深度学习~循环神经网络RNN, LSTM
目录
1. 循环神经网络RNN
1.1 RNN出现背景
1.2 RNN概念
1.3 RNN Algorithm
1.4 RNN BP
2. LSTM
2.1 遗忘门与遗忘阶段
2.2 输入门与选择记忆阶段
2.3 输出门与输出阶段
2.4 LSTM Summary
参考
1. 循环神经网络RNN
1.1 RNN出现背景
problem:传统的深度神经网络输入信息没有顺序。比如,NLP领域中,我们输入单词经常使用embedding,将单词映射为词向量,然后输入到神经网络。但这种输入方式有一些问题,“我 爱 你”和“你 爱 我”在传统的神经网络中不能很好的识别。虽然,有人提出n-gram信息加入到输入层,比如fasttext,这在一定程度上解决了短句子单词间的顺序问题,但是这种方法也有一些弊端,就是我们无法捕获长句子的单词依赖!比如一个句子n个单词,那么如果想要捕获全部的单词顺序信息,需要1+2+3+...+n,这种方式会让embedding_lookup变得非常大。
solution:RNN,根据人类记忆,就是专门解决捕获长距离句子信息的模型。
1.2 RNN概念
循环神经网络(Recurrent Neural Network,RNN),是一种时间上进行线性递归的神经网络,是一种用于处理序列数据的神经网络。
相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
区别:递归神经网络(Recursive Neural Network)
这是一种在结构上进行递归的神经网络,常用于NLP中的序列学习,它的输入数据本质不一定是时序的,但结构却往往更加复杂。
1.3 RNN Algorithm
一个RNN的结构如下:
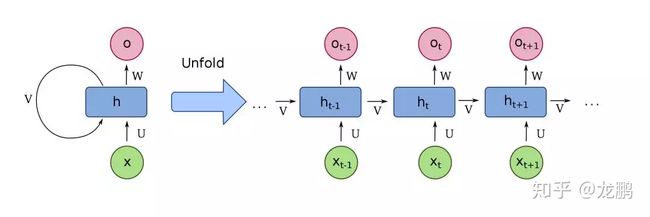
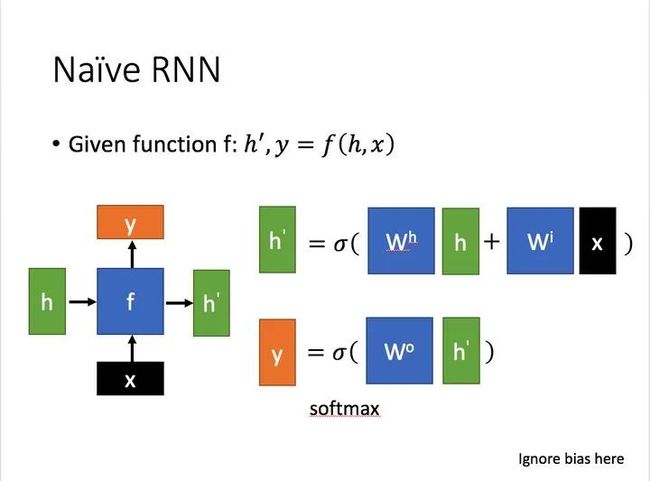
左侧是RNN模型的基础结构Naive RNN,右侧就是它在时间上进行展开的示意图。
- xt是时刻t的输入
- ht和ot分别对应时刻t的隐藏层和输出层
从上面我们可以看出,一个RNN的输入包括了两个:一个是当前时刻输入xt,用于实时更新状态,另一个是上一时刻隐藏层的状态ht-1,用于记忆状态,而不同时刻的网络共用的是同一套参数。
RNN中常用的激活函数是tanh,所以上面的式子写成公式,就是:

