由Java引起的指令重排序思考
背景
问题出现
最近遇到了一个NullPointerException,虽然量不大,但是很怪异,大致长这个样子
![]()
这是个什么空指针?居然说我LinkedList.iterator().hasNext()方法有问题?可是我就是正常的调用hasNext()啊,怎么就抛出来这种异常了呢?
问题初分析
- 调用LinkedList.iterator().hasNext()相关的代码是出现在预加载场景里的,而预加载其实大多数是在异步线程里进行的,出问题的地方恰好是异步线程和UI线程共同访问LinkedList的地方(UI线程里add,异步线程里poll),然后我们就会很自然的想到是不是因为在add和poll的过程中发生了线程切换导致的呢?
LinkedList实现(Java8之前)
源码
- Link
private static final class Link<ET> {
ET data;
Link<ET> previous, next;
Link(ET o, Link<ET> p, Link<ET> n) {
data = o;
previous = p;
next = n;
}
}Link其实就是我们所说的Node, 从这里可以看出来这是一个双向链表
- LinkedList()
public LinkedList() {
voidLink = new Link(null, null, null);
voidLink.previous = voidLink;
voidLink.next = voidLink;
} voidLink也是一个Link类型,LinkedList为了方便管理,内部实现其实是一个循环双向链表,voidLink就是连接首尾的那个节点,使用这么一个voidLink也可以减少大量空指针判断和保护,若链表为空,voidLink的previous和next都指向自己
- LinkedList#poll() -> LinkedList#removeFirst() ->LinkedList#removeFirstImpl()
private E removeFirstImpl() {
Link first = voidLink.next;
if (first != voidLink) {
Link next = first.next;
voidLink.next = next;
next.previous = voidLink;
size--;
modCount++;
return first.data;
}
throw new NoSuchElementException();
} 这也就是LinkedList的出队操作了,惊讶的发现并没有任何一个中间环节使链表上的某一个指针指向了null,那再来看一下add方法
- LinkedList#add() -> LinkedList#addLastImpl()
private boolean addLastImpl(E object) {
Link oldLast = voidLink.previous;
Link newLink = new Link(object, oldLast, voidLink);
voidLink.previous = newLink;
oldLast.next = newLink;
size++;
modCount++;
return true;
} 这是对应的入队操作,也没有发现任何一个中间步骤让链表上的某个指针指向null,那再来看下报错的地方
- LinkedList#itertator() -> LinkedList#listIterator(0) -> new LinkedIterator(LinkedList, int)
LinkIterator(LinkedList object, int location) {
list = object;
expectedModCount = list.modCount;
if (location >= 0 && location <= list.size) {
// pos ends up as -1 if list is empty, it ranges from -1 to
// list.size - 1
// if link == voidLink then pos must == -1
link = list.voidLink;
if (location < list.size / 2) {
for (pos = -1; pos + 1 < location; pos++) {
link = link.next;
}
} else {
for (pos = list.size; pos >= location; pos--) {
link = link.previous;
}
}
} else {
throw new IndexOutOfBoundsException();
}
} 最终一系列的调用,调用到这个构造方法里,location恒等于0,也就是说必然执行到
link = link.previous;- 报错的地方 LinkedListIterator#hasNext()
public boolean hasNext() {
return link.previous != list.voidLink;
}报错信息显示这个link是空,这个link是LinkIterator的一个成员变量
private static final class LinkIterator<ET> implements ListIterator<ET> {
int pos, expectedModCount;
final LinkedList list;
Link link, lastLink;
//...
} 如刚才所分析,这个link明明在LinkedListIterator的构造方法里赋值成了voidLink.previous,而这个voidLink.previous在LinkedList构造方法里就赋值成了它自己啊,在之后的poll()和add()之后都不会再有任何一个中间步骤变成null,那问题出在哪里了?
问题可能出在哪里
- 审视整个流程,只有在LinkedList的构造器里面voidLink.previous曾经短暂的等于了null,但是这个赋值动作是在构造器里,那问题也只能是出在这里了,出问题的原因也只可能是Java虚拟机把字节码指令重排序了,也就是说把构造器里的赋值动作放到了ret指令后面,导致先返回了对象地址之后才执行赋值操作
- 类似问题:单例的double check
public class PreloadManager {
private volatile static PreloadManager sInstance;
public static PreloadManager getInstance() {
if (sInstance == null) {
synchronized(PreloadManager.class) {
if (sInstance == null) {
sInstance = new PreloadManager();
}
}
}
return sInstance;
}
//...
