【软件工程】几种常见的软件开发模型:(瀑布模型,快速原型模型,增量模型,螺旋模型,喷泉模型)模型的概念特点优点缺点和不同。
(瀑布模型,快速原型模型,增量模型,螺旋模型,喷泉模型)各种模型的概念特点优点缺点和不同。
(张海藩,吕云翔)著-软件工程 复习记录
文章目录
- 一、瀑布模型
- 二、快速原型模型
- 三、增量模型
- 四、螺旋模型
- 五、喷泉模型
- 六、参考资料
一、瀑布模型
在20 世纪80 年代之前,瀑布模型一直是唯一被广泛采用的生命周期模型。现在,它仍然是软件工程中应用最广泛的过程模型。如图所示为传统的瀑布模型。

-
特点:
(1) 阶段间具有顺序性和依赖性①必须等前一阶段的工作完成之后,才能开始后一阶段的工作;②前一阶段的输出文档就是后一阶段的输入文档。
(2) 推迟实现的观点
实践表明,对于规模较大的软件项目来说,往往编码开始得越早最终完成开发工作所需要的时间反而越长。
(3) 质量保证的观点
①每个阶段都必须完成规定的文档,没有交出合格的文档就是没有完成该阶段的任务。②每个阶段结束前都要对所完成的文档进行评审,以便尽早发现问题,改正错误。
传统的瀑布模型过于理想化了。事实上,人在工作过程中不可能不犯错误。因此,实际的瀑布模型是带“反馈环”的,如图所示( 图中实线箭头表示开发过程,虚线箭头表示维护过程)。
加入迭代过程的瀑布模型

当在后面阶段发现前面阶段的错误时,需要沿图中左侧的反馈线返回前面的阶段,修正前面阶段的产品之后再回来继续完成后面阶段的任务。
-
优点:
(1) 可强迫开发人员采用规范的方法
(2) 严格地规定了每个阶段必须提交的文档
(3) 要求每个阶段交出的所有产品都必须经过质量保证小组的仔细验证 -
缺点:
(1) “瀑布模型是由文档驱动的”,在可运行的软件产品交付给用户之前,用户只能通过文档来了解产品是什么样的。很可能导致最终开发出的软件产品不能真正满足用户的需求。
"瀑布模型是由文档驱动的“这个事实也是它的一个主要缺点。在可运行的软件产品交付给用户之前,用户只能通过文档来了解产品是什么样的。要求用户不经过实践就提出完整准确的需求,在许多情况下都是不切实际的。总之,由于瀑布模型几乎完全依赖于书面的规格说明,很可能导致最终开发出的软件产品不能真正满足用户的需要。
二、快速原型模型
快速原型(rapid prototype)是快速建立起来的可以在计算机上运行的程序,它所能完成的功能往往是最终产品能完成的功能的一个子集。下图描述了快速原型模型(图中实线箭头表示开发过程,虚线箭头表示维护过程)。
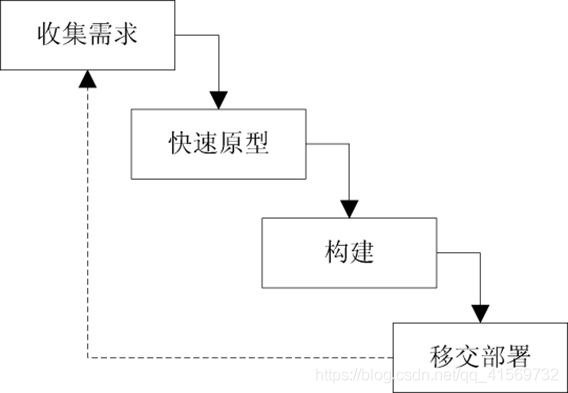
快速模型原型
优点:软件产品的开发基本上是按线性顺序进行的
快速原型模型是不带反馈环的,这正是这种过程模型的主要优点:软件产品的开发基本上是按线性顺序进行的。原型系统已经通过与用户交互而得到验证,据此产生的规格说明文档正确地描述了用户需求。开发人员通过建立原型系统已经学到了许多东西,在设计和编码阶段发生错误的可能性也比较小。它的优点是有助于保证用户的真实需要得到满足。
快速原型的本质是“快速”。开发人员应该尽可能快地建造出原型系统,以加速软件开发过程,节约软件开发成本。原型的用途是获知用户的真正需求,一旦需求确定了,原型将被抛弃。
当快速原型的某个部分是利用软件工具由计算机自动生成的时候,可以把这部分用到最终的软件产品中。
三、增量模型
增量模型也称为渐增模型,如图所示。使用增量模型开发软件时,把软件产品作为一系列的增量构件来设计、编码、集成和测试。每个构件由多个相互作用的模块构成,并且能够完成特定的功能。

