变量
a=100 #全局变量
def test():
a=5 #局部变量
print('函数内部:',a)
def test2():
b=1
print(a)#获取的全局变量100
test()
test2()
print('函数外部',a)#直接打印的外部的全局变量
查看执行结果:
函数内部: 5
100
函数外部 100
如果函数内部要使用全局变量的话,可以单独进行声明:例如:
#
d=100
def test():
global d#声明一下这是全局变量
print('libian',d)
d=6
test()
print('waibian',d)
查看执行结果:
libian 100
waibian 6
我们看到函数内部因为生命了d为全局变量,所以执行的时候首先取全局变量d=100,然后对d进行了修改为d=6,所以全局变量变为6,再次打印的时候显示为6.
我们看一下下边这个例子:
money = 899
def test(consume):
return money-consume
def test1(money):
return test(money)+test(money)
money=test1(money)
print(money)
可以先预计一下执行结果,money=test1(money),先调用test1,money=899,执行test1又会调用test,传参都是money,所以test执行后是0,test1执行是0+0=0;
我们执行一下看预期结果:0 #执行结果是0,预期正确
再看一下下边的例子:
def test():
global f
f=5
print(f)
def test1():
c=f+5
return c
res=test1()
print(res)
看上边的例子,有的朋友会预期,调用test1,c=f+5,f=5,所以结果应该是10,我们执行看一下结果:

从执行结果看到报错了,因为没有f没有定义,那是因为我们调用的时候只调用了test1,没有调用test,所以系统是不知道f的值的,只有调用的时候才会进行运算。
正确的是:
def test():
global f
f=5
print(f)
def test1():
c=f+5
return c
test()#需要调用才会执行test,不调用不执行
res=test1()
print(res)
查看执行结果:10
实例演练:
写一个小程序,校验输入的字符串是否是一个合法的小数。
分析:1、小数分为正小数和负小数:例3.3,-2.33
2、小数有且只有一个小数点
3、校验字符串就要先把输入的内容强制类型转换成字符串类型
def check_float(number):
if number.count('.') == 1:#判断小数点的个数
num_left=number.split('.')[0]#以小数点为分割点
num_rigth=number.split('.')[1]
if num_left.isdigit() and num_rigth.isdigit():#小数点左边和右边都是数字,则为正小数
print('您输入的是正小数')
elif number.count('-')==1 and number.startswith('-'):#判断符号的个数,且以负号开头
if num_left.split('-')[1].isdigit() and num_rigth.isdigit():#小数点左边,负号右边都是数字,小数点右边都是数字
print('您输入的是负小数')
else:
print('您输入的不是小数')
else:
print('您输入的不是小数')
else:
print('您输入的不是小数!')
str=input('请输入要校验的字符串:')#input输入的就是字符串类型
check_float(str)#调用函数
大家可以自己试一下执行一下结果。
递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
下面看一个例子:
def test1():
num =int(input('请输入数字:'))
if num%2==0:
return True
else:
print('不是偶数请重新输入:')
return test1()
test1()
上述代码,表达了输入一个数字,如果是偶数,返回True ,如果是计数再次调用test1,知道输入的是偶数返回True为止。这种我们就叫它递归函数。
递归函数的优点是定义简单,逻辑清晰。
但是使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,
每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。递归最多调用999次;
比较两个字典的key和value:
########################################
#对比两个报文中不一样值
#1、循环第一个字典,取出key
#2、拿第一个的key去第二个的字典中去取值
d1={'a':'1','b':'2'}
d2={'a':'1','b':'3'}
def compare(d1,d2):
for key in d1:
v1=d1.get(key)
v2=d2.get(key)
if v2:
if v1==v2:
pass
else:
print('两个值不一样,不一样的key:%s,v1的值:%s,v2的值:%s'%(key,v1,v2))
compare(d1,d2)
查看执行结果:
两个值不一样,不一样的key:b,v1的值:2,v2的值:3
def print_var_type(var):
if type(var)==str:#字符串类型
print('string')
elif type(var)==dict:#字典类型
print('dict')
elif type(var)==list:#列表类型
print('list')
s={'name':'pei'}
print_var_type(s)
#一个python文件就是一个模块
#1、标准模块
# python自带的,不需要安装的
#2、第三方模块
# 别人写的,只要安装就能使用
#3、自己写的模块
# pip install radis #直接pip install 就可以 在 python安装目录下的scripts,加到环境变量中
#下载好安装包手动安装,解压,在命令行里边进入到解压后的目录,在执行python setup.py install
#或者进入到目录中,shift+右键,在当前窗口打开命令,输入python setup.py install
import cheak
print(cheak.check_float('1.6'))
#导入python文件的实质是从头到尾运行一次
#
#import play
#import 导入文件的时候是在当前目录下找文件,
#当前目录找不到的话,从环境变量里面找
#环境变量就是让一个命令在任何目录下都能执行
#查看当前系统的环境变量目录
import sys
print(sys.path)
#60s读一次文件
#以空格切割,取第一个元素,获取到IP
#把IP地址存入list,如果大于200次,则加入黑名单import time
point = 0#文件指针
while True:
ips=[]#空列表,用于存放所有IP
bip = set()#定义一个空集合,用于存放需要加入黑名单的
with open('access.log') as f:
f.seek(point)
for line in f:
ip=line.split()[0]#分割每一行,默认split是以空格分隔
ips.append(ip)#添加到list中
if ips.count(ip)>199:#判断
bip.add(ip)
for i in bip:#bip为集合,存入的去重的ip
print('已经把%s加入黑名单'%i)
point=f.tell()
time.sleep(60)
————————————————