}sInstance必须要用volatile修饰,有的同学可能说是为了保证线程可见性,但是其实synchronized也可以保证线程可见性(有兴趣的同学可以自己去验证一下),那volatile是为了什么呢?答案是禁止指令重排序(虽然这种说法并不严谨)
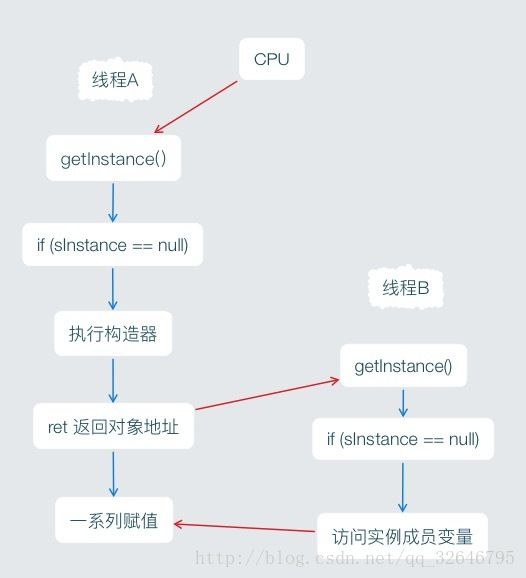
因为getInstance里面都加上了同步synchronized保护,所以假如执行构造器的时候进行了指令重排序,先执行了ret指令,把对象地址赋值给了sInstance变量之后,才进行构造器里的赋值,这时候恰好进行了线程切换,切换到了线程B,这个时候如果线程A也恰好进行了从工作内存写入到堆内存(这是JVM里的概念,从计算机硬件的角度来说就是从高速缓存中写入到主存中,注:JVM并没有规定应该何时进行写入,所以加上了“如果”两个字),那么就会检测到sInstance不是null,然后访问成员变量,问题就出现了
- 问:synchronized在这里就没有用了吗?
- 答:synchronized/锁在不发生竞态时确实没有互斥,另外synchronized有线程可见性也表明了synchronized也是有内存屏障(稍后会讲到),看了下面的内容再回来仔细体会一下,发现synchronized在这里提供的barrier对上述这种多线程问题来说—-没卵用
那么问题就确定了,就是在构造器里因为重排引起的问题!再来贴一下这段代码
public LinkedList() {
voidLink = new Link(null, null, null);
voidLink.previous = voidLink;
voidLink.next = voidLink;
} 也就是说重排序之后,线程切换恰好发生在new Link(null, null, null)的时候,导致在另外一个线程调用iterator()时,LinkIterator.link被赋值给了voidLink.previous,然后就出现了空指针,这个问题可以使用volatile解决,那么这个volatile为什么会有作用呢?
指令重排序/线程可见性
- 有关指令重排序的讲解网上有很多,我也就不盗图了,其实这本来就是很正常的一件事,现代处理器都是乱序执行的,这样可以提高吞吐量(当某些指令不在指令缓存中时,需要从主存中加载指令到高速缓存中,这个时间对于CPU来说是很长的,乱序执行允许CPU执行后面的指令而不是等待当前IO,这种情况主要出现在跳转指令),只要保证执行结果和顺序执行的是一致的就OK。
- 同样每个CPU都有自己的高速缓存(L1, L2),当某个指令执行到写回时,也许并没有把缓存中的数据写入到CPU共有的内存中去(L3和内存),这样也就导致了线程可见性
- 因为不一样的处理器采用不一样的指令集,所以上述行为可能有很多种,Java内存模型的引入其实也就是提供一种更高的抽象,把这些处理丢给JVM去适配(比如hotspot分了各个操作系统的版本),而Java开发者只需要写一样的代码就可以有意义的执行结果。
Java内存模型的有关原则
(以下内容是抄过来的)
happens-before原则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
as-if-serial
as-if-serial 语义的意思指:不管怎么重排序, 单线程下的执行结果不能被改变(简直就是废话)
数据依赖性
如果两个操作访问同一个变量,其中一个为写操作,此时这两个操作之间存在数据依赖性。编译器和处理器不会改变存在数据依赖性关系的两个操作的执行顺序,即不会重排序。
volatile语义
| 是否能重排序 | 第二个操作 | ||
|---|---|---|---|
| 第一个操作 | 普通读/写 | volatile读 | volatile写 |
| 普通读/写 | N | ||
| volatile读 | N | N | N |
| volatile写 | N | N |
提醒
Java的规范要求只需要保证乱序在单线程里看起来和顺序执行一样就OK了
内存屏障(Memory Barrier)
既然前面讲了问题所在,也说到了volatile能解决这个问题,那到底为啥能解决呢?