增量模型
- 与瀑布模型和快速原型模型的不同:
采用瀑布模型或快速原型模型开发软件时,目标都是一次就把一个满足用户需求的产品提交给用户。增量模型则与之相反,它分批地逐步向用户提交产品,每次提交一个满足用户需求子集的可运行的产品。 - 优点:
(1) 能在较短时间内向用户提交可完成一些有用的工作的产品
(2) 逐步增加产品功能可以使用户有较充裕的时间学习和适应新产品,从而减少一个全新的软件可能给客户组织带来的冲击。
(3) 缺点:
增量模型本身是自相矛盾的。它一方面要求开发人员把软件看做一个整体,另一方面又要求开发人员把软件看做构件序列,每个构件本质上都独立于另一个构件。除非开发人员有足够的技术能力协调好这一明显的矛盾,否则用增量模型开发出的产品可能并不令人满意。
增量模型分批地逐步向用户提交产品,每次提交一个满足用户需求子集的可运行的产品。整个软件产品被分解成许多个增量构件,开发人员一个构件接一个构件地向用户提交产品。每次用户都得到一个满足部分需求的可运行的产品,直到最后一次得到满足全部需求的完整产品。
能在较短时间内向用户提交可完成一些有用的工作的产品,是增量模型的一个优点。增量模型的另一个优点是,逐步增加产品功能可以使用户有较充裕的时间学习和适应新产品,从而减少一个全新的软件可能给客户组织带来的冲击。
使用增量模型的困难是,在把每个新的增量构件集成到现有软件体系结构中时,必须不破坏原来已经开发出的产品。此外,必须把软件的体系结构设计得便于按这种方式进行扩充,向现有产品中加入新构件的过程必须简单、方便。也就是说,软件体系结构必须是开放的。
从长远观点看,具有开放结构的软件拥有真正的优势,这种软件的可维护性明显好于封闭结构的软件。尽管采用增量模型比采用瀑布模型和快速原型模型需要更精心的设计,但在设计阶段多付出的劳动将在维护阶段获得回报。如果一个设计非常灵活而且足够开放、足以支持增量模型,那么这样的设计将允许在不破坏产品的情况下进行维护。
四、螺旋模型
在软件开发过程中必须及时识别和分析风险,并且采取适当措施以消除或减少风险的危害。构建原型是一种能使某些类型的风险降至最低的方法。降低交付给用户的产品不能满足用户
需要的风险。
- 螺旋模型的基本思想是,使用原型及其他方法来尽量降低风险。理解这种模型的一个简便方法,是把它看做在每个阶段之前都增加了风险分析过程的快速原型模型,如图所示。图中带箭头的点画线的长度代表当前累计的开发费用,螺线旋过的角度值代表开发进度。

螺旋模型
- 基本思想:
使用原型及其他方法来尽量降低风险。
- 优点:
(1) 对可选方案和约束条件的强调有利于已有软件的重用,也有助于把软件质量作为软件开发的一个重要目标;
(2) 减少了过多的测试(浪费资金)或测试不足(产品故障多)所带来的风险;
(3) 在螺旋模型中维护只是模型的另一个周期,在维护和开发之间并没有本质区别;
(4) 它是风险驱动的;
- 缺点:
因为它是风险驱动的,除非软件开发人员具有丰富的风险评估经验和这方面的专门知识,否则将出现真正的风险。
螺旋模型有许多优点: 对可选方案和约束条件的强调有利于巳有软件的重用,也有助于把软件质量作为软件开发的一个重要目标;减少了过多测试( 浪费资金)或测试不足(产品故障多)所带来的风险;更重要的是,在螺旋模型中维护只是模型的另一个周期,在维护和开发之间并没有本质区别。
螺旋模型主要适用于内部开发的大规模软件项目。如果进行风险分析的费用接近整个项目的经费预算,则风险分析是不可行的。事实上,项目越大,风险也越大,因此,进行风险分析的必要性也越大。使用螺旋模型开发软件,要求软件开发人员具有丰富的风险评估经验和这方面的专门知识。
五、喷泉模型
迭代是软件开发过程中普遍存在的一种内在属性。经验表明,软件过程各个阶段之间的迭代或一个阶段内各个工作步骤之间的迭代,在面向对象范型中比在结构化范型中更常见。如图所示的喷泉模型是典型的面向对象生命周期模型。"喷泉”这个词体现了面向对象软件开发过程迭代和无缝的特性。

喷泉模型
为避免使用喷泉模型开发软件时开发过程过分无序,应该把一个线性过程(例如,快速原型模型或螺旋模型中的中心垂线)作为总目标。但是,同时也应该记住,面向对象范型本身要求经常对开发活动进行迭代或求精。
六、参考资料
[1] 张海藩,吕云翔. 软件工程(第4版)[M]. 北京:人民邮电出版社,2013 软件工程
[2] 张海藩,吕云翔. 软件工程(第4版)学习辅导与习题解析[M]. 北京: 人民邮电出版社,2013