w就是要学习的权重,用几句代码表示RNN就是。
class RNN:
def step(self, x):
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x)) #更新隐藏层
y = np.dot(self.W_hy, self.h) #得到输出
return y1.4 RNN BP
普通卷积神经网络的优化使用的是反向传播,RNN使用的也是反向传播,不过是带时序的版本,即BPFT(backpropagation through time),它与BP的原理完全一样,只不过计算过程与时间有关。
与普通的反向传播算法一样,它重复地使用链式法则,区别在于损失函数不仅依赖于当前时刻的输出层,也依赖于下一时刻。所以参数W在更新梯度时,必须考虑当前时刻的梯度和下一时刻的梯度,传播示意图如下:
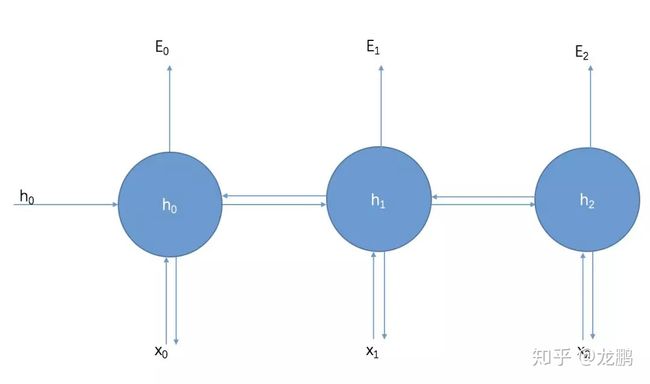
problem:RNN,因为t时刻的导师会传播到t-1, t-2,..., 1时刻,这样就有了联乘系数。
联乘带来了两个问题:梯度消失和梯度爆炸。而且,在前向过程中,开始时刻的输入对后面时刻的影响越来越小,这就是长距离依赖问题。这样依赖,RNN就失去了“记忆”能力
要知道生物的神经元对过去时序状态有很强的记忆能力。
solution:LSTM。LSTM通过引入若干门来解决这两个问题
2. LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,
problem:为了解决长序列训练过程中的梯度消失和梯度爆炸问题,因为当前的RNN仅查看最新信息以在实践中执行当前任务,因此它无法保留长期依赖关系
solve:简单来说,就是相比普通的RNN,LSTM是一种能够学习长期依赖关系的特殊RNN,LSTM能够在更长的序列中有更好的表现
LSTM相比RNN多了一个状态cell state。这个cell state承载着之前所有状态的信息,每到新时刻,就有相应的操作来决定舍弃什么旧的信息以及添加什么新的信息。这个状态与隐藏层状态h不同,在更新过程中,它的更新是缓慢的,而隐藏层状态h的更新时迅速的。

2.1 遗忘门与遗忘阶段
遗忘门决定了要从上一个状态中舍弃什么信息,它输入上一个状态的输出ht-1,当前状态输入信息xt到一个sigmoid函数中,产生一个介于0-1之间的数值,与上一个时刻的状态ct-1相乘之后来确定舍弃(保留)多少信息。0表示“完全舍弃”,1表示“完全保留”,这个阶段完成了对上一个节点cell state进行选择性忘记,遗忘门和它的输出公式如下:

2.2 输入门与选择记忆阶段
选择记忆阶段,也就是对输入有选择性地进行“记忆”,重要的记录下来,不重要的少记一些,它决定了要往当前状态中保存什么新的信息。它输入上一个状态的输出ht-1,当前输入信息xt到一个sigmoid函数中,产生一个介于0-1之间的数值it来确定需要保留多少新信息。
“候选新信息”则通过输入上一状态的输出、当前状态输入信息和一个tanh激活函数生成。有了遗忘门和输入门之后,就得到了完整的下一时刻的状态ct,它将用于产生下一状态的隐藏层ht,也就是当前单元的输出。
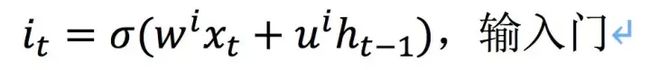

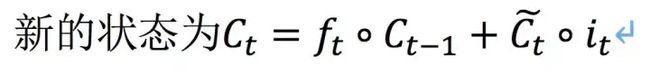
2.3 输出门与输出阶段
输出门决定了要从cell state中输出什么信息。与之前类似,会先有一个sigmoid函数产生一个介于0-1之间的数值ot来确定我们需要输出多少cell state中的信息。cell state的信息在与ot相乘时会先经过一个tanh层进行“激活”,得到的就是这个LSTM block的输出信息ht。
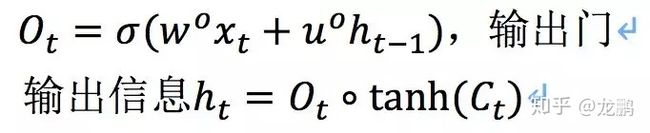
2.4 LSTM Summary
以上就是LSTM的基本原理,它通过门控状态来对信息进行选择性的记忆,满足了需要长时间记忆信息和遗忘信息的需求。
当前,随之而来的就是大量参数,因此后续有了GRU。
时序模型在语音、视频以及NLP等领域有不可替代的作用,相比于CNN,模型复杂度和训练难度也增加了不少。
参考
1. 【模型解读】浅析RNN到LSTM - 知乎
2. RNN和LSTM模型详解 - 空空如也_stephen - 博客园