CPU的角度
其实这种问题不只是出现在Java上,毕竟一切的尽头都是机器指令,所以只要运行在计算机上都会有这种问题,所以其实指令集也针对乱序在多线程时出现的问题做出了拓展,这里我们以x86为例
- sfence: 内存写屏障,保证这条指令前的所有的存储指令必须在这条指令之前执行,并且在执行此条指令时把写入到CPU的私有缓存的数据刷到公有内存(以下均简称主存)
- lfence: 内存读屏障,保证这条指令后的所有读取指令在这条指令后执行,并且执行此条指令时,清空CPU的读取缓存,也就是说强制接下来的load从主存中取数据
- mfence: full barrier,代价最大的barrier,有上述两种barrier的效果,当然也是最稳健的的barrier
- lock: 这个是一种同步指令,也可以禁止lock前的指令和之后的指令重排序(有兴趣的同学可以去看一看这个指令,这个指令稍微复杂一些,可以实现的功能也很多,我就不贴了),lock也许是很多JVM底层使用的指令
上述只是x86指令集下的相关指令,不同的指令集可能barrier的效果并不一样,fence和lock是两种实现内存屏障的方式(毕竟一个指令集很庞大)
Java的抽象
Java这个时候又来了一波抽象,他把barrier分成了4种
| 屏障类型 | 指令示例 | 解释 |
|---|---|---|
| LoadLoadBarriers | Load1; LoadLoad;Load2 | 确保 Load1 数据的装载,之前于Load2 及所有后续装载指令的装载。 |
| StoreStoreBarriers | Store1; StoreStore;Store2 | 确保 Store1 数据对其他处理器可见(刷新到内存),之前于Store2 及所有后续存储指令的存储。 |
| LoadStoreBarriers | Load1; LoadStore;Store2 | Load1 数据装载,之前于Store2 及所有后续的存储指令刷新到内存。 |
| StoreLoadBarriers | Store1; StoreLoad;Load2 | 确保 Store1 数据对其他处理器变得可见(指刷新到内存),之前于Load2 及所有后续装载指令的装载。StoreLoad Barriers 会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。 |
注意,这是Java内存模型里的内存屏障,只是Java的规范,对于不同的处理器/指令集,JVM有不同的实现方式,比如有可能在x86上一个StoreLoad会使用mfence去实现(当然这只是我的意淫)
再次说明一下,这四个barrier是JVM内存模型的规范,而不是具体的字节码指令,因为你可以看到volatile变量在字节码中只是一个标志位,javap搞出来的字节码中并没有任何的barriers,只是说JVM执行引擎会在执行时会插一个对应的屏障,或者说在JIT/AOT生成机器指令的时候插一条对应逻辑的barriers,说句人话,这个barrier不是javac插的!所以你通过javap看不到,如果想要看到volatile的作用,可以把字节码转成汇编(很多很多),具体指令如下
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly [ClassName]提醒
到这里我们可以看到,其实不存在任何一种指令能够禁止乱序执行,我们能做到的只是把这一堆指令根据”分段”,比如在指令中插入一条full barrier指令,然后所有指令被分成了两段,barrier前面的我们称之为程序段A,后面的称之为程序段B,通过barrier我们能够保证A所有指令的执行都在B之前,也就是说,程序段A和B分别都是乱序执行的。
再举个例子,假如我们在一个变量的赋值前后各加一个barrier
full barrier;
instance = new Singleton(); //C
full barrier;那么在外界看起来就好像是禁止了C处指令重排一样,其实C处又可以拆成一堆指令,这一堆指令在两个barrier之间其实又是乱序的
对于内存屏障的使用
volatile
上面我们说了volatile的两大语义:
- 保证线程可见性
- “禁止”指令重排序(Java5之后引入/修复的)
现在我们来看看JVM到底会对volatile进行怎么样的处理
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障
此处盗一波图(来自《深入理解Java内存模型》,网上可以找到)
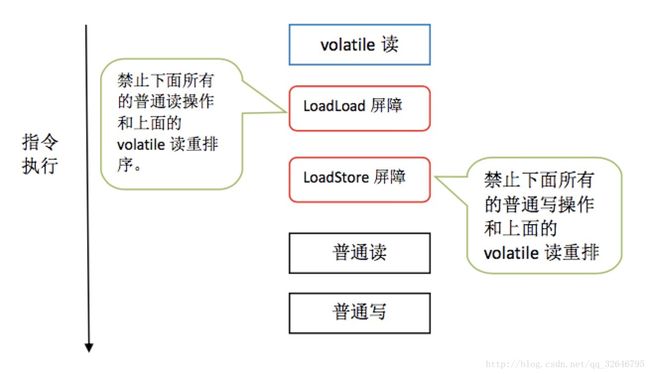
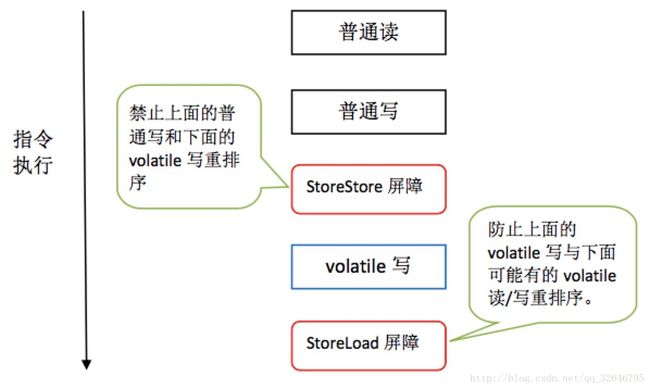
结合四种屏障的效果我们来看一下volatile是怎么实现我们最熟知的可见性和解决重排序问题的(上面说到volatile的具体语义已经一目了然了,但是表中的语义貌似和我们平时对volatile的认知关系不大)
(volatile的具体语义是指上述表中普通读写和volatile读写是否可以重排的关系)
- 可见性:这个主要体现在对volatile的写上面,当volatile写之后执行到了万能的StoreLoad屏障,然后这个屏障的语义可以把所有的写操作刷新到公共内存中去,并且使得其他缓存中的这个变量的缓存失效,所以下次在此读取时,就会重新从主存中load
- “禁止”重排序:这个之前也已经解释清楚了,两个屏障之间仍是可以乱序的,只是保证了barrier两侧整体之间时顺序的
synchronized
synchronized我们都知道就是锁,但是在java中,synchronized也是可以保证线程可见性的,我们知道信号量只能实现锁的功能,它是没有我们之前说过的内存屏障的功能的,那其实synchronized在代码块最后也是会加入一个barrier的(应该是store barrier)
final
final除了我们平时所理解的语义之外,其实还蕴含着禁止把构造器final变量的赋值重排序到构造器外面,实现方式就是在final变量的写之后插入一个store-store barrier
思考
public class Singleton {
public volatile static Singleton sInstance = new Singleton();
public LinkedList mList = new LinkedList<>();
public static void main(String[] args) {
sInstance.mList.add("A");//A
}
} 在A处,add函数内部是不是也被”框”在(sIntance的)屏障中间了呢?
我认为不会,因为sInstance.mList在是一个load操作,add()又是另外一个操作,所以我觉得add应该会在barrier的外面
我的想法是
//store-store barrier
LinkedList<String> list = sInstance.mList;
//store-load barrier
mList.add("A");(有可能是我理解错了)
性能
内存屏障禁止了CPU恣意妄为的重排序,所以肯定是会降低一定的效率,不过比synchronized应该还是要好一些的
建议
也不要过度使用volatile,如果是多个线程共有的变量,而且不能确保是没问题的,那么最好加上volatile(这也提醒我们,尽量减少多线程的公有变量)
一开始的问题
- 我自己也模拟着去复现这个bug,最终侥幸碰上了一次,自己模拟最重要的还是要看怎么样去诱导JVM/CPU去重排构造函数
- 这个问题或许在现在的项目里存在在各个地方,但是因为这个问题恰好是如果重排了,就会报NullPointer,那对于其他场景,也许只是一个基本变量,所以即使出现了重排导致了问题,可能也只是运行出现异常,而不是直接crash了
参考
- Wikipedia(wiki是个好东西)
- 《深入理解Java内存模型》